elasticsearch 聚合之 date_histogram 聚合
1、背景
此处来简单学习一下 elasticsearch 的 date_histogram直方图聚合。它和普通的直方图histogram聚合差不多,但是date_histogram只可于 日期或日期范围 类型的值一起使用。
2、bucket_key如何计算
- 假设我们存在如下时间
2022-11-29 23:59:59。 - 在
es中时间为2022-11-29 23:59:59 +0000,因为上方的时间没有时区,所以会自动加上0时区,对应的时间戳为1669766399000 - 此处假设以
1d为单位来聚合 - 聚合统计中
time_zone的值为+0800 - bucket_key计算公式为
bucket_key = localToUtc(Math.floor(utcToLocal(value) / interval) * interval))
计算步骤如下:(此处是我自己的理解,如果不对欢迎指出)
utcToLocal(value)= 1669766399000(utc的值)+8*60*60*1000(time_zone +8的值) = 1669795199000Math.floor(utcToLocal(value) / interval) * interval)= Math.floor(1669795199000 / (24*60*60*1000)) * (24*60*60*1000) = 1669766400000localToUtc(...)=1669766400000-86060*1000=1669737600000key_as_string=utc时间1669737600000转换成东八区时间展示为=2022/11/30 00:00:00

3、前置知识
- 日期(
date)类型的字段在es中是以long类型的值保存的。 es中默认 默认的时区是0时区。- 如果我们有一个东八区的时间,那么在es中是如何存储的呢?
- 假设存在如下mapping
"invoked_time": {
"type": "date",
"format": ["yyyy-MM-dd HH:mm:ss"]
}
- 如果我们此时存在 如下
东八区时间2022-11-29 12:12:12,那么在 es 会存储为2022-11-29 12:12:12 +0000对应的时间戳,为什么会加上+0000,因为我们自己的时间字符串中没有时区,就会加上默认的0时区。
4、日历和固定时间间隔
既然我们是根据时间来进行聚合,那么必然就会涉及到这么一个问题。假设以天为单位来聚合,那么1天到底是固定的24小时呢,还是可变的呢? 因为存在时区的关系,在有的国家,在某些时区下,一天就不一定是24个小时。因此在es中提供了calendar-aware time intervals, 和 fixed time intervals. 两种类型。
4.1 Calendar intervals 日历间隔
日历感知间隔使用calendar_interval参数配置。 它可以自动感应到日历中的时区变化。它的单位只能是单数,不可是复数,比如2d就是错误的。
日历间隔 可用的单位为:分钟 (1m)、小时 (1h)、天 (1d)、星期 (1w)、月 (1M)、季度 (1q)、年 (1y)
举个例子:1m 是从何时开始的,何时结束的?.
所有的分钟都从00秒开始。一分钟是指定时区中第一分钟的00秒和下一分钟的00秒之间的时间间隔,用于补偿任何介于其间的闰秒,因此整点后的分钟数和秒数在开始和结束时是相同的。
4.2 Fixed intervals 固定间隔
固定间隔使用fixed_interval参数进行配置。
与日历感知间隔相比,固定间隔是固定数量的SI单位,无论它们落在日历的哪个位置,都不会偏离。一秒总是由1000ms组成。这允许以支持的单位的任意倍数指定固定间隔。但是,这意味着固定间隔不能表示其他单位,例如月,因为一个月的持续时间不是固定的数量。尝试指定月或季度等日历间隔将引发异常。
固定间隔 可用的单位为:
毫秒 (ms)
秒 (s)
定义为每个1000毫秒
分钟 (m)
所有分钟都从00秒开始。 定义为每个60秒(60,000毫秒)
小时 (h)
所有小时都从00分00秒开始。 定义为每60分钟(3,600,000毫秒)
天 (d)
所有天都在尽可能早的时间开始,通常是00:00:00(午夜)。 定义为24小时(86,400,000毫秒)
5、数据准备
5.1 准备mapping
PUT /index_api_invoked_time
{
"settings": {
"number_of_shards": 1
},
"mappings": {
"properties": {
"id": {
"type": "long"
},
"api": {
"type": "keyword"
},
"invoked_time": {
"type": "date",
"format": ["yyyy-MM-dd HH:mm:ss"]
}
}
}
}
5.2 准备数据
PUT /index_api_invoked_time/_bulk
{"index":{"_id":1}}
{"api":"/user/infos","invoked_time": "2022-11-26 00:00:00"}
{"index":{"_id":2}}
{"api":"/user/add"}
{"index":{"_id":3}}
{"api":"/user/update","invoked_time": "2022-11-26 23:59:59"}
{"index":{"_id":4}}
{"api":"/user/list","invoked_time": "2022-11-27 00:00:00"}
{"index":{"_id":5}}
{"api":"/user/export","invoked_time": "2022-11-29 23:59:59"}
{"index":{"_id":6}}
{"api":"/user/detail","invoked_time": "2022-12-01 01:00:00"}
6、聚合案例
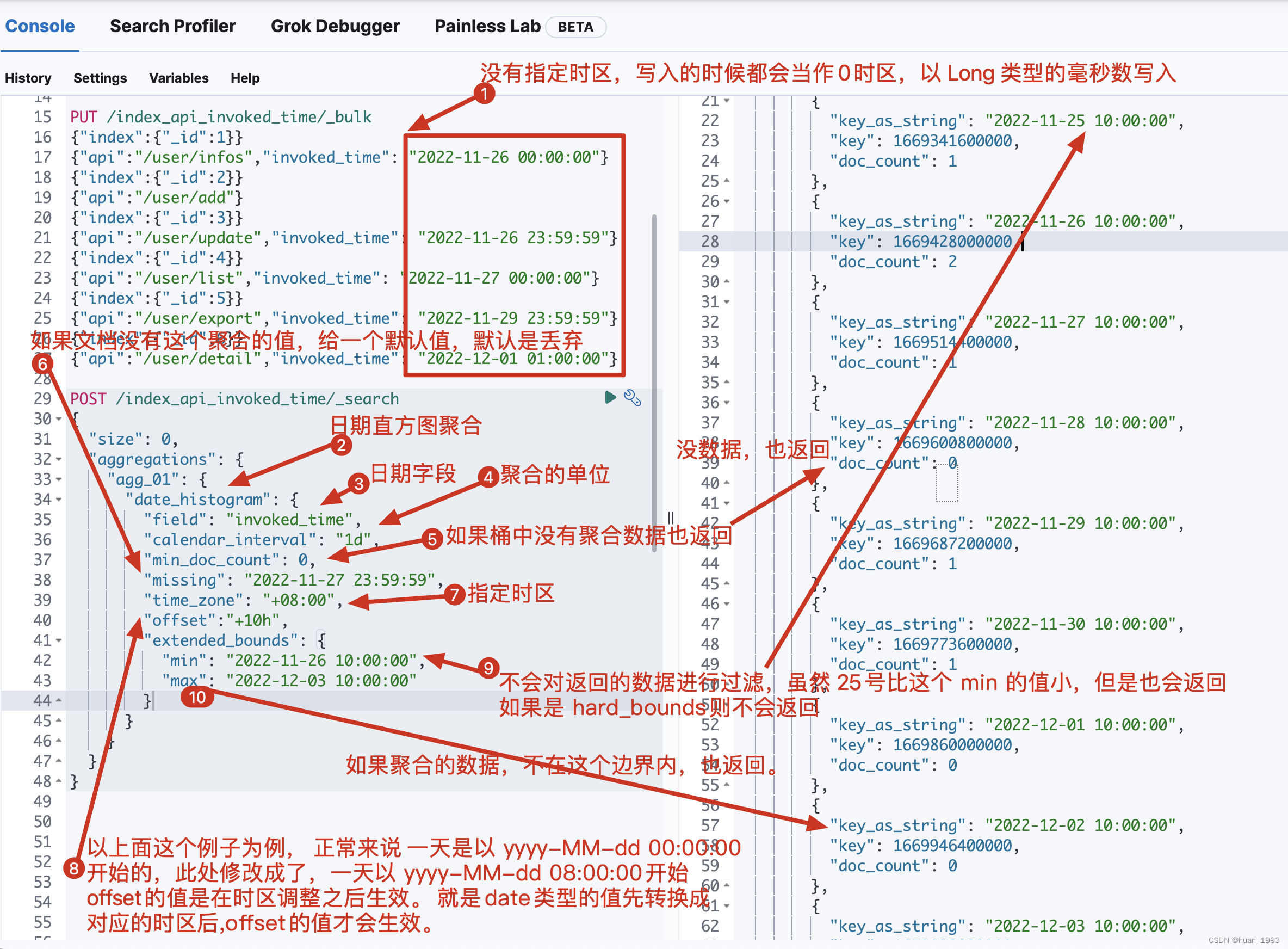
6.1 dsl
POST /index_api_invoked_time/_search
{
"size": 0,
"aggregations": {
"agg_01": {
"date_histogram": {
"field": "invoked_time",
"calendar_interval": "1d",
"min_doc_count": 0,
"missing": "2022-11-27 23:59:59",
"time_zone": "+08:00",
"offset":"+10h",
"extended_bounds": {
"min": "2022-11-26 10:00:00",
"max": "2022-12-03 10:00:00"
}
}
}
}
}
6.2 java代码
@Test
@DisplayName("日期直方图聚合")
public void test01() throws IOException {
SearchRequest request = SearchRequest.of(searchRequest ->
searchRequest.index("index_api_invoked_time")
.size(0)
.aggregations("agg_01", agg ->
agg.dateHistogram(dateAgg ->
// 聚合的字段
dateAgg.field("invoked_time")
// 聚合的单位,日历感知 单位为天,此时的一天不一定为24小时,因为夏令时时,有些国家一天可能只有23个小时
.calendarInterval(CalendarInterval.Day)
// 固定间隔, 此处可以指定 1天就是24小时
// .fixedInterval()
// 如果聚合的桶中,没有文档也返回
.minDocCount(0)
// 对于文档中,聚合字段缺失,此处给一个默认值,默认情况是此文档不参与聚合
.missing(DateTime.of("2022-11-27 23:59:59", DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss")))
// 时区
.timeZone("+08:00")
// 偏移,偏移是在时间在对应的时区调整之后,再去偏移
.offset(time -> time.time("+10h"))
// 如果返回的桶数据不在这个边界中,则给默认值,不会对数据进行过滤。
.extendedBounds(bounds ->
bounds.min(FieldDateMath.of(f -> f.expr("2022-11-26 10:00:00")))
.max(FieldDateMath.of(f -> f.expr("2022-12-03 10:00:00")))
)
)
)
);
System.out.println("request: " + request);
SearchResponse<String> response = client.search(request, String.class);
System.out.println("response: " + response);
}
6.3 聚合结果
7、完整代码
8、参考文档
- https://www.elastic.co/guide/en/elasticsearch/reference/current/search-aggregations-bucket-datehistogram-aggregation.html#date-histogram-missing-value
- https://www.pipiho.com/es/7.7/cn/search-aggregations-bucket-datehistogram-aggregation.html
elasticsearch 聚合之 date_histogram 聚合的更多相关文章
- ElasticSearch 2 (35) - 信息聚合系列之近似聚合
ElasticSearch 2 (35) - 信息聚合系列之近似聚合 摘要 如果所有的数据都在一台机器上,那么生活会容易许多,CS201 课商教的经典算法就足够应付这些问题.但如果所有的数据都在一台机 ...
- ElasticSearch 2 (34) - 信息聚合系列之多值排序
ElasticSearch 2 (34) - 信息聚合系列之多值排序 摘要 多值桶(terms.histogram 和 date_histogram)动态生成很多桶,Elasticsearch 是如何 ...
- ElasticSearch 2 (31) - 信息聚合系列之时间处理
ElasticSearch 2 (31) - 信息聚合系列之时间处理 摘要 如果说搜索是 Elasticsearch 里最受欢迎的功能,那么按时间创建直方图一定排在第二位.为什么需要使用时间直方图? ...
- Elasticsearch(9) --- 聚合查询(Bucket聚合)
Elasticsearch(9) --- 聚合查询(Bucket聚合) 上一篇讲了Elasticsearch聚合查询中的Metric聚合:Elasticsearch(8) --- 聚合查询(Metri ...
- java操作elasticsearch实现组合桶聚合
1.terms分组查询 //分组聚合 @Test public void test40() throws UnknownHostException{ //1.指定es集群 cluster.name 是 ...
- ElasticSearch 2 (37) - 信息聚合系列之内存与延时
ElasticSearch 2 (37) - 信息聚合系列之内存与延时 摘要 控制内存使用与延时 版本 elasticsearch版本: elasticsearch-2.x 内容 Fielddata ...
- ElasticSearch 2 (38) - 信息聚合系列之结束与思考
ElasticSearch 2 (38) - 信息聚合系列之结束与思考 摘要 版本 elasticsearch版本: elasticsearch-2.x 内容 本小节涵盖了许多基本理论以及很多深入的技 ...
- ElasticSearch 2 (36) - 信息聚合系列之显著项
ElasticSearch 2 (36) - 信息聚合系列之显著项 摘要 significant_terms(SigTerms)聚合与其他聚合都不相同.目前为止我们看到的所有聚合在本质上都是简单的数学 ...
- ElasticSearch 2 (33) - 信息聚合系列之聚合过滤
ElasticSearch 2 (33) - 信息聚合系列之聚合过滤 摘要 聚合范围限定还有一个自然的扩展就是过滤.因为聚合是在查询结果范围内操作的,任何可以适用于查询的过滤器也可以应用在聚合上. 版 ...
- ElasticSearch 2 (32) - 信息聚合系列之范围限定
ElasticSearch 2 (32) - 信息聚合系列之范围限定 摘要 到目前为止我们看到的所有聚合的例子都省略了搜索请求,完整的请求就是聚合本身. 聚合与搜索请求同时执行,但是我们需要理解一个新 ...
随机推荐
- WinUI 3 踩坑记:第一个窗口
本文是 WinUI 3 踩坑记 的一部分,该系列发布于 GitHub@Scighost/WinUI3Keng,文中的代码也在此仓库中,若内容出现冲突以 GitHub 上的为准. WinUI 3 应用的 ...
- GitHub desktop常见问题及解决办法
1.There are unresolved conflicts in the working directory. 问题出现:A台电脑push代码后,可能新建了分支,然后B电脑打开GitHub de ...
- 工程课Linux第一节笔记
上课笔记 文件系统结构 /根目录 /bin/ 存放系统命令,普通用户与root都可以执行 /etc/ 配置文件保存位置 /lib/ 系统调用的函数库保存位置 /var/ 目录用于存储动态数据,例如缓存 ...
- SEO知识点
SEO中的长尾理论 长尾关键词就是包含关键信息,但是搜索量比较少的句子或词组. 每一个长尾关键词都可能会为网站带来流量.一般一个较大的网站,流量的主要来源可能都由长尾关键词构成,因为网站除了目标关键词 ...
- 黑马程序员关于MongoDB的教程
基础:https://files.cnblogs.com/files/sanduzxcvbnm/mongodb_base.pdf 理解 MongoDB的业务场景.熟悉MongoDB的简介.特点和体系结 ...
- 【前端必会】eslint搞起
介绍 eslint进行代码审查,统一代码风格,预防潜在BUG 官网 https://eslint.bootcss.com/docs/user-guide/getting-started 安装 init ...
- Anaconda安装和卸载+虚拟环境Tensorflow安装以及末尾问题大全(附Anaconda安装包),这一篇就够了!!!
前言 实话说,在自己亲手捣鼓了一下午加一晚上后,本人深深地感受到了对于"Anaconda安装+虚拟环境Tensorflow安装"里面的坑点之多,再加上目前一些博主的资料有点久远,尤 ...
- 【Wine使用经验分享】Wine字体显示问题处理
字体不显示/字体为□ 首先尝试下载simsun字体到/usr/share/fonts (simsun.ttf simsun.ttc) 在新版本wine上,差不多就能解决问题. 如果还不行,就从网上下载 ...
- BigDecimal 用法总结
转载请注明出处: 目录 1.BigDecimal 简介 2.构造BigDecimal的对象 3.常用方法总结 4.divide方法使用 5.setScale 方法使用 6.BigDecimal 数据库 ...
- Docker容器技术基础
Docker基础 目录 Docker基础 容器(Container) 传统虚拟化与容器的区别 Linux容器技术 Linux Namespaces CGroups LXC docker基本概念 doc ...