python scrapy 实战简书网站保存数据到mysql
1:创建项目

2:创建爬虫

3:编写start.py文件用于运行爬虫程序
# -*- coding:utf-8 -*-
#作者: baikai
#创建时间: 2018/12/14 14:09
#文件: start.py
#IDE: PyCharm
from scrapy import cmdline
cmdline.execute("scrapy crawl js".split())
4:设置settings.py文件的相关设置



爬取详情页数据
编写items.py文件
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# https://doc.scrapy.org/en/latest/topics/items.html
import scrapy
class ArticleItem(scrapy.Item):
# 定义我们需要的存储数据字段
title=scrapy.Field()
content=scrapy.Field()
article_id=scrapy.Field()
origin_url=scrapy.Field()
author=scrapy.Field()
avatar=scrapy.Field()
pub_time=scrapy.Field()
编写js.py
# -*- coding: utf-8 -*-
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
from jianshu_spider.items import ArticleItem
class JsSpider(CrawlSpider):
name = 'js'
allowed_domains = ['jianshu.com']
start_urls = ['https://www.jianshu.com/']
rules = (
# 匹配地址https://www.jianshu.com/p/d8804d18d638
Rule(LinkExtractor(allow=r'.*/p/[0-9a-z]{12}.*'), callback='parse_detail', follow=True),
)
def parse_detail(self, response):
# 获取内容页数据并解析数据
title=response.xpath("//h1[@class='title']/text()").get()
#作者图像
avatar=response.xpath("//a[@class='avatar']/img/@src").get()
author=response.xpath("//span[@class='name']/a/text()").get()
#发布时间
pub_time=response.xpath("//span[@class='publish-time']/text()").get()
#详情页id
url=response.url
#https://www.jianshu.com/p/d8804d18d638
url1=url.split("?")[0]
article_id=url1.split("/")[-1]
#文章内容
content=response.xpath("//div[@class='show-content']").get()
item=ArticleItem(
title=title,
avatar=avatar,
author=author,
pub_time=pub_time,
origin_url=response.url,
article_id=article_id,
content=content
)
yield item
设计数据库和表
数据库jianshu
表article
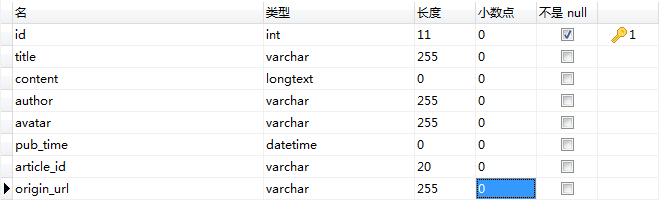
id设置为自动增长

将爬取到的数据存储到mysql数据库中
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html
import pymysql
from twisted.enterprise import adbapi
from pymysql import cursors
class JianshuSpiderPipeline(object):
def __init__(self):
dbparams = {
'host': '127.0.0.1',
'port': 3306,
'user': 'root',
'password': '8Wxx.ypa',
'database': 'jianshu',
'charset': 'utf8'
}
self.conn = pymysql.connect(**dbparams)
self.cursor = self.conn.cursor()
self._sql = None
def process_item(self, item, spider):
self.cursor.execute(self.sql, (item['title'], item['content'], item['author'], item['avatar'], item['pub_time'], item['origin_url'],item['article_id']))
self.conn.commit()
return item
@property
def sql(self):
if not self._sql:
self._sql = """
insert into article(id,title,content,author,avatar,pub_time,origin_url,article_id) values(null,%s,%s,%s,%s,%s,%s,%s)
"""
return self._sql
return self._sql
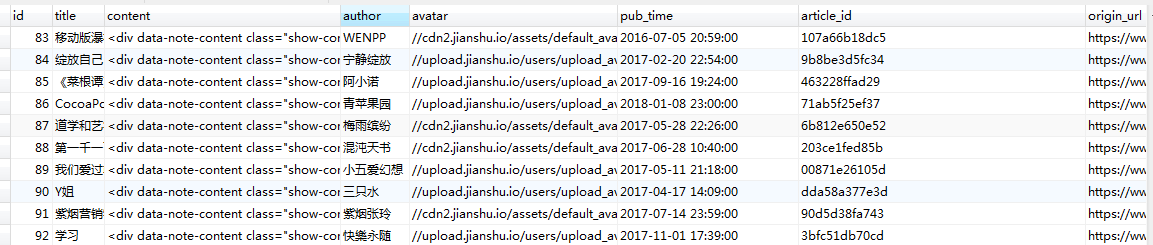
运行start.py效果如下
python scrapy 实战简书网站保存数据到mysql的更多相关文章
- SpringMVC保存数据到mysql乱码问题
SpringMVC保存数据到mysql乱码问题 乱码问题常见配置 一.web.xml配置过滤器 <filter> <filter-name>encoding-filter< ...
- hibernate保存数据到mysql时的中文乱码问题
因为hibernate底层使用的是jdbc的技术,所以我参考了别人使用jdbc保存数据到mysql里面时解决乱码问题的方法! 首先要告诉数据库要插入的字符串的字符集,mysql 默认使用的字符集是 l ...
- python scrapy实战糗事百科保存到json文件里
编写qsbk_spider.py爬虫文件 # -*- coding: utf-8 -*- import scrapy from qsbk.items import QsbkItem from scra ...
- Python爬取简书主页信息
主要学习如何通过抓包工具分析简书的Ajax加载,有时间再写一个Multithread proxy spider提升效率. 1. 关键点: 使用单线程爬取,未登录,爬取简书主页Ajax加载的内容.主要有 ...
- Python Scrapy 实战
Python Scrapy 什么是爬虫? 网络爬虫(英语:web crawler),也叫网络蜘蛛(spider),是一种用来自动浏览万维网的网络机器人.其目的一般为编纂网络索引. Python 爬虫 ...
- 教程+资源,python scrapy实战爬取知乎最性感妹子的爆照合集(12G)!
一.出发点: 之前在知乎看到一位大牛(二胖)写的一篇文章:python爬取知乎最受欢迎的妹子(大概题目是这个,具体记不清了),但是这位二胖哥没有给出源码,而我也没用过python,正好顺便学一学,所以 ...
- Scrapy Item用法示例(保存item到MySQL数据库,MongoDB数据库,使用官方组件下载图片)
需要学习的地方: 保存item到MySQL数据库,MongoDB数据库,下载图片 1.爬虫文件images.py # -*- coding: utf-8 -*- from scrapy import ...
- Spark使用Java读取mysql数据和保存数据到mysql
原文引自:http://blog.csdn.net/fengzhimohan/article/details/78471952 项目应用需要利用Spark读取mysql数据进行数据分析,然后将分析结果 ...
- 利用python scrapy 框架抓取豆瓣小组数据
因为最近在找房子在豆瓣小组-上海租房上找,发现搜索困难,于是想利用爬虫将数据抓取. 顺便熟悉一下Python. 这边有scrapy 入门教程出处:http://www.cnblogs.com/txw1 ...
随机推荐
- CentOS 6.5下安装Tomcat --专业增强版 非yum
Tomcat安装 通常情况下我们要配置Tomcat是很容易的一件事情,但是如果您要架设多用户多服务的Java虚拟主机就不那么容易了.其中最大的一个问题就是Tomcat执行权限.普通方式配置的Tomca ...
- Promise对象(异步编程)
Promise对象解决函数的异步调用(跟回调函数一样) 三种状态: 未完成(pending)已完成(fulfilled)失败(rejected) 通过then函数来链式调用 目前市面上流行的一些类库:
- Struts2_Path
路径问题说明: struts2中的路径问题是根据action的路径而不是jsp路径来确定,所以尽量不要使用相对路径.index.jsp虽然可以用rederect方式解决,但redirect方式并非必要 ...
- Python基础学习之变量赋值
1.赋值操作符 Python语言中,等号(=)是主要的赋值操作符: >>> aInt=-100 >>> aString='this is a string' > ...
- sql:表中数据全部删除之后,重新插入时,从1开始增加
数据库中设置了自增列,有时候需要清楚数据库从新录入数据.最常见的做法就是使用sql语句"delete 表明名"或是直接选中数据,然后删除数据.但是再次插入数据的时候,你就会发现自增 ...
- 如何使用ABSL代码调用Web service
需求:在C4C UI里创建web service(maintain ticket),然后通过ABSL代码消费. 1. 创建一个新的Communication Arrangement 基于Manage ...
- char 与 signed char 和 unsigned char三者之间的关系
# char 与 signed char 和 unsigned char三者之间的关系 三者都占用 1个字节,即 8 bit signed char取值范围(-128, 127) unsigned c ...
- POJ-2139 Six Degrees of Cowvin Bacon---Floyd
题目链接: https://vjudge.net/problem/POJ-2139 题目大意: 给定一些牛的关系,他们之间的距离为1. 然后求当前这只牛到每只牛的最短路的和,除以 n - 1只牛的最大 ...
- 【BZOJ3622】已经没有什么好害怕的了(动态规划+广义容斥)
点此看题面 大致题意: 有\(n\)个糖果和\(n\)个药片,各有自己的能量.将其两两配对,求糖果比药片能量大的组数恰好比药片比糖果能量大的组数多\(k\)组的方案数. 什么是广义容斥(二项式反演) ...
- querystring处理参数小利器
相信上一章的讲解,相信大家对url地址有一个更直观的认识,在url解析的时候可以用querystring这样一个module替换,然后对这个query集成一个对象,这里不管是前端开发还是后端开发,都常 ...