spark运行时出现Neither spark.yarn.jars nor spark.yarn.archive is set错误的解决办法(图文详解)
不多说,直接上干货!
福利 => 每天都推送
问题详情
每次提交spark任务到yarn的时候,总会出现uploading resource(打包spark jars并上传)到hdfs上。恶劣情况下,会在这里卡住很久。
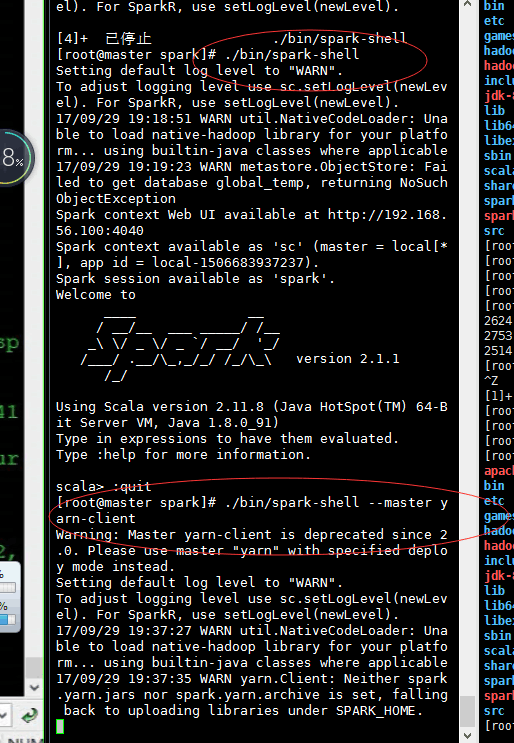
// :: INFO Client: Preparing resources for our AM container
// :: WARN Client: Neither spark.yarn.jars nor spark.yarn.archive is set, falling back to uploadi
ng libraries under SPARK_HOME.
// :: INFO Client: Uploading resource file:/tmp/spark-28ebde0d-c77a-4be3--a6d3bcccc253/__spar
k_libs__7542776655448713545.zip -> hdfs://dipperCluster/user/hadoop/.sparkStaging/application_1484215273436_0
/__spark_libs__7542776655448713545.zip
// :: INFO Client: Uploading resource file:/tmp/spark-28ebde0d-c77a-4be3--a6d3bcccc253/__spar
k_conf__8972755978315292177.zip -> hdfs://dipperCluster/user/hadoop/.sparkStaging/application_1484215273436_0
/__spark_conf__.zip
其实可以发现,上图中,已经有提示了,说被弃用了。
解决办法1
在hdfs上创建目录:
hdfs dfs -mkdir /home/hadoop/spark_jars
上传spark的jars(spark1.6 只需要上传spark-assembly-1.6.0-SNAPSHOT-hadoop2.6.0.jar)
hdfs dfs -put /opt/spark/jars/* /home/hadoop/spark_jars/
在spark的conf的spark-default.conf ,添加如下的配置
spark.yarn.jars=hdfs://master:9000/opt/spark/jars/* /home/hadoop/spark_jars/
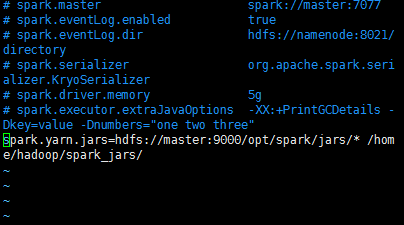
即可解决。不会出现这个问题。
当,再次启动时,则
Source and destination file systems are the same. Not copying hdfs://master:9000/home/hadoop/spark_jars/zookeeper-3.4.6.jar
之后快速开始提交任务,启动任务。
解决办法2
其实啊,说白了,就是spark2.1.0或spark2.2.0以上的版本的命令有所变化。所以压根可以需改动解决办法1所示的配置,直接用官网这样的命令来操作就可以了。
http://spark.apache.org/docs/latest/running-on-yarn.html

同时,大家可以关注我的个人博客:
http://www.cnblogs.com/zlslch/ 和 http://www.cnblogs.com/lchzls/ http://www.cnblogs.com/sunnyDream/
详情请见:http://www.cnblogs.com/zlslch/p/7473861.html
人生苦短,我愿分享。本公众号将秉持活到老学到老学习无休止的交流分享开源精神,汇聚于互联网和个人学习工作的精华干货知识,一切来于互联网,反馈回互联网。
目前研究领域:大数据、机器学习、深度学习、人工智能、数据挖掘、数据分析。 语言涉及:Java、Scala、Python、Shell、Linux等 。同时还涉及平常所使用的手机、电脑和互联网上的使用技巧、问题和实用软件。 只要你一直关注和呆在群里,每天必须有收获
对应本平台的讨论和答疑QQ群:大数据和人工智能躺过的坑(总群)(161156071)![]()
![]()
![]()
![]()
![]()




打开百度App,扫码,精彩文章每天更新!欢迎关注我的百家号: 九月哥快讯
spark运行时出现Neither spark.yarn.jars nor spark.yarn.archive is set错误的解决办法(图文详解)的更多相关文章
- Spark Mllib里决策树回归分析如何对numClasses无控制和将部分参数设置为variance(图文详解)
不多说,直接上干货! 在决策树二元或决策树多元分类参数设置中: 使用DecisionTree.trainClassifier 见 Spark Mllib里如何对决策树二元分类和决策树多元分类的分类 ...
- Spark Mllib里决策树回归分析使用.rootMeanSquaredError方法计算出以RMSE来评估模型的准确率(图文详解)
不多说,直接上干货! Spark Mllib里决策树二元分类使用.areaUnderROC方法计算出以AUC来评估模型的准确率和决策树多元分类使用.precision方法以precision来评估模型 ...
- ClouderManger搭建大数据集群时ERROR 2003 (HY000): Can't connect to MySQL server on 'ubuntucmbigdata1' (111)的问题解决(图文详解)
问题详情 相关问题的场景,是在我下面的这篇博客里 Cloudera Manager安装之利用parcels方式(在线或离线)安装3或4节点集群(包含最新稳定版本或指定版本的安装)(添加服务)(Ubun ...
- Spark Mllib里相似度度量(基于余弦相似度计算不同用户之间相似性)(图文详解)
不多说,直接上干货! 常见的推荐算法 1.基于关系规则的推荐 2.基于内容的推荐 3.人口统计式的推荐 4.协调过滤式的推荐 协调过滤算法,是一种基于群体用户或者物品的典型推荐算法,也是目前常用的推荐 ...
- Spark Mllib里如何对决策树二元分类和决策树多元分类的分类数目numClasses控制(图文详解)
不多说,直接上干货! 决策树二元分类的分类数目numClasses控制 具体,见 Hadoop+Spark大数据巨量分析与机器学习整合开发实战的第13章 使用决策树二元分类算法来预测分类Stumble ...
- Spark Mllib里如何记录开始训练时间、完成训练时间、所需训练时间(图文详解)
不多说,直接上干货! 具体,见 Hadoop+Spark大数据巨量分析与机器学习整合开发实战的第16章 朴素贝叶斯二元分类算法来预测分类StumbleUpon数据集
- Spark Mllib里如何将trainDara训练数据文件里提取第M到第N字段(图文详解)
不多说,直接上干货! 具体,见 Hadoop+Spark大数据巨量分析与机器学习整合开发实战的第13章 使用决策树二元分类算法来预测分类StumbleUpon数据集
- Spark Mllib里如何将数据集按比例随机地分成trainData、testData和validationData数据集(图文详解)
不多说,直接上干货! 具体详情见 Hadoop+Spark大数据巨量分析与机器学习整合开发实战的第11章 电影推荐引擎
- Android SDK Manager检查更新时遇到Failed to fetch URL xxxxxxx reason: Connection to xxxxxx的错误的解决办法!
首先说明的是这个问题并不是每个人都存在,但是我和我的一个同学都有这种情况,所以我同学百度了一下,找出了解决办法. 问题描述: 使用Android SDK Manager检查在线更新,提示以下错误: & ...
随机推荐
- Robot Framework 使用总结
最近项目上使用了RF快速实现了一些验收测试的自动化case,感觉不错,很好用,下面就记录一下使用RF实现自动化的过程. 什么是RF? RF是一种测试框架,帮助测试人员在其框架下快速实现验收测试的自动化 ...
- 关于Flag 老是忘掉的东西
OrderState enums = OrderState.CustomerCanceled | OrderState.CustomerOrdered | OrderState.CustomerQue ...
- asp.net mvc 请求处理流程,记录一下。
asp.net mvc 请求处理流程,记录一下.
- chkconfig的原理 和添加开机自启动的办法
当我们使用 chkconfig --list的时候 都会又 123456 这样的级别. 当某个级别是 on 他就会开机启动,当他是off 的时候他就不会开机自启动. 那么这是什么原因呢?他的 原理是 ...
- ubuntu命令行安装tomcat8
环境: 虚拟机VM14 Ubuntu16.04 java 1.8 步骤: 先更新 sudo apt-get update 然后安装: sudo apt-get install tomcat8 等一会 ...
- python中一些算法数列
斐波那契数列: 1 def fn(n): 2 if n==1: 3 return 1 4 elif n==2: 5 return 1 6 else: 7 return fn(n-1)+fn(n-2) ...
- 【bzoj4036】[HAOI2015]按位或 fmt+期望
Description 刚开始你有一个数字0,每一秒钟你会随机选择一个[0,2^n-1]的数字,与你手上的数字进行或(c++,c的|,pascal 的or)操作.选择数字i的概率是p[i].保证0&l ...
- HDU6330-2018ACM暑假多校联合训练Problem L. Visual Cube
就是画个图啦 分三个平面去画orz #include <iostream> #include <cmath> #include <cstring> #include ...
- swoole安装报错详解 mysqlnd_find_charset_nr in Unknow
今天安装 swoole扩展时候,最后一步报错如下: PHP Warning: PHP Startup: Unable to load dynamic library '/usr/lib64/php/m ...
- app.use和app.get的区别及解析
转载至:http://blog.csdn.net/wthfeng/article/details/53366169 写在前面:最近研究nodejs及其web框架express,对app.use和app ...