简单的方法爬取b站dnf视频封面步骤解释
这随笔代码链接:http://www.cnblogs.com/yinghualuowu/p/8186375.html
首先我们要知道,一个分区封面显示到底在哪里可以找到。
很明显,查看审查元素并不能找到封面。这个时候应该想到封面是动态加载的。
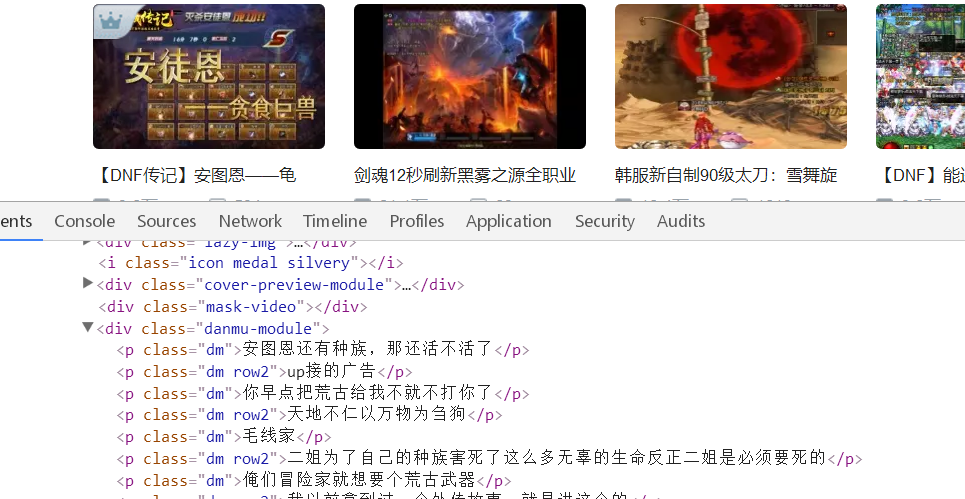
再次去Network寻找,我们发现这样一个JS。这是右侧热门视频封面的内容,点开之后存在pic:正是封面的链接。
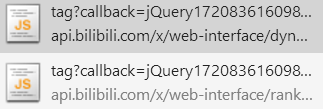

进行json解析之后,判定pic在data>archives结构下。这个时候链接是有了,那么将如何把Json拿出来呢?

让我们观察一下原来的信息,除去JQuery........()这层,里面就是json字符串了,既然如此简单,那么我们就...

查找开头第一个(,然后截取至最后一个),里面不就是了吗?
def instr(keystr):
st=keystr.find('(')+1
strhtml=keystr[st:len(keystr)-1]
return strhtml
def picsave(strJson,number):
global cnt
strdic=strJson['data']['archives']
num=len(strdic)
for i in range(0,num,1):
cnt=cnt+1
strdic=strJson['data']['archives'][i]
print(strdic['pic'])
urllib.request.urlretrieve(strdic['pic'],'E:\图片\dnf\%s.jpg'%(cnt))
然后进行翻页判断,我们尝试点开第一页和后面几页,看看不同。pn数字貌似变化很有规律啊。
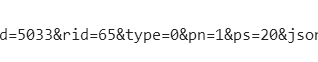
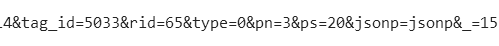
于是...
def urlget(num):
for i in range(1,num,1):
url='https://api.bilibili.com/x/tag/ranking/archives?callback=jQuery172014070206081723846_1514982701564&tag_id=5033&rid=65&type=0&pn='+str(i)+'&ps=20&jsonp=jsonp&_=1514982702144'
response=urllib.request.urlopen(url)
html=response.read().decode('utf-8')
html=instr(html)
strJson=eval(html)
picsave(strJson,i)
然后,就没有了。其实要高清大图的话,你需要点进去一个视频,然后审查元素,后面我会写一个输入av号来获取封面的代码
简单的方法爬取b站dnf视频封面步骤解释的更多相关文章
- Python 简单的方法爬取b站dnf视频封面
import urllib.request cnt=0 def instr(keystr): st=keystr.find('(')+1 strhtml=keystr[st:len(keystr)-1 ...
- 爬虫---爬取b站小视频
前面通过python爬虫爬取过图片,文字,今天我们一起爬取下b站的小视频,其实呢,测试过程中需要用到视频文件,找了几个网站下载,都需要会员什么的,直接写一篇爬虫爬取视频~~~ 分析b站小视频 1.进入 ...
- 爬取b站互动视频信息
首先分辨视频是不是互动视频可以看 https://api.bilibili.com/x/player.so?id=cid:1&aid=89017 这个api返回的xml中的 <inter ...
- Python爬虫一爬取B站小视频源码
如果要爬取多页的话 在最下方循环中 填写好循环的次数就可以了 项目源码 from fake_useragent import UserAgent import requests import time ...
- python爬取b站排行榜视频信息
和上一篇相比,差别不是很大 import xlrd#读取excel import xlwt#写入excel import requests import linecache import wordcl ...
- Python爬取B站视频信息
该文内容已失效,现已实现scrapy+scrapy-splash来爬取该网站视频及用户信息,由于B站的反爬封IP,以及网上的免费代理IP绝大部分失效,无法实现一个可靠的IP代理池,免费代理网站又是各种 ...
- 爬虫之爬取B站视频及破解知乎登录方法(进阶)
今日内容概要 爬虫思路之破解知乎登录 爬虫思路之破解红薯网小说 爬取b站视频 Xpath选择器 MongoDB数据库 爬取b站视频 """ 爬取大的视频网站资源的时候,一 ...
- scrapy进阶(CrawlSpider爬虫__爬取整站小说)
# -*- coding: utf-8 -*- import scrapy,re from scrapy.linkextractors import LinkExtractor from scrapy ...
- 萌新学习Python爬取B站弹幕+R语言分词demo说明
代码地址如下:http://www.demodashi.com/demo/11578.html 一.写在前面 之前在简书首页看到了Python爬虫的介绍,于是就想着爬取B站弹幕并绘制词云,因此有了这样 ...
随机推荐
- #define与typedef区别
1) #define是预处理指令,在编译预处理时进行简单的替换,不作正确性检查,不关含义是否正确照样带入,只有在编译已被展开的源程序时才会发现可能的错误并报错.例如: #define PI 3.141 ...
- centos7添加环境变量
# vim /etc/profile在最后,添加:export PATH="/usr/local/webserver/mysql/bin:$PATH" #添加的路径保存,退出,然后 ...
- druid数据源的加密解密工具
数据库得加密 先来一个网上大多数的教程吧,一个比较好的教程,如下. jar包版本:druid-1.0.13.jar 1. 加密,用以下命令将用户名和密码加密 cmd命令行执行 java -cp D:/ ...
- Python:extend和append的用法
转于:https://www.cnblogs.com/subic/p/6553187.html 博主:subic 1)list.append(object) 向列表中添加一个对象object2)lis ...
- java用write()拷贝一个文本文件
总结:灵活运用循环语句,或条件判断语句.每一种流的正确使用方法: 这里是两种方法: package com.ds; import java.io.*; public class tyut { /*pu ...
- Less:Less(CSS预处理语言)
ylbtech-Less:Less(CSS预处理语言) Less 是一门 CSS 预处理语言,它扩充了 CSS 语言,增加了诸如变量.混合(mixin).函数等功能,让 CSS 更易维护.方便制作主题 ...
- JavaScript权威指南读书笔记【第一章】
第一章 JavaScript概述 前端三大技能: HTML: 描述网页内容 CSS: 描述网页样式 JavaScript: 描述网页行为 特点:动态.弱类型.适合面向对象和函数式编程的风格 语法源自J ...
- 安装Ruby On Rails时运行“gem install rails”没有反应怎么办?
这两天在我的mac机上安装Ruby On Rails,感觉很爽,似乎在使用一个Windows和Linux的结合体,要界面有界面,要命令行有命令行. 不过安装Ruby On Rails的过程中遇到一个问 ...
- oracle上课 学习2 oracle 游标 存储过程 有用
1.1. 训练描述 使用游标,打印emp中20号部门的所有员工的信息 操作步骤答案 declare cursor c_emp is select * from emp where deptno=10 ...
- windows10 启用Linux子系统
转载 https://jingyan.baidu.com/article/e2284b2b99a327e2e6118d38.html 打开Windows下 设置--更新和安全--针对开发人员--选中“ ...