Java实现BP神经网络MNIST手写数字识别
Java实现BP神经网络MNIST手写数字识别
如果需要源码,请在下方评论区留下邮箱,我看到就会发过去
一、神经网络的构建
(1):构建神经网络层次结构
由训练集数据可知,手写输入的数据维数为784维,而对应的输出结果为分别为0-9的10个数字,所以根据训练集的数据可知,在构建的神经网络的输入层的神经元的节点个数为784个,而对应的输出层的神经元个数为10个。隐层可选择单层或多层。
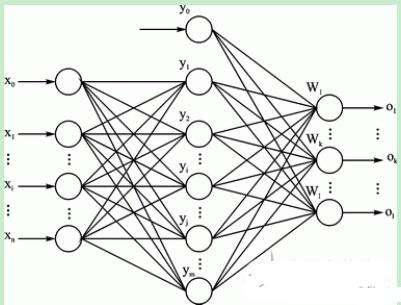
(2):确定隐层中的神经元的个数
因为对于隐层的神经元个数的确定目前还没有什么比较完美的解决方案,所以对此经过自己查阅书籍和上网查阅资料,有以下的几种经验方式来确定隐层的神经元的个数,方式分别如下所示:
一般取(输入+输出)/2
隐层一般小于输入层
3)(输入层+1)/2
log(输入层)
log(输入层)+10
实验得到以第五种的方式得到的测试结果相对较高。
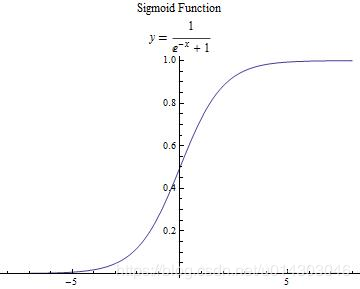
(3):设置神经元的激活函数
在《机器学习》的书中介绍了两种比较常用的函数,分别是阶跃函数和Sigmoid函数。最后自己采用了后者函数。
(4):初始化输入层和隐层之间神经元间的权值信息
采用的是使用简单的随机数分配的方法,并且两层之间的神经元权值是通过二维数组进行保留,数组的索引就代表着两层对应的神经元的索引信息
(5):初始化隐层和输出层之间神经元间的权值信息
采用的是使用简单的随机数分配的方法,并且两层之间的神经元权值是通过二维数组进行保留,数组的索引就代表着两层对应的神经元的索引信息
(6):读取CSV测试集表格信息,并加载到程序用数据保存,其中将每个维数的数据都换成了0和1的二进制数进行处理。
(7):读取CSV测试集结果表格信息,并加载到程序用数据保存
(8):计算输入层与隐层中隐层神经元的阈值
这里主要是采用了下面的方法:
Sum=sum+weight[i][j] * layer0[i];
参数的含义:将每个输入层中的神经元与神经元的权值信息weight[i][j]乘以对应的输入层神经元的阈值累加,然后再调用激活函数得到对应的隐层神经元的阈值。
(9):计算隐层与输出层中输出层的神经元的阈值
方法和上面的类似,只是相对应的把权值信息进行了修改即可。
(10):计算误差逆传播(输出层的逆误差)
采用书上P103页的方法(西瓜书)
(11):计算误差传播(隐层的逆误差)
采用书上P103页的方法(西瓜书)
(12):更新各层神经元之间的权值信息
double newVal = momentum * prevWeight[j][i] + eta * delta[i] * layer[j];
参数:其中设置momentum 为0.9,设置eta 为0.25,prevWeight[j][i]表示神经元之间的权值,layer[j]和delta[i]表示两层不同神经元的阈值。
(13):循环迭代训练5次
(14):输入测试集数据
(15):输出测试集预测结果和实际结果进行比较,得到精确度
此处放一个多隐层BP神经网络的类(自己写的,有错误请指出):
/**
* BP神经网络类
* 使用了附加动量法进行优化
* 主要使用方法:
* 初始化: BP bp = new BP(new int[]{int,int*n,int}) //第一个int表示输入层,中间n个int表示隐藏层,最后一个int表示输出层
* 训练: bp.train(double[],double[]) //第一个double[]表示输入,第二个double[]表示期望输出
* 测试 int result = bp.test(double[]) //参数表示输入,返回值表示输出层最大权值
* 另有设置学习率和动量参数方法
*/
import java.util.Random;
public class BP {
private final double[][] layers;//输入层、隐含层、输出层
private final double[][] deltas;//每层误差
private final double[][][] weights;//权值
private final double[][][] prevUptWeights;//更新之前的权值信息
private final double[] target; //预测的输出内容
private double eta; //学习率
private double momentum; //动量参数
private final Random random; //主要是对权值采取的是随机产生的方法
//初始化
public BP(int[] size, double eta, double momentum) {
int len = size.length;
//初始化每层
layers = new double[len][];
for(int i = 0; i<len; i++) {
layers[i] = new double[size[i] + 1];
}
//初始化预测输出
target = new double[size[len - 1] + 1];
//初始化隐藏层和输出层的误差
deltas = new double[len - 1][];
for(int i = 0; i < (len - 1); i++) {
deltas[i] = new double[size[i + 1] + 1];
}
//使每次产生的随机数都是第一次的分配,这是有参数和没参数的区别
random = new Random(100000);
//初始化权值
weights = new double[len - 1][][];
for(int i = 0; i < (len - 1); i++) {
weights[i] = new double[size[i] + 1][size[i + 1] + 1];
}
randomizeWeights(weights);
//初始化更新前的权值
prevUptWeights = new double[len - 1][][];
for(int i = 0; i < (len - 1); i++) {
prevUptWeights[i] = new double[size[i] + 1][size[i + 1] + 1];
}
this.eta = eta; //学习率
this.momentum = momentum; //动态量
}
//随机产生神经元之间的权值信息
private void randomizeWeights(double[][][] matrix) {
for (int i = 0, len = matrix.length; i != len; i++) {
for (int j = 0, len2 = matrix[i].length; j != len2; j++) {
for(int k = 0, len3 = matrix[i][j].length; k != len3; k++) {
double real = random.nextDouble(); //随机分配着产生0-1之间的值
matrix[i][j][k] = random.nextDouble() > 0.5 ? real : -real;
}
}
}
}
//初始化输入层,隐含层,和输出层
public BP(int[] size) {
this(size, 0.25, 0.9);
}
//训练数据
public void train(double[] trainData, double[] target) {
loadValue(trainData,layers[0]); //加载输入的数据
loadValue(target,this.target); //加载输出的结果数据
forward(); //向前计算神经元权值(先算输入到隐含层的,然后再算隐含到输出层的权值)
calculateDelta(); //计算误差逆传播值
adjustWeight(); //调整更新神经元的权值
}
//加载数据
private void loadValue(double[] value,double [] layer) {
if (value.length != layer.length - 1)
throw new IllegalArgumentException("Size Do Not Match.");
System.arraycopy(value, 0, layer, 1, value.length); //调用系统复制数组的方法(存放输入的训练数据)
}
//向前计算(先算输入到隐含层的,然后再算隐含到输出层的权值)
private void forward() {
//计算隐含层到输出层的权值
for(int i = 0; i < (layers.length - 1); i++) {
forward(layers[i], layers[i+1], weights[i]);
}
}
//计算每一层的误差(因为在BP中,要达到使误差最小)(就是逆传播算法,书上有P101)
private void calculateDelta() {
outputErr(deltas[deltas.length-1],layers[layers.length - 1],target); //计算输出层的误差(因为要反过来算,所以先算输出层的)
for(int i = (layers.length - 1); i > 1; i--) {
hiddenErr(deltas[i - 2/*输入层没有误差*/],layers[i - 1],deltas[i - 1],weights[i - 1]); //计算隐含层的误差
}
}
//更新每层中的神经元的权值信息
private void adjustWeight() {
for(int i = (layers.length - 1); i > 0; i--) {
adjustWeight(deltas[i - 1], layers[i - 1], weights[i - 1], prevUptWeights[i - 1]);
}
}
//向前计算各个神经元的权值(layer0:某层的数据,layer1:下一层的内容,weight:某层到下一层的神经元的权值)
private void forward(double[] layer0, double[] layer1, double[][] weight) {
layer0[0] = 1.0;//给偏置神经元赋值为1(实际上添加了layer1层每个神经元的阙值)简直漂亮!!!
for (int j = 1, len = layer1.length; j != len; ++j) {
double sum = 0;//保存权值
for (int i = 0, len2 = layer0.length; i != len2; ++i) {
sum += weight[i][j] * layer0[i];
}
layer1[j] = sigmoid(sum); //调用神经元的激活函数来得到结果(结果肯定是在0-1之间的)
}
}
//计算输出层的误差(delte:误差,output:输出,target:预测输出)
private void outputErr(double[] delte, double[] output,double[] target) {
for (int idx = 1, len = delte.length; idx != len; ++idx) {
double o = output[idx];
delte[idx] = o * (1d - o) * (target[idx] - o);
}
}
//计算隐含层的误差(delta:本层误差,layer:本层,delta1:下一层误差,weights:权值)
private void hiddenErr(double[] delta, double[] layer, double[] delta1, double[][] weights) {
for (int j = 1, len = delta.length; j != len; ++j) {
double o = layer[j]; //神经元权值
double sum = 0;
for (int k = 1, len2 = delta1.length; k != len2; ++k) //由输出层来反向计算
sum += weights[j][k] * delta1[k];
delta[j] = o * (1d - o) * sum;
}
}
//更新每层中的神经元的权值信息(这也就是不断的训练过程)
private void adjustWeight(double[] delta, double[] layer, double[][] weight, double[][] prevWeight) {
layer[0] = 1;
for (int i = 1, len = delta.length; i != len; ++i) {
for (int j = 0, len2 = layer.length; j != len2; ++j) {
//通过公式计算误差限=(动态量*之前的该神经元的阈值+学习率*误差*对应神经元的阈值),来进行更新权值
double newVal = momentum * prevWeight[j][i] + eta * delta[i] * layer[j];
weight[j][i] += newVal; //得到新的神经元之间的权值
prevWeight[j][i] = newVal; //保存这一次得到的权值,方便下一次进行更新
}
}
}
//我这里用的是sigmoid激活函数,当然也可以用阶跃函数,看自己选择吧
private double sigmoid(double val) {
return 1d / (1d + Math.exp(-val));
}
//测试神经网络
public int test(double[] inData) {
if (inData.length != layers[0].length - 1)
throw new IllegalArgumentException("Size Do Not Match.");
System.arraycopy(inData, 0, layers[0], 1, inData.length);
forward();
return getNetworkOutput();
}
//返回最后的输出层的结果
private int getNetworkOutput() {
int len = layers[layers.length - 1].length;
double[] temp = new double[len - 1];
for (int i = 1; i != len; i++)
temp[i - 1] = layers[layers.length - 1][i];
//获得最大权值下标
double max = temp[0];
int idx = -1;
for (int i = 0; i <temp.length; i++) {
if (temp[i] >= max) {
max = temp[i];
idx = i;
}
}
return idx;
}
//设置学习率
public void setEta(double eta) {
this.eta = eta;
}
//设置动量参数
public void setMomentum(double momentum){
this.momentum = momentum;
}
}
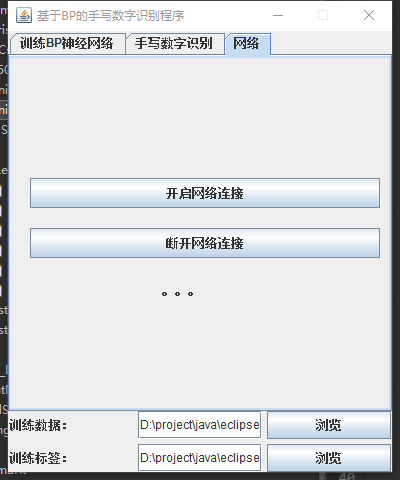
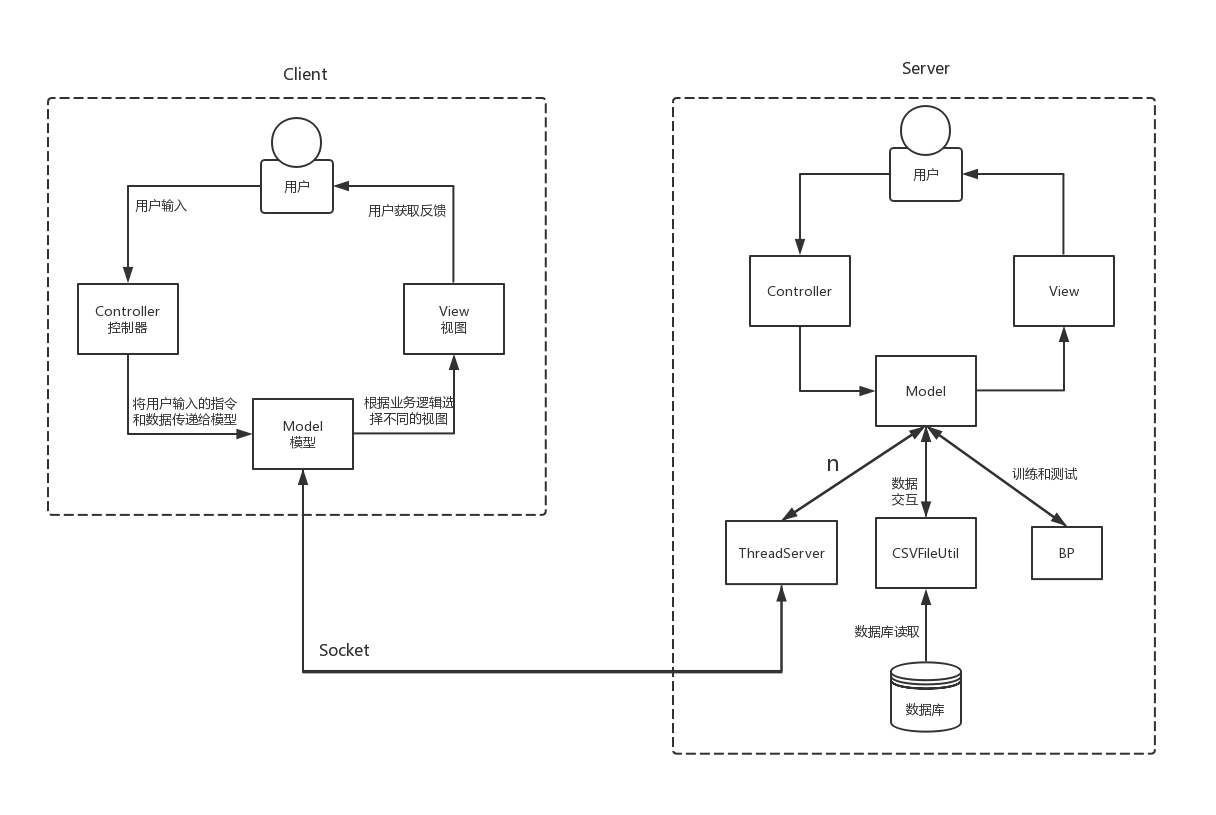
二、系统架构
由于BP神经网络训练过程时间较长,所以采用客户端服务器(C/S)的形式,在服务器进行训练,在客户端直接进行识别,使用套接字进行通讯。
服务器:
客户端:
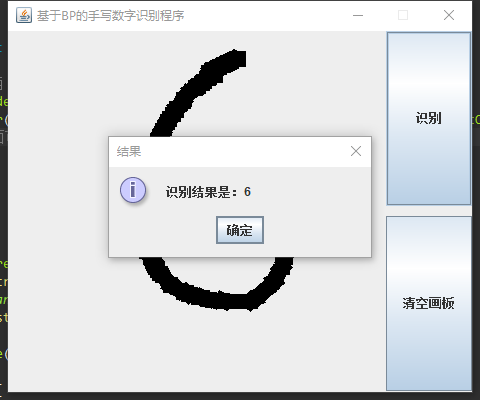
采用MVC架构:
Model(模型)表示应用程序核心。
View(视图)显示数据。
Controller(控制器)处理输入。
MNIST数字集经过整理存储在CSV文件中。
以下是系统架构:
三、源码
如果需要源码,请在下方评论区留下邮箱,我看到就会发过去
Java实现BP神经网络MNIST手写数字识别的更多相关文章
- BP神经网络的手写数字识别
BP神经网络的手写数字识别 ANN 人工神经网络算法在实践中往往给人难以琢磨的印象,有句老话叫“出来混总是要还的”,大概是由于具有很强的非线性模拟和处理能力,因此作为代价上帝让它“黑盒”化了.作为一种 ...
- 利用c++编写bp神经网络实现手写数字识别详解
利用c++编写bp神经网络实现手写数字识别 写在前面 从大一入学开始,本菜菜就一直想学习一下神经网络算法,但由于时间和资源所限,一直未展开比较透彻的学习.大二下人工智能课的修习,给了我一个学习的契机. ...
- 【机器学习】BP神经网络实现手写数字识别
最近用python写了一个实现手写数字识别的BP神经网络,BP的推导到处都是,但是一动手才知道,会理论推导跟实现它是两回事.关于BP神经网络的实现网上有一些代码,可惜或多或少都有各种问题,在下手写了一 ...
- BP神经网络(手写数字识别)
1实验环境 实验环境:CPU i7-3770@3.40GHz,内存8G,windows10 64位操作系统 实现语言:python 实验数据:Mnist数据集 程序使用的数据库是mnist手写数字数据 ...
- TensorFlow.NET机器学习入门【5】采用神经网络实现手写数字识别(MNIST)
从这篇文章开始,终于要干点正儿八经的工作了,前面都是准备工作.这次我们要解决机器学习的经典问题,MNIST手写数字识别. 首先介绍一下数据集.请首先解压:TF_Net\Asset\mnist_png. ...
- Android+TensorFlow+CNN+MNIST 手写数字识别实现
Android+TensorFlow+CNN+MNIST 手写数字识别实现 SkySeraph 2018 Email:skyseraph00#163.com 更多精彩请直接访问SkySeraph个人站 ...
- 基于tensorflow的MNIST手写数字识别(二)--入门篇
http://www.jianshu.com/p/4195577585e6 基于tensorflow的MNIST手写字识别(一)--白话卷积神经网络模型 基于tensorflow的MNIST手写数字识 ...
- 第三节,CNN案例-mnist手写数字识别
卷积:神经网络不再是对每个像素做处理,而是对一小块区域的处理,这种做法加强了图像信息的连续性,使得神经网络看到的是一个图像,而非一个点,同时也加深了神经网络对图像的理解,卷积神经网络有一个批量过滤器, ...
- keras—多层感知器MLP—MNIST手写数字识别
一.手写数字识别 现在就来说说如何使用神经网络实现手写数字识别. 在这里我使用mind manager工具绘制了要实现手写数字识别需要的模块以及模块的功能: 其中隐含层节点数量(即神经细胞数量)计算 ...
- 持久化的基于L2正则化和平均滑动模型的MNIST手写数字识别模型
持久化的基于L2正则化和平均滑动模型的MNIST手写数字识别模型 觉得有用的话,欢迎一起讨论相互学习~Follow Me 参考文献Tensorflow实战Google深度学习框架 实验平台: Tens ...
随机推荐
- 空链接的作用以及<a href="#"></a>和<a href="javascript:;"></a>的区别
空链接的作用以及<a href="#"></a>和<a href="javascript:;"></a>的区别在 ...
- 一、什么是celery
一.什么是Celery 1.1.celery是什么 celery是一个简单.灵活且可靠的,处理大量消息的分布式系统,专注于是心爱处理的异步任务队列,同事也支持任务调度. Celery的架构由三部分组成 ...
- 脚本之一键部署nexus
NEXUS_URL="https://download.sonatype.com/nexus/3/nexus-3.39.0-01-unix.tar.gz" #NEXUS_URL=& ...
- numpy常用知识点备忘
常用函数 a.max(axis=0) a.max(axis=1) a.argmax(axis=1) : 每列的最大值(在行方向找最大值).每行的最大值(在列方向找对大致).最大值的坐标 sum()求和 ...
- CodeTON Round 3 (C.差分维护,D.容斥原理)
C. Complementary XOR 题目大意: 给你两个01串ab,问你是否可以通过一下两种操作在不超过n+5次的前提下将两个串都变为0,同时需要输出可以的操作方案 选择一个区间[l,r] 将串 ...
- java反序列化_link_six
cc_link_six 0x01前言 经过cc链一的学习,然后jdk的版本一更新那两条链子就不能用了,然后这种反序列化的话就很不不止依赖于cc包的引入还有jdk版本,于是就出现了cc_link_six ...
- chronyd为隔离网络设置时间同步
参考链接:https://access.redhat.com/documentation/en-us/red_hat_enterprise_linux/8/html/configuring_basic ...
- Devexpress控件pivotGridControl显示字段面板
可在窗口加载的时候使用函数 pivotGridControl1.ShowCustomization(); 大家如果有问题可以 Console.WriteLine("加群"+&quo ...
- MySQL进阶实战4,MySQL索引详解,下篇
一.索引 索引是存储引擎用于快速查找记录的一种数据结构.我觉得数据库中最重要的知识点,就是索引. 存储引擎以不同的方式使用B-Tree索引,性能也各有不同,各有优劣.例如MyISAM使用前缀压缩技术使 ...
- TransmittableThreadLocal和@Async优雅的记录操作日志
此文主要讲解: 如何实现操作记录 如何将TransmittableThreadLocal和@Async搭配使用 TransmittableThreadLocal阿里的一个开源组件,为了在使用线程池等会 ...