Hive详解(01) - 概念
Hive详解(01) - 概念
hive简介
Hive:由Facebook开源用于解决海量结构化日志的数据统计工具,是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张表,并提供类SQL查询功能。
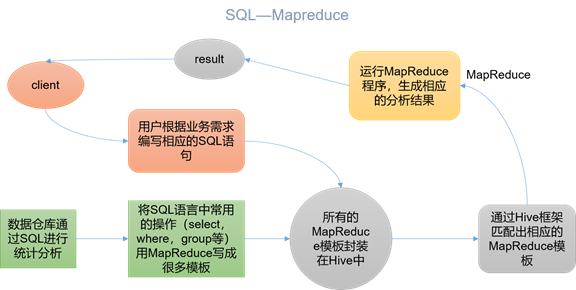
Hive本质:将HQL转化成MapReduce程序
(1)Hive处理的数据存储在HDFS
(2)Hive分析数据底层的实现是MapReduce
(3)执行程序运行在Yarn上
Hive的优缺点
- 优点
(1)操作接口采用类SQL语法,提供快速开发的能力(简单、容易上手)。
(2)避免了去写MapReduce,减少开发人员的学习成本。
(3)Hive的执行延迟比较高,因此Hive常用于数据分析,对实时性要求不高的场合。
(4)Hive优势在于处理大数据,对于处理小数据没有优势,因为Hive的执行延迟比较高。
(5)Hive支持用户自定义函数,用户可以根据自己的需求来实现自己的函数。
- 缺点
Hive的HQL表达能力有限
(1)迭代式算法无法表达
(2)数据挖掘方面不擅长,由于MapReduce数据处理流程的限制,效率更高的算法却无法实现。
Hive的效率比较低
(1)Hive自动生成的MapReduce作业,通常情况下不够智能化
(2)Hive调优比较困难,粒度较粗
Hive架构原理
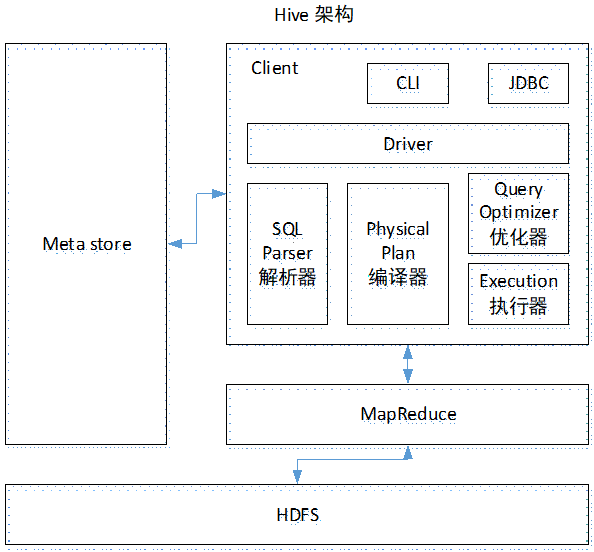
- 用户接口:Client
CLI(command-line interface)、JDBC/ODBC(jdbc访问hive)、WEBUI(浏览器访问hive)
- 元数据:Metastore
元数据包括:表名、表所属的数据库(默认是default)、表的拥有者、列/分区字段、表的类型(是否是外部表)、表的数据所在目录等;
默认存储在自带的derby数据库中,推荐使用MySQL存储Metastore
- Hadoop
使用HDFS进行存储,使用MapReduce进行计算。
- 驱动器:Driver
(1)解析器(SQL Parser):将SQL字符串转换成抽象语法树AST,这一步一般都用第三方工具库完成,比如antlr;对AST进行语法分析,比如表是否存在、字段是否存在、SQL语义是否有误。
(2)编译器(Physical Plan):将AST编译生成逻辑执行计划。
(3)优化器(Query Optimizer):对逻辑执行计划进行优化。
(4)执行器(Execution):把逻辑执行计划转换成可以运行的物理计划。对于Hive来说,就是MR/Spark。
Hive通过给用户提供的一系列交互接口,接收到用户的指令(SQL),使用自己的Driver,结合元数据(MetaStore),将这些指令翻译成MapReduce,提交到Hadoop中执行,最后,将执行返回的结果输出到用户交互接口。
Hive和 数据库比较
由于 Hive 采用了类似SQL 的查询语言 HQL(Hive Query Language),因此很容易将 Hive 理解为数据库。其实从结构上来看,Hive 和数据库除了拥有类似的查询语言,再无类似之处。下面将从多个方面来阐述 Hive 和数据库的差异。数据库可以用在 Online 的应用中,但是Hive 是为数据仓库而设计的,清楚这一点,有助于从应用角度理解 Hive 的特性。
- 查询语言
由于SQL被广泛的应用在数据仓库中,因此,专门针对Hive的特性设计了类SQL的查询语言HQL。熟悉SQL开发的开发者可以很方便的使用Hive进行开发。
- 数据更新
由于Hive是针对数据仓库应用设计的,而数据仓库的内容是读多写少的。因此,Hive中不建议对数据的改写,所有的数据都是在加载的时候确定好的。
而数据库中的数据通常是需要经常进行修改的,因此可以使用 INSERT INTO … VALUES 添加数据,使用 UPDATE … SET修改数据。
- 执行延迟
Hive 在查询数据的时候,由于没有索引,需要扫描整个表,因此延迟较高。另外一个导致 Hive 执行延迟高的因素是 MapReduce框架。由于MapReduce 本身具有较高的延迟,因此在利用MapReduce 执行Hive查询时,也会有较高的延迟。相对的,数据库的执行延迟较低。当然,这个低是有条件的,即数据规模较小,当数据规模大到超过数据库的处理能力的时候,Hive的并行计算显然能体现出优势。
- 数据规模
由于Hive建立在集群上并可以利用MapReduce进行并行计算,因此可以支持很大规模的数据;对应的,数据库可以支持的数据规模较小。
Hive详解(01) - 概念的更多相关文章
- DBA_Oracle Startup / Shutdown启动和关闭过程详解(概念)
2014-08-07 Created By BaoXinjian
- TCP/IP详解系列 --- 概念总结01
UDP协议 .vs. TCP协议: 原理上:(TCP报文段. vs . UDP用户数据报) TCP协议的特性: TCP是面向连接的运输层协议,应用程序在使用TCP协议之前,必须先建立TCP连接. ...
- 大数据入门第十一天——hive详解(一)入门与安装
一.基本概念 1.什么是hive The Apache Hive ™ data warehouse software facilitates reading, writing, and managin ...
- Hive详解
1. Hive基本概念 1.1 Hive简介 1.1.1 什么是Hive Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供类SQL查询功能. 1.1 ...
- 大数据入门第十一天——hive详解(三)hive函数
一.hive函数 1.内置运算符与内置函数 函数分类: 查看函数信息: DESC FUNCTION concat; 常用的分析函数之rank() row_number(),参考:https://www ...
- 大数据入门第十一天——hive详解(二)基本操作与分区分桶
一.基本操作 1.DDL 官网的DDL语法教程:点击查看 建表语句 CREATE [EXTERNAL] TABLE [IF NOT EXISTS] table_name [(col_name data ...
- TCP/IP详解系列 --- 概念总结02
TCP复位报文段(RST)的用途: 1.当客户端程序访问不存在的端口时,目标主机将给它发送一个复位报文段:收到复位报文段的一端应该关闭连接或者重新连接,而不能回应这个复位报文段. 2.当客户端程序向服 ...
- 一起学Hive——详解四种导入数据的方式
在使用Hive的过程中,导入数据是必不可少的步骤,不同的数据导入方式效率也不一样,本文总结Hive四种不同的数据导入方式: 从本地文件系统导入数据 从HDFS中导入数据 从其他的Hive表中导入数据 ...
- Hadoop之Hive详解
1.什么是Hive hive是基于hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表 并提供类sql查询功能 2.为什么要用Hive 1.直接使用hadoop所面临的问题 人员学 ...
- IO模型(epoll)--详解-01
写在前面 从事服务端开发,少不了要接触网络编程.epoll作为linux下高性能网络服务器的必备技术至关重要,nginx.redis.skynet和大部分游戏服务器都使用到这一多路复用技术. 本文会从 ...
随机推荐
- Oracle导出和导入
导出 exp exp 用户名/密码@实例名 file=导出的dmp文件存放路径 l og=导出日志存放路径 exp hr/123456@orcl file= C:\Users\Administrato ...
- 怎么在线预览.doc,.docx,.ofd,.pdf,.wps,.cad文件以及Office文档的在线解析方式。
前言 Office文件在线预览是目前移动化办公的一种新趋势.Office在线预览指的是Office系列的文件在线查看而不依附域客户端的存在.在浏览器或者浏览器控件中可以预览查看Word.PDF.Exc ...
- VS Code For Web 深入浅出 -- 进程间通信篇
在上一篇中,我们一起分析了 VS Code 整体的代码架构,了解了 VS Code 是由前后端分离的方式开发的.且无论前端是基于 electron 还是 web,后端是本地还是云端,其调用方式并无不同 ...
- Codeforces 1684 E. MEX vs DIFF
题意 给你n个非负整数的数列a,你可以进行K次操作,每次操作可以将任意位置的数数更改成任意一个非负整数,求操作以后,DIFF(a)-MEX(a)的最小值:DIFF代表数组中数的种类.MEX代表数组中未 ...
- C# Linq 查询汇总
分组取值.求和.计数 1 var resultlist = orderllist.GroupBy(oo => new { oo.Deptname, oo.Userid, oo.Username ...
- Docker在windows系统以及Linux系统的安装
Docker简介和安装 Docker是什么 Docker 是一个应用打包.分发.部署的工具 你也可以把它理解为一个轻量的虚拟机,它只虚拟你软件需要的运行环境,多余的一点都不要, 而普通虚拟机则是一个完 ...
- JAVA系列之JVM内存调优
一.前提 JVM性能调优牵扯到各方面的取舍与平衡,往往是牵一发而动全身,需要全盘考虑各方面的影响.在优化时候,切勿凭感觉或经验主义进行调整,而是需要通过系统运行的客观数据指标,不断找到最优解.同时,在 ...
- 浅谈消息队列 Message Queue
消息队列:在消息传递的过程中暂时保存消息的容器,充当发送者和接受者的中间人 消息队列的基本操作 using System; using System.Messaging; namespace MQ { ...
- shell实践
shell实践 父子shell 父shell:我们在登录某个虚拟机控制器终端的时候(连接某一个linux虚拟机)时,默认启动的交互式shell,然后等待命令输入. ps命令参数,是否有横杠的参数作用是 ...
- Oracle用户创建及删除
偶尔会用到,记录.分享. 1. Oracle用户创建 #创建用户表空间create tablespace $username datafile '/u01/app/oracle/oradata/ufg ...