python——文件处理
1.文件处理
f = open(file="file01.txt", mode="r", encoding="utf-8") #python3默认编码格式为utf-8
data = f.read()
print(data)
print(type(data)) # <class 'str'>
f.close()
如果报错
#UnicodeDecodeError: 'utf-8' codec can't decode byte 0xcc in position 0: invalid continuation byte
说明编码不对。
按正常逻辑来讲,文件是以什么方式存的,就应该用什么方式去读取,比如以gb2312存的,就应该以gb2312去读。文件是以utf-8存的,就用utf-8的编码格式去读。
2.文件处理-二进制模式
文件在计算机中是以二进制存储的,我们可以不理会编码,直接以二进制的形式读取文件内容
f = open(file="file01.txt", mode="rb")
data = f.read()
print(data)
f.close()
以二进制方式读取, mode = "rb" ,得到的结果也是二进制。
在读取视频、图片等内容和网络传输的时候,会使用二进制方式读取。
#打印结果 b'\xef\xbb\xbf\xe7\x94\xb0\xe7\xbb\xb4\xe9\x80\x9a\t12001\t10\r\n\xe5\xbc\xa0\xe5\xae\xb6\xe9\x93\xad\t12002\t11\r\n\xe8\x88\x92\xe5\xa8\x85\t12003\t12\r\n\xe5\xad\x99\xe7\x8e\x89\xe5\x80\xa9\t12004\t13\r\n\xe5\xbc\xa0\xe8\xb6\x85\t12005\t14\r\n\xe7\x8e\x8b\xe4\xba\xac\t12006\t15\r\n\xe5\xbb\x96\xe6\x9e\x97\xe8\x8b\xb1\t12007\t16\r\n\xe5\xbe\x90\xe6\x99\x93\xe8\x8e\x89\t12008\t17\r\n\xe9\x87\x91\xe5\x98\x89\xe7\xa5\xba\t12009\t18\r\n\xe5\x8f\x8a\xe6\xa0\xbc\t12010\t19\r\n\xe4\xba\x8e\xe5\x87\xaf\xe9\x98\xb3\t12011\t20\r\n\xe6\x9d\x8e\xe4\xbf\x8a\xe7\xba\xa2\t12012\t21\r\n\xe5\x88\x98\xe5\x86\xac\t12013\t22\r\n'
3.文件处理-智能检测编码的工具
import chardet
f = open('file01.txt', mode="rb")
data = f.read()
print(chardet.detect(data))
#打印结果:
#{'encoding': 'UTF-8-SIG', 'confidence': 1.0, 'language': ''}
#confidence,表示 encoding 为 UTF-8-SIG 的概率为 1.0
然后,当我们知道目标文件是什么格式后,data.decode("utf-8") 一下,就可以打印出我们需要的内容
4. 循环读取逐条读取文件
f = open('file01.txt', 'r', encoding='utf-8')
for line in f:
print(line, end="") # end = "" 表示,打印的时候以什么结尾,此处可以去掉print默认的换行符 \n
f.close()
打印结果:
# 田维通 12001 10
# 张家铭 12002 11
# 舒娅 12003 12
# 孙玉倩 12004 13
# 张超 12005 14
# 王京 12006 15
# 廖林英 12007 16
# 徐晓莉 12008 17 ...
5.写文件
#以 gbk 格式创建一个文件,写入内容“将进酒”
f = open(file='file02.txt', mode='w', encoding='gbk')
f.write('将进酒')
f.close()
如果这个时候再写一遍,即
f = open(file='file02.txt', mode='w', encoding='gbk')
f.write('杯莫停')
f.close()
得到的结果是:将原来的 file02.txt 文件覆盖掉了
6.写文件——追加
写入内容追加的已有内容后面
f = open('file02.txt', 'ab') #mode 为 ab 或 a,表示追加
f.write('\n人生得意须尽欢'.encode('gbk'))
f.close()

7.文件处理-读写混合操作文件
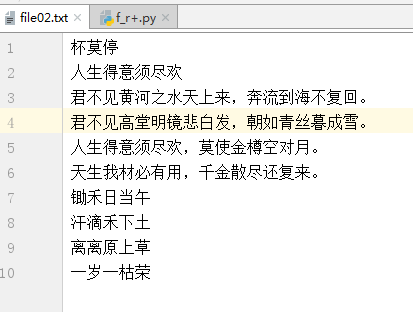
f = open('file02.txt', 'r+', encoding='gbk')
data = f.read()
print("content:", data)
f.write("\n锄禾日当午")
f.write("\n汗滴禾下土")
f.write("\n离离原上草")
f.write("\n一岁一枯荣")
f.close()
结果:
8.文件操作的其他功能
(1)flush()
f = open('f_flush.txt', 'w', encoding='utf-8')
f.write('奇门遁甲') # 在f.close() 之前,写入的内容是在内存中的,而且可能此时txt文件里是没有内容的,所以可以加一句 f.flush(),把文件强制从内存buffer里刷新到硬盘
#一般内存里的buffer满了会自动刷新到硬盘,但是使用 f.flush() 可控制强制刷新到硬盘
f.close()
(2)tell() seek()
# 文本内容: hello world!
>>> f = open('file03.txt', 'r', encoding='gbk')
>>> f.tell() #返回当前文件操作光标位置
0
>>> f.seek(1) # 把操作文件的光标移到指定位置
1
>>> f.read()
'ello world!'
注意:tell(), seek()找的都是字节,长度都是按字节算的。另外,每个字符在不同编码格式下所占的字节长度不一样,gbk 一个中文占2个字节,utf-8 一个中文占3个字节
以中文为例:
# 文件内容:技高一筹
>>> f = open("file03.txt",'r',encoding='gbk')
>>> f.read()
'技高一筹'
>>> f.tell()
8
>>> f.seek(0) #把文件光标移动到起点 0
0
>>> f.seek(4) #把文件光标移动到 4,此时,gbk 下,一个汉字占2个字节,此时光标的位置在 技高和一筹之间
4
>>> f.read() # 所以,读取结果为 后两个字
'一筹'
>>>
#-----------------------------------------------------------------------------
>>> f.seek(1) #把文件光标移动到 1,“半个字”,此时读取内容不出问题,因为他只拿到了 技 字的一部分字节,打印会报错
1
>>> f.tell()
1
>>> f.read()
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
UnicodeDecodeError: 'gbk' codec can't decode byte 0xef in position 6: incomplete
multibyte sequence
(3)seekable() 判断文件是否可进行seek操作,readable() 判断文件是否可读,writable()判断文件是否可写
(4) truncate() 按指定长度截断文件
#文件内容: 技高一筹
>>> f = open("file03.txt",'r+',encoding='gbk')
>>> f.seek(2)
2
>>> f.truncate()
2
>>> f.read() #文件内容 只剩一个 “技” 字
truncate(4)指定长度的话,就从文件开头开始截取指定长度。不指定长度的话,就从当前位置到文件尾部的内容全去掉。
#文件内容: 技高一筹
>>> f = open("file03.txt",'r+',encoding='gbk')
>>> f.tell()
0
>>> f.truncate(4) #文件内容 只剩一个 “技高” 字
9. 实现文件内容的修改
import os
f = open('file05.txt', 'r+', encoding='gbk') #打开file05.txt 文件
f_new = open('file05_new.txt', 'w', encoding='gbk') # 创建一个新文件
old_str = '李四'
new_str = '李云龙'
for line in f:
if old_str in line: #逐行读取
line = line.replace(old_str, new_str) #修改文件中的内容
f_new.write(line) # 逐行读取的内容写到新创建的文件中
f.close()
f_new.close()
os.replace('file05_new.txt', 'file05.txt') # 替换,以达到修改文件内容的目的(window用os.replace()可实现,但是使用os.rename()不可以,会报错,提示 file05.txt 已存在,无法创建)
python——文件处理的更多相关文章
- Linux下Python 文件内容替换脚本
Linux下Python 文件替换脚本 import sys,os if len(sys.argv)<=4: old_text,new_text = sys.argv[1],sys.argv[2 ...
- 【Python文件处理】递归批处理文件夹子目录内所有txt数据
因为有个需求,需要处理文件夹内所有txt文件,将txt里面的数据筛选,重新存储. 虽然手工可以做,但想到了python一直主张的是自动化测试,就想试着写一个自动化处理数据的程序. 一.分析数据格式 需 ...
- Python文件使用“wb”方式打开,写入内容
Python文件使用"wb"方式打开,写入字符串会报错,因为这种打开方式为:以二进制格式打开一个文件只用于写入.如果该文件已存在则将其覆盖.如果该文件不存在,创建新文件. 所以写入 ...
- Python 文件操作函数
这个博客是 Building powerful image classification models using very little data 的前期准备,用于把图片数据按照教程指示放到规定的文 ...
- python文件I/O(转)
Python 文件I/O 本章只讲述所有基本的的I/O函数,更多函数请参考Python标准文档. 打印到屏幕 最简单的输出方法是用print语句,你可以给它传递零个或多个用逗号隔开的表达式.此函数把你 ...
- python 文件操作总结
Python 文件I/O 本章只讲述所有基本的的I/O函数,更多函数请参考Python标准文档. 打印到屏幕 最简单的输出方法是用print语句,你可以给它传递零个或多个用逗号隔开的表达式.此函数把你 ...
- Python基础篇【第2篇】: Python文件操作
Python文件操作 在Python中一个文件,就是一个操作对象,通过不同属性即可对文件进行各种操作.Python中提供了许多的内置函数和方法能够对文件进行基本操作. Python对文件的操作概括来说 ...
- python文件和元组
python文件操作 相较于java,Python里的文件操作简单了很多 python 获取当前文件所在的文件夹: os.path.dirname(__file__) 写了一个工具类,用来在当前文件夹 ...
- Python文件基础
===========Python文件基础========= 写,先写在了IO buffer了,所以要及时保存 关闭.关闭会自动保存. file.close() 读取全部文件内容用read,读取一行用 ...
- python文件打包格式,pip包管理
1..whl是python文件的一种打包格式, 在有些情况下,可以将文件的后缀名改为.zip并解压 2.cmd中,提示pip版本太低,先升级pip pip install --upgrade pi ...
随机推荐
- ckeditor(在线文本编辑器)使用教程
ckeditor是一款由javascript编写的富文本网页编辑器,它可以填写文字.插入图片.视频.Excel等富媒体信息,也可以在源码方式下填写内容,在各个网站中应用非常广泛. 下面就来说说cked ...
- qt安装
在以下网页选择一个国内的下载地址即可 http://download.qt.io/official_releases/qt/5.7/5.7.0/qt-opensource-linux-x64-5.7. ...
- LitJson(读Exce文件写入到json文件):
读Exce文件写入到json文件汇总: //命名空间 using System.Collections; using System.Collections.Generic; using System. ...
- [引]雅虎日历控件 Example: Two-Pane Calendar with Custom Rendering and Multiple Selection
本文转自:http://yuilibrary.com/yui/docs/calendar/calendar-multipane.html This example demonstrates how t ...
- Ubuntu截图工具gnome-screenshot使用教程
Ubuntu自带的截图工具非常好用,可以自已设置各种截图的快捷键,下面我们一起来了解一下这个截图工具gnome-screenshot Ubuntu自带的截图工具非常好用,可以自已设置各种截图的快捷 ...
- DEDE会员注册邮件验证时,用户无法收到邮件的解决方法
本文以qq邮箱.163邮箱和易网库提供的企业邮箱为例,简要介绍在织梦(DEDECMS)中设置SMTP验证发送邮件的方法 一.在织梦中使用qq邮箱发送邮件 1.在织梦中使用qq邮箱发送邮件, 需要确保q ...
- php 关于时间的函数
//返回1970年1月1日零点以来的秒数. //定义为从格林威治时间1970年01月01日00时00分00秒(北京时间1970年01月01日08时00分00秒)起至现在的总秒数. time(); ...
- linux内核态和用户态小结
一 内核态和用户态的区别 当进程执行系统调用而陷入内核代码中执行时,我们就称进程处于内核状态.此时处理器处于特权级最高的(0级)内核代码.当进程处于内核态时,执行的内核代码会使用当前的内核栈.每个进程 ...
- vue学习中遇到的onchange、push、splice、forEach方法使用
最近在做vue的练习,发现有些js中的基础知识掌握的不牢,记录一下: 1.onchange事件:是在域的内容改变时发生,单选框与复选框改变后触发的事件. 2.push方法:向数组的末尾添加一个或多个元 ...
- js 去掉字符串前后空格5种方法
第一种:循环检查替换 //供使用者调用 function trim(s){ return trimRight(trimLeft(s)); } //去掉左边的空白 function trimLeft(s ...