adaboost算法
三 Adaboost 算法
AdaBoost 是一种迭代算法,其核心思想是针对同一个训练集训练不同的分类器,即弱分类器,然后把这些弱分类器集合起来,构造一个更强的最终分类器。(很多博客里说的三个臭皮匠赛过诸葛亮)
算法本身是改变数据分布实现的,它根据每次训练集之中的每个样本的分类是否正确,以及上次的总体分类的准确率,来确定每个样本的权值。将修改权值的新数据送给下层分类器进行训练,然后将每次训练得到的分类器融合起来,作为最后的决策分类器。
完整的adaboost算法如下


简单来说,Adaboost有很多优点:
1)adaboost是一种有很高精度的分类器
2)可以使用各种方法构建子分类器,adaboost算法提供的是框架
3)当使用简单分类器时,计算出的结果是可以理解的。而且弱分类器构造极其简单
4)简单,不用做特征筛选
5)不用担心overfitting!
四 Adaboost 举例
也许你看了上面的介绍或许还是对adaboost算法云里雾里的,没关系,百度大牛举了一个很简单的例子,你看了就会对这个算法整体上很清晰了。
下面我们举一个简单的例子来看看adaboost的实现过程:

图中,“+”和“-”分别表示两种类别,在这个过程中,我们使用水平或者垂直的直线作为分类器,来进行分类。
第一步:

根据分类的正确率,得到一个新的样本分布D2,一个子分类器h1
其中划圈的样本表示被分错的。在右边的途中,比较大的“+”表示对该样本做了加权。
也许你对上面的ɛ1,ɑ1怎么算的也不是很理解。下面我们算一下,不要嫌我啰嗦,我最开始就是这样思考的,只有自己把算法演算一遍,你才会真正的懂这个算法的核心,后面我会再次提到这个。
算法最开始给了一个均匀分布 D 。所以h1 里的每个点的值是0.1。ok,当划分后,有三个点划分错了,根据算法误差表达式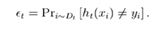 得到 误差为分错了的三个点的值之和,所以ɛ1=(0.1+0.1+0.1)=0.3,而ɑ1 根据表达式
得到 误差为分错了的三个点的值之和,所以ɛ1=(0.1+0.1+0.1)=0.3,而ɑ1 根据表达式 的可以算出来为0.42. 然后就根据算法 把分错的点权值变大。如此迭代,最终完成adaboost算法。
的可以算出来为0.42. 然后就根据算法 把分错的点权值变大。如此迭代,最终完成adaboost算法。
第二步:

根据分类的正确率,得到一个新的样本分布D3,一个子分类器h2
第三步:

得到一个子分类器h3
整合所有子分类器:

因此可以得到整合的结果,从结果中看,及时简单的分类器,组合起来也能获得很好的分类效果,在例子中所有的。
五 Adaboost 疑惑和思考
到这里,也许你已经对adaboost算法有了大致的理解。但是也许你会有个问题,为什么每次迭代都要把分错的点的权值变大呢?这样有什么好处呢?不这样不行吗? 这就是我当时的想法,为什么呢?我看了好几篇介绍adaboost 的博客,都没有解答我的疑惑,也许大牛认为太简单了,不值一提,或者他们并没有意识到这个问题而一笔带过了。然后我仔细一想,也许提高错误点可以让后面的分类器权值更高。然后看了adaboost算法,和我最初的想法很接近,但不全是。 注意到算法最后的表到式为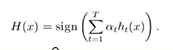 ,这里面的a 表示的权值,是由
,这里面的a 表示的权值,是由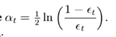 得到的。而a是关于误差的表达式,到这里就可以得到比较清晰的答案了,所有的一切都指向了误差。提高错误点的权值,当下一次分类器再次分错了这些点之后,会提高整体的错误率,这样就导致 a 变的很小,最终导致这个分类器在整个混合分类器的权值变低。也就是说,这个算法让优秀的分类器占整体的权值更高,而挫的分类器权值更低。这个就很符合常理了。到此,我认为对adaboost已经有了一个透彻的理解了。
得到的。而a是关于误差的表达式,到这里就可以得到比较清晰的答案了,所有的一切都指向了误差。提高错误点的权值,当下一次分类器再次分错了这些点之后,会提高整体的错误率,这样就导致 a 变的很小,最终导致这个分类器在整个混合分类器的权值变低。也就是说,这个算法让优秀的分类器占整体的权值更高,而挫的分类器权值更低。这个就很符合常理了。到此,我认为对adaboost已经有了一个透彻的理解了。
六 总结
最后,我们可以总结下adaboost算法的一些实际可以使用的场景:
1)用于二分类或多分类的应用场景
2)用于做分类任务的baseline
无脑化,简单,不会overfitting,不用调分类器
3)用于特征选择(feature selection)
4)Boosting框架用于对badcase的修正
只需要增加新的分类器,不需要变动原有分类器
由于adaboost算法是一种实现简单,应用也很简单的算法。Adaboost算法通过组合弱分类器而得到强分类器,同时具有分类错误率上界随着训练增加而稳定下降,不会过拟合等的性质,应该说是一种很适合于在各种分类场景下应用的算法。
第二篇
第二节,AdaBoost算法
(一)认识AdaBoost
AdaBoost算法有AdaBoost.M1和AdaBoost.M2两种算法,AdaBoost.M1是我们通常所说的Discrete AdaBoost,而AdaBoost.M2是M1的泛化形式。关于AdaBoost算法的一个结论是:当弱分类器算法使用简单的分类方法时,boosting的效果明显地统一地比bagging要好.当弱分类器算法使用C4.5时,boosting比bagging较好,但是没有前者明显。后来又有学者提出了解决多标签问题的AdaBoost.MH和AdaBoost.MR算法,其中AdaBoost.MH算法的一种形式又被称为Real Boost算法---弱分类器输出一个可能度,该值的范围是整个R, 和与之相应的权值调整,强分类器生成的AdaBoost算法。
事实上:Discrete AdaBoost是指,弱分类器的输出值限定在{-1,+1},每个弱分类器有相应的权值,从而构成一个强分类器。本文就详解该二分类的AdaBoost算法,其他请参考‘Adaboost原理、算法以及应用’。
假设是二值分类问题,X表示样本空间,Y={-1,+1}表示样本分类。令S={(Xi,yi)|i=1,2,…,m}为样本训练集,其中Xi∈X,yi∈Y。再次重申,我们假设统计样本的分布式是均匀分布的,如此在两分类分类中(类别-1或者1)可以将阈值设为0。实际训练数据中,样本往往是不均衡的,需要算法来选择最优阈值(如ROC曲线)。AdaBoost算法就是学习出一个分类器YM(x) --由M个弱分类器构成。在进行分类的时候,将新的数据点x代入,如果YM(x)小于0则将x的类别赋为-1,如果YM(x)大于0则将x的类别赋为1。均匀分布中阈值就是0,非均衡分布则还要根据ROC曲线等方法确定一个分类的最优阈值。




基本过程:针对不同的训练集训练一个个基本分类器(弱分类器),然后集成而构成一个更强的最终的分类器(强分类器)。不同的训练集是通过调整训练数据中每个样本对应的权重实现的。每次训练后根据此次训练集中的每个样本是否被分类正确以及上次的总体分类的准确率,来确定每个样本的权值。将修改权值的新数据送给下层分类器进行训练,然后将每次训练得到的分类器融合起来,作为最后的决策分类器。
每个弱分类器可以是机器学习算法中的任何一个,如logistic回归,SVM,决策树等。
Adaboost有很多优点:
1)adaboost是一种有很高精度的分类器
2)可以使用各种方法构建子分类器,adaboost算法提供的是框架
3)当使用简单分类器时,计算出的结果是可以理解的,而且弱分类器构造极其简单
4)简单,不用做特征筛选
5)不用担心overfitting
(二)AdaBoost算法过程
完整的adaboost算法如下(训练样本样本总数是N个,M是迭代停止后(积累错误率为0或者达到最大迭代次数)得到弱分类器数目)。
给定一个训练数据集T={(x1,y1), (x2,y2)…(xN,yN)},其中实例

最开始的时候,每个样本对应的权重是相同的(1/m),在此样本分布下训练出一个基本分类器h1(x)。对于h1(x)错分的样本,则增加其对应样本的权重;而对于正确分类的样本,则降低其权重。这样可以使得错分的样本突出出来,并得到一个新的样本分布。同时,根据错分的情况赋予h1(x)一个权重,表示该基本分类器的重要程度,错分得越少权重越大。在新的样本分布下,再次对基本分类器进行训练,得到基本分类器h2(x)及其权重。依次类推,经过M次这样的循环,就得到了M个基本分类器及对应权重。最后把这M个基本分类器按一定权重累加起来,就得到了最终所期望的强分类器YM(x)。迭代的停止条件就是达到了训练样本累加分类错误率为0.0或者达到了最大迭代次数。
(i)初始化训练数据的权值分布,每一个训练样本最开始时被赋予相同的权值:1/N。

(ii)进行多轮迭代,迭代的停止条件就是达到了训练样本累加分类错误率为0.0或者达到了最大迭代次数L。用m = 1,2, ..., M表示迭代的第多少轮,也就是得到了多少个弱分类器,M<=L。
a.使用具有权值分布Dm的训练数据集学习,得到基本分类器:


b.计算Gm(x)在训练数据集上的分类误差率


由上述式子可知,Gm(x)在训练数据集上的误差率em就是被弱分类器Gm(x)分类错误样本的权值之和。就是在这里,训练样本权重因子发生了作用,所有的一切都指向了当前弱分类器的误差。提高分类错误样本的权值,下一个分类器学习中其“地位”就提高了(以单层决策树为例,因为每次都要得到当前训练样本中em最小的决策桩);同时若这次的弱分类器再次分错了这些点,那么其错误率em也就更大,最终导致这个分类器在整个混合分类器的权值am变低---让优秀的分类器占整体的权值更高,而挫的分类器权值更低。
c. 计算Gm(x)的权值系数,am表示Gm(x)在最终分类器中的重要程度(目的:得到基本分类器在最终分类器中所占的权重):


可知:em <= 1/2时(两分类Adaboost算法em不可能大于1/2),am >= 0;am随着em的减小而增大,意味着分类误差率越小的本分类器在最终分类器中的作用越大。
另外,若某一个若分类器分类错误率为0计算am将会发生除数为0的异常,这属于边界处理。此时可以根据数据集的具体情况设定错误率为一个很小的数值,例如1e-16。观察样本权重更新就可以知道:没有错分,所有样本的权重就不会进一步调整,样本权重相当于没有改变。当然,该弱分类器权重alpha将较大,但是因为算法并不因此停止,如果后面还有其他弱分类器也能达到训练错误率为0,也同样会有较大的权重,从而避免由单个弱分类器完全决定强分类器的情况。当然,如果第一个弱分类器错误率就为0,那么整个分类就完成了,它有再大的权重alpha也无妨。采用下述修正方案:
alpha = float(0.5*log((1.0-error)/max(error,1e-16) ))
d. 更新训练数据集的权值分布(目的:得到样本的新的权值分布),用于下一轮迭代。这使得被基本分类器Gm(x)分类错误的样本的权值增大,而被正确分类样本的权值减小。通过这样的方式,AdaBoost算法提高了较难分类的样本的‘地位’。


Zm的意义在于让权重因子之和为1.0,使向量D是一个概率分布向量。其定义是


(iii) 组合各个弱分类器得到最终分类器,如下:


(三)Python实现单决策树AdaBoost算法
单层决策树(decision stump,也叫决策树桩)是一种简单的决策树,决策树中只有一个树桩,也就是仅基于样本单个特征来做决策分类。单层决策树是AdaBoost算法中最流行的弱分类器。
AdaBoost把多个不同的决策树用一种非随机的方式组合起来,表现出惊人的性能。第一,把决策树的准确率大大提高,可以与SVM媲美。第二,速度快,且基本不用调参数。第三,几乎不Overfitting。本节就以多个单层决策树做基本分类器实现AdaBoost算法,值得注意的是每个基本分类器单层决策树决策用分类使用的特征都是在样本N个特征中做最优选择的(也就是说在分类特征选择这个层面,每个单层决策树彼此之间是完全独立的,可能若干个单层决策树都是基于同一个样本特征),而非样本特征的串联。
该版本的AdaBoost分类算法包含decisionstump.py(decisionstump对象,其属性是包含dim, thresh, ineqtype三个域的决策树桩,方法有buildstump()、stumpClassify()等。),adaboost.py, object_json.py, test.py,其中adaboot.py实现分类算法,对象adaBoost包含属性分类器词典adaboostClassifierDict和adaboost train&classify方法等。为了存储和传输更少的字节数,也可以在adaboost模块增加一个新类adaboostClassifier只用来存储分类词典和分类算法(本包中没有这么做)。test模块则包含了一个使用adaboost分类器进行分类的示例。
由于adaboost算法每一个基本分类器都可以采用任何一种分类算法,因此通用的方案是采用dict来存储学习到的AdaBoost分类器,结构如下图:

adaboost对象可以针对决策树、SVM等定义私有的各种弱分类算法,train和classifier方法则会根据当前的弱分类器类型创建响应的弱分类器实例并调用私有弱分类train\classifer方法完成train\classify。需要记住的是,adaboost train方法创建的弱分类器对象只用来调用相应的弱分类器方法,而该弱分类实例所有的属性则存储在adaboostClassifierDict中,这样可以减少弱分类器实例数目。另外,方法jsonDumpsTransfer()和jsonLoadTransfer()则要根据adaboostClassifierDict中支持的弱分类器类型删除\创建相应实例,从而支持JSON存储和解析。
采取上图中的分类器存储方案及相应的分类函数,AdaBoost支持每一个基本分类器在决策树、贝叶斯、SVM等监督学习算法中做最优选择。分类其中adaboostClassifierDict中的classifierType用户可以自己指定,从而在上述分类存储结构的基础上做一些利于分类器程序编写的调整。我实现的单层决策树Adaboost指定classifierType为desicionstump,即基本分类器采用desicionstump,每一个弱分类器都是一个DS对象。所以存储结构可以调整为下图所示(利于分类函数实现):


通过调整adaboost算法弱分类器的数目,会得到分类错误率不同的adaboost分类器。测试证明,numIt=50时错误率最低。
AdaBoost分类算法学习包的下载地址是:
machine learning adaboost
(四)Adaboost应用
由于adaboost算法是一种实现简单、应用也很简单的算法,应该说是一种很适合于在各种分类场景下应用的算法。adaboost算法的一些实际可以使用的场景:
1)用于二分类或多分类的应用场景
2)用于做分类任务的baseline--无脑化,简单,不会overfitting,不用调分类器
3)用于特征选择(feature selection)
4)Boosting框架用于对badcase的修正--只需要增加新的分类器,不需要变动原有分类器
adaboost算法的更多相关文章
- 集成学习之Adaboost算法原理小结
在集成学习原理小结中,我们讲到了集成学习按照个体学习器之间是否存在依赖关系可以分为两类,第一个是个体学习器之间存在强依赖关系,另一类是个体学习器之间不存在强依赖关系.前者的代表算法就是是boostin ...
- Adaboost 算法
一 Boosting 算法的起源 boost 算法系列的起源来自于PAC Learnability(PAC 可学习性).这套理论主要研究的是什么时候一个问题是可被学习的,当然也会探讨针对可学习的问题的 ...
- Adaboost 算法的原理与推导
0 引言 一直想写Adaboost来着,但迟迟未能动笔.其算法思想虽然简单“听取多人意见,最后综合决策”,但一般书上对其算法的流程描述实在是过于晦涩.昨日11月1日下午,邹博在我组织的机器学习班第8次 ...
- 一个关于AdaBoost算法的简单证明
下载本文PDF格式(Academia.edu) 本文给出了机器学习中AdaBoost算法的一个简单初等证明,需要使用的数学工具为微积分-1. Adaboost is a powerful algori ...
- Adaboost算法初识
1.算法思想很简单: AdaBoost 是一种迭代算法,其核心思想是针对同一个训练集训练不同的分类器,即弱分类器,然后把这些弱分类器集合起来,构造一个更强的最终分类器.(三个臭皮匠,顶个诸葛亮) 它的 ...
- 【AdaBoost算法】积分图代码实现
一.积分图介绍 定义:图像左上方的像素点值的和: 在Adaboost算法中可用于加速计算Haar或MB-LBP特征值,如下图: 二.代码实现 #include <opencv/highgui.h ...
- Adaboost算法结合Haar-like特征
Adaboost算法结合Haar-like特征 一.Haar-like特征 目前通常使用的Haar-like特征主要包括Paul Viola和Michal Jones在人脸检测中使用的由Papageo ...
- AdaBoost 算法原理及推导
AdaBoost(Adaptive Boosting):自适应提升方法. 1.AdaBoost算法介绍 AdaBoost是Boosting方法中最优代表性的提升算法.该方法通过在每轮降低分对样例的权重 ...
- 数据挖掘学习笔记--AdaBoost算法(一)
声明: 这篇笔记是自己对AdaBoost原理的一些理解,如果有错,还望指正,俯谢- 背景: AdaBoost算法,这个算法思路简单,但是论文真是各种晦涩啊-,以下是自己看了A Short Introd ...
随机推荐
- 客户端ARPG角色行为模型
[概述] 对于玩家自身而言, 场景中的角色分两种:自己,别的生物(包括别的玩家,monster, npc等).而生物本身是一个集合{属性数据(状态), 行为(动作表现)}. 站在玩家自身的角度来看, ...
- Hibernate的Restrictions用法
Restrictions.eq --> equal,等于. Restrictions.allEq --> 参数为Map对象,使用key/value进行多个等于的比对,相当于多个Restri ...
- uva------Help is needed for Dexter(11384)
Problem H Help is needed for Dexter Time Limit: 3 Second Dexter is tired of Dee Dee. So he decided t ...
- Excepion
异常:就是程序在运行时出现不正常的情况. 异常由来:问题也就是现实生活中一个具体的食物,也可以通过java的类的形式进行秒速.并封装成对象.其实就是java对不正常情况进行毛素后的对象体现. 对于问题 ...
- 无法启动T-SQL 调试
问题详情 解决办法 1.要在服务器本机,不要远程 2.用实例名,不要用.或者local 3.以Windows身份验证的administrator或者sqlserver身份验证的sa登录
- HDU 1171(01背包)
Big Event in HDU Time Limit: 10000/5000 MS (Java/Others) Memory Limit: 65536/32768 K (Java/Others ...
- ZooKeeper(3.4.5) 使用Curator监听事件
转载:http://www.mamicode.com/info-detail-494364.html 标签: ZooKeeper原生的API支持通过注册Watcher来进行事件监听,但是Watcher ...
- C#识别验证码技术-Tesseract
相信大家在开发一些程序会有识别图片上文字(即所谓的OCR)的需求,比如识别车牌.识别图片格式的商品价格.识别图片格式的邮箱地址等等,当然需求最多的还是识别验证码.如果要完成这些OCR的工作,需要你掌握 ...
- Struts+Spring+Hibernate整合入门详解
Java 5.0 Struts 2.0.9 Spring 2.0.6 Hibernate 3.2.4 作者: Liu Liu 转载请注明出处 基本概念和典型实用例子. 一.基本概念 St ...
- 如何在datagridview 的head上绘制一个全选按钮
winform的项目中,经常要用到datagridview控件,但是为控件添加DataGridViewCheckBoxColumn来实现数据行选择这个功能的时候,经常需要提供全选反选功能,如果不重绘控 ...