Floyed(floyd)算法详解
是真懂还是假懂?
Floyed算法:是最短路径算法可以说是最慢的一个。
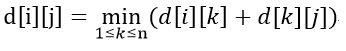 (图片源自网络大佬)
(图片源自网络大佬)
众所周知,dp(动态规划)要满足无后效性。也就是说。。。。。。
还是先举个例子:
我们设k取某一个k1时满足k1为最终点i到j最短路经过的点,但是在外层循环到k1时d[i][k1]和d[k1][j]并没有取到最小值,因为k1只能取一次,那么往后再循环是不是就取不到k1了呢??
答案当然不是的(不然这个算法为什么正确?)
还是那句话,dp无后效性,
也就是说,k不单单是枚举,还是一个状态变量,找i和j之间通过编号不超过k(k从1到n)的节点的最短路径(一定要注意,这里是当前最短路径,
k之前的已经变成最短路了,对于每一个k,我们都进行了n^2的充分枚举(ij),已保证当前已经满足对从1到k的节点最优,
那么当k枚举完所有点,那么一定是最优的了
换句话说,在d[i][j]=min(d[i][j],d[i][k]+d[k][j])
公式中,因为k之前已经作为i或者j被枚举过了;,d[i][k]和d[k][j] 已经被1到k枚举过了
for(k=;k<=n;k++) //中转节点
for(i=;i<=n;i++) 第二层循环
for(j=;j<=n;j++) 第三层循环
if(e[i][j]>e[i][k]+e[k][j] )如果直接到达比通过k这个中转接点到达的距离短
e[i][j]=e[i][k]+e[k][j];那么就更新松弛
算法复杂度O(n^3),这也是为什么平常很少使用的原因。
例题校内题目:
但题目中给的点数为250,三次方为15625000,不会爆TLE,
可以使用,对于一万次询问,O(1)询问就可以过了。
但是,这个题目有一个附加条件:繁华度。
怎样在floyed算法中加入繁华度来考虑呢?
代码:(注意floyed部分)
#include<iostream>
#include<cstring>
#include<cstdio>
#include<queue>
#include<algorithm>
using namespace std;
int n,m,q,p[],aj,bj,wj,x,y,f[][],a[][],top,t[];
int cmp(int x,int y)
{
return p[x]<p[y];
}
int main()
{
memset(a,,sizeof(a));
top=;
scanf("%d%d%d",&n,&m,&q);
for(int i=;i<=n;i++)//正常输入
scanf("%d",&p[i]);
for(int i=;i<=m;i++)
{
scanf("%d%d%d",&aj,&bj,&wj);
a[aj][bj]=min(a[aj][bj],wj);//初始化
a[bj][aj]=min(a[bj][aj],wj);//这是邻接矩阵类型的,没用链式前向星
}
for(int i=;i<=n;i++)
{
a[i][i]=;//对角线置为0
t[i]=i;//编号
}
sort(t+,t++n,cmp);//t数组开始时是编号,但经过sort排序后就变成了城市繁华度从小到大的顺序
for(int i=;i<=n;i++)
for(int j=;j<=n;j++)
f[i][j]=a[i][j]+max(p[i],p[j]);//f数组即为答案数组,这里初始化
for(int k=;k<=n;k++)
for(int i=;i<=n;i++)
for(int j=;j<=n;j++)
{
a[i][j]=min(a[i][j],a[i][t[k]]+a[t[k]][j]);//a数组就是最短路数组
f[i][j]=min(f[i][j],a[i][j]+max(p[i],max(p[j],p[t[k]])));
f数组就是答案数组,a数组不受f数组影响,有可能a更新了,但是f将最大繁华值考虑进去后并没有更新,那么a数组保留最短路为以后的更新做铺垫
}
for(int i=;i<=q;i++)
{
scanf("%d%d",&x,&y);
printf("%d\n",f[x][y]);
}
return ;
}
Floyed(floyd)算法详解的更多相关文章
- 【最短路径Floyd算法详解推导过程】看完这篇,你还能不懂Floyd算法?还不会?
简介 Floyd-Warshall算法(Floyd-Warshall algorithm),是一种利用动态规划的思想寻找给定的加权图中多源点之间最短路径的算法,与Dijkstra算法类似.该算法名称以 ...
- Floyd 算法详解
Floyd-Warshall Floyd算法,是一种著名的多源最短路算法. 核心思想: 用邻接矩阵存储图,核心代码为三重循环,第一层枚举中间点k,二三层分别枚举起始点i与目标点j.然后判断经过中间点k ...
- 最短路径Dijkstar算法和Floyd算法详解(c语言版)
博客转载自:https://blog.csdn.net/crescent__moon/article/details/16986765 先说说Dijkstra吧,这种算法只能求单源最短路径,那么什么是 ...
- Floyd算法详解
Floyd本质上使用了DP思想,我们定义\(d[k][x][y]\)为允许经过前k个节点时,节点x与节点y之间的最短路径长度,显然初始值应该为\(d[k][x][y] = +\infin (k, x, ...
- BM算法 Boyer-Moore高质量实现代码详解与算法详解
Boyer-Moore高质量实现代码详解与算法详解 鉴于我见到对算法本身分析非常透彻的文章以及实现的非常精巧的文章,所以就转载了,本文的贡献在于将两者结合起来,方便大家了解代码实现! 算法详解转自:h ...
- kmp算法详解
转自:http://blog.csdn.net/ddupd/article/details/19899263 KMP算法详解 KMP算法简介: KMP算法是一种高效的字符串匹配算法,关于字符串匹配最简 ...
- 机器学习经典算法详解及Python实现--基于SMO的SVM分类器
原文:http://blog.csdn.net/suipingsp/article/details/41645779 支持向量机基本上是最好的有监督学习算法,因其英文名为support vector ...
- [转] KMP算法详解
转载自:http://www.matrix67.com/blog/archives/115 KMP算法详解 如果机房马上要关门了,或者你急着要和MM约会,请直接跳到第六个自然段. 我们这里说的K ...
- 【转】AC算法详解
原文转自:http://blog.csdn.net/joylnwang/article/details/6793192 AC算法是Alfred V.Aho(<编译原理>(龙书)的作者),和 ...
- KMP算法详解(转自中学生OI写的。。ORZ!)
KMP算法详解 如果机房马上要关门了,或者你急着要和MM约会,请直接跳到第六个自然段. 我们这里说的KMP不是拿来放电影的(虽然我很喜欢这个软件),而是一种算法.KMP算法是拿来处理字符串匹配的.换句 ...
随机推荐
- python去掉空格和 b
直接看下面实例: In [52]: output=subprocess.check_output(["head -c 16 /dev/urandom | od -An -t x | tr - ...
- JS-T
取整函数ceil:向上取整floor:向下取整round:四舍五入 js获取当前页面信息this.location.href JS打印对象 var data = JSON.stringify(res. ...
- C#编程 委托 Lambda表达式和事件
委托 如果我们要把方法当做参数来传递的话,就要用到委托.简单来说委托是一个类型,这个类型可以赋值一个方法的引用. 声明委托 在C#中使用一个类分两个阶段,首选定义这个类,告诉编译器这个类由什么字段和方 ...
- nginx - 反向代理 - 配置文件模板 - nginx 代理tcp的服务 - 部署示意图
danjan01deiMac:~ danjan01$ cat /usr/local/etc/nginx/nginx.conf|grep -v '^$' worker_processes 1; even ...
- Macaca环境搭建(三)----uirecorder Android录制
一.安装Macaca-Android 命令窗口输入:npm i macaca-android -g 二.安装android-SDK 1.下载并安装ADT-bundle,官网下载地址我就不提供了,因为下 ...
- Oracle表概念
对于初学者来说,对表的概念也有一定的认识.因为我们对数据库的操作,90%以上是对表的操作. 常见表的规则表(Regular table),严格意义上来说又叫 heap table(堆表),也就是我们最 ...
- (四)Java秒杀项目之JMeter压测
一.JMeter入门压测 1.打开JMeter工具,选中测试计划->右键添加->线程(用户)->线程组,页面中的线程数就是并发数,页面中的Ramp-Up时间(秒)表示通过多长时间启动 ...
- HDU 2018 Cow Story DP
Basic DP Problem URL:https://vjudge.net/problem/HDU-2018 Describe: There is a cow that gives birth t ...
- vc_redist x64 或者x86下载地址
https://support.microsoft.com/en-us/help/2977003/the-latest-supported-visual-c-downloads 微软的东西,果然还是人 ...
- Java小程序—录屏小程序(下半场)
下半场. 上半场,我们我们写了录屏的程序,那么下半场我们的任务是写一个播放器. 设计思路:播放器的思路就是将图片放在一个JScrollPane中顺序播放,所以还是得使用swing组件,并且仍然要使用线 ...