Elasticsearch7.X 入门学习第二课笔记----基本api操作和CRUD
原文:Elasticsearch7.X 入门学习第二课笔记----基本api操作和CRUD
版权声明:本文为博主原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。
下面的操作 都是是kibana 中的 dev Tools工具操作的
一、索引
一个索引就是一个拥有几分相似特征的文档的集合。比如说,你可以有一个客户数据的索引,另一个产品目录的索引,还有一个订单数据的索引。一个索引由一个名字来标识(必须全部是小写字母的),并且当我们要对对应于这个索引中的文档进行索引、搜索、更新和删除的时候,都要使用到这个名字。
-
#查看所有索引相关信息
-
GET /_cat/indices?v
-
#创建索引
-
PUT customer
-
#查看所有索引相关信息
-
GET customer
-
#删除索引
-
DELETE customer
-
#查看索引的文档总数
-
GET kibana_sample_data_ecommerce/_count
-
-
#查看前10条文档,了解文档格式
-
POST kibana_sample_data_ecommerce/_search
-
{
-
}
二、文档CRUD
一个文档是一个可被索引的基础信息单元。比如,你可以拥有某一个客户的文档,某一个产品的一个文档,当然,也可以拥有某个订单的一个文档。文档以 JSON(Javascript Object Notation)格式来表示。

1 create 创建文档
_create 指定类型为create并不是type名称 默认是_doc 指定 ID 如果已经存在,就报错
-
#create document. _create 指定类型为create并不是type名称 默认是_doc 指定 ID 如果已经存在,就报错
-
PUT users/_create/1
-
{
-
"user" : "Jack2",
-
"post_date" : "2019-05-15T14:12:12",
-
"message" : "trying out Elasticsearch"
-
}
-
如果是id是1文档存在 在创建就会报错

2 index 创建文档
index和 create不一样地方:index 如果文档不错,就索引新的文档。如果文档存在就覆盖原有的文档内容。版本信息+1

3 GET查询索引
get 根据文档id查询 文档内容

4 Update 修改文档
update 修改文档 不会删除原文档 而是在 文档的基础上更新文档中的字段内容
# _update 才会根据文档中字段信息 在原文档上增加字段 必须带有doc
POST users/_update/1/
{
"doc":{
"post_date" : "2019-05-18T14:12:12",
"message" : "trying out ElasticsearchOut",
"phone" : "1806185",
"pubtest":[1,2,3],
"pubtest2":"[1,2,3]"
}
}

5 DELETE 删除文档
### Delete by Id
# 删除文档
DELETE users/_doc/1
6 查看索引的 maping 信息
maping 相当于表的 schema
GET users/_mapping

三 文档批量操作
bulk api 批量操作
1、bulk相当于数据库里的bash操作。
2、引入批量操作bulk,提高工作效率,你想啊,一批一批添加与一条一条添加,谁快?
3、bulk API可以帮助我们同时执行多个请求
4、bulk的格式:
action:index/create/update/delete
metadata:_index,_type,_id
request body:_source (删除操作不需要加request body)
{ action: { metadata }}
{ request body }
单条操作失败不会影响其他操作
5、bulk里为什么不支持get呢?
答:批量操作,里面放get操作,没啥用!所以,官方也不支持。
6、create 和index的区别
如果数据存在,使用create操作失败,会提示文档已经存在,使用index则可以成功执行。
7、bulk一次最大处理多少数据量?
bulk会把将要处理的数据载入内存中,所以数据量是有限制的,最佳的数据量不是一个确定的数值,它取决于你的硬件,你的文档大小以及复杂性,你的索引以及搜索的负载。
一般建议是1000-5000个文档,如果你的文档很大,可以适当减少队列,大小建议是5-15MB,默认不能超过100M,可以在es的配置文件(即$ES_HOME下的config下的elasticsearch.yml)中。
-
### Bulk 操作 批量操作,其中一步错误,不影响其他操作
-
-
PUT _bulk
-
{"index":{"_index":"test","_id":"1"}}
-
{"name":"dukun","post_date" : "2019-05-18T14:12:12","age":18,"phone" : "1806185","sex":"男"}
-
{"index":{"_index":"test","_id":"2"}}
-
{"name":"dukun02","post_date" : "2019-05-18T14:12:12","age":25,"phone" : "19888","sex":"男"}
-
{"create":{"_index":"test","_id":"3"}}
-
{"name":"dukun03","post_date" : "2019-05-19T14:12:12"}
-
{"update":{"_index":"test","_id":"3"}}
-
{"doc" :{"name":"dukun04","phone" : "1806185","age":28,"sex":"男"}}
-
{"delete":{"_index":"test","_id":"4"}}
mget 批量读取
批量操作可以减少网络连接所带来的开销,提供性能。
-
##批量查询mget
-
GET /_mget
-
{
-
"docs":[
-
{
-
"_index" : "test",
-
"_id" : "1"
-
},
-
{
-
"_index" : "test",
-
"_id" : "3"
-
}
-
]
-
}
-
##批量查询mget url中指定索引 可以简化如下
-
GET test/_mget
-
{
-
"ids":[1,2,3]
-
}
-
#批量查询mget 中_source过滤默认_source字段会返回所有的内容,
-
你也可以通过_source进行过滤。
-
比如使用_source,_source_include 包含字段,_source_exclude 查询排除字段. "_source" : false 不显示字段
-
GET test/_mget
-
{
-
"docs":[
-
{ "_id":"1",
-
"_source" : false
-
},
-
{ "_id":"1",
-
"_source" : true
-
},
-
{ "_id":"2",
-
"_source" : ["name","age"]
-
},
-
{
-
"_id":"3",
-
"_source":{
-
"include":["name","age","sex"]
-
}
-
},
-
{
-
"_id":"3",
-
"_source":{
-
"exclude":["name","age","sex"]
-
}
-
}
-
-
]
-
}
批量查询 _msearch

使用match_all进行查询,并且只返回第一个文档。如果没有指定size的值,则默认返回前10个文档
也可以指定返回从哪个文档开始,返回多少文档.
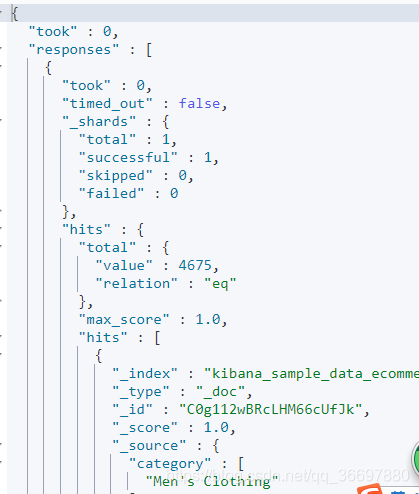
took —— Elasticsearch执行这个搜索的耗时,以毫秒为单位
timed_out —— 指明这个搜索是否超时
_shards —— 指出多少个分片被搜索了,同时也指出了成功/失败的被搜索的shards的数量
hits —— 搜索结果
hits.total —— 能够匹配我们查询标准的文档的总数目
hits.hits —— 真正的搜索结果数据(默认只显示前10个文档)
Elasticsearch7.X 入门学习第二课笔记----基本api操作和CRUD的更多相关文章
- Elasticsearch7.X 入门学习第九课笔记-----聚合分析Aggregation
原文:Elasticsearch7.X 入门学习第九课笔记-----聚合分析Aggregation 版权声明:本文为博主原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明. ...
- Elasticsearch7.X 入门学习第一课笔记----基本概念
原文:Elasticsearch7.X 入门学习第一课笔记----基本概念 版权声明:本文为博主原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明. 本文链接:https: ...
- Elasticsearch7.X 入门学习第五课笔记---- - Mapping设定介绍
原文:Elasticsearch7.X 入门学习第五课笔记---- - Mapping设定介绍 版权声明:本文为博主原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明. 本 ...
- Elasticsearch7.X 入门学习第八课笔记-----索引模板和动态模板
原文:Elasticsearch7.X 入门学习第八课笔记-----索引模板和动态模板 版权声明:本文为博主原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明. 本文链接: ...
- Elasticsearch7.X 入门学习第七课笔记-----Mapping多字段与自定义Analyzer
原文:Elasticsearch7.X 入门学习第七课笔记-----Mapping多字段与自定义Analyzer 版权声明:本文为博主原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处 ...
- Elasticsearch7.X 入门学习第四课笔记---- Search API之(Request Body Search 和DSL简介)
原文:Elasticsearch7.X 入门学习第四课笔记---- Search API之(Request Body Search 和DSL简介) 版权声明:本文为博主原创文章,遵循CC 4.0 BY ...
- Elasticsearch7.X 入门学习第三课笔记----search api学习(URI Search)
原文:Elasticsearch7.X 入门学习第三课笔记----search api学习(URI Search) 版权声明:本文为博主原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出 ...
- CI(CodeIgniter)框架入门教程——第二课 初始MVC
本文转载自:http://www.softeng.cn/?p=53 今天的主要内容是,使用CodeIgniter框架完整的MVC内容来做一个简单的计算器,通过这个计算器,让大家能够体会到我在第一节课中 ...
- python学习第二次笔记
python学习第二次记录 1.格式化输出 name = input('请输入姓名') age = input('请输入年龄') height = input('请输入身高') msg = " ...
随机推荐
- Task6.PyTorch理解更多神经网络优化方法
1.了解不同优化器 2.书写优化器代码3.Momentum4.二维优化,随机梯度下降法进行优化实现5.Ada自适应梯度调节法6.RMSProp7.Adam8.PyTorch种优化器选择 梯度下降法: ...
- php大文件下载+断点续传
如果我们的网站提供文件下载的服务,那么通常我们都希望下载可以断点续传(Resumable Download),也就是说用户可以暂停下载,并在未来的某个时间从暂停处继续下载,而不必重新下载整个文件. 通 ...
- luogu 5471 [NOI2019]弹跳 KDtree + Dijkstra
题目链接 第一眼就是 $KDtree$ 优化建图然而,空间只有 $128mb$,开不下 时间不吃紧,考虑直接跑 $Dijkstra$ $Dijkstra$ 中存储的是起点到每个输入时给出的矩阵的最 ...
- 使用chooseImage上传图片,不压缩,使用原图
参考文章: https://help.aliyun.com/document_detail/92883.html
- sqlserver 查询当前阻塞进程 并杀掉
select * from master.dbo.sysprocesses where DB_NAME(dbid)=’test’ and spid<>@@SPID 看看阻塞的进程 然后ki ...
- docker 提高效率 network-bridging 桥接
安装的时间顺序 bit3 192.168.107.128 wredis 192.168.107.129 wmysql 192.168.107.130 wslave 192.168.107.131 w ...
- C# out 和 ref 区别
C#里面的 out 和ref参数时常会用到 记录一下: public void Start() { //outSum没必要赋值,赋值了也完全没用. //如果AddByOut函数内部直接使用out对应的 ...
- 阶段1 语言基础+高级_1-3-Java语言高级_04-集合_08 Map集合_5_Entry键值对对象
- element-ui走马灯如何实现图片自适应 长度和高度 自适应屏幕大小
最近写用vue2.0写一个项目,用到了走马灯效果,由于项目赶时间,想偷下懒,第一次引用了element组件(纯JS也可以写的出来,赶时间嘛,懂得....),结果用了发现一个问题,element的组件( ...
- 观察者模式(jdk实现)
1.定义 在对象中定义一对多的依赖,当一个对象改变状态,依赖它的对象会收到通知并更新. 2.实现 (主要通过jdk自己定义的观察者实现) 以气象站通知展示板为例子,当气象站收到的各种参数改变的时候 ...