正则爬取京东商品信息并打包成.exe可执行程序
本文爬取内容,输入要搜索的关键字可自动爬取京东网站上相关商品的店铺名称,商品名称,价格,爬取100页(共100页)
代码如下;
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
|
import requestsimport re# 请求头headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36'}def get_all(url,key): for page in range(1,200,2): params = { 'keyword':key, 'enc':'utf-8', 'page':page } num = int((int(page)+1)/2) try: response = requests.get(url=url,params=params,headers=headers) # 转码 content = response.text.encode(response.encoding).decode(response.apparent_encoding) data_all = re.findall('<div class="p-price">.*?<i>(.*?)</i>.*?<div class="p-name p-name-type-2">.*?title="(.*?)"' '.*?<div class="p-shop".*?title="(.*?)"',content,re.S) for i in data_all: with open(key + '.txt', 'a+', encoding='utf-8') as f: f.write('店铺名称:' + i[2]+'\n'+'商品名称:'+i[1]+'\n'+'价格:'+i[0]+'\n\n') print('第'+str(num)+'页'+'数据下载中....') except Exception as e: print(e)if __name__ == '__main__': print('输入要搜索的内容,获取京东商城里面的商品名称,店铺名称,商品价格') key = input('输入搜索内容:') get_all(url,key) |
打包成.exe可执行文件。
需要用到pyinstaller包pip下载;
pip install pyinstaller
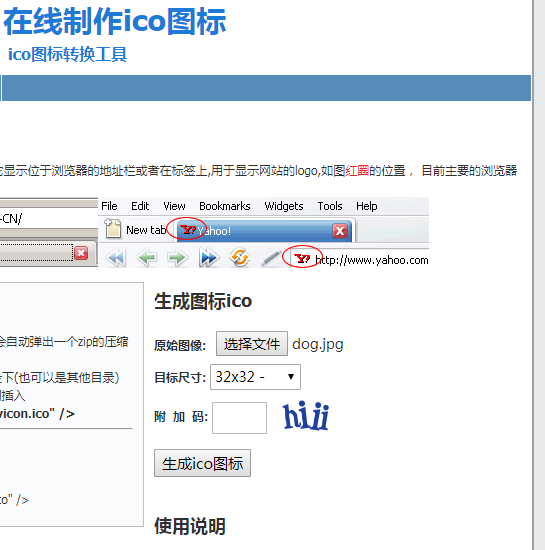
在线制作一个.ico图标,用来当程序图片,把图标和程序放在同一个文件夹下,
在.py文件目录下打开命令行窗口,执行打包命令;
E:\练习\最后阶段\0808\jd1>pyinstaller -F -i dog.ico jd.py
出现successfully表示打包成功;
27525 INFO: Building EXE from EXE-00.toc completed successfully.
可执行程序在当前文件夹下的dist文件夹下;
运行效果;
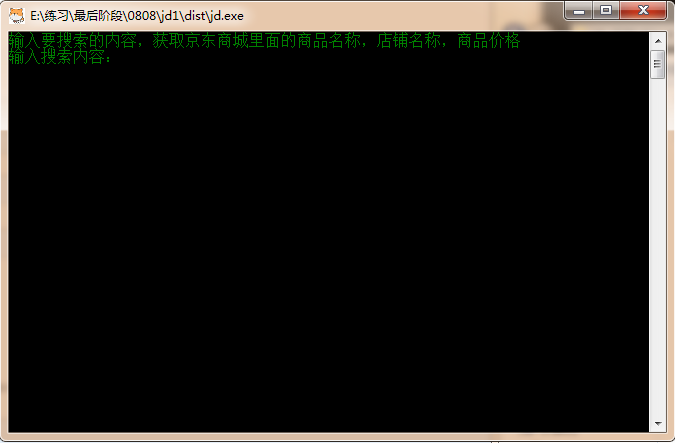
可同时执行多个程序;
输出结果;
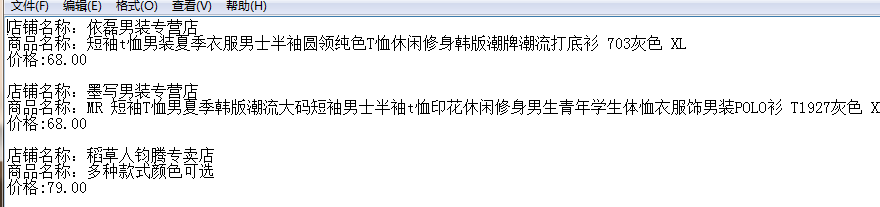
done。
正则爬取京东商品信息并打包成.exe可执行程序的更多相关文章
- 正则爬取京东商品信息并打包成.exe可执行程序。
本文爬取内容,输入要搜索的关键字可自动爬取京东网站上相关商品的店铺名称,商品名称,价格,爬取100页(共100页) 代码如下: import requests import re # 请求头 head ...
- selenium+phantomjs爬取京东商品信息
selenium+phantomjs爬取京东商品信息 今天自己实战写了个爬取京东商品信息,和上一篇的思路一样,附上链接:https://www.cnblogs.com/cany/p/10897618. ...
- Python爬虫-爬取京东商品信息-按给定关键词
目的:按给定关键词爬取京东商品信息,并保存至mongodb. 字段:title.url.store.store_url.item_id.price.comments_count.comments 工具 ...
- selenium模块使用详解、打码平台使用、xpath使用、使用selenium爬取京东商品信息、scrapy框架介绍与安装
今日内容概要 selenium的使用 打码平台使用 xpath使用 爬取京东商品信息 scrapy 介绍和安装 内容详细 1.selenium模块的使用 # 之前咱们学requests,可以发送htt ...
- 利用selenium爬取京东商品信息存放到mongodb
利用selenium爬取京东商城的商品信息思路: 1.首先进入京东的搜索页面,分析搜索页面信息可以得到路由结构 2.根据页面信息可以看到京东在搜索页面使用了懒加载,所以为了解决这个问题,使用递归.等待 ...
- 八个commit让你学会爬取京东商品信息
我发现现在不用标题党的套路还真不好吸引人,最近在做相关的事情,从而稍微总结出了一些文字.我一贯的想法吧,虽然才疏学浅,但是还是希望能帮助需要的人.博客园实在不适合这种章回体的文章.这里,我贴出正文的前 ...
- python爬虫——用selenium爬取京东商品信息
1.先附上效果图(我偷懒只爬了4页) 2.京东的网址https://www.jd.com/ 3.我这里是不加载图片,加快爬取速度,也可以用Headless无弹窗模式 options = webdri ...
- 爬虫之selenium爬取京东商品信息
import json import time from selenium import webdriver """ 发送请求 1.1生成driver对象 2.1窗口最大 ...
- Java爬虫爬取京东商品信息
以下内容转载于<https://www.cnblogs.com/zhuangbiing/p/9194994.html>,在此仅供学习借鉴只用. Maven地址 <dependency ...
随机推荐
- 磁盘的分区和挂载(mount)
一.挂载问题的引入 我们大多数人用惯了windos系统,对linux系统中磁盘的管理就先入为主,不太好理解挂载这一动作.在linux系统中添加一块新磁盘后,要进行分区.格式化(分配文件系统).挂载.当 ...
- C++中内联函数的用法
程序带调用函数需要一定的时间\空间花销,这就要求在主程序进行过程中调用函数前几下执行指令的地址及其他相关信息,一边函数调用后能继续执行.函数调用后流程返回先前记下的地址处,并根据记录的相关信息回复,而 ...
- Prometheus Querying Function rate() vs irate()
rate() rate(v range-vector) calculates the per-second average rate of increase of the time series in ...
- Java 并发编程:核心理论(一)
前言......... 并发编程是Java程序员最重要的技能之一,也是最难掌握的一种技能.它要求编程者对计算机最底层的运作原理有深刻的理解,同时要求编程者逻辑清晰.思维缜密,这样才能写出高效.安全.可 ...
- vim中代码按照行对齐。
在vim下, 用命令v, 然后移动光标,选种你的文本, 然后按下=键, 看看效果如何吧.
- numpy-添加操作大全
合并 hstack(tup):按行合并 [前面有个 h,可以理解为 行,这样方便记忆] vstack(tup):按列合并 参数虽然是 tuple,但是 list 也行,可以合并2个或者多个数组. a= ...
- Tarjan算法求有向图强连通分量并缩点
// Tarjan算法求有向图强连通分量并缩点 #include<iostream> #include<cstdio> #include<cstring> #inc ...
- Leaving Auction CodeForces - 749D (set,贪心,模拟)
大意: 若干个人参加拍卖会, 给定每个人出价顺序, 保证价格递增, q个询问, 给出k个人的编号, 求删除这k个人的所有出价后, 最终谁赢, 他最少出价多少. set维护每个人最后一次投票的时间, 每 ...
- ALV打印不显示打印界面的问题
用OO的方式screen0 不画屏幕会产生这个问题,解决办法就是不用screen0 要自己画一个区域
- python变量、对象和引用你真的明白了吗
python变量.对象和引用你真的明白了吗 变量.对象和引用 Python不像C++,Java等语言一样,他们可以不用事先声明变量类型而直接对变量进行赋值.对Python语言来讲,对象的类型和内存都是 ...