手把手教你搭建一个 Elasticsearch 集群
为何要搭建 Elasticsearch 集群
凡事都要讲究个为什么。在搭建集群之前,我们首先先问一句,为什么我们需要搭建集群?它有什么优势呢?
高可用性
Elasticsearch 作为一个搜索引擎,我们对它的基本要求就是存储海量数据并且可以在非常短的时间内查询到我们想要的信息。所以第一步我们需要保证的就是 Elasticsearch 的高可用性,什么是高可用性呢?它通常是指,通过设计减少系统不能提供服务的时间。假设系统一直能够提供服务,我们说系统的可用性是 100%。如果系统在某个时刻宕掉了,比如某个网站在某个时间挂掉了,那么就可以它临时是不可用的。所以,为了保证 Elasticsearch 的高可用性,我们就应该尽量减少 Elasticsearch 的不可用时间。
那么怎样提高 Elasticsearch 的高可用性呢?这时集群的作用就体现出来了。假如 Elasticsearch 只放在一台服务器上,即单机运行,假如这台主机突然断网了或者被攻击了,那么整个 Elasticsearch 的服务就不可用了。但如果改成 Elasticsearch 集群的话,有一台主机宕机了,还有其他的主机可以支撑,这样就仍然可以保证服务是可用的。
那可能有的小伙伴就会说了,那假如一台主机宕机了,那么不就无法访问这台主机的数据了吗?那假如我要访问的数据正好存在这台主机上,那不就获取不到了吗?难道其他的主机里面也存了一份一模一样的数据?那这岂不是很浪费吗?
为了解答这个问题,这里就引出了 Elasticsearch 的信息存储机制了。首先解答上面的问题,一台主机宕机了,这台主机里面存的数据依然是可以被访问到的,因为在其他的主机上也有备份,但备份的时候也不是整台主机备份,是分片备份的,那这里就又引出了一个概念——分片。
分片,英文叫做 Shard,顾名思义,分片就是对数据切分成了多个部分。我们知道 Elasticsearch 中一个索引(Index)相当于是一个数据库,如存某网站的用户信息,我们就建一个名为 user 的索引。但索引存储的时候并不是整个存一起的,它是被分片存储的,Elasticsearch 默认会把一个索引分成五个分片,当然这个数字是可以自定义的。分片是数据的容器,数据保存在分片内,分片又被分配到集群内的各个节点里。当你的集群规模扩大或者缩小时, Elasticsearch 会自动的在各节点中迁移分片,使得数据仍然均匀分布在集群里,所以相当于一份数据被分成了多份并保存在不同的主机上。
那这还是没解决问题啊,如果一台主机挂掉了,那么这个分片里面的数据不就无法访问了?别的主机都是存储的其他的分片。其实是可以访问的,因为其他主机存储了这个分片的备份,叫做副本,这里就引出了另外一个概念——副本。
副本,英文叫做 Replica,同样顾名思义,副本就是对原分片的复制,和原分片的内容是一样的,Elasticsearch 默认会生成一份副本,所以相当于是五个原分片和五个分片副本,相当于一份数据存了两份,并分了十个分片,当然副本的数量也是可以自定义的。这时我们只需要将某个分片的副本存在另外一台主机上,这样当某台主机宕机了,我们依然还可以从另外一台主机的副本中找到对应的数据。所以从外部来看,数据结果是没有任何区别的。
一般来说,Elasticsearch 会尽量把一个索引的不同分片存储在不同的主机上,分片的副本也尽可能存在不同的主机上,这样可以提高容错率,从而提高高可用性。
但这时假如你只有一台主机,那不就没办法了吗?分片和副本其实是没意义的,一台主机挂掉了,就全挂掉了。
健康状态
针对一个索引,Elasticsearch 中其实有专门的衡量索引健康状况的标志,分为三个等级:
- green,绿色。这代表所有的主分片和副本分片都已分配。你的集群是 100% 可用的。
- yellow,黄色。所有的主分片已经分片了,但至少还有一个副本是缺失的。不会有数据丢失,所以搜索结果依然是完整的。不过,你的高可用性在某种程度上被弱化。如果更多的分片消失,你就会丢数据了。所以可把 yellow 想象成一个需要及时调查的警告。
- red,红色。至少一个主分片以及它的全部副本都在缺失中。这意味着你在缺少数据:搜索只能返回部分数据,而分配到这个分片上的写入请求会返回一个异常。
如果你只有一台主机的话,其实索引的健康状况也是 yellow,因为一台主机,集群没有其他的主机可以防止副本,所以说,这就是一个不健康的状态,因此集群也是十分有必要的。
存储空间
另外,既然是群集,那么存储空间肯定也是联合起来的,假如一台主机的存储空间是固定的,那么集群它相对于单个主机也有更多的存储空间,可存储的数据量也更大。
所以综上所述,我们需要一个集群!
详细了解 Elasticsearch 集群
接下来我们再来了解下集群的结构是怎样的。
首先我们应该清楚多台主机构成了一个集群,每台主机称作一个节点(Node)。
如图就是一个三节点的集群:
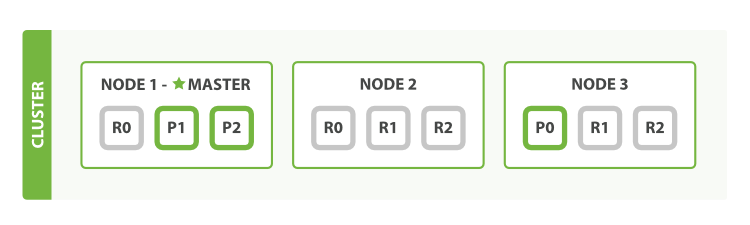
在图中,每个 Node 都有三个分片,其中 P 开头的代表 Primary 分片,即主分片,R 开头的代表 Replica 分片,即副本分片。所以图中主分片 1、2,副本分片 0 储存在 1 号节点,副本分片 0、1、2 储存在 2 号节点,主分片 0 和副本分片 1、2 储存在 3 号节点,一共是 3 个主分片和 6 个副本分片。同时我们还注意到 1 号节点还有个 MASTER 的标识,这代表它是一个主节点,它相比其他的节点更加特殊,它有权限控制整个集群,比如资源的分配、节点的修改等等。
这里就引出了一个概念就是节点的类型,我们可以将节点分为这么四个类型:
- 主节点:即 Master 节点。主节点的主要职责是和集群操作相关的内容,如创建或删除索引,跟踪哪些节点是群集的一部分,并决定哪些分片分配给相关的节点。稳定的主节点对集群的健康是非常重要的。默认情况下任何一个集群中的节点都有可能被选为主节点。索引数据和搜索查询等操作会占用大量的cpu,内存,io资源,为了确保一个集群的稳定,分离主节点和数据节点是一个比较好的选择。虽然主节点也可以协调节点,路由搜索和从客户端新增数据到数据节点,但最好不要使用这些专用的主节点。一个重要的原则是,尽可能做尽量少的工作。
- 数据节点:即 Data 节点。数据节点主要是存储索引数据的节点,主要对文档进行增删改查操作,聚合操作等。数据节点对 CPU、内存、IO 要求较高,在优化的时候需要监控数据节点的状态,当资源不够的时候,需要在集群中添加新的节点。
- 负载均衡节点:也称作 Client 节点,也称作客户端节点。当一个节点既不配置为主节点,也不配置为数据节点时,该节点只能处理路由请求,处理搜索,分发索引操作等,从本质上来说该客户节点表现为智能负载平衡器。独立的客户端节点在一个比较大的集群中是非常有用的,他协调主节点和数据节点,客户端节点加入集群可以得到集群的状态,根据集群的状态可以直接路由请求。
- 预处理节点:也称作 Ingest 节点,在索引数据之前可以先对数据做预处理操作,所有节点其实默认都是支持 Ingest 操作的,也可以专门将某个节点配置为 Ingest 节点。
以上就是节点几种类型,一个节点其实可以对应不同的类型,如一个节点可以同时成为主节点和数据节点和预处理节点,但如果一个节点既不是主节点也不是数据节点,那么它就是负载均衡节点。具体的类型可以通过具体的配置文件来设置。
怎样搭建 Elasticsearch 集群
好,接下来我们就来动手搭建一个集群吧。
这里我一共拥有七台 Linux 主机,系统是 Ubuntu 16.04,都连接在一个内网中,IP 地址为:
10.0.0.4
10.0.0.5
10.0.0.6
10.0.0.7
10.0.0.8
10.0.0.9
10.0.0.10
每台主机的存储空间是 1TB,内存是 13GB。
下面我们来一步步介绍如何用这几台主机搭建一个 Elasticsearch 集群,这里使用的 Elasticsearch 版本是 6.3.2,另外我们还需要安装 Kibana 用来可视化监控和管理 Elasticsearch 的相关配置和数据,使得集群的管理更加方便。
环境配置如下所示:
|
名称 |
内容 |
|---|---|
|
主机台数 |
7 |
|
主机内存 |
13GB |
|
主机系统 |
Ubuntu 16.04 |
|
存储空间 |
1TB |
|
Elasticsearch 版本 |
6.3.2 |
|
Java 版本 |
1.8 |
|
Kibana 版本 |
6.3.2 |
安装 Java
Elasticsearch 是基于 Lucene 的,而 Lucene 又是基于 Java 的。所以第一步我们就需要在每台主机上安装 Java。
首先更新 Apt 源:
sudo apt-get update
然后安装 Java:
sudo apt-get install default-jre
安装好了之后可以检查下 Java 的版本:
java -version
这里的版本是 1.8,类似输出如下:
openjdk version "1.8.0_171"
OpenJDK Runtime Environment (build 1.8.0_171-8u171-b11-0ubuntu0.16.04.1-b11)
OpenJDK 64-Bit Server VM (build 25.171-b11, mixed mode)
如果看到上面的内容就说明安装成功了。
注意一定要每台主机都要安装。
安装 Elasticsearch
接下来我们来安装 Elasticsearch,同样是每台主机都需要安装。
首先需要添加 Apt-Key:
wget -qO - https://artifacts.elastic.co/GPG-KEY-elasticsearch | sudo apt-key add -
然后添加 Elasticsearch 的 Repository 定义:
echo "deb https://artifacts.elastic.co/packages/6.x/apt stable main" | sudo tee -a /etc/apt/sources.list.d/elastic-6.x.list
接下来安装 Elasticsearch 即可:
sudo apt-get update
sudo apt-get install elasticsearch
运行完毕之后我们就完成了 Elasticsearch 的安装,注意还是要每台主机都要安装。
配置 Elasticsearch
这时我们只是每台主机都安装好了 Elasticsearch,接下来我们还需要将它们联系在一起构成一个集群。
安装完之后,Elasticsearch 的配置文件是 /etc/elasticsearch/elasticsearch.yml,接下来让我们编辑一下配置文件:
- 集群的名称
通过 cluster.name 可以配置集群的名称,集群是一个整体,因此名称都要一致,所有主机都配置成相同的名称,配置示例:
cluster.name: germey-es-clusters
- 节点的名称
通过 node.name 可以配置每个节点的名称,每个节点都是集群的一部分,每个节点名称都不要相同,可以按照顺序编号,配置示例:
node.name: es-node-1
其他的主机可以配置为 es-node-2、es-node-3 等。
- 是否有资格成为主节点
通过 node.master 可以配置该节点是否有资格成为主节点,如果配置为 true,则主机有资格成为主节点,配置为 false 则主机就不会成为主节点,可以去当数据节点或负载均衡节点。注意这里是有资格成为主节点,不是一定会成为主节点,主节点需要集群经过选举产生。这里我配置所有主机都可以成为主节点,因此都配置为 true,配置示例:
node.master: true
- 是否是数据节点
通过 node.data 可以配置该节点是否为数据节点,如果配置为 true,则主机就会作为数据节点,注意主节点也可以作为数据节点,当 node.master 和 node.data 均为 false,则该主机会作为负载均衡节点。这里我配置所有主机都是数据节点,因此都配置为 true,配置示例:
node.data: true
- 数据和日志路径
通过 path.data 和 path.logs 可以配置 Elasticsearch 的数据存储路径和日志存储路径,可以指定任意位置,这里我指定存储到 1T 硬盘对应的路径下,另外注意一下写入权限问题,配置示例:
path.data: /datadrive/elasticsearch/data
path.logs: /datadrive/elasticsearch/logs
- 设置访问的地址和端口
我们需要设定 Elasticsearch 运行绑定的 Host,默认是无法公开访问的,如果设置为主机的公网 IP 或 0.0.0.0 就是可以公开访问的,这里我们可以都设置为公开访问或者部分主机公开访问,如果是公开访问就配置为:
network.host: 0.0.0.0
如果不想被公开访问就不用配置。
另外还可以配置访问的端口,默认是 9200:
http.port: 9200
- 集群地址设置
通过 discovery.zen.ping.unicast.hosts 可以配置集群的主机地址,配置之后集群的主机之间可以自动发现,这里我配置的是内网地址,配置示例:
discovery.zen.ping.unicast.hosts: ["10.0.0.4", "10.0.0.5", "10.0.0.6", "10.0.0.7", "10.0.0.8", "10.0.0.9", "10.0.0.10"]
这里请改成你的主机对应的 IP 地址。
- 节点数目相关配置
为了防止集群发生“脑裂”,即一个集群分裂成多个,通常需要配置集群最少主节点数目,通常为 (可成为主节点的主机数目 / 2) + 1,例如我这边可以成为主节点的主机数目为 7,那么结果就是 4,配置示例:
discovery.zen.minimum_master_nodes: 4
另外还可以配置当最少几个节点回复之后,集群就正常工作,这里我设置为 4,可以酌情修改,配置示例:
gateway.recover_after_nodes: 4
其他的暂时先不需要配置,保存即可。注意每台主机都需要配置。
启动 Elasticsearch
配置完成之后就可以在每台主机上分别启动 Elasticsearch 服务了,命令如下:
sudo systemctl daemon-reload
sudo systemctl enable elasticsearch.service
sudo systemctl start elasticsearch.service
所有主机都启动之后,我们在任意主机上就可以查看到集群状态了,命令行如下:
curl -XGET 'http://localhost:9200/_cluster/state?pretty'
类似的输出如下:
{
"cluster_name": "germey-es-clusters",
"compressed_size_in_bytes": 20799,
"version": 658,
"state_uuid": "a64wCwPnSueKRtVuKx8xRw",
"master_node": "73BQvOC2TpSXcr-IXBcDdg",
"blocks": {},
"nodes": {
"I2M80AP-T7yVP_AZPA0bpA": {
"name": "es-node-1",
"ephemeral_id": "KpCG4jNvTUGKNHNwKKoMrA",
"transport_address": "10.0.0.4:9300",
"attributes": {
"ml.machine_memory": "7308464128",
"ml.max_open_jobs": "20",
"xpack.installed": "true",
"ml.enabled": "true"
}
},
"73BQvOC2TpSXcr-IXBcDdg": {
"name": "es-node-7",
"ephemeral_id": "Fs9v2XTASnGbqrM8g7IhAQ",
"transport_address": "10.0.0.10:9300",
"attributes": {
"ml.machine_memory": "14695202816",
"ml.max_open_jobs": "20",
"xpack.installed": "true",
"ml.enabled": "true"
}
},
....
可以看到这里输出了集群的相关信息,同时 nodes 字段里面包含了每个节点的详细信息,这样一个基本的集群就构建完成了。
安装 Kibana
接下来我们需要安装一个 Kibana 来帮助可视化管理 Elasticsearch,依然还是通过 Apt 安装,只需要任意一台主机安装即可,因为集群是一体的,所以 Kibana 在任意一台主机只要能连接到 Elasticsearch 即可,安装命令如下:
sudo apt-get install kibana
安装之后修改 /etc/kibana/kibana.yml,设置公开访问和绑定的端口:
server.port: 5601
server.host: "0.0.0.0"
然后启动服务:
sudo systemctl daemon-reload
sudo systemctl enable kibana.service
sudo systemctl start kibana.service
这样我们可以在浏览器输入该台主机的 IP 加端口,查看 Kibana 管理页面了,类似如下:

这样 Kibana 可视化管理就配置成功了。
配置认证
现在集群已经初步搭建完成了,但是现在集群很危险,如果我们配置了可公网访问,那么它是可以被任何人操作的,比如储存数据,增删节点等,这是非常危险的,所以我们必须要设置访问权限。
在 Elasticsearch 中,配置认证是通过 X-Pack 插件实现的,幸运的是,我们不需要额外安装了,在 Elasticsearch 6.3.2 版本中,该插件是默认集成到 Elasticsearch 中的,所以我们只需要更改一部分设置就可以了。
首先我们需要升级 License,只有修改了高级版 License 才能使用 X-Pack 的权限认证功能。
在 Kibana 中访问 Management -> Elasticsearch -> License Management,点击右侧的升级 License 按钮,可以免费试用 30 天的高级 License,升级完成之后页面会显示如下:

另外还可以使用 API 来更新 License,详情可以参考官方文档:https://www.elastic.co/guide/en/elasticsearch/reference/6.2/update-license.html。
然后每台主机需要修改 /etc/elasticsearch/elasticsearch.yml 文件,开启 Auth 认证功能:
xpack.security.enabled: true
随后设置 elastic、kibana、logstash_system 三个用户的密码,任意一台主机修改之后,一台修改,多台生效,命令如下:
/usr/share/elasticsearch/bin/elasticsearch-setup-passwords interactive
运行之后会依次提示设置这三个用户的密码并确认,一共需要输入六次密码,完成之后就成功设置好了密码了。
修改完成之后重启 Elasticsearch 和 Kibana 服务:
sudo systemctl restart elasticsearch.service
sudo systemctl restart kibana.service
这时再访问 Kibana 就会跳转到登录页面了:

可以使用 elastic 用户登录,它的角色是超级管理员,登录之后就可以重新进入 Kibana 的管理页面。
我们还可以自行修改和添加账户,在 Management -> Security -> User/Roles 里面:

例如这里添加一个超级管理员的账户:
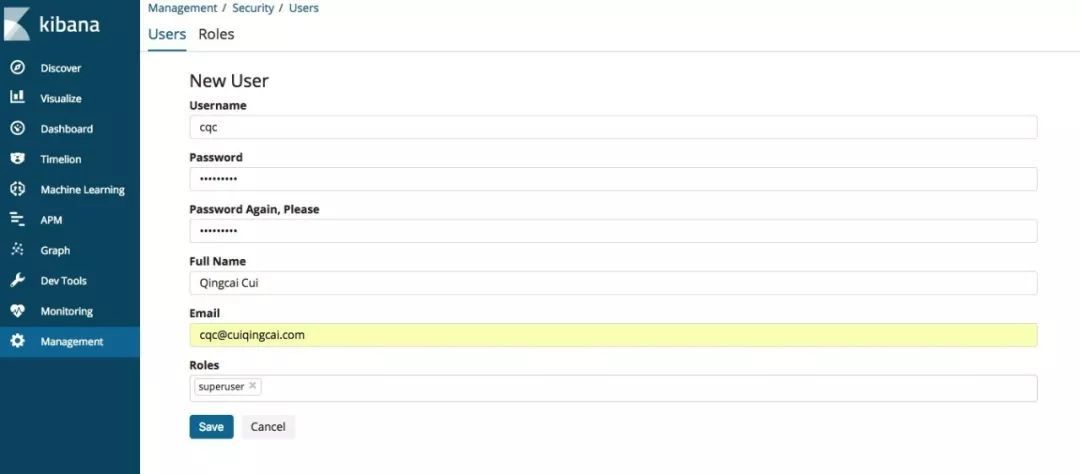
这样以后我们就可以使用新添加的用户来登录和访问了。
另外修改权限认证之后,Elasticsearch 也不能直接访问了,我们也必须输入用户密码才可以访问和调用其 API,保证了安全性。
开启内存锁定
系统默认会进行内存交换,这样会导致 Elasticsearch 的性能变差,我们查看下内存锁定状态,在任意一台主机上的访问 http://ip:port/_nodes?filter_path=**.mlockall:
可以看到如下结果:
{
"nodes": {
"73BQvOC2TpSXcr-IXBcDdg": {
"process": {
"mlockall": false
}
},
"9tRr4nFDT_2rErLLQB2dIQ": {
"process": {
"mlockall": false
}
},
"hskSDv_JQlCUnjp_INI8Kg": {
"process": {
"mlockall": false
}
},
"LgaRuqXBTZaBdDGAktFWJA": {
"process": {
"mlockall": false
}
},
"ZcsZgowERzuvpqVbYOgOEA": {
"process": {
"mlockall": false
}
},
"I2M80AP-T7yVP_AZPA0bpA": {
"process": {
"mlockall": false
}
},
"_mSmfhUtQiqhzTKZ7u75Dw": {
"process": {
"mlockall": true
}
}
}
}
这代表内存交换没有开启,会影响 Elasticsearch 的性能,所以我们需要开启内存物理地址锁定,每台主机需要修改 /etc/elasticsearch/elasticsearch.yml 文件,修改如下配置:
bootstrap.memory_lock: true
但这样修改之后重新启动是会报错的,Elasticsearch 无法正常启动,查看日志,报错如下:
[1] bootstrap checks failed
[1]: memory locking requested for elasticsearch process but memory is not locked
这里需要修改两个地方,第一个是 /etc/security/limits.conf,添加如下内容:
* soft nofile 65536
* hard nofile 65536
* soft nproc 32000
* hard nproc 32000
* hard memlock unlimited
* soft memlock unlimited
另外还需要修改 /etc/systemd/system.conf,修改如下内容:
DefaultLimitNOFILE=65536
DefaultLimitNPROC=32000
DefaultLimitMEMLOCK=infinity
详细的解释可以参考:https://segmentfault.com/a/1190000014891856。
修改之后重启 Elasticsearch 服务:
sudo systemctl restart elasticsearch.service
重新访问刚才的地址,即可发现每台主机的物理地址锁定都被打开了:
{
"nodes": {
"73BQvOC2TpSXcr-IXBcDdg": {
"process": {
"mlockall": true
}
},
"9tRr4nFDT_2rErLLQB2dIQ": {
"process": {
"mlockall": true
}
},
"hskSDv_JQlCUnjp_INI8Kg": {
"process": {
"mlockall": true
}
},
"LgaRuqXBTZaBdDGAktFWJA": {
"process": {
"mlockall": true
}
},
"ZcsZgowERzuvpqVbYOgOEA": {
"process": {
"mlockall": true
}
},
"I2M80AP-T7yVP_AZPA0bpA": {
"process": {
"mlockall": true
}
},
"_mSmfhUtQiqhzTKZ7u75Dw": {
"process": {
"mlockall": true
}
}
}
}
这样我们就又解决了性能的问题。
安装分词插件
另外还推荐安装中文分词插件,这样可以对中文进行全文索引,安装命令如下:
sudo /usr/share/elasticsearch/bin/elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v6.3.2/elasticsearch-analysis-ik-6.3.2.zip
安装完之后需要重启 Elasticsearch 服务:
sudo systemctl restart elasticsearch.service
主机监控
到此为止,我们的 Elasticsearch 集群就搭建完成了。
最后我们看下 Kibana 的部分功能,看下整个 Elasticsearch 有没有在正常工作。
访问 Kibana,打开 Management -> Elasticsearch ->Index Management,即可看到当前有的一些索引和状态:

打开 Monitoring,可以查看 Elasticsearch 和 Kibana 的状态:

进一步点击 Nodes,可以查看各个节点的状态:

打开任意节点,可以查看当前资源状况变化:

另外还有一些其他的功能如可视化、图表、搜索等等,这里就不再一一列举了,更多功能可以详细了解 Kibana。
以上都是自己在安装过程中的记录和趟过的坑,如有疏漏,还望指正。
还有更多的 Elasticsearch 相关的内容可以参考官方文档:https://www.elastic.co/guide/index.html。
参考资料
- https://www.elastic.co/guide/en/x-pack/current/security-getting-started.html
- https://segmentfault.com/a/1190000014891856
- https://blog.csdn.net/a19860903/article/details/72467996
- https://logz.io/blog/elasticsearch-cluster-tutorial/
- https://es.xiaoleilu.com/020_Distributed_Cluster/30_Scale_more.html
- https://blog.csdn.net/archer119/article/details/76589189
手把手教你搭建一个 Elasticsearch 集群的更多相关文章
- 手把手教你搭建一个Elasticsearch集群
一.为何要搭建 Elasticsearch 集群 凡事都要讲究个为什么.在搭建集群之前,我们首先先问一句,为什么我们需要搭建集群?它有什么优势呢? (1)高可用性 Elasticsearch 作为一个 ...
- 手把手教你:将 ClickHouse 集群迁至云上
前言 随着云上 ClickHouse 服务完善,越来越多的用户将自建 ClickHouse 服务迁移至云上.对于不同数据规模,我们选择不同的方案: 对于数据量比较小的表,通常小于10GB 情况下,可以 ...
- 用Python手把手教你搭建一个web框架-flask微框架!
在之前的文章当中,小编已经教过大家怎么搭建一个Django框架,今天我们来探索另外的一种框架的搭建,这个框架就是web框架-flask微框架啦!首先我们带着以下的几个问题来阅读本文: 1.flask是 ...
- 单机简单搭建一个kafka集群(没有进行内核参数和JVM的调优)
1.JDK安装 在我的部署单节点kafka的博客里有相关的方法.(https://www.cnblogs.com/ToBeExpert/p/9789486.html )zookeeper和kafka的 ...
- 高性能高并发网站架构,教你搭建Redis5缓存集群
一.Redis集群介绍 Redis真的是一个优秀的技术,它是一种key-value形式的NoSQL内存数据库,由ANSI C编写,遵守BSD协议.支持网络.可基于内存亦可持久化的日志型.Key-Val ...
- 『原创』手把手教你搭建一个实用的油耗App(一)
前言: 入行快10年,有点积蓄,三年前买了代步车.于是乎,汽车油耗开销就成了每个月都必须关注的问题.三年来,用过了无数油耗记录软件,比如最知名的“小熊油耗”,从第一次用,一直到最新一版,感觉越来越“臃 ...
- 手把手教你搭建一个跟vue官方同款文档(vuepress)
前言 VuePress 由两部分组成:第一部分是一个极简静态网站生成器 (opens new window),它包含由 Vue 驱动的主题系统和插件 API,另一个部分是为书写技术文档而优化的默认主题 ...
- 2.使用Helm构建ElasticSearch集群
作者 微信:tangy8080 电子邮箱:914661180@qq.com 更新时间:2019-05-24 16:08:53 星期五 欢迎您订阅和分享我的订阅号,订阅号内会不定期分享一些我自己学习过程 ...
- 手把手教你搭建FastDFS集群(上)
手把手教你搭建FastDFS集群(上) 本文链接:https://blog.csdn.net/u012453843/article/details/68957209 FastDFS是一个 ...
随机推荐
- Linux日常之命令sed
一. 命令sed简介 利用命令sed能够同时处理多个文件多行的内容,可以不对原文件改动,仅把匹配的内容显示在屏幕上,也可以对原文件进行改动,但是不会在屏幕上返回结果,若想查看改动后的文件,可以使用命令 ...
- jQuery $.ajax传递数组的traditional参数传递必须true 对象的序列化
数组类型参数传递: 若一个请求中包含多个值,如:(test.action?tid=1&tid=2&tid=3),参数都是同一个,只是指定多个值,这样请求时后台会发生解析错误,应先使用 ...
- NJU 操作系统实验三
实验描述: 代码实现: 链接:https://pan.baidu.com/s/1so3-XsvWBY9ZDbINob6qCw 提取码:8hhe
- SSM框架中IoC、DI与AOP的理解
框架封装了普通项目中程序员需要重复书写的代码和调用过程,就比如说在传统的jsp项目中,我们的controller接收到前端的请求然后程序员就需要去开发Dao层,里面还涉及数据库的连接和存储过程的代码, ...
- 用css编写三角和半圆形状样式
1.三角样式 htriangle-down { height:; border-left:11rpx solid transparent; border-right:11rpx solid trans ...
- Linux系统无法启动故障解决方案
Linux系统无法启动故障解决方案 2011-09-27 09:42 佚名 比特网 我要评论(0) 字号:T | T 不管你多么喜爱你的Linux系统机器,有时候你都必须恢复你的系统.是的,即使一台L ...
- UFUN函数 UF_TRNS(平移 变换)( uf5943 , uf5947)
//设置class_dialog选择过滤 static int init_proc(UF_UI_selection_p_t select,void* user_data) { ; //实体 片体 UF ...
- 从1G到5G发展史(3GPP是个什么组织 为啥5G标准离不开它)
1.“3GPP”组织建立的来龙去脉 3GPP一直以来在人们心中是一个神秘的组织,很多用户对于它的理解和认知,说不清,道不明.最近关于5G网络的诸多报道,都陈述了“5G网络”的标准是由“3GPP”来规定 ...
- @JsonView注解指定返回的model类中显示的字段
1.User类 package com.imooc.model; import com.fasterxml.jackson.annotation.JsonView; /** * @author oy ...
- 泛型(二)封装工具类CommonUtils-把一个Map转换成指定类型的javabean对象
1.commons-beanutils的使用 commons-beanutils-1.9.3.jar 依赖 commons-logging-1.2.jar 代码1: String className ...