【Python3 爬虫】06_robots.txt查看网站爬取限制情况
大多数网站都会定义robots.txt文件来限制爬虫爬去信息,我们在爬去网站之前可以使用robots.txt来查看的相关限制信息
例如:
我们以【CSDN博客】的限制信息为例子
在浏览器输入:https://blog.csdn.net/robots.txt
获取到信息如下:
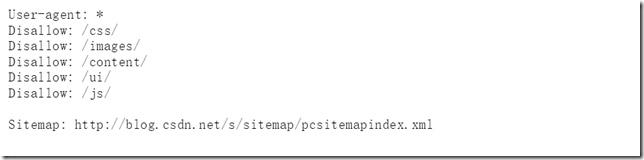
从上图我们可以看出:
①该网站无论用户使用哪种代理都允许爬取
②但是当爬取/css,/images…等链接的时候是禁止的
③我们可以看到还存在一个网址Sitemap,j具体解析如下:
网站提供的Sitemap文件(即网站地图)可以帮助网站定位最新的内容,则无须爬取每一个网页,虽然Sitemap文件提供了一种爬取网站的有效方式,但是我们仍然需要对其谨慎处理,因为该文件经常存在缺失,过期和不完整。
【Python3 爬虫】06_robots.txt查看网站爬取限制情况的更多相关文章
- Python3爬虫:(一)爬取拉勾网公司列表
人生苦短,我用Python 爬取原因:了解一下Python工程师在北上广等大中城市的薪资水平与入职前要求. Python3基础知识 requests,pyquery,openpyxl库的使用 爬取前的 ...
- Python3爬虫系列:理论+实验+爬取妹子图实战
Github: https://github.com/wangy8961/python3-concurrency-pics-02 ,欢迎star 爬虫系列: (1) 理论 Python3爬虫系列01 ...
- Python爬虫入门教程 2-100 妹子图网站爬取
妹子图网站爬取---前言 从今天开始就要撸起袖子,直接写Python爬虫了,学习语言最好的办法就是有目的的进行,所以,接下来我将用10+篇的博客,写爬图片这一件事情.希望可以做好. 为了写好爬虫,我们 ...
- Python爬虫初探 - selenium+beautifulsoup4+chromedriver爬取需要登录的网页信息
目标 之前的自动答复机器人需要从一个内部网页上获取的消息用于回复一些问题,但是没有对应的查询api,于是想到了用脚本模拟浏览器访问网站爬取内容返回给用户.详细介绍了第一次探索python爬虫的坑. 准 ...
- Python爬虫学习三------requests+BeautifulSoup爬取简单网页
第一次第一次用MarkDown来写博客,先试试效果吧! 昨天2018俄罗斯世界杯拉开了大幕,作为一个伪球迷,当然也得为世界杯做出一点贡献啦. 于是今天就编写了一个爬虫程序将腾讯新闻下世界杯专题的相关新 ...
- python爬虫实践(二)——爬取张艺谋导演的电影《影》的豆瓣影评并进行简单分析
学了爬虫之后,都只是爬取一些简单的小页面,觉得没意思,所以我现在准备爬取一下豆瓣上张艺谋导演的“影”的短评,存入数据库,并进行简单的分析和数据可视化,因为用到的只是比较多,所以写一篇博客当做笔记. 第 ...
- 5分钟掌握智联招聘网站爬取并保存到MongoDB数据库
前言 本次主题分两篇文章来介绍: 一.数据采集 二.数据分析 第一篇先来介绍数据采集,即用python爬取网站数据. 1 运行环境和python库 先说下运行环境: python3.5 windows ...
- 爬虫系列(十三) 用selenium爬取京东商品
这篇文章,我们将通过 selenium 模拟用户使用浏览器的行为,爬取京东商品信息,还是先放上最终的效果图: 1.网页分析 (1)初步分析 原本博主打算写一个能够爬取所有商品信息的爬虫,可是在分析过程 ...
- 一起学爬虫——使用selenium和pyquery爬取京东商品列表
layout: article title: 一起学爬虫--使用selenium和pyquery爬取京东商品列表 mathjax: true --- 今天一起学起使用selenium和pyquery爬 ...
随机推荐
- IIS7.0添加IP地址和域名限制
IIS7.0默认安装是没有“IP地址和域名限制”功能的,需要我们自己选择安装 1.windows系统的添加方式 控制面板--程序与功能--启用或关闭windows功能--internat inform ...
- apt-get常用命令及工作原理
https://blog.csdn.net/mosquito_zm/article/details/63684608
- python 连接ubuntu xampp mysql
>>> import MySQLdb >>> db=MySQLdb.connect(user="root",passwd="" ...
- oracle 替换其中部分内容
update TABLE_NAME set field =REPLACE(field ,substr(field ,0,1) ,'P') where field is not null ;
- [九省联考2018]林克卡特树(DP+wqs二分)
对于k=0和k=1的点,可以直接求树的直径. 然后对于60分,有一个重要的转化:就是求在树中找出k+1条点不相交的链后的最大连续边权和. 这个DP就好.$O(nk^2)$ 然后我们完全不可以想到,将b ...
- [CF235E]Number Challenge
$\newcommand{fl}[1]{\left\lfloor#1\right\rfloor}$题意:求$\sum\limits_{i=1}^a\sum\limits_{j=1}^b\sum\lim ...
- 【bitset】poj2443 Set Operation
模板题.S[i][j]表示i是否存在于第j个集合里.妈蛋poj差点打成poi(波兰无关)是不是没救了. #include<cstdio> #include<bitset> us ...
- 【二分图】【最大匹配】【匈牙利算法】CODEVS 2776 寻找代表元
裸的匈牙利,存模板. #include<cstdio> #include<vector> #include<cstring> using namespace std ...
- 上传--下载HDFS文件并指定文件物理块的大小
使用hdfs的api接口分别实现从本地上传文件到集群和从集群下载文件到本地. 1)上传文件主要是使用FileSystem类的copyFromLocalFile()方法来实现,另外我们上传文件时可以指定 ...
- iOS开发——使用Autolayout生成动态高度的TableViewCell单元格
步骤一.TableViewCell中使用Autolayout 要点:Cell的高度必须在Constraints中指明,但不能定死,需要让内部由内容决定高度的View决定动态高度. 如UILabel设置 ...