Python之-爬虫
1、得到页面的HTML代码


第一个参数是URL
第二三个参数可以不传送,数据和时间
2、request请求
HTTP是基于请求和应答的,客户端发出请求,服务端做出响应,所以urllib2创建一个request对象,代表发送的HTTP请求。

3、数据传送POST和GET
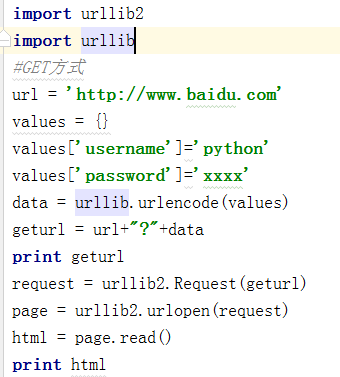
GET方式
直接把参数写到URL当中。
和我们平常GET访问方式一模一样,用一个问号连接传送的数据
POST方式

4、Headers
有些网站不会同意程序直接用上面的方式进行访问,如果识别有问题,那么站点根本不会响应,所以为了完全模拟浏览器的工作,我们需要设置一些Headers 的属性。

5、异常处理
【1】URLEeeor
产生的原因:
网络无连接
服务器不存在
连接不到服务器
在代码中,我们需要用try-except语句来包围并捕获相应的异常

【2】HTTPEeeor
每个来自服务器的HTTP应答都包含一个数值的状态码。有时候,状态码表明服务器不能满足我们做出的请求。默认的handlers将会帮我们处理一些应答(例如,应答是一个重定向,要求客户端从不同的URL抓取资源,urllib2将会替你处理好)。但是总有一些不能处理好,urloprn将会抛出一个HTTPError异常。典型的异常有404(页面丢失),403(请求被禁止),401(要求验证)


注意,HTTPError一定要放在最前面进行捕获。因为HTTPError是URLError的子集,不然的话会一直捕获到的是URLError

6、Cookie
Cookie,指某些网站为了辨别用户身份、进行session跟踪而储存在用户本地终端上的数据(通常经过加密)
比如说有些网站需要登录后才能访问某个页面,在登录之前,你想抓取某个页面内容是不允许的。那么我们可以利用Urllib2库保存我们登录的Cookie,然后再抓取其他页面就达到目的了。
但是URLopen只接受三个参数:url、data、timeout
urllib2库.官方文档翻译 - 莫利斯安的博客 - 博客频道 - CSDN.NET http://blog.csdn.net/u014343243/article/details/49308043
Python之-爬虫的更多相关文章
- Python简单爬虫入门三
我们继续研究BeautifulSoup分类打印输出 Python简单爬虫入门一 Python简单爬虫入门二 前两部主要讲述我们如何用BeautifulSoup怎去抓取网页信息以及获取相应的图片标题等信 ...
- Ubuntu下配置python完成爬虫任务(笔记一)
Ubuntu下配置python完成爬虫任务(笔记一) 目标: 作为一个.NET汪,是时候去学习一下Linux下的操作了.为此选择了python来边学习Linux,边学python,熟能生巧嘛. 前期目 ...
- Python简单爬虫入门二
接着上一次爬虫我们继续研究BeautifulSoup Python简单爬虫入门一 上一次我们爬虫我们已经成功的爬下了网页的源代码,那么这一次我们将继续来写怎么抓去具体想要的元素 首先回顾以下我们Bea ...
- [Python] 网络爬虫和正则表达式学习总结
以前在学校做科研都是直接利用网上共享的一些数据,就像我们经常说的dataset.beachmark等等.但是,对于实际的工业需求来说,爬取网络的数据是必须的并且是首要的.最近在国内一家互联网公司实习, ...
- python简易爬虫来实现自动图片下载
菜鸟新人刚刚入住博客园,先发个之前写的简易爬虫的实现吧,水平有限请轻喷. 估计利用python实现爬虫的程序网上已经有太多了,不过新人用来练手学习python确实是个不错的选择.本人借鉴网上的部分实现 ...
- GJM : Python简单爬虫入门(二) [转载]
感谢您的阅读.喜欢的.有用的就请大哥大嫂们高抬贵手"推荐一下"吧!你的精神支持是博主强大的写作动力以及转载收藏动力.欢迎转载! 版权声明:本文原创发表于 [请点击连接前往] ,未经 ...
- Python分布式爬虫原理
转载 permike 原文 Python分布式爬虫原理 首先,我们先来看看,如果是人正常的行为,是如何获取网页内容的. (1)打开浏览器,输入URL,打开源网页 (2)选取我们想要的内容,包括标题,作 ...
- Python 网页爬虫 & 文本处理 & 科学计算 & 机器学习 & 数据挖掘兵器谱(转)
原文:http://www.52nlp.cn/python-网页爬虫-文本处理-科学计算-机器学习-数据挖掘 曾经因为NLTK的缘故开始学习Python,之后渐渐成为我工作中的第一辅助脚本语言,虽然开 ...
- 关于Python网络爬虫实战笔记③
Python网络爬虫实战笔记③如何下载韩寒博客文章 Python网络爬虫实战笔记③如何下载韩寒博客文章 target:下载全部的文章 1. 博客列表页面规则 也就是, http://blog.sina ...
- 关于Python网络爬虫实战笔记①
python网络爬虫项目实战笔记①如何下载韩寒的博客文章 python网络爬虫项目实战笔记①如何下载韩寒的博客文章 1. 打开韩寒博客列表页面 http://blog.sina.com.cn/s/ar ...
随机推荐
- HashMap的底层原理 cr:csdn:zhangshixi
1. HashMap概述: HashMap是基于哈希表的Map接口的非同步实现.此实现提供所有可选的映射操作,并允许使用null值和null键.此类不保证映射的顺序,特别是它不保证该顺序恒久不变 ...
- html标签内部简单加js 一维数组求最大值 最小值两个值位置和数字金字塔图形
html标签内部,简单加js <a href=""></a><!DOCTYPE html PUBLIC "-//W3C//DTD XHTM ...
- python实现计时器(装饰器)
1.写一个装饰器,查看函数执行的时间 import time # 装饰器run_time,@run_time加在谁头上,谁就是参数fundef run_time(fun): start_time = ...
- SQL:REGEXP
作为一个更为复杂的示例,正则表达式B[an]*s匹配下述字符串中的任何一个:Bananas,Baaaaas,Bs,以及以B开始.以s结束.并在其中包含任意数目a或n字符的任何其他字符串. 以下是可用于 ...
- Makefile之自动化变量
makefile自动化变量在大型项目的Makefile使用的太普遍了,如果你看不懂自动化变量,开源项目的makefile你是看不下去的. 以往总是看到一些项目的makefile,总是要翻gnu的Mak ...
- 嵌入式C语言3.5 关键字---运算符
1. 算数运算符 + - A +/- B 要求A,B数据类型一致 * 乘法 / 除法 %取模 乘法CPU可能需要多个周期,甚至需要利用软件的模拟方法来实 ...
- Linux下的tar压缩解压命令
tar 这五个是独立的命令,压缩解压都要用到其中一个,可以和别的命令连用但只能用其中一个. -c: 建立压缩档案-x:解压-t:查看内容-r:向压缩归档文件末尾追加文件-u:更新原压缩包中的文件 下 ...
- jvm学习(1) 总体篇
1.1 Java体系构成 JAVA体系包括四个方面: JAVA编程语言,编辑的文件为Java源代码,文件格式为(.java): JAVA类文件格式,编译后文件格式为(.class): JA ...
- mySQL部分疑问和小结(orale)
2015/10/15 1.mysql语句: ALTER table scfz_xewp add BGR varchar(255) after KYR 2.创建触发器时: --/ CREATE D ...
- Java中的HashMap的2种遍历方式比较
首先我们准备数据,准备一个map Map<String, String> map = new HashMap<String, String>(); for (int i = 0 ...