Java 集合系列 16 HashSet
java 集合系列目录:
Java 集合系列 03 ArrayList详细介绍(源码解析)和使用示例
Java 集合系列 04 LinkedList详细介绍(源码解析)和使用示例
Java 集合系列 05 Vector详细介绍(源码解析)和使用示例
Java 集合系列 06 Stack详细介绍(源码解析)和使用示例
Java 集合系列 07 List总结(LinkedList, ArrayList等使用场景和性能分析)
Java 集合系列 09 HashMap详细介绍(源码解析)和使用示例
Java 集合系列 10 Hashtable详细介绍(源码解析)和使用示例
Java 集合系列 11 hashmap 和 hashtable 的区别
概述
第1 部分 HashSet介绍
1.1 HashSet 简介
HashSet 是一个没有重复元素的集合。它是由HashMap实现的,不保证元素的顺序,而且HashSet允许使用 null 元素。
HashSet是非同步的。如果多个线程同时访问一个哈希 set,而其中至少一个线程修改了该 set,那么它必须 保持外部同步。这通常是通过对自然封装该 set 的对象执行同步操作来完成的。如果不存在这样的对象,则应该使用 Collections.synchronizedSet 方法来“包装” set。最好在创建时完成这一操作,以防止对该 set 进行意外的不同步访问:
Set s = Collections.synchronizedSet(new HashSet(...));
1.2 HashSet的构造函数
// 默认构造函数
public HashSet() // 带集合的构造函数
public HashSet(Collection<? extends E> c) // 指定HashSet初始容量和加载因子的构造函数
public HashSet(int initialCapacity, float loadFactor) // 指定HashSet初始容量的构造函数
public HashSet(int initialCapacity) // 指定HashSet初始容量和加载因子的构造函数,dummy没有任何作用
HashSet(int initialCapacity, float loadFactor, boolean dummy)
1.3 HashSet的主要API
boolean add(E e)
如果此 set 中尚未包含指定元素,则添加指定元素。
void clear()
从此 set 中移除所有元素。
Object clone()
返回此 HashSet 实例的浅表副本:并没有复制这些元素本身。
boolean contains(Object o)
如果此 set 包含指定元素,则返回 true。
boolean isEmpty()
如果此 set 不包含任何元素,则返回 true。
Iterator<E> iterator()
返回对此 set 中元素进行迭代的迭代器。
boolean remove(Object o)
如果指定元素存在于此 set 中,则将其移除。
int size()
返回此 set 中的元素的数量(set 的容量)。
第2 部分 HashSet数据结构
HashSet的继承关系如下:
java.lang.Object
↳ java.util.AbstractCollection<E>
↳ java.util.AbstractSet<E>
↳ java.util.HashSet<E> public class HashSet<E>
extends AbstractSet<E>
implements Set<E>, Cloneable, java.io.Serializable { }
HashSet与Map关系如下图:
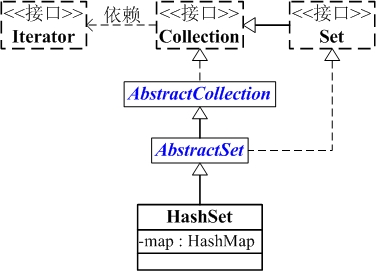
从图中可以看出:
(01) HashSet继承于AbstractSet,并且实现了Set接口。
(02) HashSet的本质是一个"没有重复元素"的集合,它是通过HashMap实现的。HashSet中含有一个"HashMap类型的成员变量"map,HashSet的操作函数,实际上都是通过map实现的。
第3 部分 源码分析
public class HashSet<E>
extends AbstractSet<E>
implements Set<E>, Cloneable, java.io.Serializable
{
static final long serialVersionUID = -5024744406713321676L; // HashSet是通过map(HashMap对象)保存内容的
private transient HashMap<E,Object> map; // PRESENT是向map中插入key-value对应的value
// 因为HashSet中只需要用到key,而HashMap是key-value键值对;
// 所以,向map中添加键值对时,键值对的值固定是PRESENT
private static final Object PRESENT = new Object(); // 默认构造函数
//default initial capacity (16) and load factor (0.75)
public HashSet() {
// 调用HashMap的默认构造函数,创建map
map = new HashMap<>();
} // 带集合的构造函数
public HashSet(Collection<? extends E> c) {
// 创建map。
// 为什么要调用Math.max((int) (c.size()/.75f) + 1, 16),从 (c.size()/.75f) + 1 和 16 中选择一个比较大的树呢?
// 首先,说明(c.size()/.75f) + 1
// 因为从HashMap的效率(时间成本和空间成本)考虑,HashMap的加载因子是0.75。
// 当HashMap的“阈值”(阈值=HashMap总的大小*加载因子) < “HashMap实际大小”时,
// 就需要将HashMap的容量翻倍。
// 所以,(c.size()/.75f) + 1 计算出来的正好是总的空间大小。
// 接下来,说明为什么是 16 。
// HashMap的总的大小,必须是2的指数倍。若创建HashMap时,指定的大小不是2的指数倍;
// HashMap的构造函数中也会重新计算,找出比“指定大小”大的最小的2的指数倍的数。
// 所以,这里指定为16是从性能考虑。避免重复计算。
map = new HashMap<>(Math.max((int) (c.size()/.75f) + 1, 16));
// 将集合(c)中的全部元素添加到HashSet中
addAll(c);
} // 指定HashSet初始容量和加载因子的构造函数
public HashSet(int initialCapacity, float loadFactor) {
map = new HashMap<>(initialCapacity, loadFactor);
} // 指定HashSet初始容量的构造函数
public HashSet(int initialCapacity) {
map = new HashMap<>(initialCapacity);
} /**
* Constructs a new, empty linked hash set. (This package private
* constructor is only used by LinkedHashSet.) The backing
* HashMap instance is a LinkedHashMap with the specified initial
* capacity and the specified load factor.
*
* @param initialCapacity the initial capacity of the hash map
* @param loadFactor the load factor of the hash map
* @param dummy ignored (distinguishes this
* constructor from other int, float constructor.)
* @throws IllegalArgumentException if the initial capacity is less
* than zero, or if the load factor is nonpositive
*/
//以指定的initialCapacity和loadFactor构造一个新的空链接哈希集合。
//dummy 为标识 该构造函数主要作用是对LinkedHashSet起到一个支持作用
HashSet(int initialCapacity, float loadFactor, boolean dummy) {
map = new LinkedHashMap<>(initialCapacity, loadFactor);
} // 返回HashSet的迭代器
public Iterator<E> iterator() {
return map.keySet().iterator();
} public int size() {
return map.size();
} public boolean isEmpty() {
return map.isEmpty();
} public boolean contains(Object o) {
return map.containsKey(o);
} // 将元素(e)添加到HashSet中
public boolean add(E e) {
return map.put(e, PRESENT)==null;
} // 删除HashSet中的元素(o)
public boolean remove(Object o) {
return map.remove(o)==PRESENT;
} public void clear() {
map.clear();
} // 克隆一个HashSet,并返回Object对象
public Object clone() {
try {
HashSet<E> newSet = (HashSet<E>) super.clone();
newSet.map = (HashMap<E, Object>) map.clone();
return newSet;
} catch (CloneNotSupportedException e) {
throw new InternalError();
}
} // java.io.Serializable的写入函数
// 将HashSet的“总的容量,加载因子,实际容量,所有的元素”都写入到输出流中
private void writeObject(java.io.ObjectOutputStream s)
throws java.io.IOException {
// Write out any hidden serialization magic
s.defaultWriteObject(); // Write out HashMap capacity and load factor
s.writeInt(map.capacity());
s.writeFloat(map.loadFactor()); // Write out size
s.writeInt(map.size()); // Write out all elements in the proper order.
for (E e : map.keySet())
s.writeObject(e);
} // java.io.Serializable的读取函数
// 将HashSet的“总的容量,加载因子,实际容量,所有的元素”依次读出
private void readObject(java.io.ObjectInputStream s)
throws java.io.IOException, ClassNotFoundException {
// Read in any hidden serialization magic
s.defaultReadObject(); // Read in HashMap capacity and load factor and create backing HashMap
int capacity = s.readInt();
float loadFactor = s.readFloat();
map = (((HashSet)this) instanceof LinkedHashSet ?
new LinkedHashMap<E,Object>(capacity, loadFactor) :
new HashMap<E,Object>(capacity, loadFactor)); // Read in size
int size = s.readInt(); // Read in all elements in the proper order.
for (int i=0; i<size; i++) {
E e = (E) s.readObject();
map.put(e, PRESENT);
}
}
}
Java 集合系列 16 HashSet的更多相关文章
- Java 集合系列16之 HashSet详细介绍(源码解析)和使用示例
概要 这一章,我们对HashSet进行学习.我们先对HashSet有个整体认识,然后再学习它的源码,最后再通过实例来学会使用HashSet.内容包括:第1部分 HashSet介绍第2部分 HashSe ...
- 【转】Java 集合系列16之 HashSet详细介绍(源码解析)和使用示例--不错
原文网址:http://www.cnblogs.com/skywang12345/p/3311252.html 概要 这一章,我们对HashSet进行学习.我们先对HashSet有个整体认识,然后再学 ...
- 【java集合系列】---HashSet
在前面的博文中,小编主要简单介绍了java集合中的总体框架,以及list接口中典型的集合ArrayList和LinkedList,接着,我们来看set的部分集合,set集合和数学意义上的集合没有差别, ...
- Java 集合系列 09 HashMap详细介绍(源码解析)和使用示例
java 集合系列目录: Java 集合系列 01 总体框架 Java 集合系列 02 Collection架构 Java 集合系列 03 ArrayList详细介绍(源码解析)和使用示例 Java ...
- Java 集合系列 10 Hashtable详细介绍(源码解析)和使用示例
java 集合系列目录: Java 集合系列 01 总体框架 Java 集合系列 02 Collection架构 Java 集合系列 03 ArrayList详细介绍(源码解析)和使用示例 Java ...
- Java 集合系列 17 TreeSet
java 集合系列目录: Java 集合系列 01 总体框架 Java 集合系列 02 Collection架构 Java 集合系列 03 ArrayList详细介绍(源码解析)和使用示例 Java ...
- Java 集合系列 15 Map总结
java 集合系列目录: Java 集合系列 01 总体框架 Java 集合系列 02 Collection架构 Java 集合系列 03 ArrayList详细介绍(源码解析)和使用示例 Java ...
- Java 集合系列 14 hashCode
java 集合系列目录: Java 集合系列 01 总体框架 Java 集合系列 02 Collection架构 Java 集合系列 03 ArrayList详细介绍(源码解析)和使用示例 Java ...
- Java 集合系列 13 WeakHashMap
java 集合系列目录: Java 集合系列 01 总体框架 Java 集合系列 02 Collection架构 Java 集合系列 03 ArrayList详细介绍(源码解析)和使用示例 Java ...
随机推荐
- CUBRID学习笔记 15 Lobs类型数据
BLOB: Binary large object CLOB: Character large object 一个二进制 一个字符类型 二进制的读取 CUBRIDCommand cmd = new C ...
- Codeforces Round #377 (Div. 2) C. Sanatorium 水题
C. Sanatorium time limit per test 1 second memory limit per test 256 megabytes input standard input ...
- E2 2014.5.8 更新日志
增加功能 增加报价单功能,可以针对指定客户生成报价单,可以直接生成一个在线地址,直接把地址发给客户在线打开 传统的报价,先生成一个EXCEL,再传给客户,使用E2,这一切都变得简单,你可生成一个在线地 ...
- [转载] C++11中的右值引用
C++11中的右值引用 May 18, 2015 移动构造函数 C++98中的左值和右值 C++11右值引用和移动语义 强制移动语义std::move() 右值引用和右值的关系 完美转发 引用折叠推导 ...
- C#中“==”和equals()的区别
如以下代码: 1 2 3 4 5 6 7 8 9 int age = 25; short newAge = 25; Console.WriteLine(age == newAge); //t ...
- CentOS用yum快速安装nginx
增加nginx源 vim /etc/yum.repos.d/nginx.repo [nginx] name=nginx repo baseurl=http://nginx.org/packages/ ...
- linux 通过 ulimit 改善系统性能
https://www.ibm.com/developerworks/cn/linux/l-cn-ulimit/ 概述 系统性能一直是一个受关注的话题,如何通过最简单的设置来实现最有效的性能调优,如何 ...
- vitamio框架
import io.vov.vitamio.LibsChecker; import io.vov.vitamio.MediaPlayer; import io.vov.vitamio.MediaPla ...
- DOS中文乱码解决
在中文Windows系统中,如果一个文本文件是UTF-8编码的,那么在CMD.exe命令行窗口(所谓的DOS窗口)中不能正确显示文件中的内容.在默认情况下,命令行窗口中使用的代码页是中文或者美国的,即 ...
- 转:设计模式-----桥接模式(Bridge Pattern)
转自:http://www.cnblogs.com/houleixx/archive/2008/02/23/1078877.html 记得看原始链接的评论. 学习设计模式也有一段时间了,今天就把我整理 ...