ARMv8之memory model和Observability(四)
最近在学习整理ARMv8的memory 相关知识,对memory的各种概念搞的头痛,太难读了!!有幸看看窝窝大神整理了部分知识,关键是讲解的地道,透彻。因此在这里学习并转载一下,也希望能够和大家一起探讨,共同进步。
1. memory model
1.1 memory model的概念
想要理解ARMv8的memory model,首先需要知道什么是memory model,或者说memory consistency model(内存一致性模型)。
当cpu从memory中的某个位置发起一次读操作的时候,该操作的返回值应该是什么样子的呢?对于程序员,直觉就是当然返回上次写入的数值了。不过,怎么定义“上次”呢?对于单核的执行环境,“上次”比较容易定义,从program order中可以轻易的得出上一次对该地址的写入操作。对于share-memory的多核环境而言,如何定义“上次”呢?那么多Hardware Thread在并发执行程序(每个cpu core上都有自己的指令流,都有自己的program order),想找出“上次”还不是一个显而易见的事情啊(当从两个不同CPU core上发起了对同一个memory location的访问,谁先谁后是无法通过program order来定义的)。为了搞清楚这个问题,我们必须要引入memory consistency model这个概念。所谓memory consistency model,其实就是就是定义系统中对内存访问需要遵守的规则(本质上就是read操作返回什么样的值),了解了这些规则,软件和硬件才能和谐工作,软件工程师才能写出逻辑正确的程序。
memory consistency model的规则影响了一大票人:使用高级语言的程序员、写编译器的软件工程师、CPU设计人员。做为一个程序员,一个有情怀的c程序员,我期望的memory model符合c语言的基本逻辑,内存操作是按照c程序中的program order进行的,而且是有序的进行,符合c程序的逻辑推导的,一言以蔽之,程序员当然希望能够编程简单,不要考虑什么memory order啊,memory barrier什么的。不过,从系统设计人员的角度看呢,需要找到一个各方面都OK的memory model。你看,系统设计人员就是高瞻远瞩啊,可以从多方面考虑,在性能和编程易用性方面平衡。
1.2 sequential consistency的概念
我们从ARMv8的手册中知道它的memory consistency model是属于Relaxed Memory Consistency Models,这里的“Relaxed”是针对sequential consistency而言的,因此我们先解释什么是sequential consistency,定义如下:
“the result of any execution is the same as if the operations of all the processors were executed in some sequential order, and the operations of each individual processor appear in this sequence in the order specified by its program”.
通俗的讲,如果shared memory multicore系统符合sequential consistency模型,那么在多个cpu core上执行的程序就好象在一个单一cpu core上顺序执行一样。例如如果系统有两个cpu,分别是core 0和core 1,core 0执行了A B C D内存访问指令,core 1执行了a b c d内存访问指令,对于程序员而言,sequential consistency的系统上执行这8条指令的效果就好象在一个core上顺序执行了A a B b C c D d的指令流。当然,上面只是给出一个示例的程序执行流,实际上也可以是A B a b C c D d,也可以是A B C D a b c d,也可以是……只要你熟悉排列组合的原理,就能把所有可能的顺序罗列出来。当然,也不是任意的排组合都OK,因为这个综合效果的指令流必须符合core 0的program order(即单独从core 0的角度看,其program order必须是A->B->C->D),必须符合core 1的program order(即单独从core 1的角度看,其program order必须是a->b->c->d)。我们可以总结sequential consistency模型的两条规则:
(1)各个cpu core按照其program order来执行程序,执行完一条,然后启动下一条指令的执行,不会有local reordering。为了理解这条规则,我们来看看著名的Dekker algorithm,代码如下:
| core 0 | core 1 |
| flag0 = 1; if (flag1 == 0) enter critical section |
flag1 = 1; if (flag0 == 0) enter critical section |
上面代码的初始条件是flag0 = flag1 = 0。在core 0上,当想要进入临界区的时候,会设定flag0等于1,并且判断flag1的值是否等于0,如果等于0,则说明core 1没有进入临界区,还没有执行flag1=1这一条指令,同时也就隐含了flag0=1的赋值已经执行完毕。对于sequential consistency模型,各个CPU core能够保证自己的local program order被严格执行,从而保证了不会有多个thread同时进入临界区。
(2)从全局来看,每一个写的操作,都被系统中的所有cpu core同时感知到。注意上面句子中的“同时”,这也就意味着cpu 系统(包括所有的cpu core们)和存储系统之间有一个开关,一次只会连接一个CPU core和存储系统,因此对memory的访问都是原子的、串行化的。例如:某个cpu core对某个内存操作进行write操作,该操作完成之后,那个开关才会放下一个内存操作进入存储系统。我们用下面的代码示例来解释这一条规则:
| core 0 | core 1 | core 2 |
| A = 1; |
if (A == 1) B = 1; |
if (B== 1) load A |
上面代码的初始条件是A = B = 0。对于sequential consistency模型,我们可以进行下面的推导:对于core 1,如果该处理器执行了B=1的赋值语句的时候,说明core 1已经感知到了core 0上对A变量的write操作,因此core 2必须也知道了A等于1这个事实。因此,在core 2上执行load A操作的时候,这时候A值必须要等于1。
程序员当然喜欢简单、直观的sequential consistency模型,但是,这也限制了CPU硬件和编译器的优化,从而影响了整个系统的性能。怎么办?答案是显而易见的,云计算、大数据等等这些真实用户的需求(要求更好的performance)无情的碾压了程序员的“小确幸”,因此,骚年们,直面“惨淡的人生”吧,这也就是relaxed consistency model。
1.3 relaxed consistency model 的概念
通过上一节,我们了解到sequential consistency模型中的各种要求,这些对内存操作顺序的要求实际上是对性能的限制和束缚,为了性能,能不能放松(relax)这些要求呢?当然没有问题,否则也就不会有relaxed consistency model的商业化应用了。这些发送内存操作的要求可以被分成两个类别:
(1)CPU core是否可以不按照program order的顺序来执行代码?进一步又可以分成RAW(Read after Write),WAW(write after write)和WAR(write after read)三种情况。需要特别强调的是这些内存操作对(RW,WR或者WW)必须操作不同的memory location,否则,这些操作是有数据依赖关系,CPU必须保证起操作顺序,否则在单CPU core上的程序逻辑就不对了。对于ARMv8而言,如果没有memory barrier指令,program order中的RAW,WAW和WAR的内存操作对都可以被reorder。
(2)CPU core的write操作是否必须是全局原子性的。对于sequential consistency,一个写的动作,会被其他CPU core同时观察到,即要么全部观察到新值,要么全部观察到旧值,不会有中间情况的存在。有的内存模型可以允许某个cpu core的read操作返回其他cpu core写入的新值,而其他的cpu core仍然观察到旧值。这里实际上说的是Multi-copy atomicity,对于ARMv8而言,normal memory的写入操作不具备Multi-copy atomicity的特性。
当然,无论如何的放松要求,下面的要求不能放松:
(1)在单核上,程序中的数据依赖和控制依赖必须保证,即有依赖关系的内存操作必须保证操作顺序,不能out of order。
(2)对同一地址的memory location的写入操作必须是串行化的。如果系统中有cache,那么需要cache coherence protocol来保证这一点。
2. Observability
2.1 observer 的概念
原文定义:
An observer is a master in the system that is capable of observing memory accesses
从字面的意思看,能够“观察”到内存访问行为的master角色的硬件组件就是observer。这里需要解释两个关键词:一个是master,另外一个是观察(observing)。一个observer首先需要是一个总线master,可以通过总线发出读写操作。而所谓“观察”,实际上也通过read或者write操作来感知其他的内存操作,例如:通过read操作,observer可以感知到内存值的数据变化。当然,observer不仅仅能够读,还可以执行写操作,一个PE中可能的observer包括:
- 执行load或者store操作的CPU组件(能够对内存发起读或者写操作)
- 执行取指操作的CPU组件(仅仅能够发起对内存的read操作)
- 加载页表的CPU组件(仅仅能够发起对内存的read操作)
从上面的描述可知,并非系统中有多少个CPU core(或者称为PE)就有多少个observer,一个PE往往包括多个observer。实际上,系统中的observer的数目是和具体的实现相关,除了PE之外,GPU,DMA controller等都可以发起对memory的read或者write操作,也都是observer。
2.2 Observability的概念
可以用下面通俗的语言来描述Observability:
I have observed your write when I can read what you wrote and I have observed your read when I can no longer change the value you read.
这里的I和you都是指的系统中的observer。上面的这句话是针对两个场景:
- 一个是对写动作的观察,I have observed your write when I can read what you wrote,当A observer通过对X地址的读操作获取了另外B observer对X地址的写入数值的时候,那么,可以认为A observer观察到了B observer的写入动作。
- 另外一个场景是对读动作的观察,I have observed your read when I can no longer change the value you read,当A observer无法通过对地址X的值的写入操作来影响B observer的对X地址的read操作结果的时候,我们认为A observer观察到了B observer的read动作。
2.3 observed write
原文定义:
A write to a location in memory is said to be observed by an observer when:
• A subsequent read of the location by the same observer returns the value written by the observed write, or written by a write to that location by any observer that is sequenced in the Coherence order of the location after the observed write.
• A subsequent write of the location by the same observer is sequenced in the Coherence order of the location after the observed write.
什么叫一次写入的内存操作被某个observer观察到(observed)?这事不能从单个写入操作看,还是让我们拉高一些,从一个写入序列来看。我们还是通过一个经典的例子来说明observed write这个概念。假设系统中有四个cpu core,分别执行同样的代码:cpux给一个全局变量A赋值为x,然后不断对A进行观察(即load操作)。在这个例子中A分别被四个CPU设定了1、 2、3、4的值,当然,先赋值的操作结果会被后来赋值操作覆盖,最后那个执行的write操作则决定了A变量最后的赋值。假设一次运行后,cpu 1看到的序列是{1,2},cpu 2看到的序列是{2},cpu 3看到的序列是{3,2},cpu 4看到的序列是{4,2},具体如下图所示:
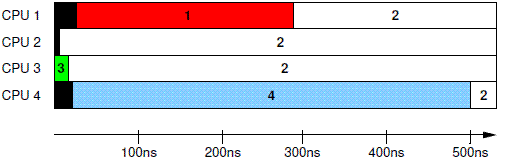
我们先选定一个观察对象:cpu4的写入操作。怎么观察呢?通过read或者write来观察(英文原文的两段解释就是分别针对read和write的)。我们先看read吧,这是最直观的感受(或者称为观察)cpu4的写入动作的方法。有两种情况都可以认为本observer已经观察到了cpu4的写入操作:
- 该observer的read操作返回了“4”。例如在cpu4上,read返回了之前write的数值“4”
- 该observer的read操作没有返回“4”,但是返回了Coherence order 排在4之后的数值。例如,对于cpu1而言,刚开始,其read操作返回“1”(红色条带),大概在300ns的时间左右,read操作返回了“2”,我们知道,对于全局变量A,其coherent order是{3,1,4,2},只要返回了coherent order序列中,4之后的数值,我们就认为该observer已经观察到了cpu4的对全局变量A写入数值4的操作。
通过write来“观察”另外一个write操作有点不是那么符合人类的逻辑思维,但是可以慢慢适应的,毕竟我们的目标是理解multiprocessing environment。对于write而言,只有一种情况认为本observer已经观察到了cpu4的写入操作:即做为观察者的那个observer的写入动作在coherent order序列中排在“4”之后。对于cpu 2而言,当执行写入2的操作的时候,我们认为,cpu 2已经观察到了cpu4的写入操作。
需要强调的是,本节描述的observed write都是以一个特定的observer为视角的,不是全局的概念。
2.4 globally observed write
原文定义:
A write to a location in memory is said to be globally observed for a shareability domain or set of observers when:
• A subsequent read of the location by any observer in that shareability domain returns the value written by the globally observed write, or written by a write to that location by any observer that is sequenced in the Coherence order of the location after the globally observed write.
• A subsequent write of the location by any observer in that shareability domain is sequenced in the
Coherence order of the location after the globally observed write.
理解了上一节的内容,这里几乎不需要过多的解释,只需要强调两点:
- globally observed write是限定在一个shareability domain内部,或者指定的一个observer的集合。
- 当一个shareability domain(observer集合)内所有的observer都观察到了一次write操作,那么就是globally observed write。
2.5 observed read和globally observed read
原文定义:
• A read of a location in memory is said to be observed by an observer when a subsequent write to the location by the same observer has no effect on the value returned by the read.
• A read of a location in memory is said to be globally observed for a shareability domain when a subsequent write to the location by any observer in that shareability domain has no effect on the value returned by the read.
怎么观察(感知)其他observer的读操作的确是一个技术活,通过read毫无疑问是不可能感知的,唯有通过write来感知。当某个observer无法通过write操作来影响被观察者的read操作的时候,我们就认为该observer已经感知到了该read操作。类似的,globally observed read就是一个shareability domain内所有的observer们都观察到了该read操作。
2.6 内存访问指令的执行完成(completion)
原文定义:
A read or write is complete for a shareability domain when all of the following are true:
• The read or write is globally observed for that shareability domain.
• Any translation table walks associated with the read or write are complete for that shareability domain.
内存访问指令被观察到和内存访问指令执行完毕是两个不同的概念,对于内存访问指令执行完毕,需要满足下面的两个条件:
- 该内存访问操作被特定的shareability domain内的所有的observer globally observed
- 和该内存访问指令相关的translation table walks(也会引发内存访问操作)必须执行完毕。
这里又牵扯出另外一个问题:什么叫做translation table walks执行完毕?原文定义如下:
A translation table walk is complete for a shareability domain when the memory accesses associated with the translation table walk are globally observed for that shareability domain, and the TLB is updated.
需要满足两个条件:
- 这个translation table walks而引起的内存访问操作被该shareability domain内的所有的observer globally observed;
- TLB已经完成更新;
本文转载自:
(1)ARMv8之memory model
(2)ARMv8之Observability
ARMv8之memory model和Observability(四)的更多相关文章
- 【原创】(四)Linux内存模型之Sparse Memory Model
背景 Read the fucking source code! --By 鲁迅 A picture is worth a thousand words. --By 高尔基 说明: Kernel版本: ...
- 当我们在谈论JMM(Java memory model)的时候,我们在谈论些什么
前面几篇中,我们谈论了synchronized.final以及voilate的用法和底层实现,都绕不开一个话题-Java内存模型(java memory model,简称JMM).Java内存模型是保 ...
- Java (JVM) Memory Model – Memory Management in Java
原文地址:http://www.journaldev.com/2856/java-jvm-memory-model-memory-management-in-java Understanding JV ...
- 还是说Memory Model,gcc的__sync_synchronize真是太坑爹了
还是说Memory Model,gcc的__sync_synchronize真是太坑爹了! 时间 2012-01-29 03:18:35 IT牛人博客聚合网站 原文 http://www.udpw ...
- memory model
最近看C++11 atomic发现对memory_order很是不理解,memory_order_relaxed/memory_order_consume/memory_order_acquire/m ...
- Keil中Memory Model和Code Rom Size说明
C51中定义变量时如果省略存储器类型,Keil C51编译系统则会按编译模式SMALL.COMPACT和LARGE所规定的默认存储器类型去指定变量的存储区域,无论什么存储模式都可以声明变量在任何的80 ...
- 【翻译】go memory model
https://studygolang.com/articles/819 原文链接 Introduction The Go memory model specifies the conditions ...
- 并发研究之Java内存模型(Java Memory Model)
Java内存模型JMM java内存模型定义 上一遍文章我们讲到了CPU缓存一致性以及内存屏障问题.那么Java作为一个跨平台的语言,它的实现要面对不同的底层硬件系统,设计一个中间层模型来屏蔽底层的硬 ...
- java学习:JMM(java memory model)、volatile、synchronized、AtomicXXX理解
一.JMM(java memory model)内存模型 从网上淘来二张图: 上面这张图说的是,在多核CPU的系统中,每个核CPU自带高速缓存,然后计算机主板上也有一块内存-称为主内(即:内存条).工 ...
- CUDA ---- Memory Model
Memory kernel性能高低是不能单纯的从warp的执行上来解释的.比如之前博文涉及到的,将block的维度设置为warp大小的一半会导致load efficiency降低,这个问题无法用war ...
随机推荐
- 知乎问题之:.NET AOT编译后能替代C++吗?
标题上的Native库是指:Native分为静态库( 作者:nscript链接:https://www.zhihu.com/question/536903224/answer/2522626086 ( ...
- Golang实现set
背景 Golang语言本身未实现set,但是实现了map golang的map是一种无序的键值对的集合,其中键是唯一的 而set是键的不重复的集合,因此可以用map来实现set Empty 由于map ...
- Lua 支持虚函数的解决方案
概述 lua本身没有提供类似C++虚函数机制,调用的父类方法调用虚函数可能会出现问题. 问题分析 分析这段代码和输出 local Gun = {} -- 示例,实际应用还要考虑构造,虚表等情况 fun ...
- [Python]-json模块-处理字典数据的存取
import json 函数 json.dumps() json.dumps()函数是将字典转化为字符串 json.loads() json.loads()函数是将字符串转化为字典 注意: 从json ...
- 6、Arrays类
Arrays类 Arrays里面包含了一系列静态方法,用于管理或操作数组(比如排序和搜索) 常用方法 toString 返回数组的字符串形式 Arrays.toString(arr) Integer[ ...
- 第六章:Django 综合篇 - 3:使用MySQL数据库
在实际生产环境,Django是不可能使用SQLite这种轻量级的基于文件的数据库作为生产数据库.一般较多的会选择MySQL. 下面介绍一下如何在Django中使用MySQL数据库. 一.安装MySQL ...
- 银河麒麟安装node,mysql,forever环境
这就是国产银河系统的界面,测试版本是麒麟V10 链接: https://pan.baidu.com/s/1_-ICBkgSZPKvmcdy1nVxVg 提取码: xhep 一.传输文件 cd /hom ...
- Java中的多线程的创建方式
首先理清几个基本概念: 程序:为完成特定任务,用某种语言编写的一组指令的集合.即一段静态的代码(还没运行起来) 进程:是程序的一次执行过程,也就是说程序运行起来了,加载到了内存中,并占用了cpu的资源 ...
- 手把手教你使用LabVIEW OpenCV dnn实现物体识别(Object Detection)含源码
前言 今天和大家一起分享如何使用LabVIEW调用pb模型实现物体识别,本博客中使用的智能工具包可到主页置顶博客LabVIEW AI视觉工具包(非NI Vision)下载与安装教程中下载 一.物体识别 ...
- 糟了,线上服务出现OOM了
前言 前一段时间,公司同事的一个线上服务OOM的问题,我觉得挺有意思的,在这里跟大家一起分享一下. 我当时其实也参与了一部分问题的定位. 1 案发现场 他们有个mq消费者服务,在某一天下午,出现OOM ...