深度增强学习--Policy Gradient
前面都是value based的方法,现在看一种直接预测动作的方法 Policy Based
Policy Gradient
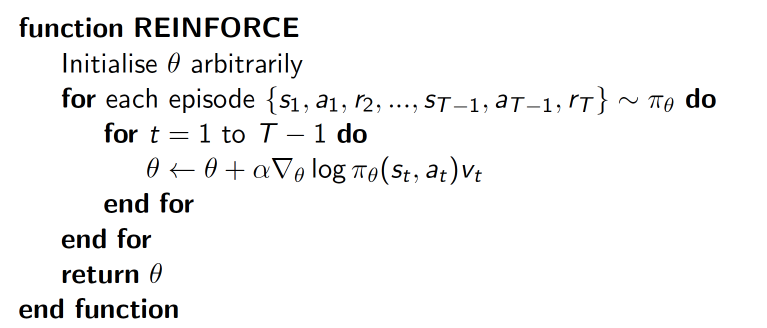
下面的例子实现的REINFORCE算法
import sys
import gym
import pylab
import numpy as np
from keras.layers import Dense
from keras.models import Sequential
from keras.optimizers import Adam EPISODES = 1000 #policy gradient的一种,REINFORCE算法
# This is Policy Gradient agent for the Cartpole
# In this example, we use REINFORCE algorithm which uses monte-carlo update rule
class REINFORCEAgent:
def __init__(self, state_size, action_size):
# if you want to see Cartpole learning, then change to True
self.render = True
self.load_model = False
# get size of state and action
self.state_size = state_size#
self.action_size = action_size# # These are hyper parameters for the Policy Gradient
self.discount_factor = 0.99
self.learning_rate = 0.001
self.hidden1, self.hidden2 = 24, 24 # create model for policy network
self.model = self.build_model() # lists for the states, actions and rewards
self.states, self.actions, self.rewards = [], [], [] if self.load_model:
self.model.load_weights("./save_model/cartpole_reinforce.h5") # approximate policy using Neural Network
# state is input and probability of each action is output of network
def build_model(self):
model = Sequential()
model.add(Dense(self.hidden1, input_dim=self.state_size, activation='relu', kernel_initializer='glorot_uniform'))
model.add(Dense(self.hidden2, activation='relu', kernel_initializer='glorot_uniform'))
model.add(Dense(self.action_size, activation='softmax', kernel_initializer='glorot_uniform'))
model.summary()
# Using categorical crossentropy as a loss is a trick to easily
# implement the policy gradient. Categorical cross entropy is defined
# H(p, q) = sum(p_i * log(q_i)). For the action taken, a, you set
# p_a = advantage. q_a is the output of the policy network, which is
# the probability of taking the action a, i.e. policy(s, a).
# All other p_i are zero, thus we have H(p, q) = A * log(policy(s, a))
model.compile(loss="categorical_crossentropy", optimizer=Adam(lr=self.learning_rate))
return model # using the output of policy network, pick action stochastically
def get_action(self, state):
policy = self.model.predict(state, batch_size=1).flatten()#
return np.random.choice(self.action_size, 1, p=policy)[0]#choose action accordding to probability # In Policy Gradient, Q function is not available.
# Instead agent uses sample returns for evaluating policy
def discount_rewards(self, rewards):
discounted_rewards = np.zeros_like(rewards)
running_add = 0
for t in reversed(range(0, len(rewards))):
running_add = running_add * self.discount_factor + rewards[t]
discounted_rewards[t] = running_add
return discounted_rewards # save <s, a ,r> of each step
def append_sample(self, state, action, reward):
self.states.append(state)
self.rewards.append(reward)
self.actions.append(action) # update policy network every episode
def train_model(self):
'''
example:
self.states:[array([[-0.00647736, -0.04499117, 0.02213829, -0.00486359]]), array([[-0.00737719, -0.24042351, 0.02204101, 0.2947212 ]]), array([[-0.01218566, -0.04562261, 0.02793544, 0.00907036]]), array([[-0.01309811, -0.24113382, 0.02811684, 0.31043471]]), array([[-0.01792078, -0.04642351, 0.03432554, 0.02674995]]), array([[-0.01884925, -0.24202048, 0.03486054, 0.33006229]]), array([[-0.02368966, -0.04741166, 0.04146178, 0.04857336]]), array([[-0.0246379 , -0.24310286, 0.04243325, 0.35404415]]), array([[-0.02949995, -0.43880168, 0.04951413, 0.65979978]]), array([[-0.03827599, -0.2444025 , 0.06271013, 0.38310959]]), array([[-0.04316404, -0.44035616, 0.07037232, 0.69488702]]), array([[-0.05197116, -0.63637999, 0.08427006, 1.00886738]]), array([[-0.06469876, -0.83251953, 0.10444741, 1.32677873]]), array([[-0.08134915, -0.63885961, 0.13098298, 1.06852366]]), array([[-0.09412634, -0.44569036, 0.15235346, 0.8196508 ]]), array([[-0.10304015, -0.25294509, 0.16874647, 0.57850069]]), array([[-0.10809905, -0.44997994, 0.18031649, 0.91923131]]), array([[-0.11709865, -0.25769299, 0.19870111, 0.68820344]])]
self.rewards:[1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, -100]
self.actions:[0, 1, 0, 1, 0, 1, 0, 0, 1, 0, 0, 0, 1, 1, 1, 0, 1, 1]
'''
episode_length = len(self.states)# discounted_rewards = self.discount_rewards(self.rewards)
'''
example:
disconnted_rewards:array([ -68.58863868, -70.29155422, -72.01167093, -73.74916255,-75.5042046 , -77.27697434, -79.06765085, -80.876415 , -82.7034495 , -84.54893889, -86.41306958, -88.29602988,-90.19800998, -92.119202 , -94.0598,-96.02,-98., -100. ])
'''
discounted_rewards -= np.mean(discounted_rewards)
discounted_rewards /= np.std(discounted_rewards)#将作为神经网络预测对象
'''
array([ 1.59468271, 1.41701722, 1.23755712, 1.05628429, 0.87318042,
0.68822702, 0.50140541, 0.3126967 , 0.12208185, -0.0704584 ,
-0.26494351, -0.46139311, -0.65982705, -0.86026537, -1.06272832,
-1.26723636, -1.47381013, -1.6824705 ])
'''
update_inputs = np.zeros((episode_length, self.state_size))#shape(18,4)
advantages = np.zeros((episode_length, self.action_size))#shape(18,2) for i in range(episode_length):
update_inputs[i] = self.states[i]
advantages[i][self.actions[i]] = discounted_rewards[i] self.model.fit(update_inputs, advantages, epochs=1, verbose=0)
self.states, self.actions, self.rewards = [], [], [] if __name__ == "__main__":
# In case of CartPole-v1, you can play until 500 time step
env = gym.make('CartPole-v1')
# get size of state and action from environment
state_size = env.observation_space.shape[0]
action_size = env.action_space.n # make REINFORCE agent
agent = REINFORCEAgent(state_size, action_size) scores, episodes = [], [] for e in range(EPISODES):
import pdb; pdb.set_trace()
done = False
score = 0
state = env.reset()
state = np.reshape(state, [1, state_size]) while not done:
if agent.render:
env.render() # get action for the current state and go one step in environment
action = agent.get_action(state)
next_state, reward, done, info = env.step(action)
next_state = np.reshape(next_state, [1, state_size])
reward = reward if not done or score == 499 else -100 # save the sample <s, a, r> to the memory
agent.append_sample(state, action, reward) score += reward
state = next_state if done:
# every episode, agent learns from sample returns
agent.train_model() # every episode, plot the play time
score = score if score == 500 else score + 100
scores.append(score)
episodes.append(e)
pylab.plot(episodes, scores, 'b')
pylab.savefig("./save_graph/cartpole_reinforce.png")
print("episode:", e, " score:", score) # if the mean of scores of last 10 episode is bigger than 490
# stop training
if np.mean(scores[-min(10, len(scores)):]) > 490:
sys.exit() # save the model
if e % 50 == 0:
agent.model.save_weights("./save_model/cartpole_reinforce.h5")
深度增强学习--Policy Gradient的更多相关文章
- 强化学习--Policy Gradient
Policy Gradient综述: Policy Gradient,通过学习当前环境,直接给出要输出的动作的概率值. Policy Gradient 不是单步更新,只能等玩完一个epoch,再 ...
- 深度增强学习--DDPG
DDPG DDPG介绍2 ddpg输出的不是行为的概率, 而是具体的行为, 用于连续动作 (continuous action) 的预测 公式推导 推导 代码实现的gym的pendulum游戏,这个游 ...
- 深度增强学习--A3C
A3C 它会创建多个并行的环境, 让多个拥有副结构的 agent 同时在这些并行环境上更新主结构中的参数. 并行中的 agent 们互不干扰, 而主结构的参数更新受到副结构提交更新的不连续性干扰, 所 ...
- 深度增强学习--Actor Critic
Actor Critic value-based和policy-based的结合 实例代码 import sys import gym import pylab import numpy as np ...
- 深度增强学习--Deep Q Network
从这里开始换个游戏演示,cartpole游戏 Deep Q Network 实例代码 import sys import gym import pylab import random import n ...
- 深度增强学习--DPPO
PPO DPPO介绍 PPO实现 代码DPPO
- 深度增强学习--DQN的变形
DQN的变形 double DQN prioritised replay dueling DQN
- Deep Learning专栏--强化学习之从 Policy Gradient 到 A3C(3)
在之前的强化学习文章里,我们讲到了经典的MDP模型来描述强化学习,其解法包括value iteration和policy iteration,这类经典解法基于已知的转移概率矩阵P,而在实际应用中,我们 ...
- 增强学习 | AlphaGo背后的秘密
"敢于尝试,才有突破" 2017年5月27日,当今世界排名第一的中国棋手柯洁与AlphaGo 2.0的三局对战落败.该事件标志着最新的人工智能技术在围棋竞技领域超越了人类智能,借此 ...
随机推荐
- django返回二进制图片
@login_required def down_img(request, path): content = Storage().download(path) from django.http imp ...
- C++高精度
整理了一下高精度,虽然可用java,但很多时候还是C++写的方便. 附上kuangbin神的高精度模板(HDU1134 求卡特兰数) #include <iostream> #includ ...
- 搭建 Linux 下 GitLab 服务器【转】
转自:http://blog.csdn.net/passion_wu128/article/details/8216086 版权声明:本文为博主原创文章,未经博主允许不得转载. 目录(?)[-] 平台 ...
- python memcache 常用操作
add() 添加一条键值对,如果key已存在,重复执行add操作会报异常 mc.add('name2', 'lisi') print(mc.get('name2')) # lisi replace 修 ...
- Android的简单应用(四)——字符串处理
在Java中,对字符串进行处理的方法很多,也可以通过导入相应的字符串处理的lib包来进行处理.不过今天要说的是Android中看到的两种处理字符串的方法. 一.正则表达式 其实正则表达式没有大家想象的 ...
- SSH的简单入门体验(Struts2.1+Spring3.1+Hibernate4.1)- 查询系统(下)
我们继续吧,SSH最大的优点就是实现的系统的松耦合,能够将后台和前台有机的分离开来. 一.目录结构 一个好的程序要有一个好的开始.我们先来看看整个目录结构吧 主要的是三层架构概念,或者说是mvc的概念 ...
- inside a shard
fsync sync fsync/syncsync is a standard system call in the Unix operating system, which commits to d ...
- KDJ回测
# -*- coding: utf-8 -*- import os import pandas as pd # ========== 遍历数据文件夹中所有股票文件的文件名,得到股票代码列表stock_ ...
- hdu 3870(平面图最小割转最短路)
Catch the Theves Time Limit: 5000/2000 MS (Java/Others) Memory Limit: 65768/32768 K (Java/Others) ...
- Android InputStream转Bitmap
android socket服务端 接收Delphi socket客户端发来的图片,保存到bitmap中,代码如下: public static Bitmap readInputStreamToBit ...