hdfs的balancer
参考:
https://blog.csdn.net/mnasd/article/details/80369603
在CDH中选一个资源多的节点,安装
HDFS->添加角色到实例
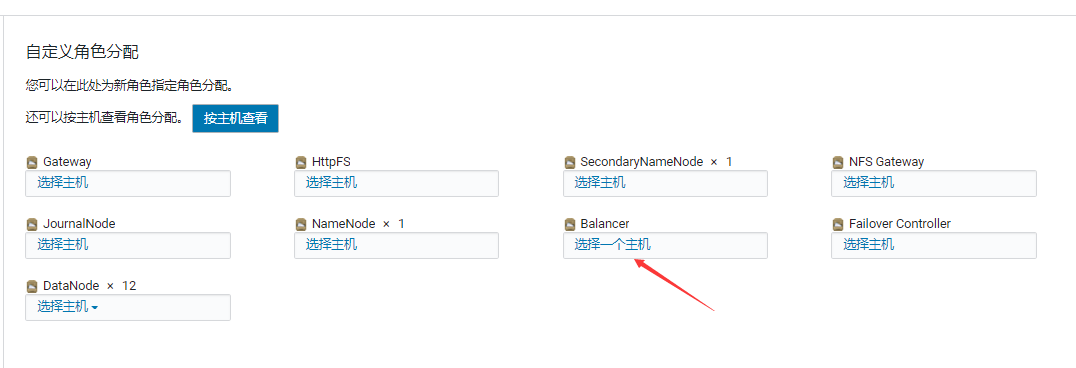
启动后状态是灰的
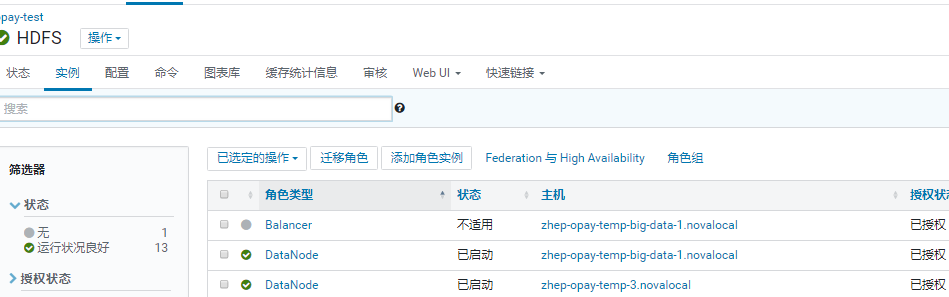
在做平衡之前,可做相关参数调整:
在hdfs的配置中输入balancer
dfs.datanode.balance.max.concurrent.moves #默认50
dfs.balancer.max-size-to-move 10G #各节点差异超过10G就平衡
Balancer 的 Java 堆栈大小 默认1G #可增加到2G
不过没关系,点进去在操作中选择重新平衡
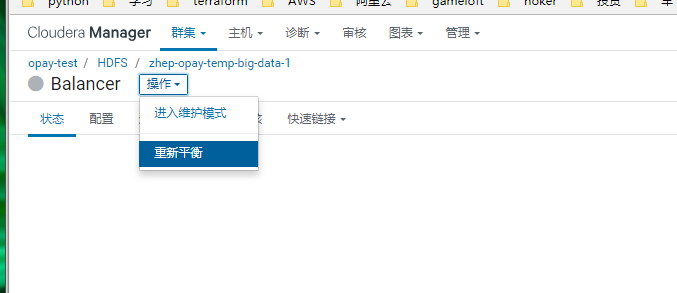
实际上就是在该节点上运行hdfs.sh balancer.
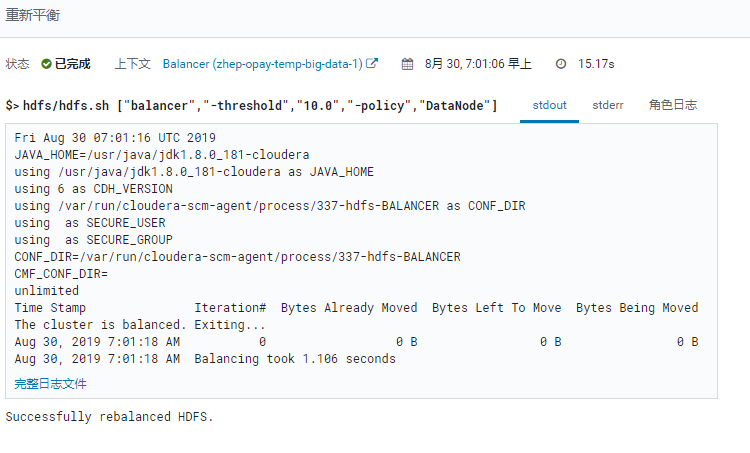
注: 也可在该节点上手动执行命令:
hdfs balancer -policy datanode -threshold 30 -include -f /tmp/hdfs-blancer.txt
#tmp/hdfs-blancer.txt 写上想要执行平衡节点的hostname.
hdfs的balancer的更多相关文章
- CDH版HDFS Block Balancer方法
命令: sudo -u hdfs hdfs balancer 默认会检查每个datanode的磁盘使用情况,对磁盘使用超过整个集群10%的datanode移动block到其他datanode达到均衡作 ...
- Apache Hadoop2.0之HDFS均衡操作分析
1 HDFS均衡操作原理 HDFS默认的块的副本存放策略是在发起请求的客户端存放一个副本,如果这个客户端在集群以外,那就选择一个不是太忙,存储不是太满的节点来存放,第二个副本放在与第一个副本相同的机架 ...
- HDFS的7个设计特点
1.Block的放置:默认不配置.一个Block会有三份备份,一份放在NameNode指定的DataNode,另一份放在与指定DataNode非同一Rack上的DataNode,最后一份放在与指定Da ...
- Hadoop Balancer源代码解读
前言 近期在做一些Hadoop运维的相关工作,发现了一个有趣的问题,我们公司的Hadoop集群磁盘占比数值參差不齐,高的接近80%.低的接近40%.并没有充分利用好上面的资源,可是balance的操作 ...
- Hadoop ->> HDFS(Hadoop Distributed File System)
HDFS全称是Hadoop Distributed File System.作为分布式文件系统,具有高容错性的特点.它放宽了POSIX对于操作系统接口的要求,可以直接以流(Stream)的形式访问文件 ...
- hadoop balancer
一.balancer是当hdfs集群中一些datanodes的存储要写满了或者有空白的新节点加入集群时,用于均衡hdfs集群磁盘使用量的一个工具.这个工具作为一个应用部署在集群中,可以由集群管理员在一 ...
- Hadoop hadoop balancer配置
hadoop版本:2.9.2 1.带宽的设置参数: dfs.datanode.balance.bandwidthPerSec 默认值 10m 2.datanode之间数据块的传输线程大小:dfs. ...
- (转)hadoop balancer(重新平衡)
借鉴:https://blog.csdn.net/mnasd/article/details/80369603?utm_source=blogxgwz2 参考文档: http://blog.csdn ...
- HDFS数据平衡
一.datanode之间的数据平衡 1.1.介绍 Hadoop 分布式文件系统(Hadoop Distributed FilSystem),简称 HDFS,被设计成适合运行在通用硬件上的分布式文件 ...
随机推荐
- 【C#-枚举】枚举的使用
枚举是用户定义的整数类型. namespace ConsoleApplication1 { /// <summary> /// 在枚举中使用一个整数值,来表示一天的阶段 /// 如:Tim ...
- sh_03_列表的数据统计
sh_03_列表的数据统计 name_list = ["张三", "李四", "王五", "王小二", "张三 ...
- python之timeit模块
timeit模块: timeit 模块定义了接受两个参数的 Timer 类.两个参数都是字符串. 第一个参数是你要计时的语句或者函数. 传递给 Timer 的第二个参数是为第一个参数语句构建环境的导入 ...
- idea中JSP页面不能访问静态资源(图片,js,css)
必须配置SpringMvc对访问静态资源的支持,idea默认就是在main/webapp 下的文件路径,要在web-info同级的resource文件下放置,JSP中 ${pageContext.re ...
- Apicloud_(项目)网上书城03_拓展模块实现
Apicloud_(项目)网上书城01_前端页面开发 传送门 Apicloud_(项目)网上书城02_后端数据获取 传送门 Apicloud_(项目)网上书城03_拓展模块实现 传送门 实现商品详情页 ...
- Jmeter -- 入门,基础操作
1. 添加线程组 设置线程组参数(线程数.准备时长.循环次数等): a)线程数:虚拟用户数.一个虚拟用户占用一个进程或线程.设置多少虚拟用户数在这里也就是设置多少个线程数. b)Ramp-Up Per ...
- JMH基准测试框架
jmh-gradle-plugin, 集成JMH基准测试框架和 Gradle 0 赞 0 评论 文章标签:Gradle JMH 基准 INT benchmark framework 帧 ...
- C++入门经典-例6.18-数组的动态分配,动态获得斐波那契数列
1:有时在获得一定的信息之前,我们并不确定数组的大小.动态分配数组则可以使用变量作为数组的大小,使数组的大小符合我们的要求. 2:科普一下斐波纳契数列:斐波那契数列指的是这样一个数列 1, 1, 2, ...
- lyf基础作业
include <stdio.h> include <stdlib.h> int main (void) { FILE * fp; int a[10]; int max=0; ...
- EBS 页面影藏“关于此页”
EBS环境: R12.1.3 问题:要影藏EBS登录页面左下角的“关于此页” 方法: 修改的配置文件参数:FND:诊断 , 由 是 改为 否 个性化自助定义 ,由 是 改为 否参数说明:‘FND:诊断 ...