hadoop平台搭建
前言
这是小的第一次搭建hadoop平台,写下这篇博客有以下几个目的(ps:本博只记录在linux系统下搭建hadoop的步骤,如果需要了解在其他平台上搭建hadoop的步骤,还请移步):
- 1.希望大牛可以指出小的在搭建hadoop平台中的错误的打开方式
- 2.希望可以帮助到那些需要在linux平台上搭建hadoop的人们
- 3.记录下搭建过程,以便以后很好的回顾
准备工作
- 1.linux中java环境的搭建(ps:java环境的搭建不是本博的重点,如果不知道搭建方法,请自行百度)
- 2.硬件需求至少4g内存
搭建环境
- 1.ubuntu 14(ps:一定要是64位的操作系统,不然安装cloudera-manager-agant会报错)
- 2.jdk 7
安装Hadoop
安装SSH
SSH的作用:
- 1.cloudera manager需要通过SSH跳转到所有的节点上执行任务
- 2.为将来远程服务提供方便
安装步骤:
- 1.更新最新的软件列表(ps:下载最新的软件列表):
sudo apt-get update
- 2.安装ssh:
sudo apt-get -y --force-yes install ssh
- 3.查看ssh是否安装成功:
sudo service ssh status
4.安装ntp
安装步骤:
- 1.安装ntp:
sudo apt-get -y --force-yes install ntp
配置无密码sudo
原因:在安装CDH的过程中,让Cloudera Manager可以不使用密码直接获取root权限
操作步骤:
- 1.创建一个新的用户cdh:
sudo useradd -b /home -d /home/cdh -m -s /bin/bash cdh
- 2.查看用户是否创建成功:
sudo cat /etc/passwd
- 3.设置cdh用户的密码(ps:之后集群页面安装,提供ssh凭证时需要用到)
sudo passwd cdh
- 4.生成文件nopasswd
echo "cdh ALL=(ALL:ALL) NOPASSWD: ALL" > nopasswd
- 5.修改nopasswd文件的用户
sudo chown root.root nopasswd
- 6.将文件放入权限配置文件夹下
sudo mv nopasswd /etc/sudoers.d/nopasswd
配置网络
介绍:Ubuntu默认将网络配置成以DHCP的方式获取IP地址。集群中每一台都已经有固定IP地址,所以我们需要固定一个IP地址,因此需要将IP获取方式改为静态获取。
操作步骤:
- 1.修改/etc/network/interfaces文件(ps:以下指令使用到了vim,若各位看官没有该指令,请百度自行安装)
sudo vim /etc/network/interface
在打开的文件末尾添加以下代码:
auto eth0
iface eth0 inet static
address x.x.x.x
netmask x.x.x.x
gateway x.x.x.x
broadcast x.x.x.x
dns-nameservers x.x.x.x 8.8.8.8
- 2.保存文件,并且重启电脑
reboot
问题记录:
1.修改为静态获取ip后,重启系统,发现该主机ping局域网的其他主机显示
dstination host unreachable,但是可以上网。原因:通过百度,发现小弟安装的是桌面版的ubuntu,然而桌面版的ubuntu修改interface文件后,重启系统也是不会生效的。
解决:修改 /etc/NetworkManager/NetworkManager.conf 文档中的managed参数,使之为true。重启系统,问题解决。
配置host文件
操作步骤:
- 1.打开hosts文件
sudo vim /etc/hosts
- 2.在文件最后面加入如下代码
127.0.0.1 server.bigdata.net localhost
配置hostsname文件
操作步骤:
- 1.打开hostsname文件
sudo vim /etc/hostname
- 2.在文件末尾加入以下代码
server.bigdata.net
配置sysctl.conf文件
操作步骤:
- 1.打开sysctl.conf文件
sudo vim /etc/sysctl.conf
- 2.在文件末尾加入以下代码
vm.swappiness=0
安装CDH
注意:在安装CDH的过程中,请保持电脑可以访问外网,因为在安装的过程中需要下载安装包。
安装步骤:
- 1.进入到sources.list.d文件夹下(ps:该文件夹是使用 add-apt-repository命令安装的第三方源库)
cd /etc/apt/sources.list.d/
- 2.下载couldera的第三方源
sudo wget http://archive.cloudera.com/cm5/ubuntu/trusty/amd64/cm/cloudera.list
- 3.向apt添加cloudera源公钥(不执行这一步,
更新源可能会出现NO_PUBKEY的错误提示)
sudo curl -s http://archive.cloudera.com/cm5/ubuntu/trusty/amd64/cm/archive.key | sudo apt-key add -
- 4.更新源
sudo apt-get update
- 5.在Cloudera Manager节点上安装cloudera server
sudo apt-get -y --force-yes install cloudera-manager-daemons cloudera-manager-server
- 6.在Cloudera Manager节点上安装DB
sudo apt-get -y --force-yes install cloudera-manager-server-db-2
- 7.启动Cloudera Manager节点
sudo service cloudera-scm-server-db start
sudo service cloudera-scm-server start
通过网页安装cdh
- 1.使用浏览器访问Cloudera Manager节点的7180端口,比如http://server.bigdata.net:7180

输入用户名和密码(ps:默认都是admin),点击登录
- 2.选择版本
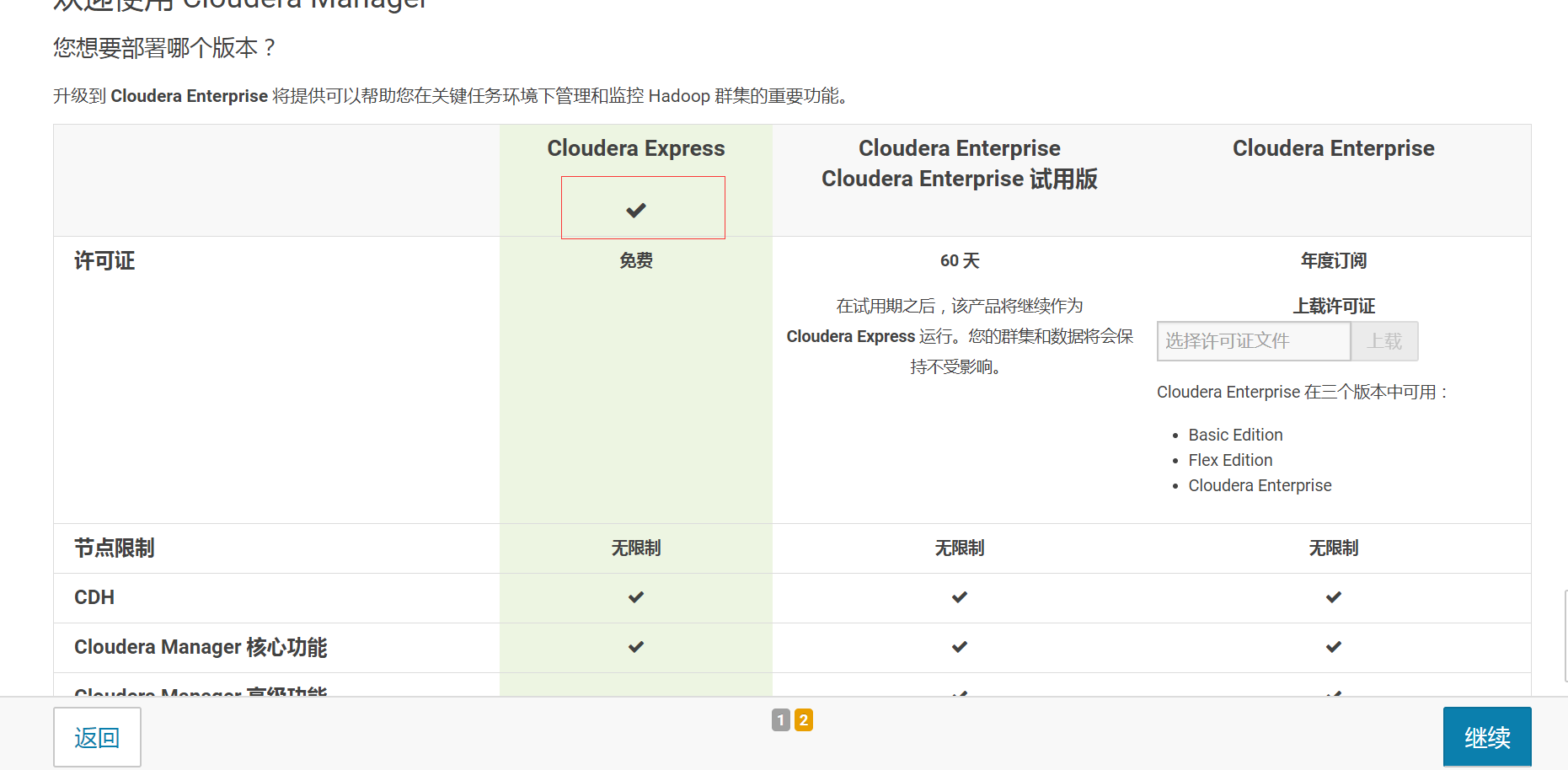
这里我选择的是免费版本,点击继续,看到下面的界面,点击继续
- 3.指定集群的主机
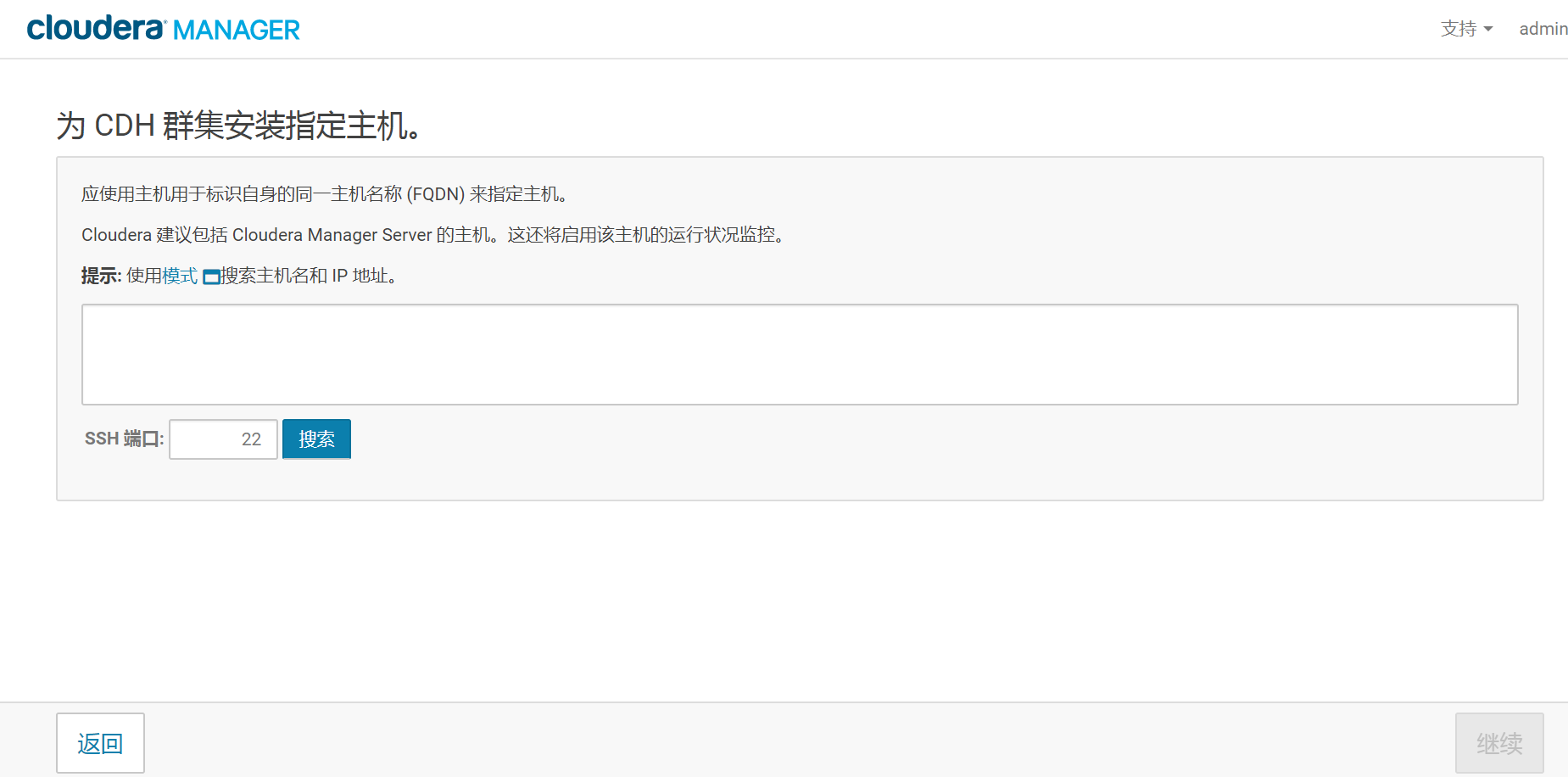
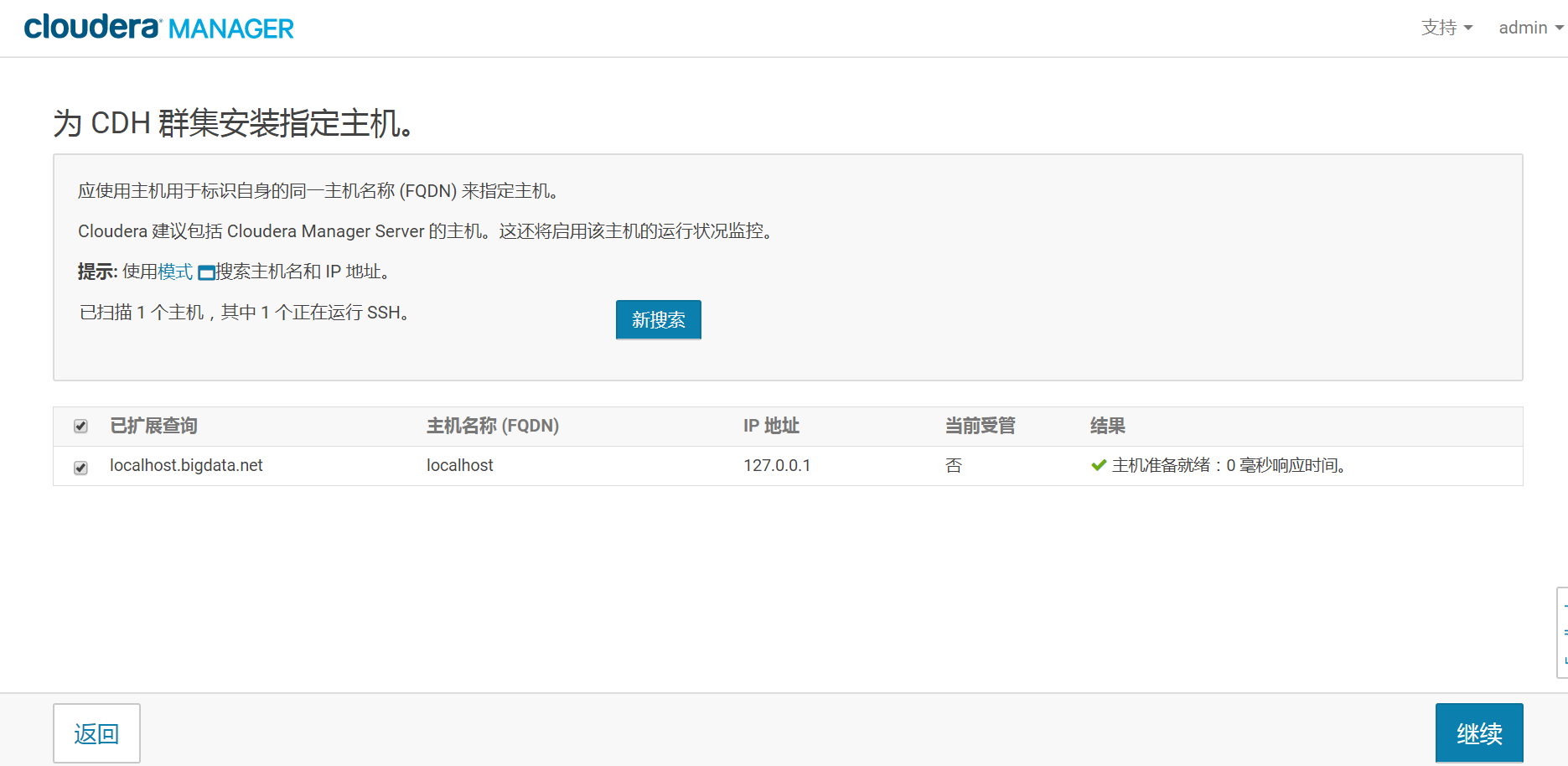
在这里,由于就一个节点,所以我们在框内填写server.bigdata.net,并且点击搜索按钮,出现下图的节点信息,勾选,然后点击继续。
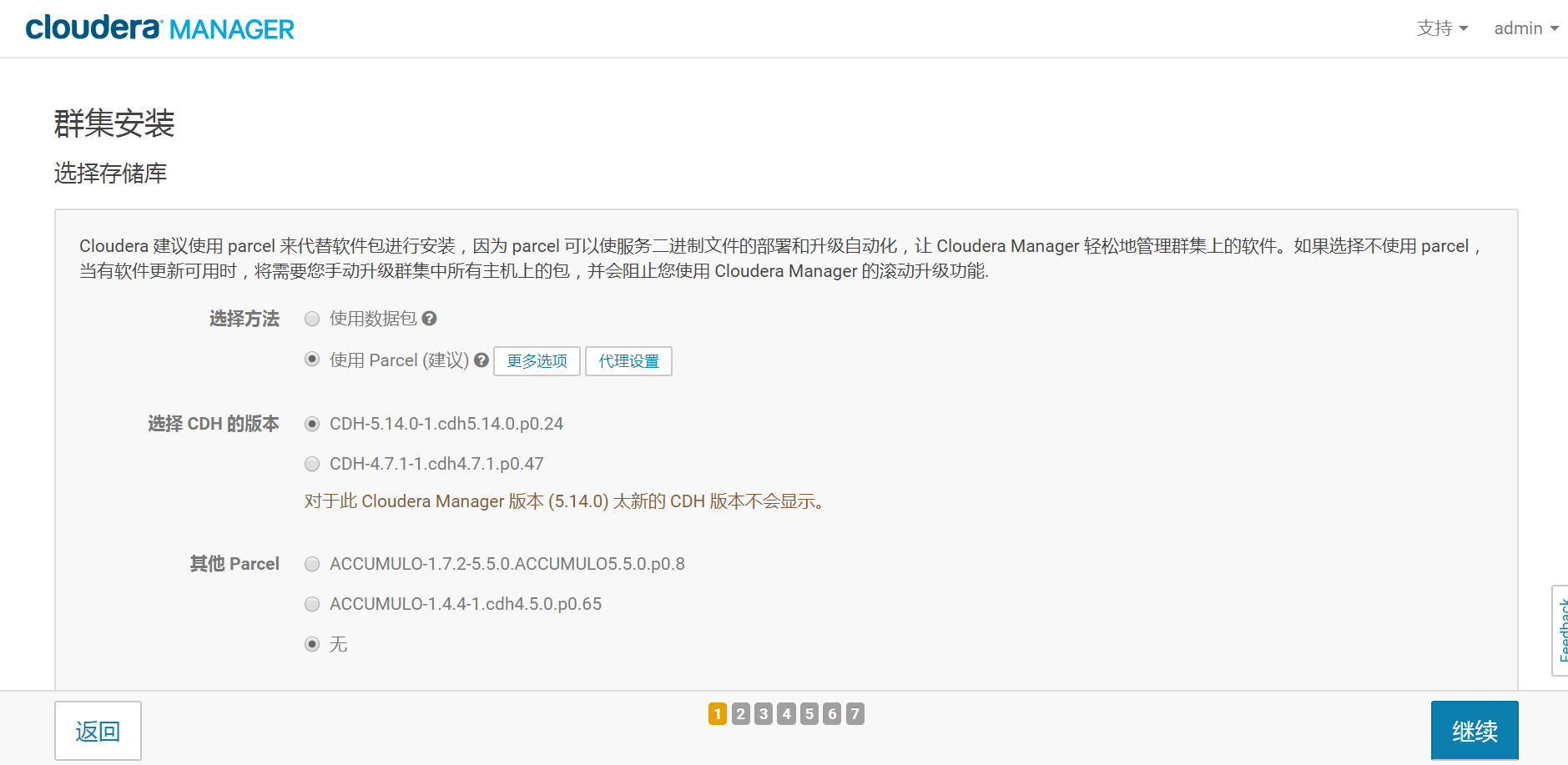
- 4.集群CDH包的选择
这里保持默认的就好了,除非你确定还要选择其他的包。然后点继续按钮
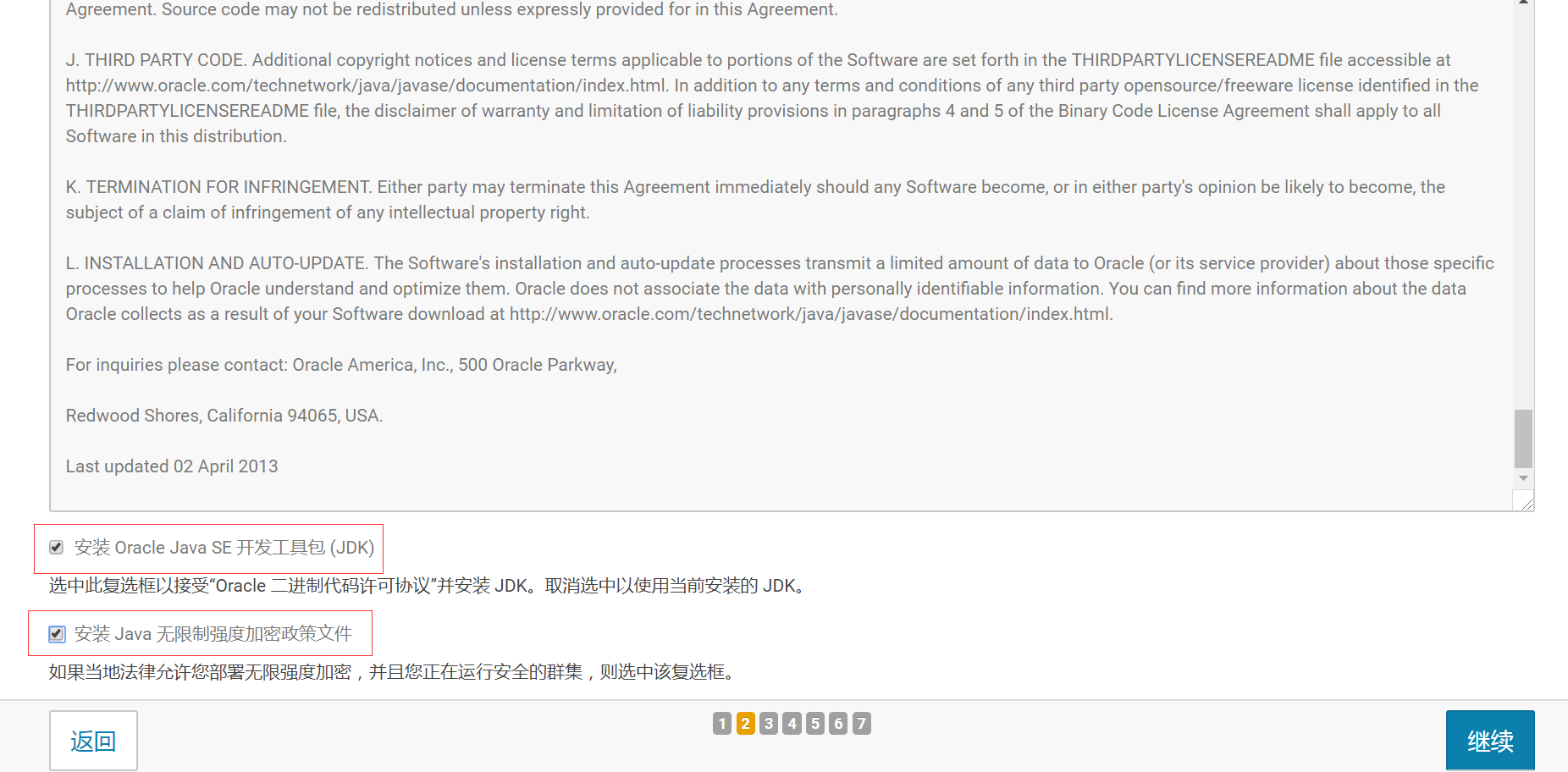
- 5.JDK选项
先选中安装Oracle JDK,然后再选中安装Java无限制强度加密,然后点继续按钮
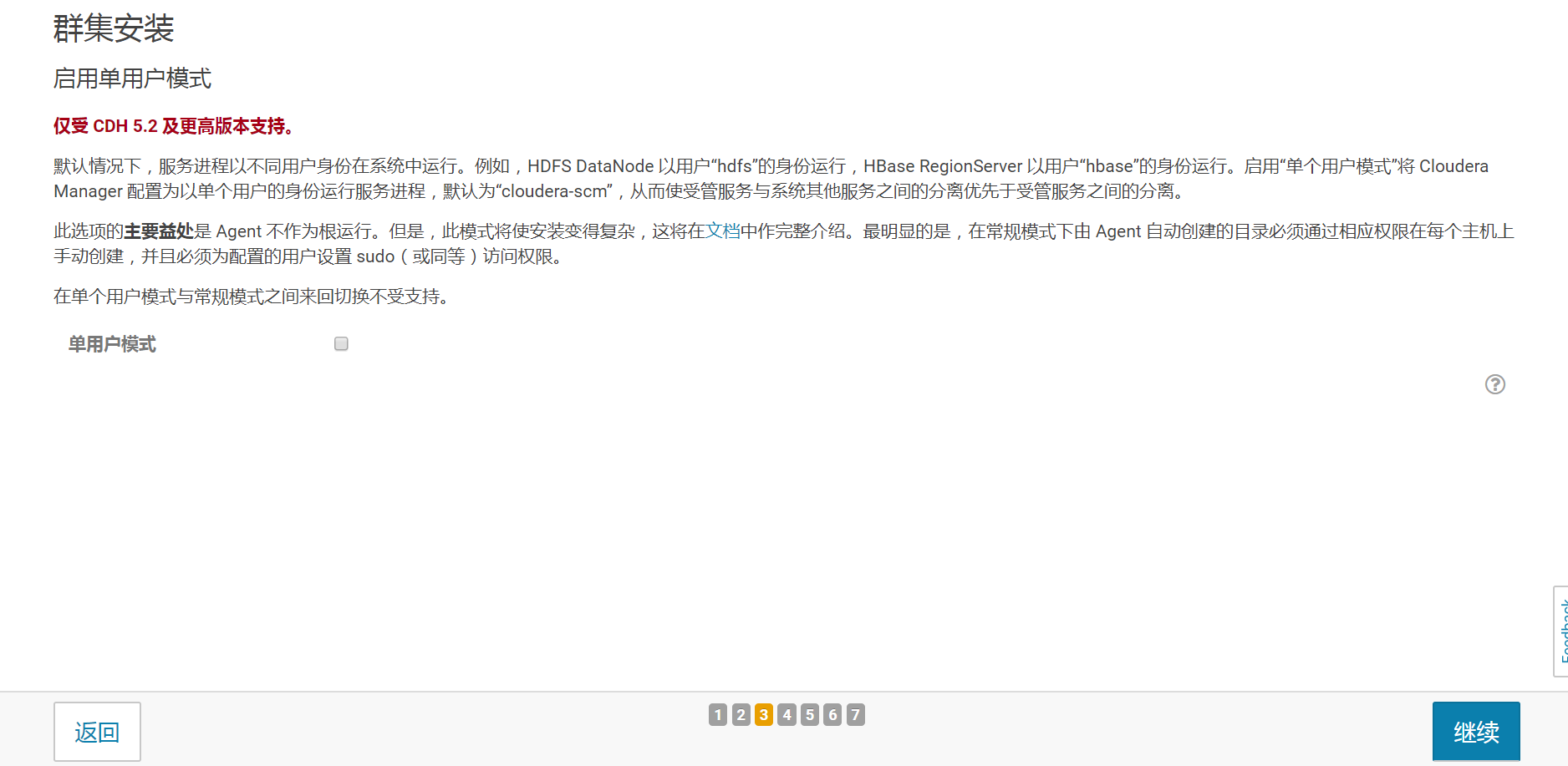
- 6.启用单用户模式
这一页保持默认就好了,点继续按钮
- 7.提供SSH登陆凭据
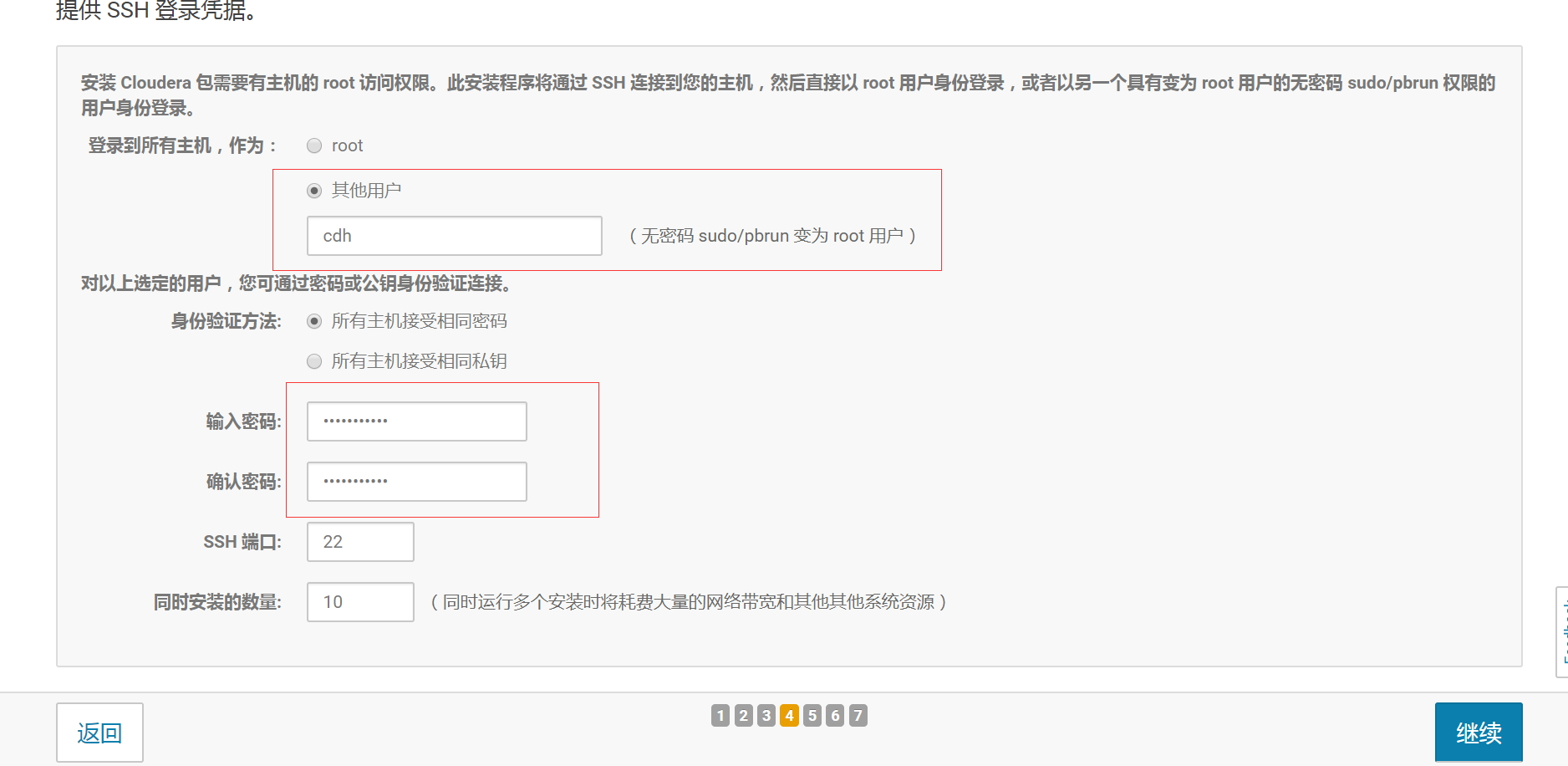
这里我们选择其他用户,密码就是之前设置的密码,其他的配置保持不变,点击继续,安装完成后,点击继续。
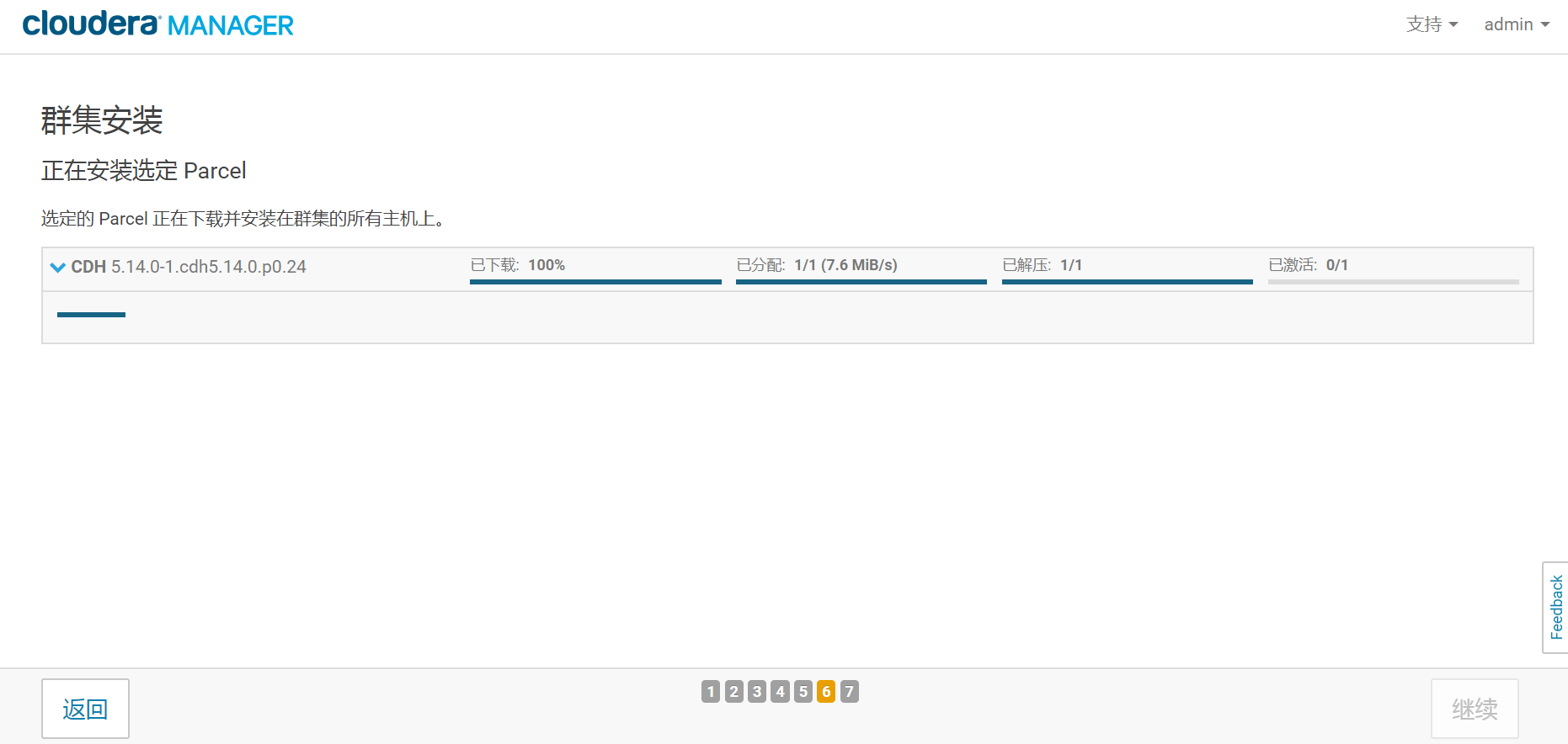
- 8.安装选定的Parcel
在这个界面耐心等待继续按钮变亮,注意,如果你现在做的是为了备份安装包而进行的单节点临时安装过程,那么到这里就可以停止了,然后进行安装包的备份操作。如果你是在安装一个实际会使用的集群,那么请点击继续按钮
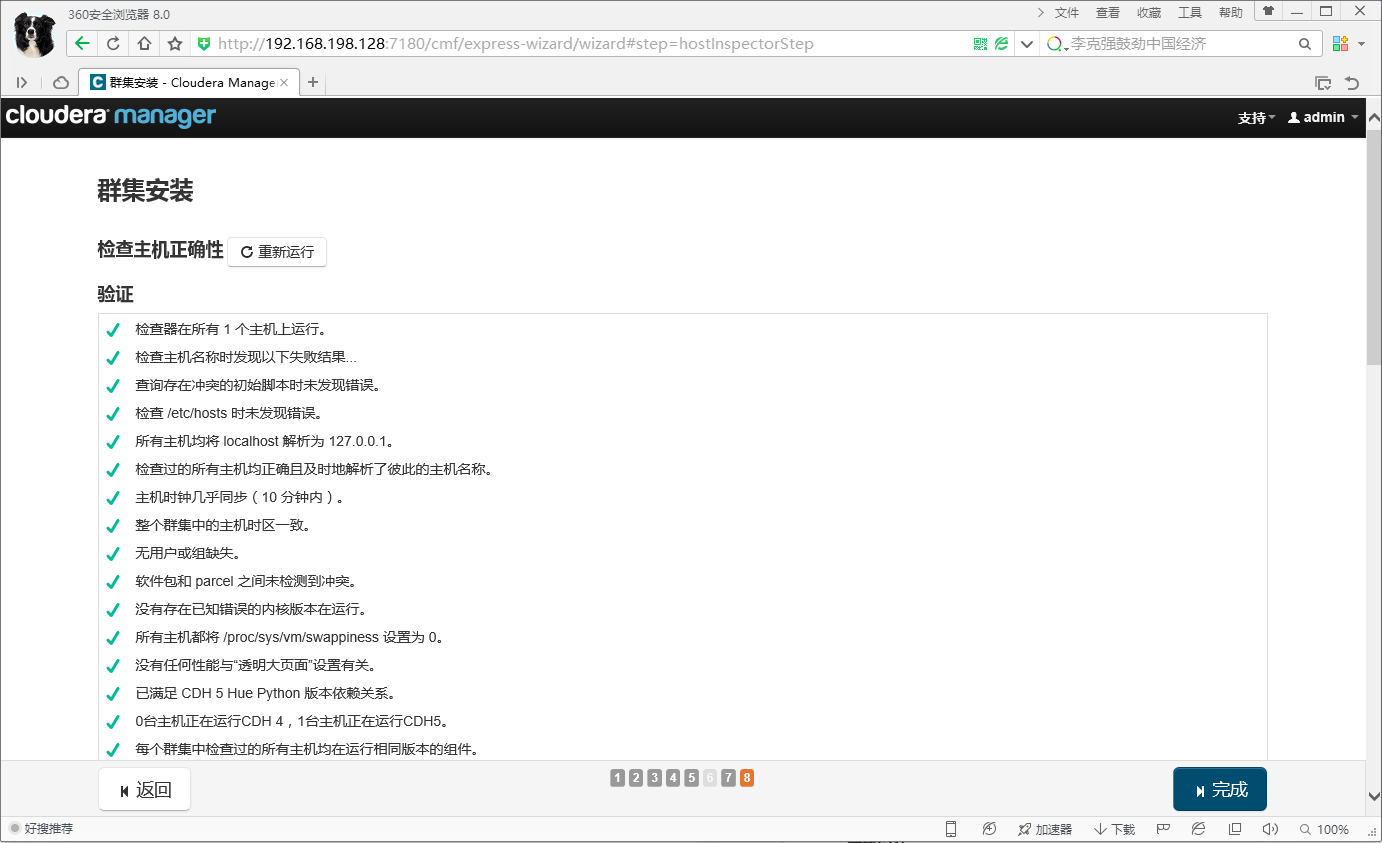
- 9.检查主机正确性
在这个界面耐心等待主机检查完成,要保证没有一个错误。如果有任何错误,参考前面的配置修改,然后点“重新运行”按钮,如果没有任何问题了,就点完成按钮
- 10.后续配置请参考这里(#http://blog.csdn.net/f1321368/article/details/49635587)
hadoop平台搭建的更多相关文章
- Hadoop 平台搭建
一.在Linux中安装JDK并配置环境变量 输入javac 查看是否已安装java环境如果没有安装 sudo apt-get install openjdk-7-jdk再次检测 javac修改配置参数 ...
- hadoop伪分布式平台搭建(centos 6.3)
最近要写一个数据量较大的程序,所以想搭建一个hbase平台试试.搭建hbase伪分布式平台,需要先搭建hadoop平台.本文主要介绍伪分布式平台搭建过程. 目录: 一.前言 二.环境搭建 三.命令测试 ...
- Hadoop 全分布模式 平台搭建
现将博客搬家至CSDN,博主改去CSDN玩玩~ 传送门:http://blog.csdn.net/sinat_28177969/article/details/54138163 Ps:主要答疑区在本帖 ...
- 大数据平台搭建(hadoop+spark)
大数据平台搭建(hadoop+spark) 一.基本信息 1. 服务器基本信息 主机名 ip地址 安装服务 spark-master 172.16.200.81 jdk.hadoop.spark.sc ...
- Hadoop高可用平台搭建
文章概览: 1.机器规划和预配置 2.软件安装 3.集群文件配置 4.启动集群 5.HA验证 6.注意事项 7.小结 机器规划和预配置 主机/进程 NN DN RM NM ZK(QP) ZKFC ...
- 大数据Hadoop学习之搭建hadoop平台(2.2)
关于大数据,一看就懂,一懂就懵. 一.概述 本文介绍如何搭建hadoop分布式集群环境,前面文章已经介绍了如何搭建hadoop单机环境和伪分布式环境,如需要,请参看:大数据Hadoop学习之搭建had ...
- 大数据Hadoop学习之搭建Hadoop平台(2.1)
关于大数据,一看就懂,一懂就懵. 一.简介 Hadoop的平台搭建,设置为三种搭建方式,第一种是"单节点安装",这种安装方式最为简单,但是并没有展示出Hadoop的技术优势,适合 ...
- 高可用Hadoop平台-HBase集群搭建
1.概述 今天补充一篇HBase集群的搭建,这个是高可用系列遗漏的一篇博客,今天抽时间补上,今天给大家介绍的主要内容目录如下所示: 基础软件的准备 HBase介绍 HBase集群搭建 单点问题验证 截 ...
- 大数据平台搭建:Hadoop
To construct big data distributed platform based on Hadoop is a common method. Hadoop comes fron Goo ...
随机推荐
- 获取文件夹中前N个文件
@echo off set input="list.txt" set srcDir="%1" set /a fileCount=10 set /a curInd ...
- Log4j指定输出日志的文件
在Log4j的配置文件中,有一个log4j.rootLogger用于指定将何种等级的信息输出到哪些文件中, 这一项的配置情况如下: log4j.rootLogger=日志等级,输出目的地1,输出目的地 ...
- 解决在data里面获取一个固定的img值
正常情况下在data里面申明,在img标签里面通过 :src应用就行了,但是如果是直接申明引用是没效果的: html: <div class="logo"> <i ...
- CentOS 下 redis 安装与配置
CentOS 下 redis 安装与配置 1.到官网上找到合适版本下载解压安装 [root@java src]# wget -c http://redis.googlecode.com/files ...
- BitMap的原理和实现
相关概念 基础类型 在java中: byte -> 8 bits -->1字节 char -> 16 bit -->2字节 short -> 16 bits --> ...
- A.Gennady and a Card Game
http://m3.codeforces.com/contest/1097/problem/A Gennady and a Card Game time limit per test 1 second ...
- [THUPC2018] 弗雷兹的玩具商店
link $solution:$ 好久没写数据结构了,那就写道简单题吧! 可以发现 $m\leq 50$,所以可以去取在 $[l,r]$ 中当价格相同时愉悦值最高的做完全背包 $dp$ . 发现修改价 ...
- 二分查找---有序数组的 Single Element
有序数组的 Single Element 540. Single Element in a Sorted Array (Medium) Input: [1, 1, 2, 3, 3, 4, 4, 8, ...
- Linux下创建虚VIP的方法及相互的区别:
#创建虚VIPifconfig eth1:1 192.168.202.200 broadcast 192.168.202.255 netmask 255.255.255.0 up ip addr ad ...
- moongoose对象无法新增删除属性
昨天用nodes中的moongoose去查询一个结果遇到一个大坑,这个坑貌似用moongoose可能会遇到.背景是这样的,我在nodejs中去查询document,得到的可以看作是一个对象list.在 ...