JMS学习八(ActiveMQ消息持久化)
ActiveMQ的消息持久化机制有JDBC,AMQ,KahaDB和LevelDB,还有一种内存存储的方式,由于内存不属于持久化范畴,而且如果使用内存队列,可以考虑使用更合适的产品,如ZeroMQ。所以内存存储不在讨论范围内。
无论使用哪种持久化方式,消息的存储逻辑都是一致的。
消息分为Queue和Topic两种,Queue是点对点消费,发送者发送一条消息,只有一个且唯一的一个消费者能对其进行消费。
Topic是订阅式消费,一个消息可以被很多的订阅者消费,其中定阅者又分为持久化订阅和非持久化订阅。持久化订阅是指即使订阅者当前不在线,其订阅之后,发送方发到Broker的消息,也会在持久化订阅者再次上线的时候完成消费,不会丢失消息。而非持久化订阅者,只有订阅者在线时才会消费,不在线时,即使Broker收到新的消息,当其再次上线时,也不会收到错过的消息。
ActiveMQ的持久化机制,对于Queue类型的消息,将存储在Broker,但是一旦其中一个消费者完成消费,则立即删除这条消息。对于Topic类型的消息,即使所有的订阅者都完成了消费,Broker也不一定会马上删除无用消息,而是保留推送历史,之后会异步清除无用消息。而每个订阅者消费到了哪条消息的offset会记录在Broker,以免下次重复消费。因为消息是顺序消费,先进先出,所以只需要记录上次消息消费到哪里就可以了。
配置持久化的方式,都是修改%ACTIVEMQ_HOME%conf/acticvemq.xml文件。
下面分别介绍几种持久化方式的特点:
JDBC:很多企业级应用比较喜欢这种存储方式。优点是大多数企业都有专门的DBA,以数据库作为存储介质,会让有这方面人才的公司比较放心。另外,数据库的存储方式,可以看到消息是如何存储的,可以通过SQL查询消息消费状态,可以查看消息内容,这是其他持久化方式所不具备的。还有一个优点就是数据库可以支持强一致性事务,支持两阶段提交的分布式事务。缺点是性能问题,数据库持久化是性能最低的一种方式。
之所以最先介绍数据库的持久化方式,是因为我们可以通过表结构很好的理解ActiveMQ是怎么存储和消费消息的。
数据库会创建3个表:activemq_msgs,activemq_acks和activemq_lock。
activemq_msgs用于存储消息,Queue和Topic都存储在这个表中。

下面介绍一下主要的数据库字段:
ID:自增的数据库主键
CONTAINER:消息的Destination
MSGID_PROD:消息发送者客户端的主键
MSG_SEQ:是发送消息的顺序,MSGID_PROD+MSG_SEQ可以组成JMS的MessageID
EXPIRATION:消息的过期时间,存储的是从1970-01-01到现在的毫秒数
MSG:消息本体的Java序列化对象的二进制数据
PRIORITY:优先级,从0-9,数值越大优先级越高
activemq_acks用于存储订阅关系。如果是持久化Topic,订阅者和服务器的订阅关系在这个表保存。

主要的数据库字段如下:
CONTAINER:消息的Destination
SUB_DEST:如果是使用Static集群,这个字段会有集群其他系统的信息
CLIENT_ID:每个订阅者都必须有一个唯一的客户端ID用以区分
SUB_NAME:订阅者名称
SELECTOR:选择器,可以选择只消费满足条件的消息。条件可以用自定义属性实现,可支持多属性AND和OR操作
LAST_ACKED_ID:记录消费过的消息的ID。
表activemq_lock在集群环境中才有用,只有一个Broker可以获得消息,称为Master Broker,其他的只能作为备份等待Master Broker不可用,才可能成为下一个Master Broker。这个表用于记录哪个Broker是当前的Master Broker。
配置如下:
<beans>
<broker brokerName="test-broker" persistent="true" xmlns="http://activemq.apache.org/schema/core">
<persistenceAdapter>
<jdbcPersistenceAdapter dataSource="#mysql-ds"/>
</persistenceAdapter>
</broker> <bean id="mysql-ds" class="org.apache.commons.dbcp.BasicDataSource" destroy-method="close">
<property name="driverClassName" value="com.mysql.jdbc.Driver"/>
<property name="url" value="jdbc:mysql://localhost/activemq?relaxAutoCommit=true"/>
<property name="username" value="activemq"/>
<property name="password" value="activemq"/>
<property name="maxActive" value="200"/>
<property name="poolPreparedStatements" value="true"/>
</bean>
</beans>
首先定义一个mysql-ds的MySQL数据源,然后在persistenceAdapter节点中配置jdbcPersistenceAdapter并且引用刚才定义的数据源。
AMQ:性能高于JDBC,写入消息时,会将消息写入日志文件,由于是顺序追加写,性能很高。为了提升性能,创建消息主键索引,并且提供缓存机制,进一步提升性能。每个日志文件的大小都是有限制的(默认32m,可自行配置)。当超过这个大小,系统会重新建立一个文件。当所有的消息都消费完成,系统会删除这个文件或者归档(取决于配置)。主要的缺点是AMQ Message会为每一个Destination创建一个索引,如果使用了大量的Queue,索引文件的大小会占用很多磁盘空间。而且由于索引巨大,一旦Broker崩溃,重建索引的速度会非常慢。
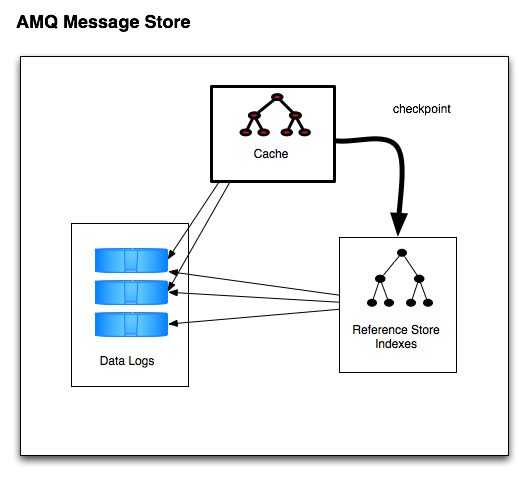
配置片段如下:
<persistenceAdapter>
<amqPersistenceAdapter directory="${activemq.data}/activemq-data" maxFileLength="32mb"/>
</persistenceAdapter>
虽然AMQ性能略高于Kaha DB,但是由于其重建索引时间过长,而且索引文件占用磁盘空间过大,所以已经不推荐使用。这里就不在详细介绍AMQ持久化的数据结构。在新版本的ActiveMQ中,AMQ已经被删除。
KahaDB:从ActiveMQ 5.4开始默认的持久化插件,KahaDb恢复时间远远小于其前身AMQ并且使用更少的数据文件,所以可以完全代替AMQ。kahaDB的持久化机制和AMQ非常像。同样是基于日志文件,索引和缓存。和AMQ不同,KahaDB所有的Destination都使用一个索引文件。《ActiveMQ In Action》表示其可以支持10000个连接,每个连接都是一个独立的Queue,足以满足大部分应用场景。

Data logs用于存储消息日志,消息的全部内容都在Data logs中。同AMQ一样,一个Data logs文件大小超过规定的最大值,会新建一个文件。同样是文件尾部追加,写入性能很快。每个消息在Data logs中有计数引用,所以当一个文件里所有的消息都不需要了,系统会自动删除文件或放入归档文件夹。
缓存用于存放在线消费者的消息。如果消费者已经快速的消费完成,那么这些消息就不需要再写入磁盘了。
Btree索引会根据MessageID创建索引,用于快速的查找消息。这个索引同样维护持久化订阅者与Destination的关系,以及每个消费者消费消息的指针。
Redo log用于系统崩溃后,重建Btree索引。因为Redo log的存在,使得重建索引时不需要读取Data logs的全量数据,大大提升性能。
KahaDB的目录结构:

db log文件,以db-<Number>.log命名。archive目录用于存档归档的数据。db.data和db.redo分别是Btree索引和redo log。
由于是ActiveMQ的默认持久化机制,所以不需要修改配置文件就可以使用KahaDB,但是还是贴出配置片段:
<persistenceAdapter>
<kahaDB directory="${activemq.data}/activemq-data" journalMaxFileLength="16mb"/>
</persistenceAdapter>
LevelDB:从ActiveMQ 5.6版本之后,又推出了LevelDB的持久化引擎。LevelDB持久化性能高于KahaDB,虽然目前默认的持久化方式仍然是KahaDB,但是LevelDB是将来的趋势。并且,在ActiveMQ 5.9版本提供了基于LevelDB和Zookeeper的数据复制方式,用于Master-slave方式的首选数据复制方案。LevelDB使用自定义的索引代替常用的BTree索引。
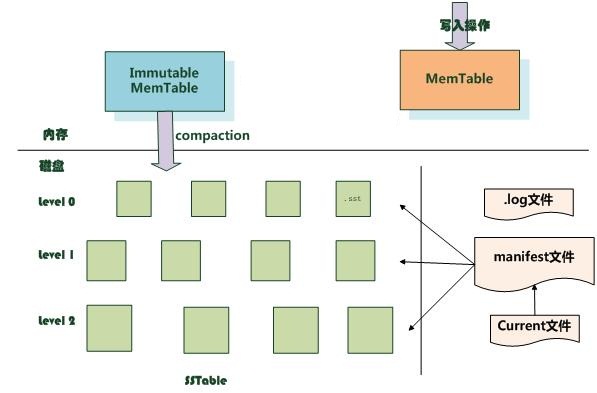
通过上图可以看出LevelDB主要由6部分组成:内存中的MemTable和ImmutableMemTable,还有硬盘上的log文件,manifest文件,current文件和SSTable文件。还有一些其他的辅助文件,暂时不做说明。
每写入一次数据,需要写入log文件,和MemTable,也就是说,只需要一次硬盘的顺序写入,和一个内存写入,如果系统崩溃,可以通过log文件恢复数据。每次写入会先写log文件,后写MemTable来保证不丢失数据。
当MemTable到达内存阀值,LevelDB会创建一个新的MemTable和log文件,而旧的MemTable会变成ImmutableMemTable,ImmutableMemTable的内容是只读的。然后系统会定时的异步的把ImmutableMemTable的数据写入新的SSTable文件。
SSTable文件和MemTable,ImmutableMemTable的数据结构相同,都是key,value的数据,按照key排序。
manifest文件用于记录每个SSTable的key的起始值和结束值,有点类似于B-tree索引。而manifest同样会生成新文件,旧的文件不再使用。current文件就是指定哪个manifest文件是现在正在使用的。
更具体实现原理可参见:http://www.cnblogs.com/haippy/archive/2011/12/04/2276064.html
配置片段如下:
<persistenceAdapter>
<levelDB directory="${activemq.data}/activemq-data"/>
</persistenceAdapter>
在目前的ActiveMQ 5.10版本中,直接使用LevelDB会导致服务不能启动,抛出java.io.IOException: com.google.common.base.Objects.firstNonNull(Ljava/lang/Object;Ljava/lang/Object;)Ljava/lang/Object;
原因是有两个Guava cache导致版本冲突,解决的办法是:
1.删除%ACTIVEMQ_HOME%lib下面的pax-url-aether-1.5.2.jar
2.注释掉%ACTIVEMQ_HOME%conf/activemq.xml的下面几行:
<bean id="logQuery" class="org.fusesource.insight.log.log4j.Log4jLogQuery"
lazy-init="false" scope="singleton"
init-method="start" destroy-method="stop">
</bean>
这个BUG地址是https://issues.apache.org/jira/browse/AMQ-5225,希望可以在下个版本顺利解决。
下面是跑在我机器上的性能测试,实际数据意义不大,因为每个环境的配置都不同,但是可以通过对比看出几种持久化方式的性能对比。
| 发送1000条消息(毫秒) | 发送10000条消息(毫秒) | 消费1000条消息的时间(毫秒) | 消费10000条消息的时间(毫秒) | |
| JDBC-Mysql | 43009 | 369802 | 610 | 509338 |
| KahaDB | 34227 | 360493 | 208 | 2224 |
| LevelDB | 34032 | 347712 | 220 | 2877 |
通过这个表格可以看出来,发送消息LevelDB最快,KahaDB稍微慢点,JDBC最慢,但是也不会慢太多,是一个数量级。消费消息,KahaDB最快,LevelDB稍微慢点,JDBC慢的让人不能忍受,差好几个数量级。LevelDB并没有显现出比KahaDB更多速度上的优势。但是由于LevelDB支持高可用的复制数据,所以首选肯定还是LevelDB。
上面对几种持久化方案讲解的很详细下面在看看着另一种
JDBC Message Store with ActiveMQ Journal
1、这种方式客服了jdbc store 的不足,使用快速的缓存写入技术,大大提高了性能,具体配置如下:
<persistenceFactory>
<journalPersistenceAdapterFactory journalLogFiles="2" journalLogFileSize="16" useJournal="true" useQuickJournal="true" dataSource="#mysql-ds" dataDirectory="${activemq.data}/data"/>
</persistenceFactory>
其他的和jdbc store 是一样的。
优点: 比jdbdc store 写入速度快
缺点:不用用于master/slave 模式
注意:如果使用数据库持久化方案则 记得在activemq的lib文件夹下添加相关数据库的驱动!
原文地址:https://my.oschina.net/u/719192/blog/287434
JMS学习八(ActiveMQ消息持久化)的更多相关文章
- JMS学习(八)-ActiveMQ Consumer 使用 push 还是 pull 获取消息
ActiveMQ是一个消息中间件,对于消费者而言有两种方式从消息中间件获取消息: ①Push方式:由消息中间件主动地将消息推送给消费者:②Pull方式:由消费者主动向消息中间件拉取消息.看一段官网对P ...
- JMS学习(七)-ActiveMQ消息的持久存储方式之KahaDB存储
一,介绍 自ActiveMQ5.4以来,KahaDB成为了ActiveMQ默认的持久化存储方式.相比于原来的AMQ存储方式,官方宣称KahaDB使用了更少的文件描述符,并且提供了更快的存储恢复机制. ...
- JMS学习(五)--ActiveMQ中的消息的持久化和非持久化 以及 持久订阅者 和 非持久订阅者之间的区别与联系
一,消息的持久化和非持久化 ①DeliveryMode 这是传输模式.ActiveMQ支持两种传输模式:持久传输和非持久传输(persistent and non-persistent deliver ...
- ActiveMQ消息持久化到Mysql数据库
1.把连接MySQL数据库的jar文件,放到ActiveMQ的lib目录下 2.修改ActiveMQ的conf目录下的activemq.xml文件,修改数据持久化的方式2.1 修改原来的kahadb的 ...
- ActiveMQ 消息持久化到数据库(Mysql、SQL Server、Oracle、DB2等)
ActiveMQ具体就不介绍了,直接介绍如何讲ActiveMQ持久化到本地数据库,以SQL Server 2008 R2为例1.下载ActiveMQ后直接解压,我下载的是apache-activemq ...
- Springboot+ActiveMQ(ActiveMQ消息持久化,保证JMS的可靠性,消费者幂等性)
ActiveMQ 持久化设置: 在redis中提供了两种持久化机制:RDB和AOF 两种持久化方式,避免redis宕机以后,能数据恢复,所以持久化的功能 对高可用程序来说 很重要. 同样在Active ...
- Activemq消息持久化
官方文档: http://activemq.apache.org/persistence.html ActiveMq持久化相关配置:/usr/local/apache-activemq-5.11.1/ ...
- JMS学习(六)-ActiveMQ的高可用性实现
原文地址:http://www.cnblogs.com/hapjin/p/5663024.html 一,ActiveMQ高可用性的架构 ActiveMQ的高可用性架构是基于Master/Slave 模 ...
- ActiveMQ消息持久化存储策略
ActiveMQ的内核是Java编写的,也就是说如果服务端没有Java运行环境ActiveMQ是无法运行的.ActiveMQ启动时,启动脚本使用wrapper包装器来启动JVM.JVM相关的配置信息在 ...
随机推荐
- Java第二周总结报告
第二周的学习,开始正式实践进行Java的学习. 本周做了什么? 了解的Java的一些基本知识,如Java变量,数据类型和运算符等.Java变量对不同的数据类型最好采用不同的命名规则,合理的命名有利于提 ...
- python爬取天气后报网
前言 大二下学期的大数据技术导论课上由于需要获取数据进行分析,我决定学习python爬虫来获取数据.由于对于数据需求量相对较大,我最终选择爬取 天气后报网,该网站可以查询到全国各地多年的数据,而且相对 ...
- ZOJ 2836 Number Puzzle 题解
题面 lcm(x,y)=xy/gcd(x,y) lcm(x1,x2,···,xn)=lcm(lcm(x1,x2,···,xn-1),xn) #include <bits/stdc++.h> ...
- python-day8(正式学习)
目录 列表类型内置方法 常用操作+内置方法 优先掌握(***) 需要掌握(**) 存一个值or多个值 有序or无序 可变or不可变 元组类型内置方法 定义 常用操作+内置方法 优先掌握 一个值or多个 ...
- 会引起全表扫描的几种SQL 以及sql优化 (转)
出处: 查询语句的时候尽量避免全表扫描,使用全扫描,索引扫描!会引起全表扫描的几种SQL如下 1.模糊查询效率很低: 原因:like本身效率就比较低,应该尽量避免查询条件使用like:对于like ‘ ...
- 利用lambda和条件表达式构造匿名递归函数
from operator import sub, mul def make_anonymous_factorial(): """Return the value of ...
- Codeforces - 1203D2 - Remove the Substring (hard version) - 双指针
https://codeforces.com/contest/1203/problem/D2 上次学了双指针求两个字符串之间的是否t是s的子序列.但其实这个双指针可以求出的是s的前i个位置中匹配t的最 ...
- Two progressions CodeForces - 125D (暴力)
大意: 给定序列, 求划分为两个非空等差序列. 暴搜, 加个记忆化剪枝. #include <iostream> #include <sstream> #include < ...
- RabbitMQ入门教程(三):Hello World
原文:RabbitMQ入门教程(三):Hello World 版权声明:本文为博主原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明. 本文链接:https://blog. ...
- 如何使用Resource资源文件
一.目的 为了能够在DisplayAttribute中重复使用同样的名称,将所有的显示字符串集中管理. 二.方法 1.DisplayAttribute本身支持直接使用资源文件. [Display(Re ...