26. ClustrixDB 分布式架构/数据分片
数据分片
介绍
共享磁盘vs.无共享
分布式数据库系统可分为两大类数据存储架构:(1)共享磁盘和(2)无共享。
|
Shared Disk Architecture
|
Shared Nothing Architecture
|
|---|---|
 |
 |
共享磁盘方法在协调对单个中心资源的访问时受到几个固有的体系结构限制。在这样的系统中,随着集群中节点数量的增加,协调开销也随之增加。虽然一些工作负载可以通过共享磁盘很好地扩展(例如,由大量读操作控制的小型工作集),但是大多数工作负载的扩展能力都很差——尤其是具有大量写负载的工作负载。
ClustrixDB使用无共享的方法,因为它是唯一已知的允许大规模分布式系统的方法。
无共享的挑战
为了构建一个可伸缩的无共享数据库系统,必须解决两个基本问题:
- 将大型数据集拆分到多个单独的节点上。
- 创建一个可以利用分布式数据环境的评估模型。
本文档解释了ClustrixDB如何将数据集分布到大量独立节点上,并提供了一些架构决策背后的推理。
无共享分配策略
在无共享架构中,大多数数据库可分为以下几类:
- Table-level distribution。最基本的方法,将整个表分配给一个节点。数据库不分割表。这样的系统不能处理非常大的表。
- Single-key-per-table distribution (a.k.索引定位,或单键分片)。最常见的方法。大多数分布式数据库(如MySQL集群、MongoDB等)的首选方法。在这种方法中,使用一个键(例如用户id)将表分成多个块。与块关联的所有索引都由主键维护(位于同一位置)。
- Independent index distribution。ClustrixDB使用的策略。在这种方法中,每个索引都有自己的分布。需要支持广泛的分布式查询评估计划。
ClustrixDB基础知识
ClustrixDB对数据分发有一种细粒度的方法。下表总结了系统使用的基本概念和术语。请注意,与许多其他系统不同,ClustrixDB使用每个索引的分发策略。
分布的概念概述
|
ClustrixDB分布的概念 |
|
|---|---|
| Representation |
每个表包含一个或多个索引。在内部,ClustrixDB将这些索引作为表的表示。每个表示都有自己的分布键(也称为分区键或碎片键),这意味着ClustrixDB使用多个独立键来分割一个表中的数据。这与大多数其他分布式数据库系统形成了对比,后者使用单个键来分割一个表中的数据。 每个表必须有一个主键。如果用户没有定义主键,ClustrixDB将自动创建一个隐藏的主键。基本表示包含表中的所有列,按主键排序。非基表示包含表中列的一个子集。 |
| Slice |
ClustrixDB使用一致的散列将每个表示分解为逻辑片的集合。 通过使用一致的哈希,ClustrixDB可以分割单个片,而不必重新哈希整个表示。 |
| Replica |
ClustrixDB为容错和可用性维护多个数据副本。每个逻辑片至少有两个物理副本,存储在不同的节点上。 ClustrixDB支持配置每个表示的副本数量。例如,一个用户可能需要三个副本作为表的基本表示,而只需要两个副本作为表的其他表示。 |
概念的例子:
sql> CREATE TABLE example (
id bigint primary key,
col1 integer,
col2 integer,
col3 varchar(),
key k1 (col2),
key k2 (col3, col1)
);
我们用以下数据填充我们的表:
| Table: example | |||
| id | col1 | col2 | col3 |
|---|---|---|---|
| 1 | 16 | 36 | january |
| 2 | 17 | 35 | february |
| 3 | 18 | 34 | march |
| 4 | 19 | 33 | april |
| 5 | 20 | 32 | may |
Representation
ClustrixDB将上述模式组织成三种表示形式。一个用于主表(由主键组织的基本表示),然后是另外两个表示,每个表示由索引键组织。
下图中的黄色显示了每种表示的排序键。注意,辅助索引的表示包括主键列。
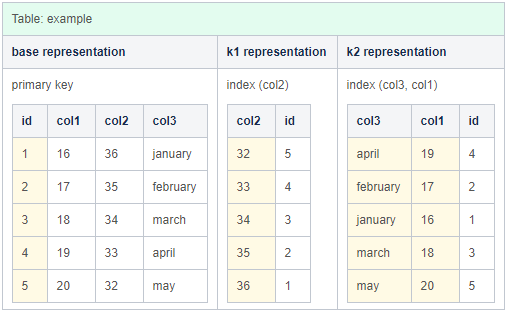
Slice
ClustrixDB将把每个表示分割成一个或多个逻辑片。当对ClustrixDB进行切片时,使用以下规则:
- 我们对表示的键应用一致的哈希算法。
- 我们独立地分配每个表示。请参考下面的单键与独立分布,以深入研究这种设计背后的原因。
- 片的数量在同一个表的不同表示之间可能有所不同。
- 我们根据大小来分割切片。
- 用户可以配置每个表示的初始片数。默认情况下,每个表示从每个节点的一个片开始。

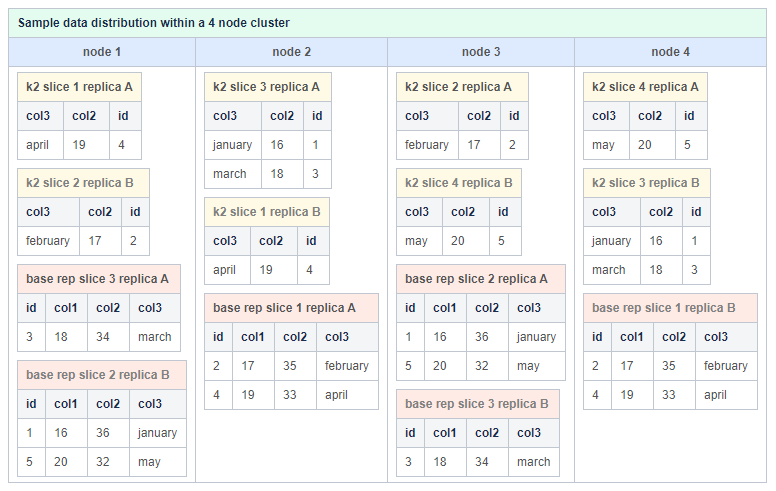
Replica
为了确保容错和可用性,ClustrixDB包含多个数据副本。ClustrixDB使用以下规则在集群中放置副本(片的副本):
- 每个逻辑片由两个或多个物理副本实现。默认的保护因子可在每个表示级别上配置。
- 复制位置基于大小、读和写的平衡。
- 同一个节点上不能存在同一片的两个副本。
- ClustrixDB可以在线生成新的副本,而不需要挂起或阻塞对片的写操作。
一致性哈希
ClustrixDB对数据分布使用一致的哈希。一致的哈希允许ClustrixDB动态地重新分发数据,而不必重新哈希整个数据集。
切片
ClustrixDB将每个分布键散列到64位数字。然后我们把空间分成范围。然后,每个范围由一个特定的片拥有。下表说明了一致哈希如何将特定键分配给特定的片。

Re-Slicing增长
随着数据集的增长,ClustrixDB将自动并递增地重新切片数据集,每次一个或多个切片。目前,我们的重新切片阈值是基于数据集大小的。如果一个片超过了最大大小,系统将自动将其分成两个或更多的小片。
例如,假设我们的一个切片超出了预先设置的阈值:

单键与独立的索引分布
很容易看出为什么表级分发提供非常有限的可伸缩性。设想一个由一个或两个非常大的表(数十亿行)控制的模式。在这种情况下,向系统添加节点没有帮助,因为单个节点必须能够容纳整个表。
为什么ClustrixDB使用独立的索引分布而不是单一键方法?答案是双重的:
- 独立的索引分布允许更广泛的分布式查询计划,这些计划可以随集群节点数量的增加而扩展。
- 独立的索引分布需要系统内部的严格支持,以保证索引之间和主表之间保持一致。许多系统没有提供支持索引一致性所需的严格保证。
让我们检查一个特定的用例来比较和对比这两种方法。想象一个公告板应用程序,其中不同的主题由线程分组,用户可以将其发布到不同的主题中。我们的公告栏服务已经变得很受欢迎,我们现在有数十亿的帖子,数十万的帖子,数百万的用户。
我们还假设公告栏的主要工作负载由以下两种访问模式组成:
- 以post id顺序检索特定线程的所有post。
- 对于特定用户,检索该用户最近的10篇文章
我们可以想象一个包含应用程序中所有post的大表,其简化模式如下:
-- Example schema for the posts table.
sql> CREATE TABLE thread_posts (
post_id bigint,
thread_id bigint,
user_id bigint,
posted_on timestamp,
contents text,
primary key (thread_id, post_id),
key (user_id, posted_on)
); -- Use case : Retrieve all posts for a particular thread in post id order.
-- desired access path: primary key (thread_id, post_id)
sql> SELECT *
FROM thread_posts
WHERE thread_id =
ORDER BY post_id; -- Use case : For a specific user, retrieve the last posts by that user.
-- desired access path: key (user_id, posted_on)
sql> SELECT *
FROM thread_posts
WHERE user_id =
ORDER BY posted_on desc
LIMIT ;
单一的关键方法
使用单一键方法时,我们面临着一个难题:我们选择哪个键来分发posts表?从下表可以看出,我们不能选择一个键来实现跨两个用例的良好可伸缩性。
|
Distribution Key
|
Use case 1: posts in a thread
|
Use case 2: top 10 posts by user
|
|---|---|---|
| thread_id | 包含thread_id的查询将执行得很好。对特定线程的请求被路由到集群中的单个节点。当线程和帖子的数量增加时,我们只需向集群添加更多的节点来增加容量。 | .不包含thread_id的查询(比如某个特定用户对最近10篇文章的查询)必须对包含thread_posts表的所有节点求值。换句话说,系统必须广播查询请求,因为相关的post可以驻留在任何节点上 |
| user_id | 在广播中不包含user_id的查询。与thread_id密钥示例(用例2)一样,在必须进行广播时,我们会失去系统的可伸缩性。 | 包含user_id的查询被路由到单个节点。每个节点将包含一个用户的一组有序的帖子。该系统可以通过避免广播来扩展。 |
使用这种系统的一种可能性是维护一个单独的表,其中包括user_id和posted_on列。然后,我们可以让应用程序手动维护这个索引表。
然而,这意味着应用程序现在必须发出多个写操作,并承担两个表之间数据一致性的责任。想象一下,如果我们需要添加更多的索引?这种方法根本无法推广。数据库的优点之一是自动索引管理。
独立索引键方法
ClustrixDB将自动创建满足这两个用例的独立发行版。DBA可以通过thread_id指定分发基本表示(主键),通过user_id指定分发辅助键。系统将自动管理具有完整ACID保证的表和二级索引。
有关更详细的解释,请参阅我们的评估模型部分。
缓存效率
与其他使用主从对进行数据容错的系统不同,ClustrixDB以更细粒度的方式分布数据,如前面几节所述。我们的方法允许ClustrixDB通过不向次副本发送读操作来提高缓存效率。
考虑下面的例子。假设一个由2个节点和2个片a和B组成的集群,其中有二级副本a '和B'。
|
Read from both copies
|
Read from primary copy only
|
||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
|
|
||||||||||||
|
如果我们允许从主副本和次副本读取,那么每个节点都必须缓存A和b的内容。假设每个节点有32GB的缓存,那么系统的总有效缓存为32GB。 |
通过将读取限制为主副本,我们使节点1只负责A,节点2只负责B。假设每个节点有32GB的缓存,那么总的有效缓存占用空间将是64GB,或者是相反模型的两倍。 |
26. ClustrixDB 分布式架构/数据分片的更多相关文章
- 31. ClustrixDB 分布式架构/查询优化器
ClustrixDB查询优化器有何不同 ClustrixDB查询优化器的核心是能够执行一个具有最大并行性的查询和多个具有最大并发性的并发查询.这是通过分布式查询规划器和编译器以及分布式无共享执行引擎实 ...
- 29. ClustrixDB 分布式架构/并发控制
介绍 ClustrixDB使用多版本并发控制(MVCC)和2阶段锁(2PL)的组合来支持混合的读写工作负载.在我们的系统中,读取器享受无锁快照隔离,而写入器使用2PL来管理冲突.并发控制的组合意味着读 ...
- 28. ClustrixDB 分布式架构/评估模型
本节描述如何在数据库中计算查询.在ClustrixDB中,我们跨节点切片数据,然后将查询发送到数据.这是数据库的基本原则之一,它允许随着添加更多节点而几乎线性地扩展. 有关如何分布数据的概念,请参阅数 ...
- 27. ClustrixDB 分布式架构/一致性、容错和可用性
一致性 许多分布式数据库都采用最终一致性而不是强一致性来实现可伸缩性.但是,最终的一致性会增加应用程序开发人员的复杂性,他们必须针对可能出现的数据不一致的异常进行开发. ClustrixDB提供了一个 ...
- 30. ClustrixDB 分布式架构/Rebalancer
Rebalancer是一个自动化系统,用于维护集群中数据的健康分布.通过修改数据的分布和位置来响应“不健康”集群是Rebalancer的工作.Rebalancer是一个在线进程,它影响对集群的更改,对 ...
- MongoDB 分布式架构 复制 分片 适用性范围
转载自 http://www.mongoing.com/archives/3573
- 王家林的81门一站式云计算分布式大数据&移动互联网解决方案课程第14门课程:Android软硬整合设计与框架揭秘: HAL&Framework &Native Service &App&HTML5架构设计与实战开发
掌握Android从底层开发到框架整合技术到上层App开发及HTML5的全部技术: 一次彻底的Android架构.思想和实战技术的洗礼: 彻底掌握Andorid HAL.Android Runtime ...
- [原创].NET 分布式架构开发实战之三 数据访问深入一点的思考
原文:[原创].NET 分布式架构开发实战之三 数据访问深入一点的思考 .NET 分布式架构开发实战之三 数据访问深入一点的思考 前言:首先,感谢园子里的朋友对文章的支持,感谢大家,希望本系列的文章能 ...
- ClickHouse(02)ClickHouse架构设计介绍概述与ClickHouse数据分片设计
ClickHouse核心架构设计是怎么样的?ClickHouse核心架构模块分为两个部分:ClickHouse执行过程架构和ClickHouse数据存储架构,下面分别详细介绍. ClickHouse执 ...
随机推荐
- window启动目录
启动文件目录 C:\Users\Administrator\AppData\Roaming\Microsoft\Windows\Start Menu\Programs\Startup
- ioctl接口内容操作
int ioctl( int fd, int request, .../* void *arg */ ) 详解 第三个参数总是一个指针,但指针的类型依赖于request 参数.我们可以把和网络相关的请 ...
- HDU3336 Count the string(kmp
It is well known that AekdyCoin is good at string problems as well as number theory problems. When g ...
- nginx+gunicorn/uwsgi+python web 的前世今生
我们在部署 flask.django 等 python web 框架时,网上最多的教程就是 nginx+gunicorn/uwsgi 的部署方式,那为什么要这么部署呢,本文就来系统地解释这个问题. 必 ...
- css中的position 的absolute和relative的区别(转)
我们先来看看CSS3 Api中对position属性的相关定义: static:无特殊定位,对象遵循正常文档流.top,right,bottom,left等属性不会被应用. relative:对象遵循 ...
- css样式水平居中和垂直居中的方法
水平居中(包含块中居中) 1. 定宽,左右margin为auto.(常规流块盒.弹性项目[不用定宽]) 例子:在box1盒子上设置宽,再设置margin:auto: <style> .bo ...
- mongodb的简单操作记录
由于项目上需要对mongodb进行监控,所以需要先熟悉下什么是mongobd以及mongodb的简单操作 mongodb的安装: curl -O https://fastdl.mongodb.org/ ...
- react 在新窗口 打开页面
遇到这个需求 首先通过 Link a去尝试直接跳转.发现2个问题 1.Link跳转 会自动进行登录校验,我设想是路由没有匹配到,去验证后大致排除了. 因为这个链接 直接粘贴到浏览器 是可以访问到的. ...
- 解决GitHub添加sshkey仍然无法访问clone远程仓库的问题
1 ssh -v git@github.com 通过这个命令打印调试信息 ebug1: expecting SSH2_MSG_NEWKEYS debug1: SSH2_MSG_NEWKEYS rece ...
- python、第五篇:数据备份、pymysql模块
一 IDE工具介绍 生产环境还是推荐使用mysql命令行,但为了方便我们测试,可以使用IDE工具 下载链接:https://pan.baidu.com/s/1bpo5mqj 掌握: #1. 测试+链接 ...