hdfs、zookeepeer之HA模式
HA简介
1.所谓HA,即高可用(high available)
2.消除单点故障,避免集群瘫痪,hdfs中namenode保存了整个集群的元数据,如果namenode所在机器宕机,则整个集群瘫痪,HA
能够即使将备用的namenode替代宕机节点的namenode
3.当机器出现故障,或需要升级等操作时,HA起到了很好的作用
准备工作
1.硬件需求:
三台主机(网络均能ping通、ssh免密服务)
2.软件需求:
①jdk 我使用的是jdk1.8.0_131
②hadoop 我使用hadoop-2.7.2
③zookeeper 我使用zookeeper-3.4.10
以上软件单独的配置我就不说了,网上有很多安装教程,下面我主要说明搭建HA的一些原理、步骤。
HA工作原理
图解:
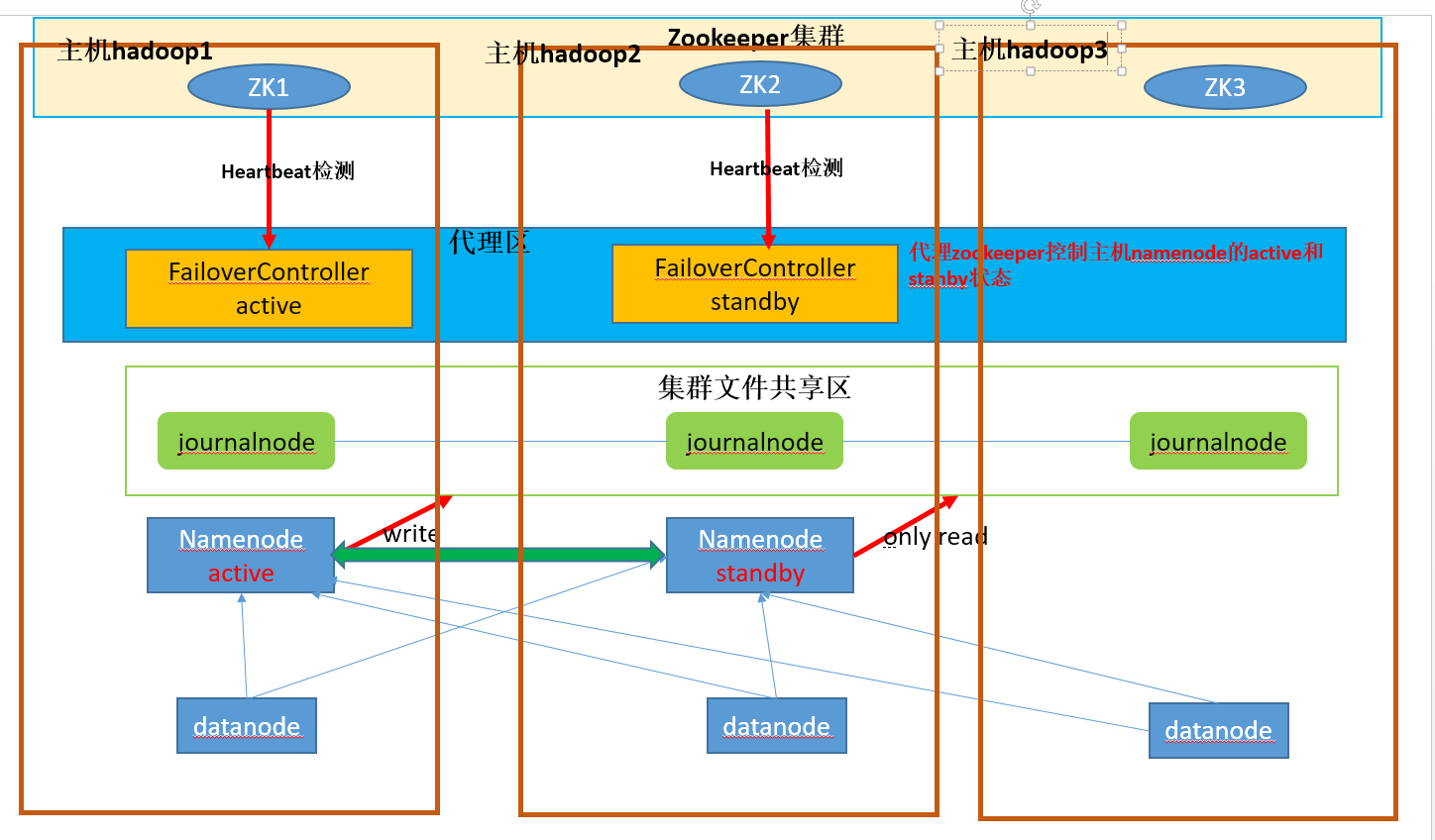
说明:
①集群文件共享区主要存放每个处于active的namenode所写的edit-profile文件和fsimage镜像,供其它备份的namenode节点(即standby namenode)
同步,及时更新集群的元数据信息
②代理区的FailoverController有active和standby两种,它们分别控制同一主机上namenode,防止脑裂现象(brain split)
如:当主机hadoop1和主机hadoop2网络连接异常时,原本hadoop1上的namenode为active,它并没有宕机,而主机hadoop2认为它宕机了,FailoverControlle
stanby 准备将自己主机上的namenode提升为active状态
为了防止脑裂现象,FailoverController stanby会先发送请求给FailoverController active去将它控制的namenode改变为stanby状态,之后hadoop2的namenode
才能为active状态
③JournalNode的作用:两个NameNode为了数据同步,会通过一组称作JournalNodes的独立进程进行相互通信。当active状态的NameNode的命名空间有任何修改时,
会告知大部分的JournalNodes进程。standby状态的NameNode有能力读取JNS中的变更信息,并且一直监控edit log的变化,把变化应用于自己的命名空间。
standby可以确保在集群出错时,命名空间状态已经完全同步了。
④zookeeper投票选举:zookeeper集群通过心跳检测,监视着集群中各个节点的健康状态,如果发现有节点下线,将自动删除该节点在zookeeper中的信息,进行重新
投票选举。
选举制度
- 默认选举节点数大的作为leader
- leader必须得到集群中半数以上的节点的选举
- 票数相当时,节点值小的节点把自己的票数给大的
hdfs-HA搭建过程
一、zookeeper集群配置
①将zookeeper安装目录下的conf文件夹下zoo-template.cfg改为zoo.cfg,并且做如下配置
修改zookeeper的启动目录:dataDir=/opt/module/zookeeper-3.4.10/data/zkData,并且在安装目录下建立出该路径文件夹
在/opt/module/zookeeper-3.4.10/data/zkData下建立一个myid文件,文件内写集群配置中对应的主机号
添加集群配置:
server.1=centos101:2888:3888 (在centos101主机上/opt/module/zookeeper-3.4.10/data/zkData/myid中写1)
server.2=centos102:2888:3888 (在centos102主机上/opt/module/zookeeper-3.4.10/data/zkData/myid中写2)
server.3=centos103:2888:3888 (在centos103主机上/opt/module/zookeeper-3.4.10/data/zkData/myid中写3)
启动zookeeper集群:分别在每台主机上启动zookeeper
cneos101中 zookeeper-3.4.10/bin/zkServer.sh start
cneos102中 zookeeper-3.4.10/bin/zkServer.sh start
cneos103中 zookeeper-3.4.10/bin/zkServer.sh start
查看启动状态
zookeeper-3.4.10/bin/zkServer.sh status
出现Mode: follower才表示zookeeper集群启动成功,注意:等所有主机都启动zookeeper后才能保证集群中有选举结果,才能查看到集群状态
二、hdfs集群配置
zookeeper结合hdfs的配置写在下面两个配置内了
hdfs-site.xml配置
<configuration>
<!--规定副本数-->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<!--规定集群服务名称-->
<property>
<name>dfs.nameservices</name>
<value>mycluster</value>
</property>
<!--规定指定集群下的namenode的名称-->
<property>
<name>dfs.ha.namenodes.mycluster</name>
<value>nn1,nn2</value>
</property>
<!--指定集群下的namenode的rpc通讯地址-->
<property>
<name>dfs.namenode.rpc-address.mycluster.nn1</name>
<value>centos101:8020</value>
</property>
<property>
<name>dfs.namenode.rpc-address.mycluster.nn2</name>
<value>centos102:8020</value>
</property>
<!--指定集群下的namenode的http通讯地址-->
<property>
<name>dfs.namenode.http-address.mycluster.nn1</name>
<value>centos101:50070</value>
</property>
<property>
<name>dfs.namenode.http-address.mycluster.nn2</name>
<value>centos102:50070</value>
</property>
<!--指定集群下的所有namenode共享journal nodes的位置-->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://centos101:8485;centos102:8485;centos103:8485/mycluster</value>
</property>
<!--将namenode提起为active时的代理类-->
<property>
<name>dfs.client.failover.proxy.provider.mycluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property> <!--权限检查开关-->
<property>
<name>dfs.permissions.enable</name>
<value>false</value>
</property> <!--仿脑裂的隔离机制-->
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<!--仿脑裂的隔离机制使用ssh私钥地址-->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/home/ljm/.ssh/id_rsa</value>
</property>
<!--开启自动故障转移zookeeper-->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
</configuration>
core-site.xml配置
<configuration>
<!-- 指定集群 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://mycluster</value>
</property> <!-- 指定hadoop运行时产生文件的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/HA/hadoop-2.7.2/data/tmp</value>
</property> <!-- JournalNode存储数据的位置 -->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/opt/module/HA/hadoop-2.7.2/data/tmp/jn</value>
</property>
<!-- 配置zookepeer集群地址 -->
<property>
<name>ha.zookeeper.quorum</name>
<value>centos101:2181,centos102:2181,centos103:2181</value>
</property> </configuration>
三、启动hdfs-HA集群
首次搭建需要
①启动启动所有journalnode
命令:sbin/hadoop-daemon.sh start journalnode
注意:格式化hdfs前,必须启动所有journalnode
②格式化hdfs
命令:bin/hdfs namenode -format
③启动zookeeper(可以写一个脚本一次性启动)
cneos101中 zookeeper-3.4.10/bin/zkServer.sh start
cneos102中 zookeeper-3.4.10/bin/zkServer.sh start
cneos103中 zookeeper-3.4.10/bin/zkServer.sh start
检查zookeeper
zookeeper-3.4.10/bin/zkServer.sh status
④格式化hdfs中的zkfc (即代理FailoverController)
命令:/bin/hdfs zkfc -formatZK
⑤可以一次性启动hdfs
命令:sbin/start-dfs.sh
结果如下:
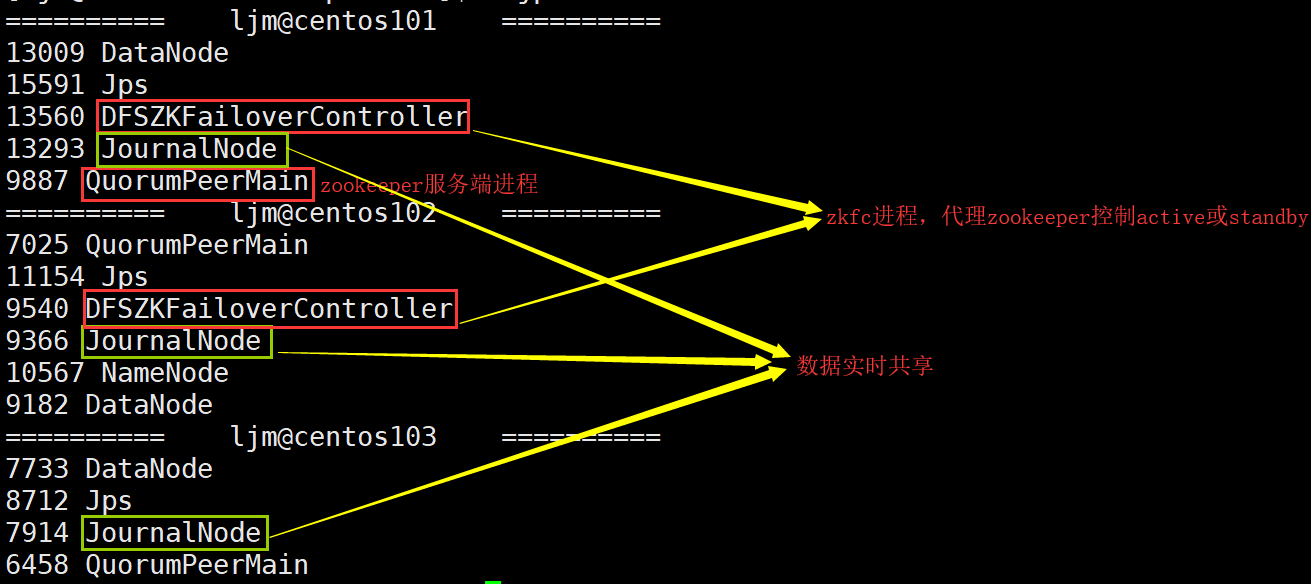
hdfs、zookeepeer之HA模式的更多相关文章
- hadoop hdfs ha 模式
这是我自己在公司一个搭建公司大数据框架是自己的选项,在配置yarn ha 出现了nodemanager起不来的问题于是我把yarn搭建为普通yarn 如果有人解决 高yarn的nodemanager问 ...
- HA模式下历史服务器配置
笔者的集群是 HA 模式的( HDFS 和 ResourceManager HA).在 ” Hadoop-2.5.0-cdh5.3.2 HA 安装" 中详细讲解了关于 HA 模式的搭建,这里就不再赘述 ...
- Hadoop-2.X HA模式下的FSImage和EditsLog合并过程
补充了一下NameNode启动过程中有关FSImage与EditsLog的相关知识. 一.什么是FSImage和EditsLog 我们知道HDFS是一个分布式文件存储系统,文件分布式存储在多个Data ...
- 一脸懵逼学习Hadoop分布式集群HA模式部署(七台机器跑集群)
1)集群规划:主机名 IP 安装的软件 运行的进程master 192.168.199.130 jdk.hadoop ...
- 搭建HBase的本地模式、伪分布式、全分布式和HA模式
一.安装HBase: 我这里选择的是hbase-1.3.1-bin.tar.gz版本解压HBase: tar -zxvf hbase-1.3.1-bin.tar.gz -C ~/training 配置 ...
- [hadoop][会装]HBase集群安装--基于hadoop ha模式
可以参考部署HBase系统(分布式部署) 和基于无HA模式的hadoop下部署相比,主要是修改hbase-site .xml文件,修改如下参数即可: <property> <name ...
- [hadoop][会装]hadoop ha模式安装
1.简介 2.X版本后namenode支持了HA特性,使得整个文件系统的可用性更加增强. 2.安装前提 zookeeper集群,zookeeper的安装参考[hadoop][会装]zookeeper安 ...
- 大数据技术之Hadoop3.1.2版本HA模式
大数据技术之Hadoop3.1.2版本HA模式 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.Hadoop的HA特点 1>.主备NameNode 2>.解决单点故障 ...
- 分布式集群HA模式部署
一:HDFS系统架构 (一)利用secondary node备份实现数据可靠性 (二)问题:NameNode的可用性不高,当NameNode节点宕机,则服务终止 二:HA架构---提高NameNode ...
随机推荐
- sql server if else
DECLARE IF (@sex = '1')BEGIN PRINT '2'END ELSE BEGIN PRINT(1) END begin... end可以省略 declare @sex int ...
- es分数_score衰减函数
1.按日期衰变 GET news/doc/_search { "query" : { "function_score": { "query" ...
- 大神的JS代码风格指南
js代码风格指南:1.缩进使用空格,不要用制表符2.必须用分号3.暂时不用ES6(modules)例如export和import命令4.不鼓励(不禁止)水平对齐5.少用var 都应该使用const或者 ...
- JS定时器的用法及示例
JS定时器的用法及示例 目录 js 定时器的四个方法 示例一 示例二 示例三 js 定时器的四个方法 setInterval() :按照指定的周期(以毫秒计)来调用函数或计算表达式.方法会不停地调用函 ...
- Java泛型:利用泛型动态确认方法返回值类型
根据泛型类型动态返回对象 public <T extends PackObject> T unPackMessage(String interfaceCode, String respVa ...
- SpringMVC基础02——HelloWorld
1.搭建环境 博主使用的环境是IDEA2017.3,首先我们需要创建一个maven项目父项目,创建一个project,选择maven,之后点击next 添写当前项目的坐标,之后点击next 填写项目名 ...
- Delphi 程序调试
- DNS解析综合学习案例(附详细答案)
1.用户需把/dev/myvg/mylv逻辑卷以支持磁盘配额的方式挂载到网页目录下2.在网页目录下创建测试文件index.html,内容为用户名称,通过浏览器访问测试3.创建用户账户,对LVM配置磁盘 ...
- Qt Creator 4.10 Beta版发布
使用Qt Creator 4.10 Beta,现在支持固定文件,因此即使在关闭所有文件时它们仍然保持打开状态,围绕语言服务器协议支持继续集成,将Android目标添加到CMake/Qbs项目,支持Bo ...
- Docker的bridge和macvlan两种网络模式
项目上部署的Docker集群创建的容器网络遇到问题,借机会学习了一下docker的网络模式,其他类型我们用的不多,这里只列举我们常用的bridge和macvlan两种,下面的描述和截图有一些是直接从网 ...