大数据(3) - 高可用 HDFS HA
HDFS HA高可用
1 HA概述
1)所谓HA(high available),即高可用(7*24小时不中断服务)。
2)实现高可用最关键的策略是消除单点故障。HA严格来说应该分成各个组件的HA机制:HDFS的HA和YARN的HA。
3)Hadoop2.0之前,在HDFS集群中NameNode存在单点故障(SPOF)。
4)NameNode主要在以下两个方面影响HDFS集群
NameNode机器发生意外,如宕机,集群将无法使用,直到管理员重启
NameNode机器需要升级,包括软件、硬件升级,此时集群也将无法使用
HDFS HA功能通过配置Active/Standby两个nameNodes实现在集群中对NameNode的热备来解决上述问题。如果出现故障,如机器崩溃或机器需要升级维护,这时可通过此种方式将NameNode很快的切换到另外一台机器。
2 HDFS-HA工作机制
1)通过双namenode消除单点故障
2.1 HDFS-HA工作要点
1)元数据管理方式需要改变:
内存中各自保存一份元数据;
Edits日志只有Active状态的namenode节点可以做写操作;
两个namenode都可以读取edits;
共享的edits放在一个共享存储中管理(qjournal和NFS两个主流实现);
2)需要一个状态管理功能模块
实现了一个zkfailover,常驻在每一个namenode所在的节点,每一个zkfailover负责监控自己所在namenode节点,利用zk进行状态标识,当需要进行状态切换时,由zkfailover来负责切换,切换时需要防止brain split现象的发生。
3)必须保证两个NameNode之间能够ssh无密码登录。
4)隔离(Fence),即同一时刻仅仅有一个NameNode对外提供服务
2.2 HDFS-HA自动故障转移工作机制
前面学习了使用命令hdfs haadmin -failover手动进行故障转移,在该模式下,即使现役NameNode已经失效,系统也不会自动从现役NameNode转移到待机NameNode,下面学习如何配置部署HA自动进行故障转移。自动故障转移为HDFS部署增加了两个新组件:ZooKeeper和ZKFailoverController(ZKFC)进程。ZooKeeper是维护少量协调数据,通知客户端这些数据的改变和监视客户端故障的高可用服务。HA的自动故障转移依赖于ZooKeeper的以下功能:
1)故障检测:集群中的每个NameNode在ZooKeeper中维护了一个持久会话,如果机器崩溃,ZooKeeper中的会话将终止,ZooKeeper通知另一个NameNode需要触发故障转移。
2)现役NameNode选择:ZooKeeper提供了一个简单的机制用于唯一的选择一个节点为active状态。如果目前现役NameNode崩溃,另一个节点可能从ZooKeeper获得特殊的排外锁以表明它应该成为现役NameNode。
ZKFC是自动故障转移中的另一个新组件,是ZooKeeper的客户端,也监视和管理NameNode的状态。每个运行NameNode的主机也运行了一个ZKFC进程,ZKFC负责:
1)健康监测:ZKFC使用一个健康检查命令定期地ping与之在相同主机的NameNode,只要该NameNode及时地回复健康状态,ZKFC认为该节点是健康的。如果该节点崩溃,冻结或进入不健康状态,健康监测器标识该节点为非健康的。
2)ZooKeeper会话管理:当本地NameNode是健康的,ZKFC保持一个在ZooKeeper中打开的会话。如果本地NameNode处于active状态,ZKFC也保持一个特殊的znode锁,该锁使用了ZooKeeper对短暂节点的支持,如果会话终止,锁节点将自动删除。
3)基于ZooKeeper的选择:如果本地NameNode是健康的,且ZKFC发现没有其它的节点当前持有znode锁,它将为自己获取该锁。如果成功,则它已经赢得了选择,并负责运行故障转移进程以使它的本地NameNode为active。故障转移进程与前面描述的手动故障转移相似,首先如果必要保护之前的现役NameNode,然后本地NameNode转换为active状态。
3 HDFS-HA集群配置 -- 手动转移
3.1.将hadoop2.7.2 复制到 modules/HA里面
cd /home/admin/modules mkdir HA cp -r hadoop-2.7.2/ Ha/
3.2 配置,修改core-site.xml 与 hdfs-site.xml 文件
cd /home/admin/modules/HA/hadoop-2.7.2/etc/hadoop vim core-site.xml <configuration>
<!-- 把两个NameNode)的地址组装成一个集群mycluster -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://mycluster</value>
</property> <!-- 指定hadoop运行时产生文件的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/home/admin/modules/HA/hadoop-2.7.2/hadoop-data</value>
</property> <property>
<name>dfs.journalnode.edits.dir</name>
<value>/home/admin/modules/HA/hadoop-2.7.2/jn/mycluster</value>
</property> </configuration>
vim hdfs-site.xml <configuration>
<!-- 完全分布式集群名称 -->
<property>
<name>dfs.nameservices</name>
<value>mycluster</value>
</property> <!-- 集群中NameNode节点都有哪些 -->
<property>
<name>dfs.ha.namenodes.mycluster</name>
<value>nn1,nn2</value>
</property> <!-- nn1的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.mycluster.nn1</name>
<value>linux01:8020</value>
</property> <!-- nn2的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.mycluster.nn2</name>
<value>linux02:8020</value>
</property> <!-- nn1的http通信地址 -->
<property>
<name>dfs.namenode.http-address.mycluster.nn1</name>
<value>linux01:50070</value>
</property> <!-- nn2的http通信地址 -->
<property>
<name>dfs.namenode.http-address.mycluster.nn2</name>
<value>linux02:50070</value>
</property> <!-- 指定NameNode元数据在JournalNode上的存放位置 -->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://linux01:8485;linux02:8485;linux03:8485/mycluster</value>
</property> <!-- 配置隔离机制,即同一时刻只能有一台服务器对外响应 -->
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property> <!-- 使用隔离机制时需要ssh无秘钥登录-->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/home/admin/.ssh/id_rsa</value>
</property> <!-- 指定数据冗余分数 -->
<property>
<name>dfs.replication</name>
<value>1</value>
</property> <!-- 关闭权限检查-->
<property>
<name>dfs.permissions.enable</name>
<value>false</value>
</property> <property>
<name>dfs.webhdfs.enable</name>
<value>true</value>
</property> <!-- 访问代理类:client,mycluster,active配置失败自动切换实现方式-->
<property>
<name>dfs.client.failover.proxy.provider.mycluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
</configuration>
3.3.分发到linux02和linux03中
scp -r HA/ linux02:/home/admin/modules/ scp -r HA/ linux03:/home/admin/modules/
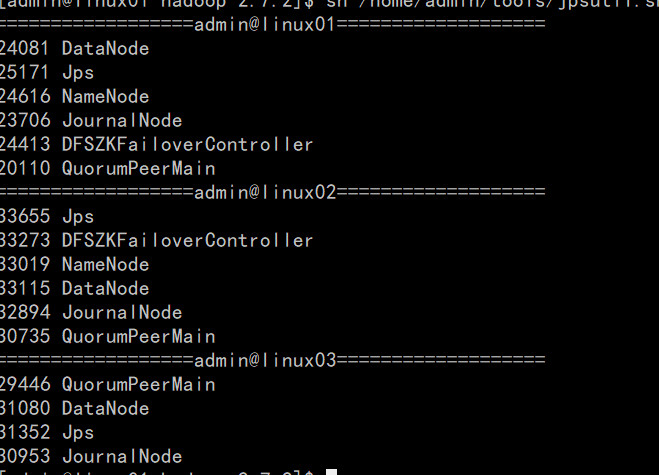
3.4启动三台机器的journalnode(分别在三台机器上面执行且jps查看是否执行成功)
sbin/hadoop-daemon.sh start journalnode
3.5格式化linux01的namenode节点
bin/hdfs namenode -format
3.6启动刚格式化的namenode
sbin/hadoop-daemon.sh start namenode
3.7备用namenode同步主namenode的元数据信息,(在linux02中执行)
bin/hdfs namenode -bootstrapStandby
3.8启动被namenode(在linux02中执行)
sbin/hadoop-daemon.sh start namenode
3.9启动所有datanode(分别在三台机器执行,并用jps查看是否执行成功)
注意,有时datanode会启动失败,原因:
当时“再来一次”,又重新执行了格式化命令(hdfs namenode -format),这时namenode的clusterID会重新生成,而datanode的clusterID 保持不变。
所以,解决办法也很简单了,把/hadoop-2.7.2/hadoop-data/dfs/name/current/VERSION里面的clusterID复制下来,依次替换/hadoop-2.7.2/hadoop-data/dfs/data/current/VERSION里的clusterID,再执行:
sbin/hadoop-daemon.sh start datanode
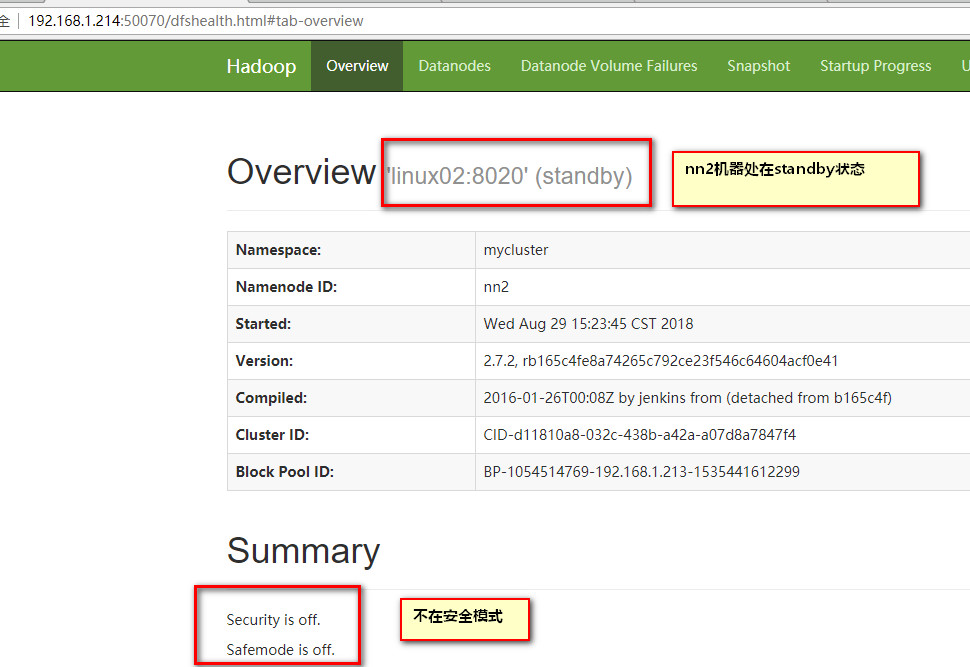
3.10两个namenode目前都处于standby状态,所以是都没有办法Browse Directory (浏览目录的),必须手动激活其中一个namenode的
状态为active才可以,如果想把nn2设置为active状态,必须先把nn1设置为standby状态
转变为active状态
bin/hdfs haadmin -transitionToActive nn1 转变为standby状态
bin/hdfs haadmin -transitionToStandby nn1
3.11重点:把处于active状态的nn1手动关掉,看会发生什么事
关掉linux01的namenode
sbin/hadoop-daemon.sh stop namenode
结论:关掉以后,想去把nn2设置为active状态,但是不成功,这是防止脑裂机制决定的,只能强制切换:
bin/hdfs haadmin -transitionToActive nn2 --forceactive
4.自动故障转移
(前面说了这么多都是为这里铺垫)
先关闭集群
sbin/stop-dfs.sh
4.1安装zookeepercd /home/admin/softwares/installtions/
下载zookeeper安装包 wget 'http://mirror.bit.edu.cn/apache/zookeeper/zookeeper-3.4.10/zookeeper-3.4.10.tar.gz' 解压到HA目录 tar -zxf ~/softwares/installtions/zookeeper-3.4.10.tar.gz -C /home/admin/modules/HA/ 进入/zookeeper-3.4.10/conf文件夹,修改文件名字 mv zoo_sample.cfg zoo.cfg 配置zoo.cfg文件 dataDir=/home/admin/modules/HA/zookeeper-3.4.10/zkData 文件最后配置集群ip节点 server.1=192.168.1.213:2888:3888
server.2=192.168.1.214:2888:3888
server.3=192.168.1.215:2888:3888
在zookeeper-3.4.10文件夹里面创建一个zkData文件夹
mkdir zkData 进入zkData文件夹,myid里面的数字对应server.1最后的数字
touch myid
echo 1 > myid 分发到linux02和linux03中(会自动覆盖,所以修改了东西可用直接使用下面命令分发)
scp -r zookeeper-3.4.10/ linux02:/home/admin/modules/HA/
scp -r zookeeper-3.4.10/ linux03:/home/admin/modules/HA/ 分发后记得也要到zkData文件夹里面修改myid的数字
4.2 配置core-site.xml文件 与 hdfs-site.xml文件
core-site.xml
cd /home/admin/modules/HA/hadoop-2.7.2/etc/hadoop vim core-site.xml <configuration>
<!-- 把两个NameNode)的地址组装成一个集群mycluster -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://mycluster</value>
</property> <!-- 指定hadoop运行时产生文件的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/home/admin/modules/HA/hadoop-2.7.2/hadoop-data</value>
</property> <property>
<name>dfs.journalnode.edits.dir</name>
<value>/home/admin/modules/HA/hadoop-2.7.2/jn/mycluster</value>
</property> <property>
<name>ha.zookeeper.quorum</name>
<value>linux01:2181,linux02:2181,linux03:2181</value>
</property>
</configuration>
hdfs-site.xml
<configuration>
<!-- 完全分布式集群名称 -->
<property>
<name>dfs.nameservices</name>
<value>mycluster</value>
</property> <!-- 集群中NameNode节点都有哪些 -->
<property>
<name>dfs.ha.namenodes.mycluster</name>
<value>nn1,nn2</value>
</property> <!-- nn1的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.mycluster.nn1</name>
<value>linux01:8020</value>
</property> <!-- nn2的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.mycluster.nn2</name>
<value>linux02:8020</value>
</property> <!-- nn1的http通信地址 -->
<property>
<name>dfs.namenode.http-address.mycluster.nn1</name>
<value>linux01:50070</value>
</property> <!-- nn2的http通信地址 -->
<property>
<name>dfs.namenode.http-address.mycluster.nn2</name>
<value>linux02:50070</value>
</property> <!-- 指定NameNode元数据在JournalNode上的存放位置 -->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://linux01:8485;linux02:8485;linux03:8485/mycluster</value>
</property> <!-- 配置隔离机制,即同一时刻只能有一台服务器对外响应 -->
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property> <!-- 使用隔离机制时需要ssh无秘钥登录-->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/home/admin/.ssh/id_rsa</value>
</property> <!-- 指定数据冗余分数 -->
<property>
<name>dfs.replication</name>
<value>1</value>
</property> <!-- 关闭权限检查-->
<property>
<name>dfs.permissions.enable</name>
<value>false</value>
</property> <!-- 是否开启故障自动转移 -->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property> <property>
<name>dfs.webhdfs.enable</name>
<value>true</value>
</property> <!-- 访问代理类:client,mycluster,active配置失败自动切换实现方式-->
<property>
<name>dfs.client.failover.proxy.provider.mycluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
</configuration>
配置完成以后记得scp到linux02和03中(分发后记得查看是否分发成功,不然就不会故障转移了,我就是掉进这个坑)
scp -r etc/ linux02:/home/admin/modules/HA/hadoop-2.7.2/
scp -r etc/ linux03:/home/admin/modules/HA/hadoop-2.7.2/
4.3 开启zookeeper(分别在三台机器执行)
cd /home/admin/modules/HA/zookeeper-3.4.10
bin/zkServer.sh start
查看一下是否是一台leader,两台follower,如果不是,证明zoo.cfg没有配置好(我又掉坑了)
bin/zkServer.sh status
4.4 初始化zookeeperd中的HA状态(只需在第一次部署时初始化)(如果之前core-site.xml与hdfs-site.xml配置好,这里是可用初始化的,我又又掉坑了)
cd /home/admin/modules/HA/hadoop-2.7.2
bin/hdfs zkfc -formatZK
4.5 启动三台机器的journalnode (分别在三台机器上面执行)
sbin/hadoop-daemon.sh start journalnode
jps查看是否有启动
4.6 启动hdfs集群
sbin/start-dfs.sh
如果全部正确启动成功,可以看到:(途中超多坑,劝君多尝试)
如果处在active的机器有什么特殊情况,断线关机等等,处在standby的机器会马上顶上,变成active状态,达到自动故障转移,高可用的目的。

5.配置yarn高可用
5.1修改yarn-site.xml文件
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!--启用resourcemanager ha-->
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<!--声明两台resourcemanager的地址-->
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>cluster-yarn1</value>
</property>
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>linux02</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>linux03</value>
</property>
<!--指定zookeeper集群的地址-->
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>linux01:2181,linux02:2181,linux03:2181</value>
</property>
<!--启用自动恢复-->
<property>
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value>
</property>
<!--指定resourcemanager的状态信息存储在zookeeper集群-->
<property>
<name>yarn.resourcemanager.store.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value>
</property>
</configuration>
5.2 分发到linux02和linux03中
scp -r etc/ linux02:/home/admin/modules/HA/hadoop-2.7.2/
scp -r etc/ linux03:/home/admin/modules/HA/hadoop-2.7.2/
5.3 启动yarn (在linux02执行)
sbin/start-yarn.sh
5.4启动resourcemanager(在linux03中操作)
sbin/yarn-daemon.sh start resourcemanager
5.5 测试:(目前还没达到预期测试效果)
如果成功,linux02(192.168.1.214:8088)成为active,linux03(192.168.1.215:8088)成为standby
输入192.168.1.215:8088 会自动重定向到 192.168.1.214:8088
如果linux02挂了,linux03会自动顶上。
6.目前遗留问题
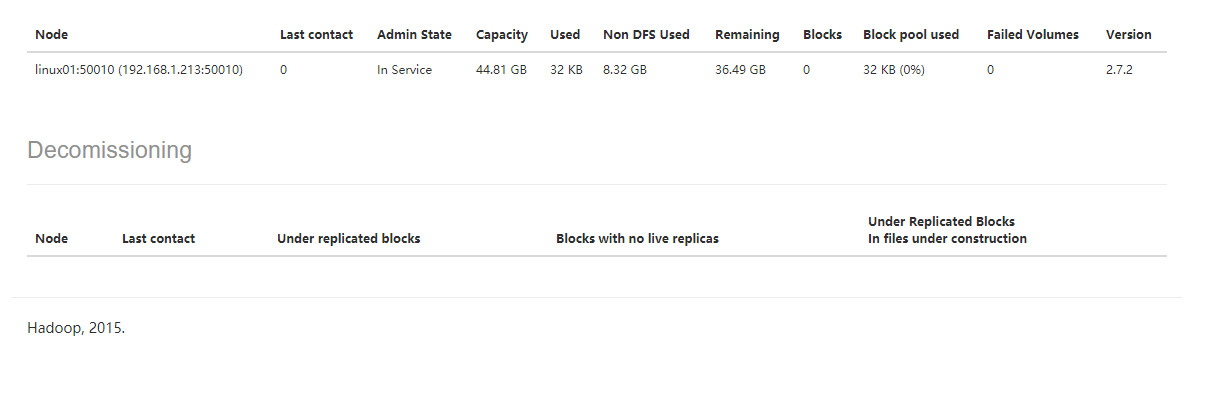
6.1 开启hdfs时,datanode只显示一个,不是显示3个,但是刷新页面时却会随机出现linux01,linux02,linux03的datanode
6.2 yarn高可用配置时,linux02的resourcemanager没有启动,但是却可以用浏览器访问8088端口,且不知如何关闭
6.3 yarn的自动故障转移测试还没成功
大数据(3) - 高可用 HDFS HA的更多相关文章
- [大数据] hadoop高可用(HA)部署(未完)
一.HA部署架构 如上图所示,我们可以将其分为三个部分: 1.NN和DN组成Hadoop业务组件.浅绿色部分. 2.中间深蓝色部分,为Journal Node,其为一个集群,用于提供高可用的共享文件存 ...
- 理解 OpenStack 高可用(HA)(2):Neutron L3 Agent HA 之 虚拟路由冗余协议(VRRP)
本系列会分析OpenStack 的高可用性(HA)概念和解决方案: (1)OpenStack 高可用方案概述 (2)Neutron L3 Agent HA - VRRP (虚拟路由冗余协议) (3)N ...
- 理解 OpenStack 高可用(HA)(1):OpenStack 高可用和灾备方案 [OpenStack HA and DR]
本系列会分析OpenStack 的高可用性(HA)概念和解决方案: (1)OpenStack 高可用方案概述 (2)Neutron L3 Agent HA - VRRP (虚拟路由冗余协议) (3)N ...
- 我眼中的大数据(二)——HDFS
Hadoop的第一个产品是HDFS,可以说分布式文件存储是分布式计算的基础,也可见分布式文件存储的重要性.如果我们将大数据计算比作烹饪,那么数据就是食材,而Hadoop分布式文件系统HDFS就是烧菜的 ...
- 高可用(HA)架构
http://aokunsang.iteye.com/blog/2053719 浅谈web应用的负载均衡.集群.高可用(HA)解决方案 http://zhuanlan.51cto.com/art/ ...
- MySQL在大数据、高并发场景下的SQL语句优化和"最佳实践"
本文主要针对中小型应用或网站,重点探讨日常程序开发中SQL语句的优化问题,所谓“大数据”.“高并发”仅针对中小型应用而言,专业的数据库运维大神请无视.以下实践为个人在实际开发工作中,针对相对“大数据” ...
- Nfs+Drdb+Heartbeat 数据存储高可用服务架构方案
一.方案的应用场景 适用于2千万-3千万PV架构的网站,Nfs数据存储高可用服务方案 备注:互联网排名前30左右公司常用的架构 二.生产环境方案部署原理图 三.生产环境服务器硬件配置: 生产环境中采用 ...
- Memcached 集群的高可用(HA)架构
Memcache自身并没有实现集群功能,如果想用Memcahce实现集群需要借助第三方软件或者自己设计编程实现,这里将采用memagent代理实现,memagent又名magent,大家注意下,不要将 ...
- Keepalived+Nginx实现高可用(HA)
Keepalived+Nginx实现高可用(HA) service iptables stopchkconfig iptables offsetenforce 0/etc/selinux/config ...
随机推荐
- 利用hsdis和JITWatch查看分析HotSpot JIT compiler生成的汇编代码
http://blog.csdn.net/hengyunabc/article/details/26898657
- Swift,字典
1.创建(Dictionary)字典(无序的可重复) (1)指定类型 var a:Dictionary<String,String>=["a":"b" ...
- Android 中 Environment.getExternalStorageDirectory()无效
我们在处理缓存的时候,并不是每次都会在应用私有存储空间那里保存,很多时候是需要用到ExternalStorage.我们平时一般都是用Environment.getExternalStorageDire ...
- pwn2own
Pwn2Own是全球最著名的黑客大赛之一,由美国五角大楼入侵防护系统供应商TippingPoint的DVLabs赞助,今年已经是第六届. 1比赛规则 参赛黑客们的目标是4大主流网页浏览器——IE.Fi ...
- Git与GitLab
Git与GitLab 一.Git Git是一个开源的分布式版本控制系统,用于敏捷高效地处理任何或小或大的项目. Git 是 Linus Torvalds 为了帮助管理 Linux 内核开发而开发的一个 ...
- vue2自定义事件之$emit
父组件: API上的解释不多: https://cn.vuejs.org/v2/api/#vm-emit vm.$emit( event, […args] ) 参数: {string} event [ ...
- 安卓File类汇总
File类 构造函数 參数 File(File dir,String name) File制定构造的新的File对象的路径.而String制定新的File名字 File(String path) St ...
- java 线程的几种状态(转载)
java thread的运行周期中, 有几种状态, 在 java.lang.Thread.State 中有详细定义和说明: NEW 状态是指线程刚创建, 尚未启动 RUNNABLE 状态是线程正在 ...
- android adt 最新下载地址
打开这个网址就可以看到adt的详细信息: http://developer.android.com/sdk/installing/installing-adt.html 或者直接在你的eclipse ...
- VB的第一个项目
前言-----本人也是刚刚接触VB,企业的VB代码基本能看的懂,但是自己开发,只能呵呵.一般在刚学习一门新的语言时,很容易发生一些自己相当然的认识错误,so,记下并分享开发学习的过程,望指正.--- ...