Monte Carlo Policy Evaluation
Model-Based and Model-Free
In the previous several posts, we mainly talked about Model-Based Reinforcement Learning. The biggest assumption for Model-Based learning is the whole knowledge of the environment is given, but it is unrealistic in real life or even video games. I do believe unknown makes life (game) interesting. Personally, everytime I know what will happen in a game, I get rid of it! So, people like playing games with some uncertainties. That is what Model-Free Reinforcement Learning does: lean the unknown environment, and then come up with the best policy.
Two Task for Model-Free Learning
For Model-Based Learning,we have two tasks: Evaluation and Control. We use Dynamic Programming to evaluate a policy, while two algorithms called Policy Iteration and Value Iteration are used to extract the optimal policy. In Model-Free Learning, we have the same two tasks:
Evaluation: we need to estimate State-Value functions for every state, although Transition Matrices and Reward Function are not given.
Control: we need to find the best policy to solve the interesting game.
Monte Carlo Method in Daily Life
One of the algorithms for Evaluation is Monte Carlo Method. Probably the superior name 'Monte Carlo' is scaring, but you would feel comfortable while following my example below.
Assume our task is traveling from London to Toronto, and the policy is 'random walk'. we define travel distance and time as rewards. There are cities, towns, even villages on the map on which agents would randomly draw diverse trajectories from London to Toronto. Even it is possible that an agent arrives and departs some places more than once. But finally every agent will complete an episode when it arrives at Toronto, and then we can review paths, learning experience from trials.
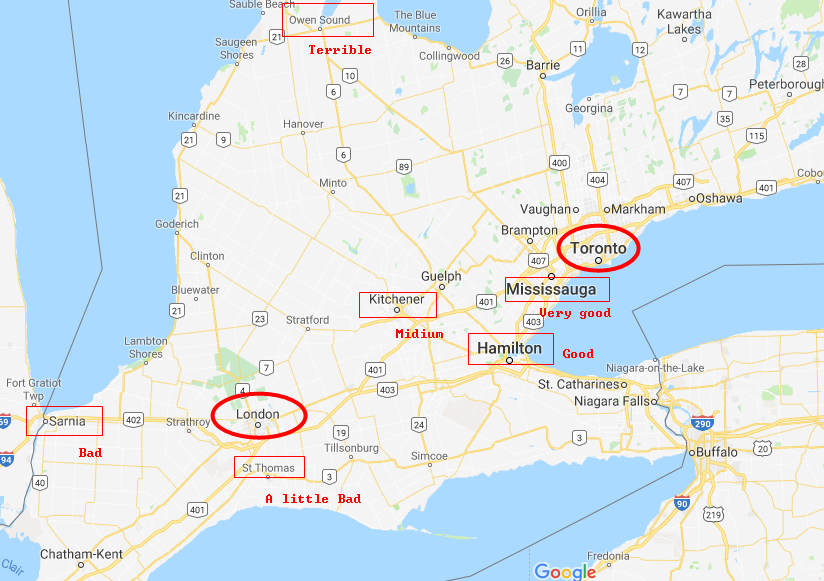
Finally, we will know goodnesses of being in every place on the map. Mississauga is a very good state for our task, but the state Owen Sound is terrible. The reason why we can get this conclusion is: states closed to the final state usually have great State-Value functions, because they tend to win the game soon. Episodes in our example that get to Mississauga have great probabilities getting to Toronto soon, so the Expectation of their State-Value functions is also high. On the other hand, the expectation of Owen Sound's State-Value function pretty low. That's why most people choose 401 Highway passing Mississauga to Toronto, but nobody go Owen Sound first. It's from daily life experience.
Definition of Monte Carlo Method
1. First-Visit Monte Carlo Evaluation Algorithm
Initialize:
a. π is the policy that needs to be evaluated;
b. V(St) is an arbitary State-Value function;
c. Counter matrix N(St), to record the appearance time of each state;
Repeat in loops:
a. Generate an episode from π
b. For each state s appearing in the episode for the first time, calculate new State-Value function V(St)
To avoid storing all returns or the sum of returns for all episodes, we transform the equation a little bit when we calculate the new State-Value function:
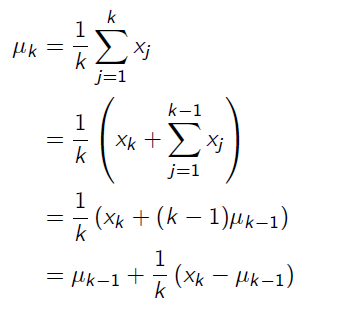
And we get the equation for updating State-Value function:
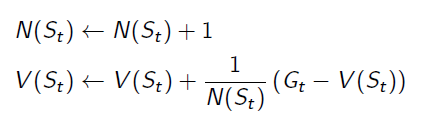
it can also be rewritten to:
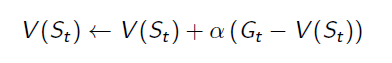
2. Every-Visit Monte Carlo Evaluation Algorithm
Initialize:
a. π is the policy that needs to be evaluated;
b. V(St) is an arbitary State-Value function;
c. Counter matrix N(St), to record the appearance time of each state;
Repeat in loops:
a. Generate an episode from π
b. For each state s appearing in the episode for every time, calculate new State-Value function V(St)
Population vs. Sample
A online video from MIT(Here we go) reminds me the idea of Population and Sample from Statistics. Population is quite like the whole knowledge on Model-Based learning, but getting samples is easier and more realistic in real life. Monte Carlo is similar to using the distribution of samples to do inference of the population.
Monte Carlo Policy Evaluation的更多相关文章
- 增强学习(四) ----- 蒙特卡罗方法(Monte Carlo Methods)
1. 蒙特卡罗方法的基本思想 蒙特卡罗方法又叫统计模拟方法,它使用随机数(或伪随机数)来解决计算的问题,是一类重要的数值计算方法.该方法的名字来源于世界著名的赌城蒙特卡罗,而蒙特卡罗方法正是以概率为基 ...
- 蒙特卡罗方法、蒙特卡洛树搜索(Monte Carlo Tree Search,MCTS)初探
1. 蒙特卡罗方法(Monte Carlo method) 0x1:从布丰投针实验说起 - 只要实验次数够多,我就能直到上帝的意图 18世纪,布丰提出以下问题:设我们有一个以平行且等距木纹铺成的地板( ...
- Monte Carlo Control
Problem of State-Value Function Similar as Policy Iteration in Model-Based Learning, Generalized Pol ...
- Introduction to Monte Carlo Tree Search (蒙特卡罗搜索树简介)
Introduction to Monte Carlo Tree Search (蒙特卡罗搜索树简介) 部分翻译自“Monte Carlo Tree Search and Its Applicati ...
- 强化学习读书笔记 - 05 - 蒙特卡洛方法(Monte Carlo Methods)
强化学习读书笔记 - 05 - 蒙特卡洛方法(Monte Carlo Methods) 学习笔记: Reinforcement Learning: An Introduction, Richard S ...
- Programming a Hearthstone agent using Monte Carlo Tree Search(chapter one)
Markus Heikki AnderssonHåkon HelgesenHesselberg Master of Science in Computer Science Submission dat ...
- Ⅳ Monte Carlo Methods
Dictum: Nutrition books in the world. There is no book in life, there is no sunlight; wisdom withou ...
- Monte Carlo方法简介(转载)
Monte Carlo方法简介(转载) 今天向大家介绍一下我现在主要做的这个东东. Monte Carlo方法又称为随机抽样技巧或统计实验方法,属于计算数学的一个分支,它是在上世纪四十年代 ...
- PRML读书会第十一章 Sampling Methods(MCMC, Markov Chain Monte Carlo,细致平稳条件,Metropolis-Hastings,Gibbs Sampling,Slice Sampling,Hamiltonian MCMC)
主讲人 网络上的尼采 (新浪微博: @Nietzsche_复杂网络机器学习) 网络上的尼采(813394698) 9:05:00 今天的主要内容:Markov Chain Monte Carlo,M ...
随机推荐
- AlphaStar: Mastering the Real-Time Strategy Game StarCraft II 博客要点
original blog: https://deepmind.com/blog/alphastar-mastering-real-time-strategy-game-starcraft-ii S ...
- Python(3) 进制转换
2进制 :0b8进制: 0o16进制: 0x10进制:原来的数据 进制转换:bin() 方法:转化为 2进制 >>> bin(10)'0b1010'oct() 方法:转化为 8进制& ...
- Flask【第1篇】:Flask介绍
Flask入门 一.Flask介绍(轻量级的框架,非常快速的就能把程序搭建起来) Flask是一个基于Python开发并且依赖jinja2模板和Werkzeug WSGI服务的一个微型框架,对于Wer ...
- 35.ES6语法介绍——2019年12月24日
2019年12月24日16:22:24 2019年10月09日12:04:44 1. ES6介绍 1.1 新的 Javascript 语法标准 --2015年6月正式发布 --使用babel语法转换器 ...
- B1016. 部分 A+B
题目描述 正整数A的"D(为1位整数)部分"定义由A中所有D组成的新整数P,例如给定A=3862767,D=6,则A的"6部分" P是66,因为A中有2个6,现 ...
- LeetCode--098--验证搜索二叉树(python)
给定一个二叉树,判断其是否是一个有效的二叉搜索树. 假设一个二叉搜索树具有如下特征: 节点的左子树只包含小于当前节点的数.节点的右子树只包含大于当前节点的数.所有左子树和右子树自身必须也是二叉搜索树. ...
- lua脚本入门
在网上下载一些工程,里边常常存在.lua .sh .in .cmake .bat等文件 今天专门查了一下相关文件的作用 .sh 通常是linux.unix系统下的脚本文件(文本文件),用于调用默认的s ...
- Ubuntu 16.04下使用docker部署rabbitmq
(以下docker相关的命令,需要在root用户环境下或通过sudo提升权限来进行操作.) 1.拉取rabbimq镜像到本地 docker pull rabbitmq 2. Docker运行rabbi ...
- sift特征点检测和特征数据库的建立
类似于ORBSLAM中的ORB.txt数据库. https://blog.csdn.net/lingyunxianhe/article/details/79063547 ORBvoc.txt是怎么 ...
- kali语言设置
1.直接在终端命令 dpkg-reconfigure locales 然后按需选择支持字符编码:en_US.UTF-8(英文).zh_CN.GBK(中文).zh_CN.UTF-8(中文) (注:选择字 ...