Dubbo源码分析之ExtensionLoader加载过程解析
ExtensionLoader加载机制阅读:
Dubbo的类加载机制是模仿jdk的spi加载机制;
Jdk的SPI扩展加载机制:约定是当服务的提供者每增加一个接口的实现类时,需要在jar包的META-INF/service/目录下同时创建一个以服务接口命名的具体实现类,该文件里面就是保存的实现该接口的具体实现类。而当外部程序装配这个模块的时候,就能通过该jar包META-INF/services/里的配置文件找到具体的实现类
名,并装载实例化,完成模块的注入。 基于这样一个约定就能很好的找到服务接口的实现类,而不需要再代码里制定。jdk提供服务实现查找的一个工具
类:java.util.ServiceLoader。
但是原始的jdk扩展点加载机制有些缺陷:
·JDK标准的SPI会一次性实例化扩展点所有实现,如果有扩展实现初始化很耗时,但如果没用上也加载,会很浪费资源。
·如果扩展点加载失败,连扩展点的名称都拿不到了。比如:JDK标准的ScriptEngine,通过getName();获取脚本类型的名称,但如果RubyScriptEngine因为所依赖的jruby.jar不存在,导致RubyScriptEngine类加载失败,这个失败原因被吃掉了,和ruby对应不起来,当用户执行ruby脚本时,会报不支持ruby,而不是真正失败的原因。
·Dubbo增加了对扩展点IoC和AOP的支持,一个扩展点可以直接setter注入其它扩展点。
理解Dubbo的SPI机制之前的几个概念:
·扩展点:Dubbo作为一个非常灵活的框架,并不会强制所有用户必须使用Dubbo框架里自带的某些架构,比如注册中心的话,dubbo提供了zookeeper和redis,而开发者可以根据自己的需要使用自定的注册中心,针对这种可灵活替换的技术我们就称之为扩展点技术,类似扩展点在Dubbo中有很多,比如Protocol,Filter,LoadBlance,Cluster等等;
·Wrapper:Dubbo在加载某个接口的扩展类时候,如果发现某个实现中有一个拷贝构造函数,那么该接口实现是就是该接口的包装类,此时dubbo会在真正的实现类上包装一层wrapper,比如ProtocolFilterWrapper中含有Protocol引用,及构造函数,所以加载filter配置时会返回wrapper类;即这个时候从ExtensionLoader中返回的实际扩展类是被Wrapper包装的接口实现类。
· Adaptive:这个自适应的扩展点比较难理解,所以这里直接以一个例子来讲解:在RegistryProtocol中有一个属性为Cluster,其中Protocol和Cluster都是Dubbo提供的扩展点,所以这时候当我们真正在操作中使用cluster的时候究竟使用的哪一个cluster的实现类呢?是FailbackCluster还是FailoverCluster?Dubbo在加载一个扩展点的时候如果发现其成员变量也是一个扩展点并且有相关的set方法,就会在这时候将该扩展点设置为一个自适应的扩展点,自适应扩展点(Adaptive)会在真正使用的时候从URL中获取相关参数,来调用真正的扩展点实现类。它的用途主要是用于从 ExtensionLoader 返回扩展点时,包装在真正的扩展点实现外。即从 ExtensionLoader 中返回的实际上是 Wrapper 类的实例,Wrapper 持有了实际的扩展点实现类。通过 Wrapper 类可以把所有扩展点公共逻辑移至 Wrapper 中。新加的 Wrapper 在所有的扩展点上添加了逻辑,有些类似 AOP,即 Wrapper 代理了扩展点。
扩展点自适应:ExtensionLoader 注入的依赖扩展点是一个 Adaptive 实例,直到扩展点方法执行时才决定调用是一个扩展点实现。Dubbo 使用 URL 对象(包含了Key-Value)传递配置信息。类似/context/path?version=1.0.0&application=morgan ,扩展点方法调用会有URL参数(或是参数有URL成员)注入的 Adaptive 实例可以提取约定 Key 来决定使用哪个接口的实现类来调用对应的实现的方法,比如提取协议为dubbo则会调用DubboProtocol进行实现。
·扩展点自动激活:可以理解为条件激活,比如Filter接口有很多扩展点实现类,当想简化配置用到哪些过滤器时,可以@Activate自动激活,或者配置为@Activate(“xxx”)条件配置激活。
ExtensionLoader过程详解:
在Dubbo的扩展点加载机制中,ExtensionLoader是整个SPI加载的核心,而在Dubbo中ExtensionLoader的调用一般如下:
private static final Cluster cluster = ExtensionLoader.getExtensionLoader(Cluster.class).getAdaptiveExtension();
接下来分析整个扩展点加载过程:
1.首先先从Dubbo的官方测试用例说起:
@Test
public void test_useAdaptiveClass() throws Exception {
ExtensionLoader.getExtensionLoader(Protocol.class).getAdaptiveExtension();
// 加载扩展类加载器
ExtensionLoader<HasAdaptiveExt> loader = ExtensionLoader.getExtensionLoader(HasAdaptiveExt.class);
// 获取适配扩展点
HasAdaptiveExt ext = loader.getAdaptiveExtension();
// 判断是否添加了HasAdaptiveExt_ManualAdaptive
assertTrue(ext instanceof HasAdaptiveExt_ManualAdaptive);
}
1.对于一个新的扩展类接口HasAdaptiveExt,首先获取它的扩展类加载器,过程如下:
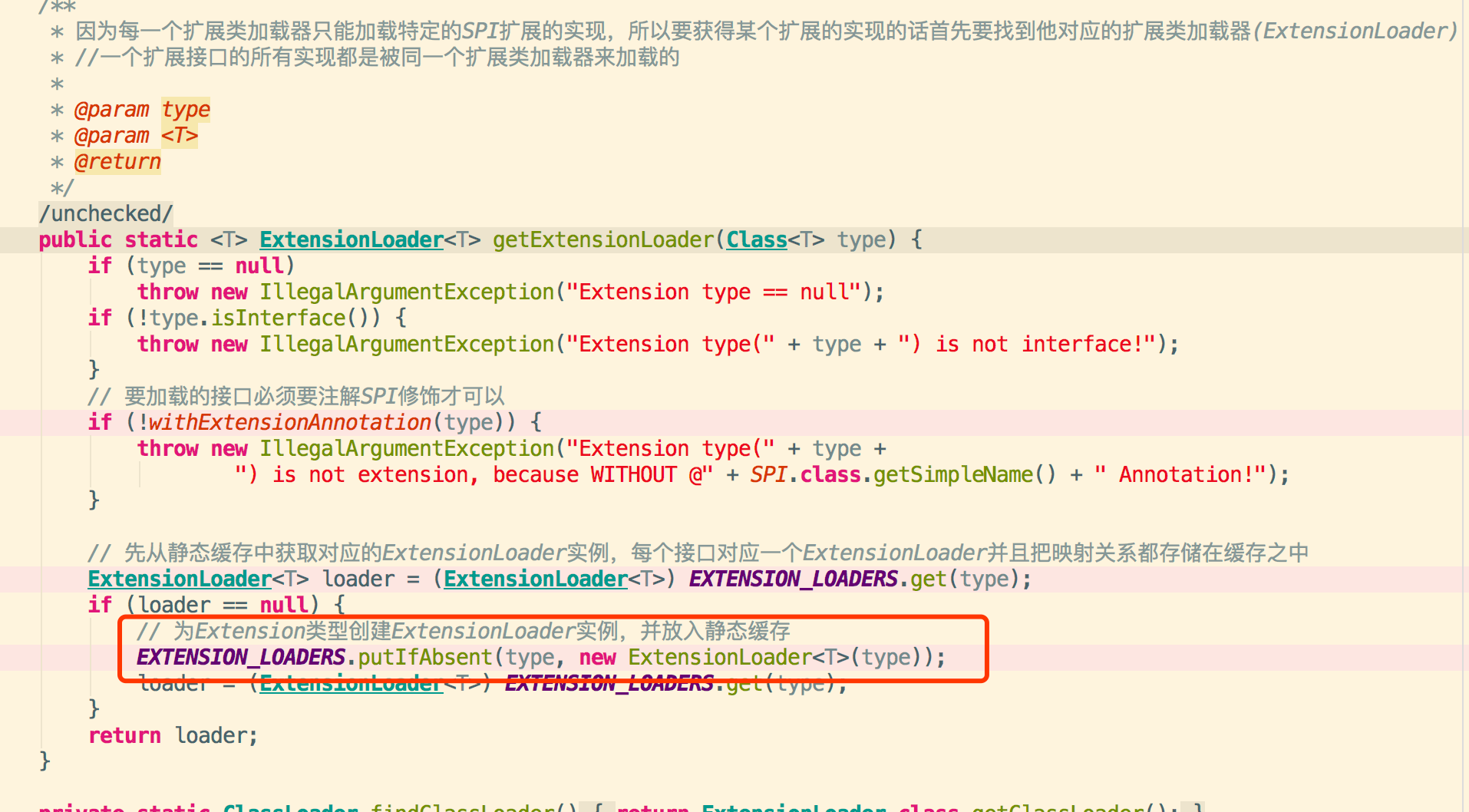
2.首次创建没有扩展类加载器则进行创建,而在新建ExtensionLoader时会首先判断扩展工程类的扩展点是否已经加载,没有的话,会先进行扩展工程类的扩展点实现的加载。

3.此时又回到第1步进行ExtensionFactory的扩展类加载器,进行ExtensionFactory类型的ExtensionLoader的实例化,实例化完成后则进行加载扩展点实现类;
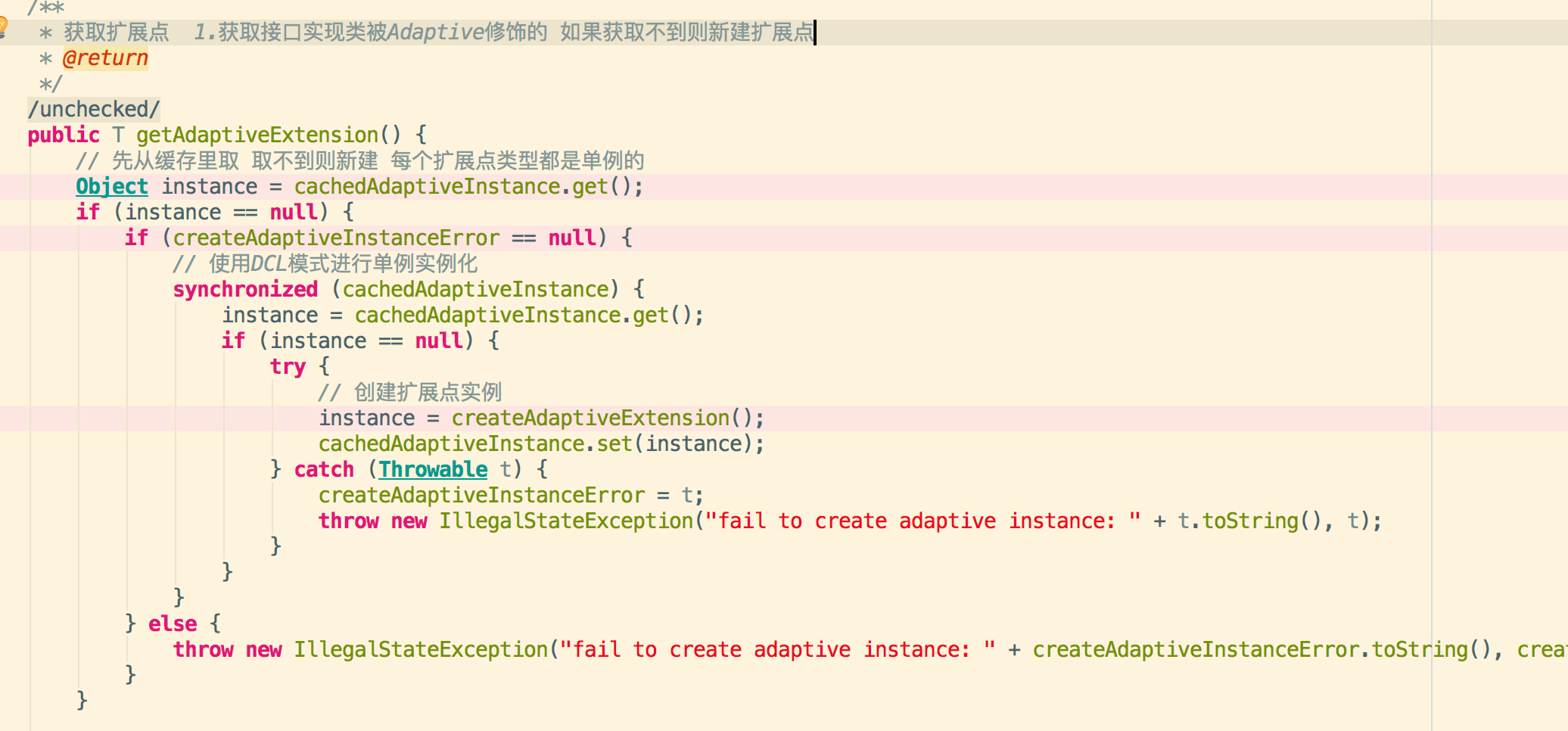
3.1:扩展点实例创建过程a.首先获取适配器类b.在适配器扩展点钟注入其他依赖的扩展点
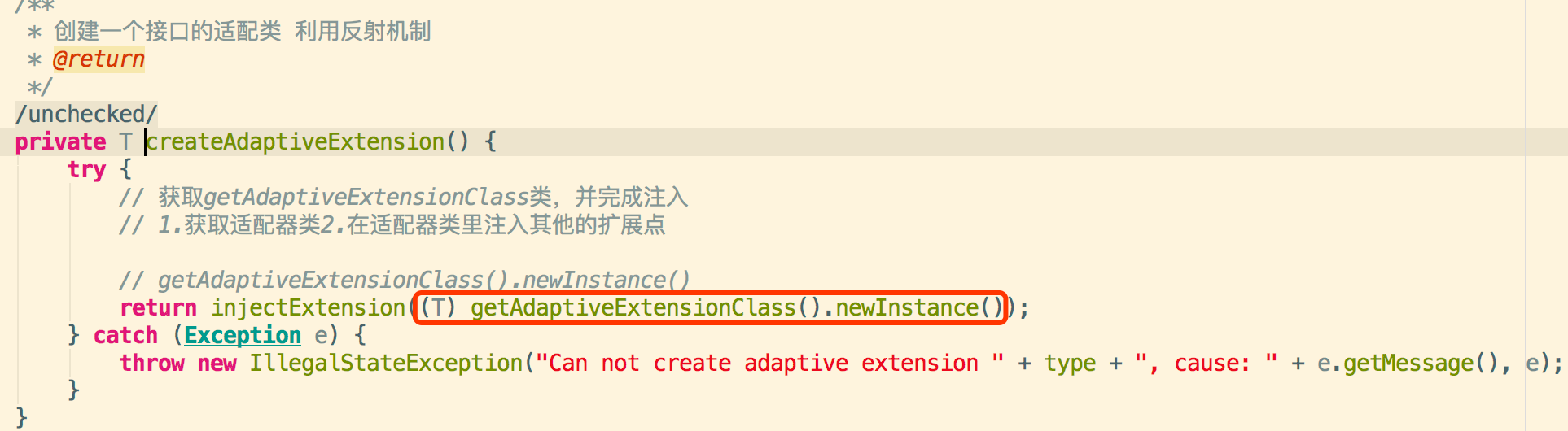
3.2.获取适配扩展类的方式有两种:a.在某个实现类上加@Adaptive注解b.如果没有实现类被注解,则自动生成该接口的适配类扩展点
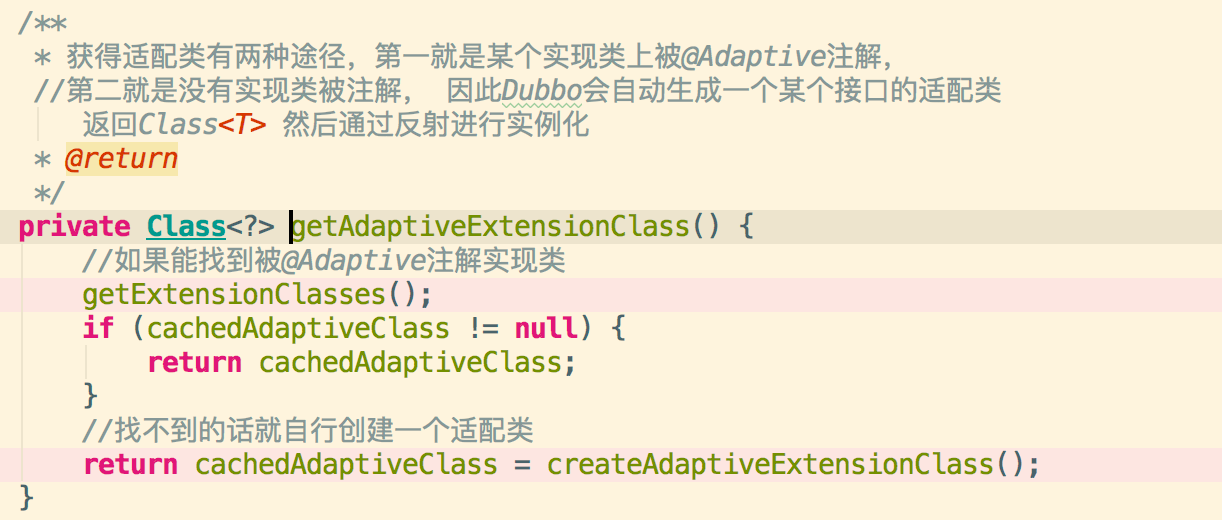
3.3加载指定目录下的配置文件
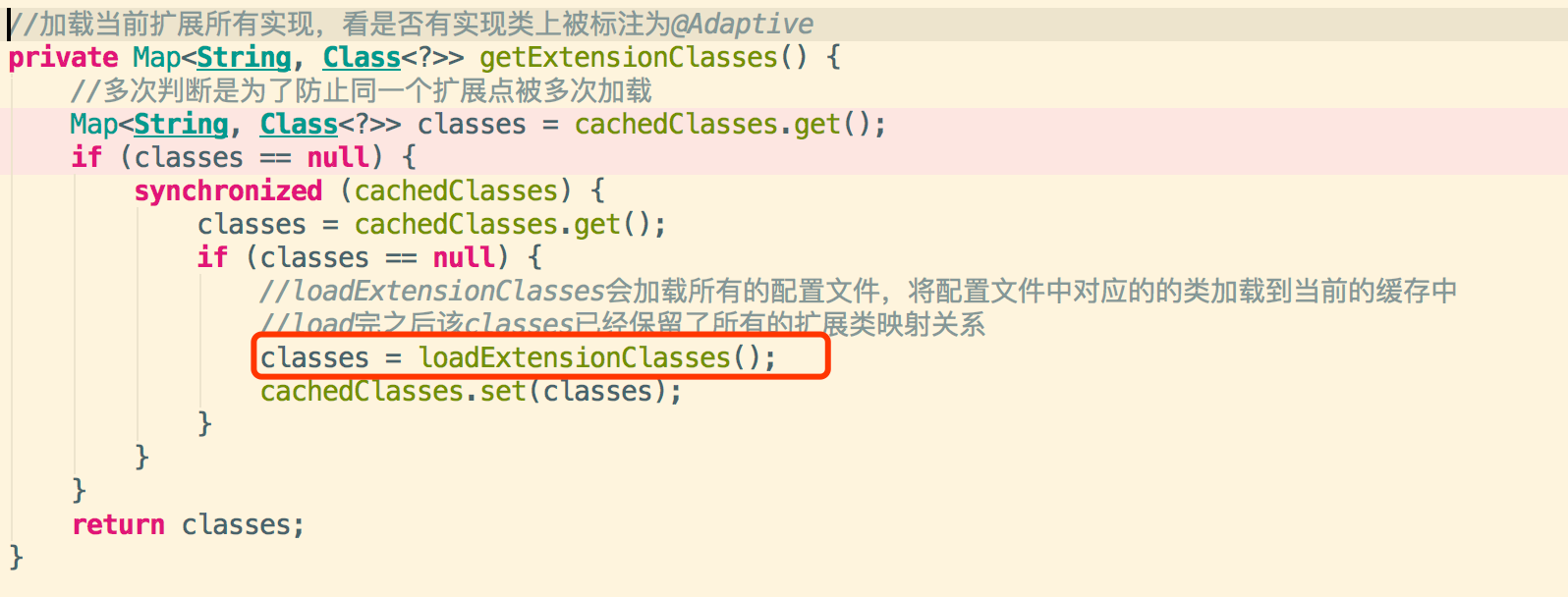
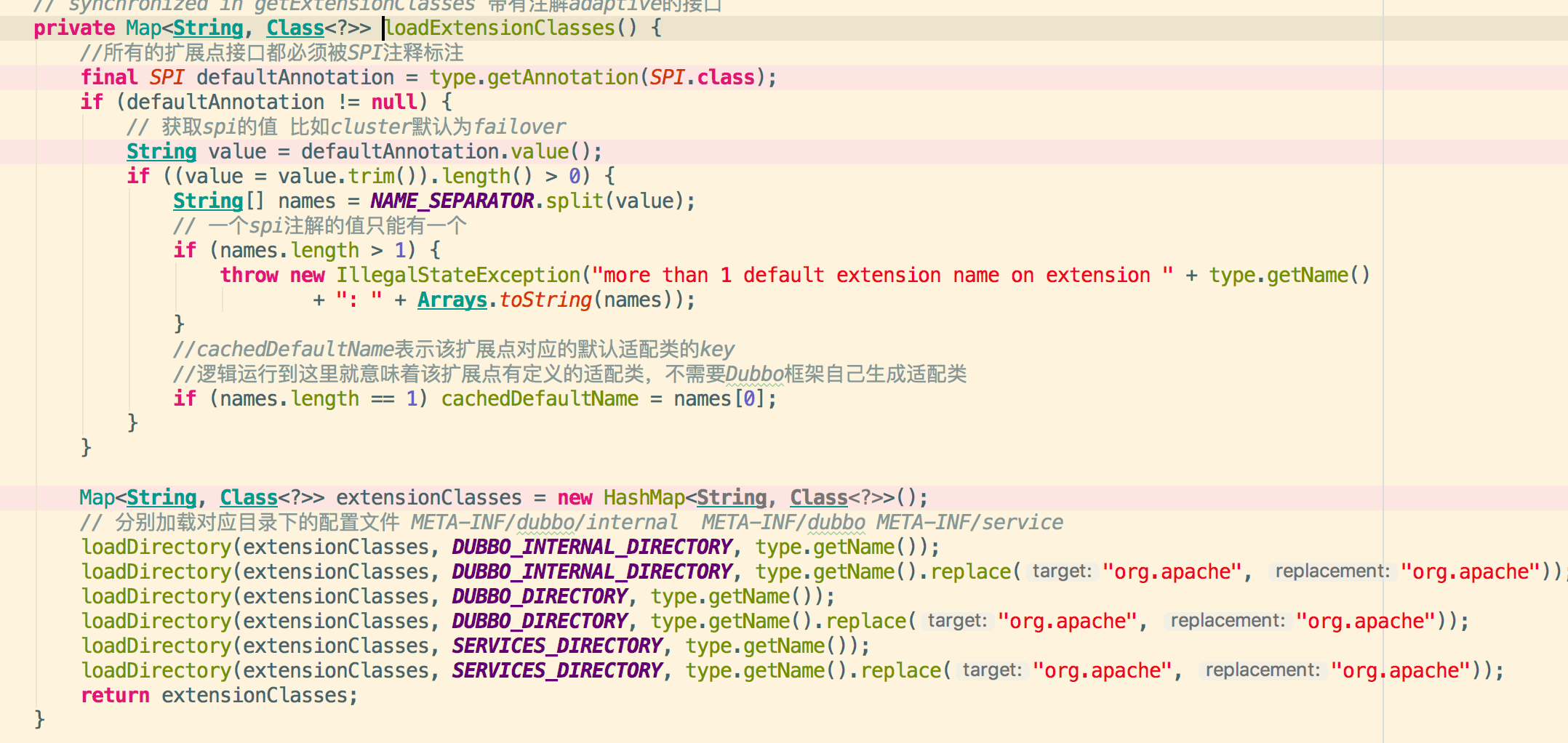
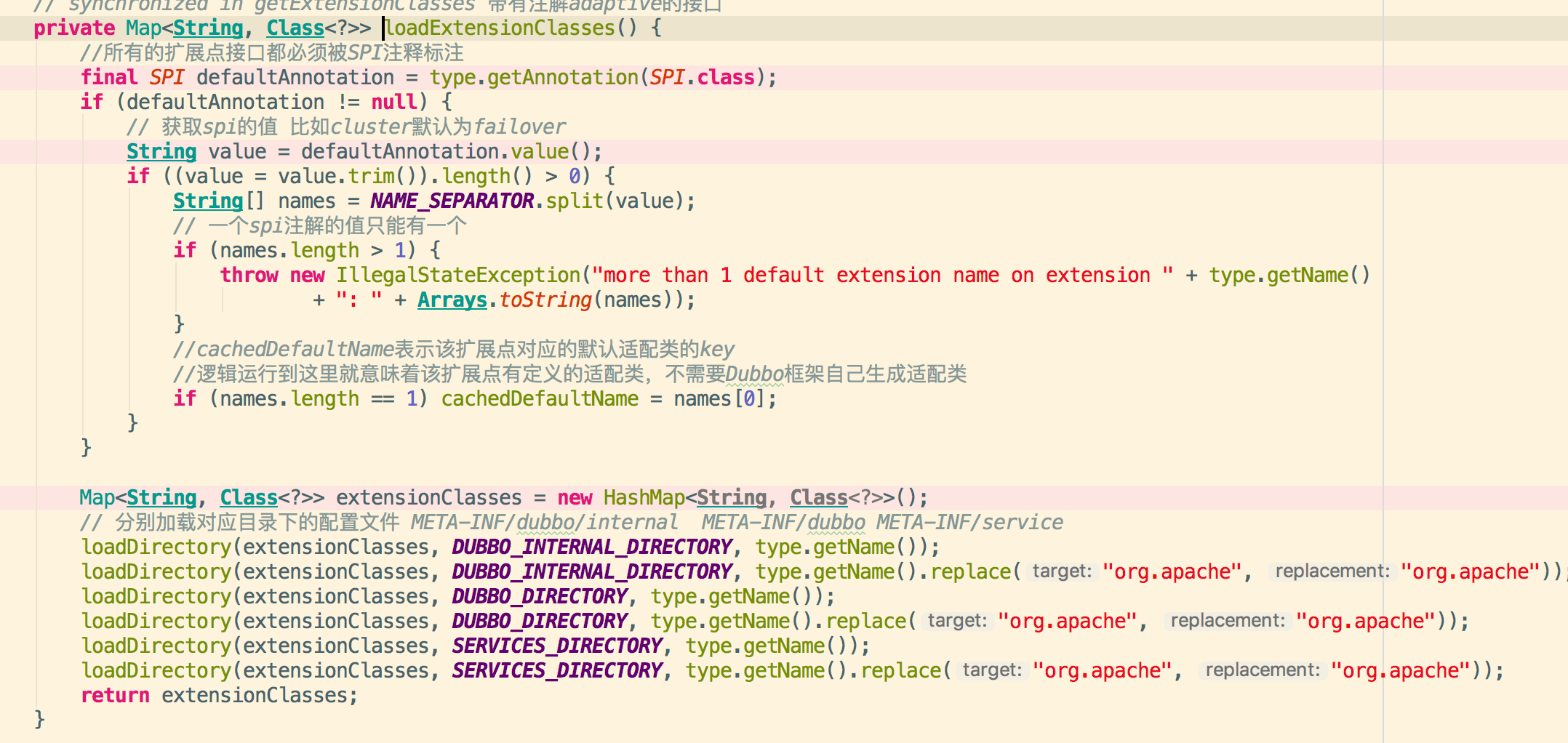
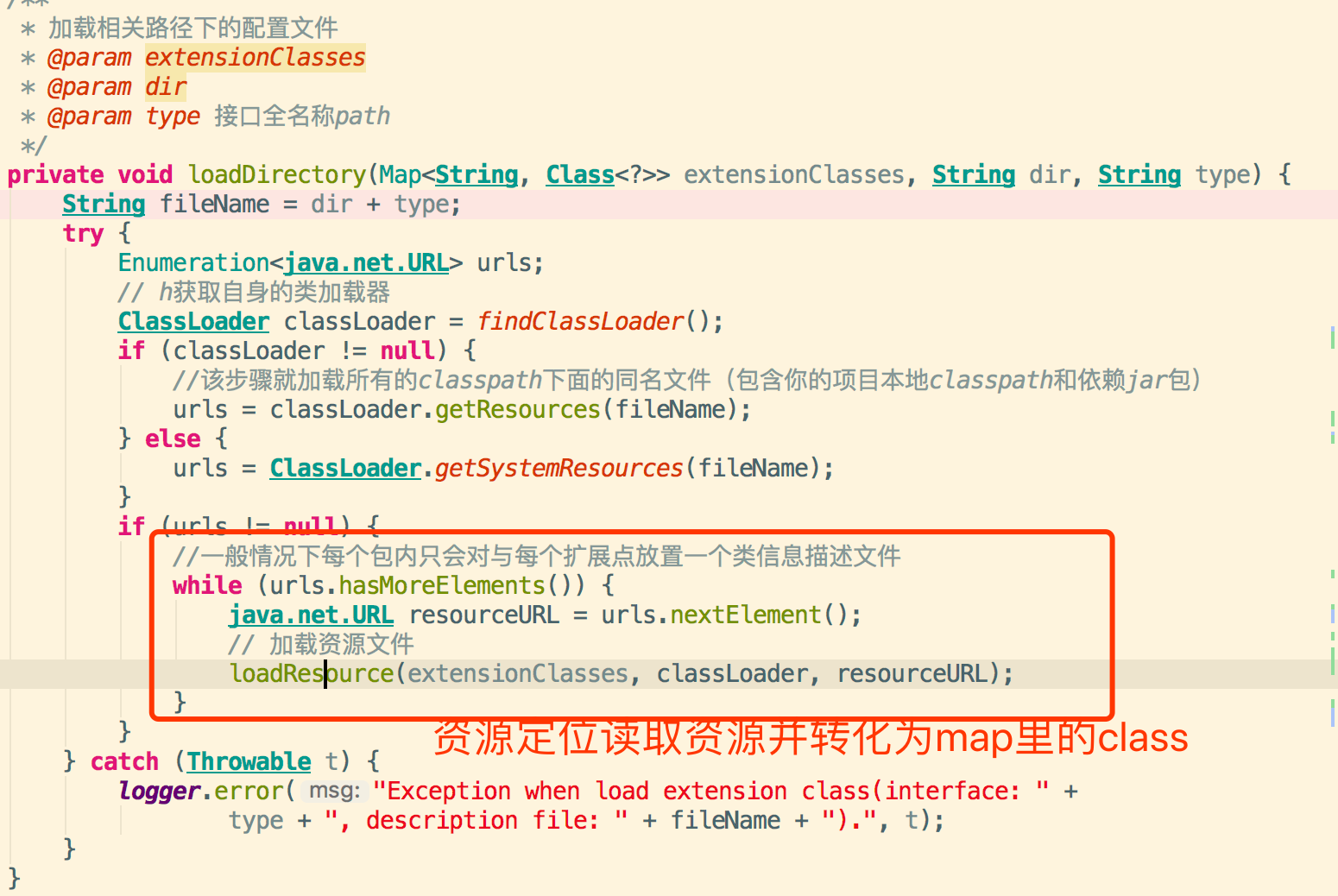
3.4.资源定位获取配置文件的内容进行具体扩展实现类的加载,里面配置key-value为类型和类路径全名称
例如:adaptive=org.apache.dubbo.common.extension.factory.AdaptiveExtensionFactory
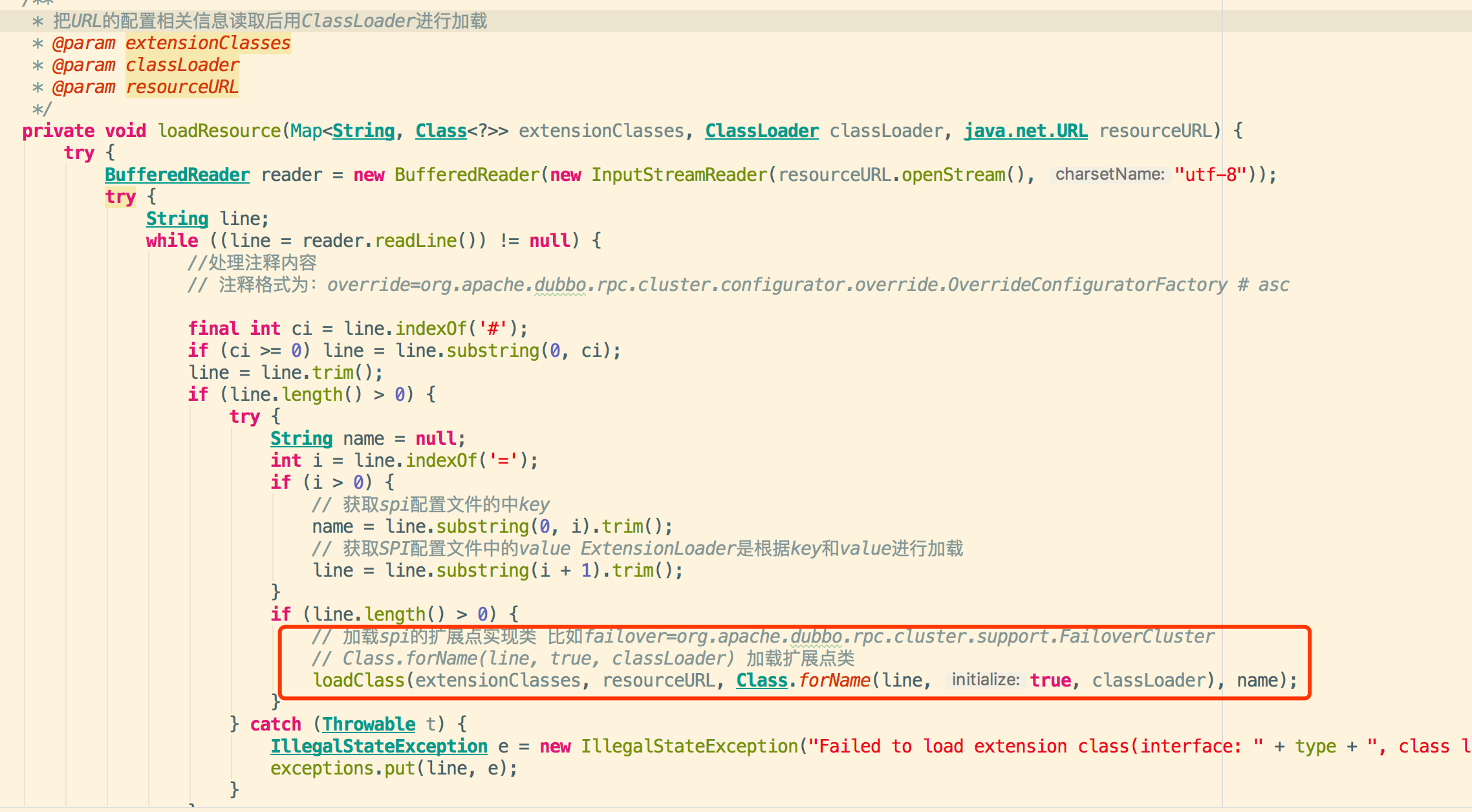
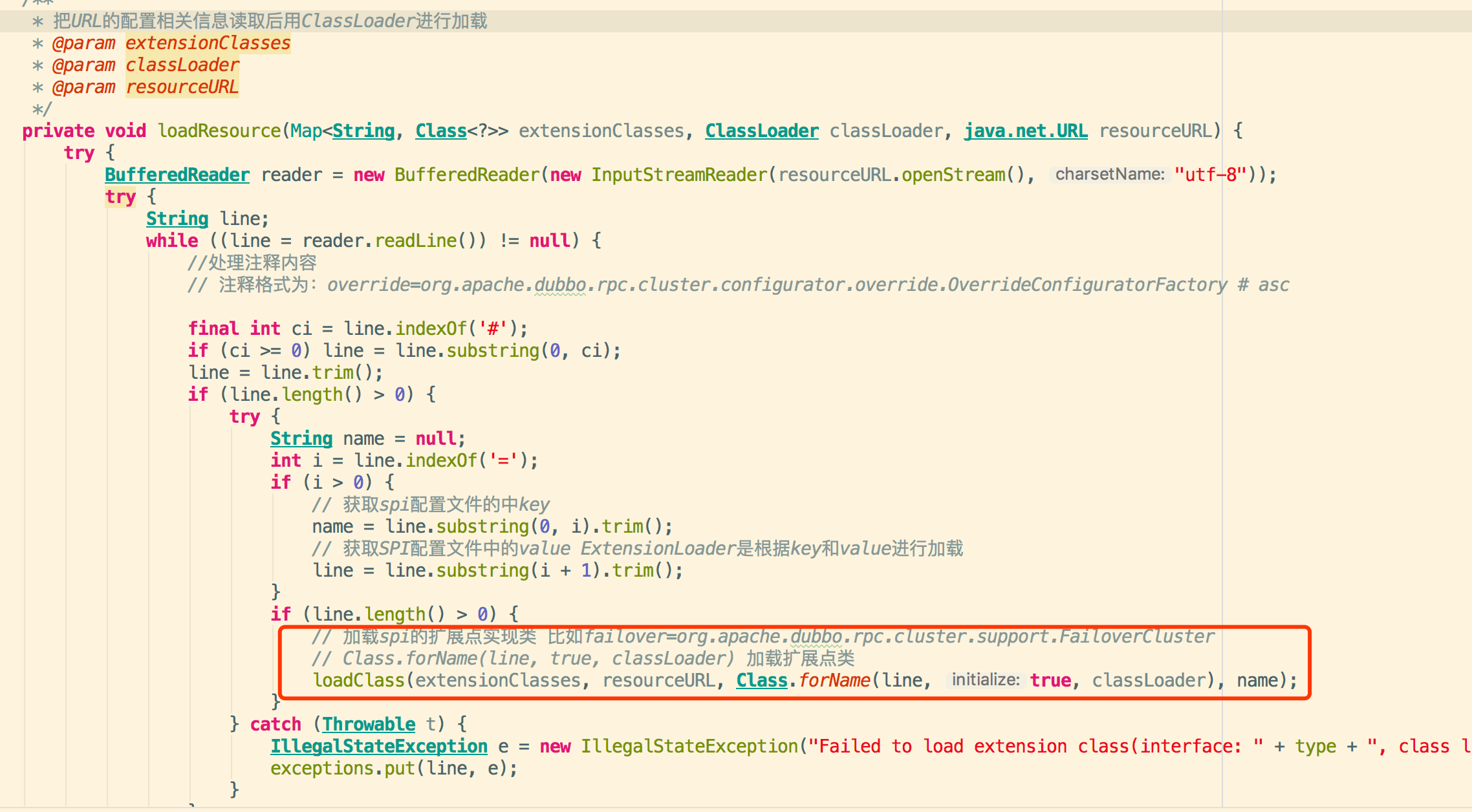
3.5 然后进行指定扩展类实现的加载并进行缓存

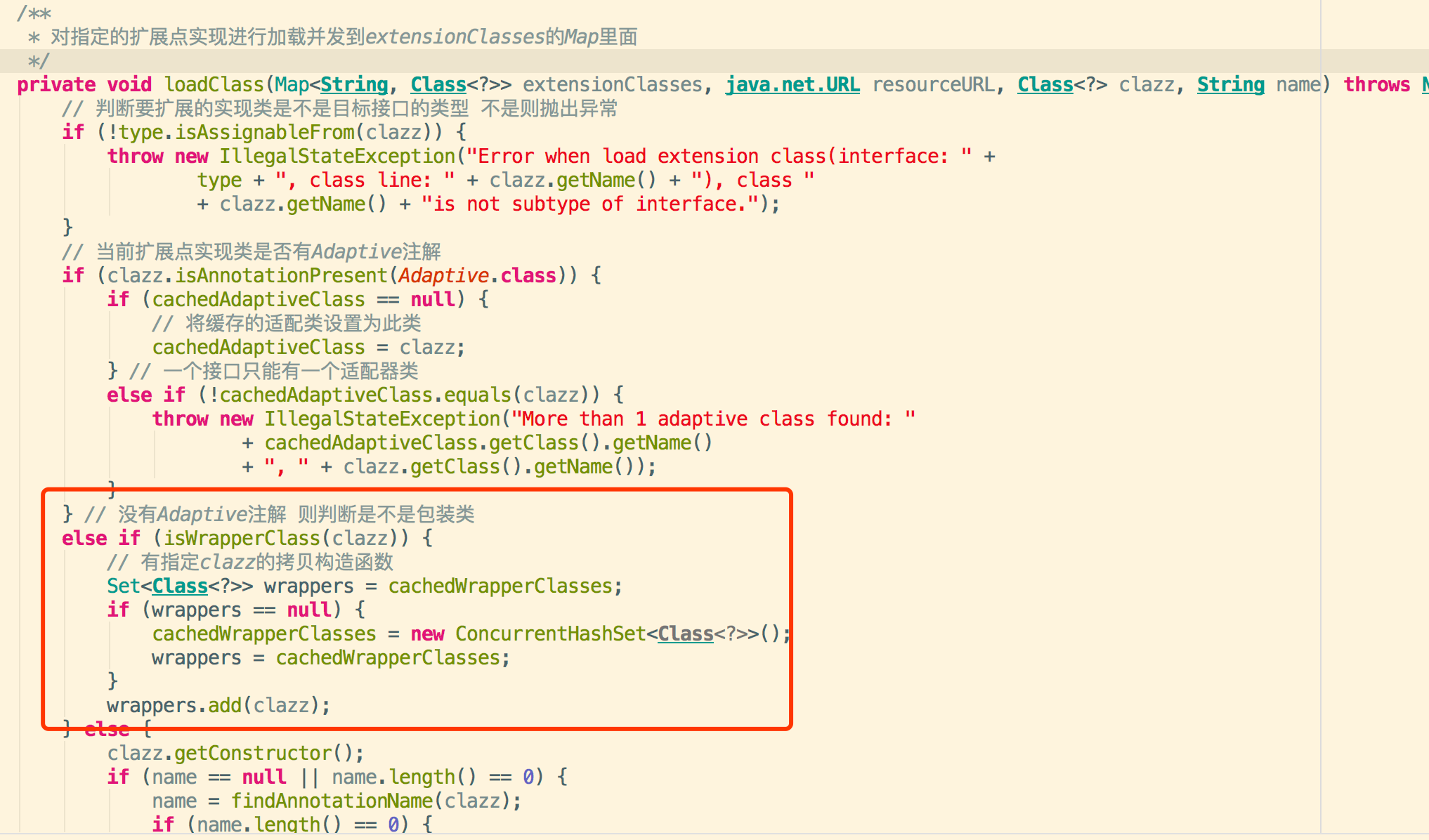
3.5.1如果扩展类既不是有adaptive注解修饰,也不是包装类:如果扩展点实例名称长度为空
则自己手动获取赋值给name,然后如果name以,分割的话则进行分割成数组处理,然后获取该扩展点实例是否有Activate注解,有的话则进行激活点缓存处理,

findAnnotation实现:name为配置文件中的key

此时如果还没找到适配的扩展点实例,则回到上面的3.2步骤会创建一个默认的扩展点;
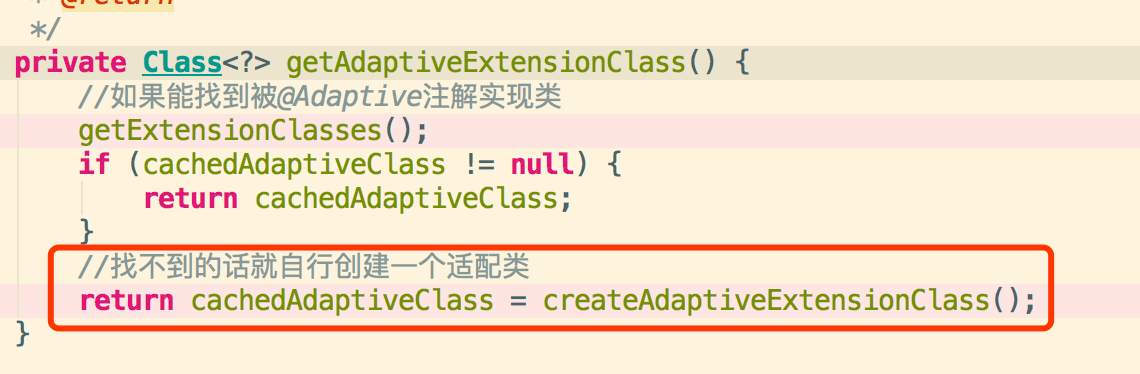
3.6获取code和类加载器,这样通过编译器生成一个class
private Class<?> createAdaptiveExtensionClass() {
String code = createAdaptiveExtensionClassCode();
ClassLoader classLoader = findClassLoader();
org.apache.dubbo.common.compiler.Compiler compiler = ExtensionLoader.getExtensionLoader(org.apache.dubbo.common.compiler.Compiler.class).getAdaptiveExtension();
return compiler.compile(code, classLoader);
}
大概的逻辑流程如下:
1.为了获得一个扩展点的适配类,首先会看缓存中有没有已经加载过的适配类,如果有的话就直接返回,没有的话就进入第2步。
2.加载所有的配置文件,将所有的配置类都load进内存并且在ExtensionLoader内部做好缓存,如果配置的文件中有适配类就缓存起来,如果没有适配类就自行通过代码自行创建适配类并且缓存起来(代码之后给出样例)。
3.在加载配置文件的时候,会依次将包装类,自激活的类都进行缓存。
4.将获取完适配类时候,如果适配类的set方法对应的属性也是扩展点话,会依次注入对应的属性的适配类(循环进行)。
下面看一下Dubbo自己生成的适配类代码是怎样的(以Protocol为例):
import com.alibaba.dubbo.common.extension.ExtensionLoader;
public class Protocol$Adpative implements Protocol {
public Invoker refer(Class arg0, URL arg1) throws Class {
if (arg1 == null) throw new IllegalArgumentException("url == null");
URL url = arg1;
String extName = ( url.getProtocol() == null ? "dubbo" : url.getProtocol() );
if(extName == null) throw new IllegalStateException("Fail to get extension(Protocol) name from url(" + url.toString() + ") use keys([protocol])");
Protocol extension = (Protocol)ExtensionLoader.getExtensionLoader(Protocol.class).getExtension(extName);
return extension.refer(arg0, arg1);
}
public Exporter export(Invoker arg0) throws Invoker {
if (arg0 == null) throw new IllegalArgumentException("Invoker argument == null");
if (arg0.getUrl() == null) throw new IllegalArgumentException("Invoker argument getUrl() == null");URL url = arg0.getUrl();
//这里会根据url中的信息获取具体的实现类名
String extName = ( url.getProtocol() == null ? "dubbo" : url.getProtocol() );
if(extName == null) throw new IllegalStateException("Fail to get extension(Protocol) name from url(" + url.toString() + ") use keys([protocol])");
//根据上面的实现类名,会在运行时,通过Dubbo的扩展机制加载具体实现类
Protocol extension = (Protocol)ExtensionLoader.getExtensionLoader(Protocol.class).getExtension(extName);
return extension.export(arg0);
}
public void destroy() {
throw new UnsupportedOperationException("method public abstract void Protocol.destroy() of interface Protocol is not adaptive method!");
}
public int getDefaultPort() {
throw new UnsupportedOperationException("method public abstract int Protocol.getDefaultPort() of interface Protocol is not adaptive method!");
}
}
本质上的做法就是通过方法的参数获得URL信息,从URL中获得对应的value对应值,然后从ExtensionLoader的缓存中找到value对应的具体实现类,然后用该实现类进行工作。可以看到上面的核心就是getExtension方法了,下面来看一下该方法的实现:
public T getExtension(String name) {
if (name == null || name.length() == 0)
throw new IllegalArgumentException("Extension name == null");
//DefaultExtension就是自适应的扩展类
if ("true".equals(name)) {
return getDefaultExtension();
}
//先从缓存中去取
Holder<Object> holder = cachedInstances.get(name);
if (holder == null) {
//如果缓存中没有的话在创建一个然后放进去,但是此时并没有实际内容,只有一个空的容器Holder
cachedInstances.putIfAbsent(name, new Holder<Object>());
holder = cachedInstances.get(name);
}
Object instance = holder.get();
if (instance == null) {
synchronized (holder) {
instance = holder.get();
if (instance == null) {
//根据名字创建特定的扩展
instance = createExtension(name);
holder.set(instance);
}
}
}
return (T) instance;
}
private T createExtension(String name) {
//获取name类型对应的扩展类型,从cachedClasses根据key获取对应的class,cachedClasses已经在load操作的时候初始化过了。
Class<?> clazz = getExtensionClasses().get(name);
if (clazz == null) {
throw findException(name);
}
try {
//获得扩展类型对应的实例
T instance = (T) EXTENSION_INSTANCES.get(clazz);
if (instance == null) {
//将实例放进缓存中
EXTENSION_INSTANCES.putIfAbsent(clazz, (T) clazz.newInstance());
instance = (T) EXTENSION_INSTANCES.get(clazz);
}
//injectExtension方法的作用就是通过set方法注入其他的属性扩展点,上面已经讲过
injectExtension(instance);
Set<Class<?>> wrapperClasses = cachedWrapperClasses;
if (wrapperClasses != null && wrapperClasses.size() > 0) {
for (Class<?> wrapperClass : wrapperClasses) {
//循环遍历所有wrapper实现,实例化wrapper并进行扩展点注入
instance = injectExtension((T) wrapperClass.getConstructor(type).newInstance(instance));
}
}
return instance;
} catch (Throwable t) {
throw new IllegalStateException("Extension instance(name: " + name + ", class: " +
type + ") could not be instantiated: " + t.getMessage(), t);
}
}
ExtensionLoader的源码分析流程大概如上,在Dubbo源码中这种使用是非常常见的,所以对源码的阅读很有必要了解Dubbo的类加载机制,如有疏漏之处还望多多指教,后面其他的Dubbo源码还在路上,如感兴趣可以关注一下
源码分析的github:https://github.com/martixZero/dubbo-parent 参考文档:
https://www.jianshu.com/p/a72856c77b6a
Dubbo官方开发者指南:http://dubbo.apache.org/zh-cn/docs/dev/implementation.html
Dubbo源码分析之ExtensionLoader加载过程解析的更多相关文章
- 从SpringBoot源码分析 配置文件的加载原理和优先级
本文从SpringBoot源码分析 配置文件的加载原理和配置文件的优先级 跟入源码之前,先提一个问题: SpringBoot 既可以加载指定目录下的配置文件获取配置项,也可以通过启动参数( ...
- 【MyBatis源码分析】Configuration加载(下篇)
元素设置 继续MyBatis的Configuration加载源码分析: private void parseConfiguration(XNode root) { try { Properties s ...
- 【Spring源码分析】Bean加载流程概览
代码入口 之前写文章都会啰啰嗦嗦一大堆再开始,进入[Spring源码分析]这个板块就直接切入正题了. 很多朋友可能想看Spring源码,但是不知道应当如何入手去看,这个可以理解:Java开发者通常从事 ...
- 【Spring源码分析】Bean加载流程概览(转)
转载自:https://www.cnblogs.com/xrq730/p/6285358.html 代码入口 之前写文章都会啰啰嗦嗦一大堆再开始,进入[Spring源码分析]这个板块就直接切入正题了. ...
- Spring源码分析:Bean加载流程概览及配置文件读取
很多朋友可能想看Spring源码,但是不知道应当如何入手去看,这个可以理解:Java开发者通常从事的都是Java Web的工作,对于程序员来说,一个Web项目用到Spring,只是配置一下配置文件而已 ...
- Android 7.0 Gallery图库源码分析3 - 数据加载及显示流程
前面分析Gallery启动流程时,说了传给DataManager的data的key是AlbumSetPage.KEY_MEDIA_PATH,value值,是”/combo/{/local/all,/p ...
- Tomcat8源码笔记(三)Catalina加载过程
之前介绍过 Catalina加载过程是Bootstrap的load调用的 Tomcat8源码笔记(二)Bootstrap启动 按照Catalina的load过程,大致如下: 接下来一步步分析加载过程 ...
- 【MyBatis源码分析】Configuration加载(上篇)
config.xml解析为org.w3c.dom.Document 本文首先来简单看一下MyBatis中将config.xml解析为org.w3c.dom.Document的流程,代码为上文的这部分: ...
- 【Spring源码分析系列】加载Bean
/** * Create a new XmlBeanFactory with the given input stream, * which must be parsable using DOM. * ...
随机推荐
- 深入理解JavaScript系列(26):设计模式之构造函数模式
介绍 构造函数大家都很熟悉了,不过如果你是新手,还是有必要来了解一下什么叫构造函数的.构造函数用于创建特定类型的对象——不仅声明了使用的对象,构造函数还可以接受参数以便第一次创建对象的时候设置对象的成 ...
- L1-002 打印沙漏 (20 分)
L1-002 打印沙漏 (20 分) 方法:清晰思路,纸上写出实例,注意循环使用 本题要求你写个程序把给定的符号打印成沙漏的形状.例如给定17个“*”,要求按下列格式打印 ***** *** * ** ...
- Android4.4源码学习笔记
1.StatusBar和Recents是如何建立联系的 在BaseStatusBar的start()函数通过getComponent(RecentsComponent.class)得到了Recents ...
- HDU 4731 找规律,打表
http://acm.hust.edu.cn/vjudge/contest/126262#problem/D 分为3种情况,n=1,n=2,n>=3 其中需要注意的是n=2的情况,通过打表找规律 ...
- Jquery系列:textarea常用操作
1.textarea内容的读取与设置 读textarea文本值可以用name和id.而写入文本值只能用id. <textarea name="content" id=&quo ...
- Spring课程 Spring入门篇 5-1 aop基本概念及特点
概念: 1 什么是aop及实现方式 2 aop的基本概念 3 spring中的aop 1 什么是aop及实现方式 1.1 aop,面向切面编程,比如:唐僧取经需要经过81难,多一难少一难都不行.孙悟空 ...
- 自封装ajax
项目中有时候用不到jq,需要了解xmlhttp原理,自己写一套函数请求和发送数据! /* 封装ajax函数 * @param {string}opt.type http连接的方式,包括POST和GET ...
- Python单元测试框架unittest使用方法讲解
这篇文章主要介绍了Python单元测试框架unittest使用方法讲解,本文讲解了unittest概述.命令行接口.测试案例自动搜索.创建测试代码.构建测试套件方法等内容,需要的朋友可以参考下 概 ...
- 【Leetcode】【Easy】Merge Sorted Array
Given two sorted integer arrays A and B, merge B into A as one sorted array. Note:You may assume tha ...
- vmware克隆的linux机器网络不通
当我使用vmware的完全克隆功能克隆出两台虚拟机之后,登录发现网络不通,仔细检查发现几个问题,由于克隆之后默认的eth0网卡在系统中会变成eth1,导致之前的eth0网卡配置信息无法加载,网络不通, ...