论文笔记 - Fantastically Ordered Prompts and Where to Find Them: Overcoming Few-Shot Prompt Order Sensitivity

prompt 的影响因素
Motivation
- Prompt 中 Example 的排列顺序对模型性能有较大影响(即使已经校准参见好的情况下,选取不同的排列顺序依然会有很大的方差):
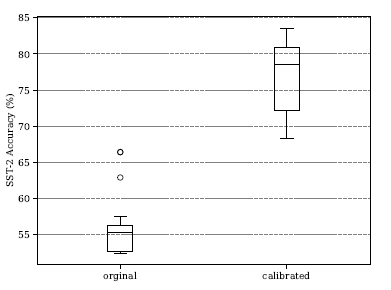
- 校准可以大幅度提高准确率,但是不同的排列顺序方差依然很大
Analysis
- 提出探测集(probing set),流程如下:
- 训练集 $S={(x_i, y_i)}$,模板转换函数(将一组数据转换为自然语言) $t_i=\tau (x_i,y_i)=input:x_i,type:y_y$,因此自然语言数据集 $S'=\{t_i\}$;
- 排列方程集合 $\mathfrak{F}=\{f_m\},m=1\rightarrow n!$,$f_m(S')=c_m$ 为一种训练数据的组合顺序($m=1\rightarrow n!$);
- 对于每一种排列组合$c_m$,使用语言模型进行去预测后续的句子(注意这里没有加上测试集的问题,纯粹对训练集进行组合),得到模型生成的新的 example:$g_m\propto P(...|c_m;\theta)$,$\theta$为语言模型的参数,对生成序列解析得到模型生成的数据集:$D=\{\tau ^{-1}(g_m)\},m=1\rightarrow n!$。
- 针对探测集提出两种评估 prompt 的指标:
Global Entropy
- 对探测集合中探测数据$(x'_i, y'_i)\in D$(生成的 label 不需要,不具有参考意义),选择一种排列组合(上下文)$c_m$进行推理得到$\hat{y_{i,m}}$,即:
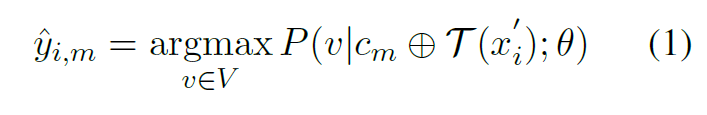
- 对探测集中的每个探测数据进行预测,求得每个预测的种类占探测集的比例:
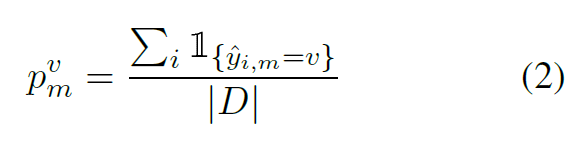
- 最后求熵(熵反应了预测各个种类的均匀程度,预测的正确与否并不重要,假如熵非常小,说明预测的结果 bias 非常大):
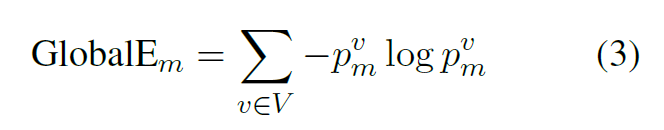
Local Entropy
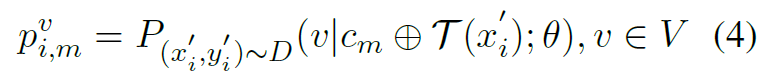
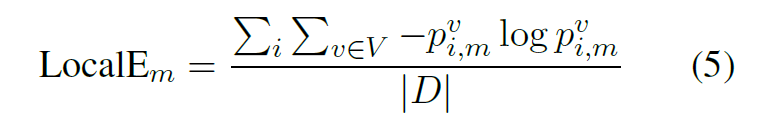
- 与全局熵类似,只不过先求熵再求和。
为什么上面的方法有用呢?
- 个人猜想:你能得到的训练集是非常有限的,假设改变 example 的排列顺序会使 output distribution 发生改变。假如你只有 4 个 example,那么你最多能模拟出来 24 种不同的 distribution(很多模拟不出来但是没有办法,受数据制约),也就是说你得到的包含 24 个数据的探测集其实就是尽最大能力准备出来的多样数据集。如果在这些探测数据上,某个排序$c_m$预测的结果集合很均匀(各种类别数量差不多),那么说明这种排序 rebust 比较强(这种排序没有倾向性,导致生成的问题都是中性的,生成什么label的可能性都一样)。
论文笔记 - Fantastically Ordered Prompts and Where to Find Them: Overcoming Few-Shot Prompt Order Sensitivity的更多相关文章
- Deep Learning论文笔记之(四)CNN卷积神经网络推导和实现(转)
Deep Learning论文笔记之(四)CNN卷积神经网络推导和实现 zouxy09@qq.com http://blog.csdn.net/zouxy09 自己平时看了一些论文, ...
- 论文笔记之:Visual Tracking with Fully Convolutional Networks
论文笔记之:Visual Tracking with Fully Convolutional Networks ICCV 2015 CUHK 本文利用 FCN 来做跟踪问题,但开篇就提到并非将其看做 ...
- Deep Learning论文笔记之(八)Deep Learning最新综述
Deep Learning论文笔记之(八)Deep Learning最新综述 zouxy09@qq.com http://blog.csdn.net/zouxy09 自己平时看了一些论文,但老感觉看完 ...
- Twitter 新一代流处理利器——Heron 论文笔记之Heron架构
Twitter 新一代流处理利器--Heron 论文笔记之Heron架构 标签(空格分隔): Streaming-process realtime-process Heron Architecture ...
- Deep Learning论文笔记之(六)Multi-Stage多级架构分析
Deep Learning论文笔记之(六)Multi-Stage多级架构分析 zouxy09@qq.com http://blog.csdn.net/zouxy09 自己平时看了一些 ...
- Multimodal —— 看图说话(Image Caption)任务的论文笔记(一)评价指标和NIC模型
看图说话(Image Caption)任务是结合CV和NLP两个领域的一种比较综合的任务,Image Caption模型的输入是一幅图像,输出是对该幅图像进行描述的一段文字.这项任务要求模型可以识别图 ...
- 论文笔记(1):Deep Learning.
论文笔记1:Deep Learning 2015年,深度学习三位大牛(Yann LeCun,Yoshua Bengio & Geoffrey Hinton),合作在Nature ...
- 论文笔记(2):A fast learning algorithm for deep belief nets.
论文笔记(2):A fast learning algorithm for deep belief nets. 这几天继续学习一篇论文,Hinton的A Fast Learning Algorithm ...
- 论文笔记:Towards Diverse and Natural Image Descriptions via a Conditional GAN
论文笔记:Towards Diverse and Natural Image Descriptions via a Conditional GAN ICCV 2017 Paper: http://op ...
随机推荐
- P5384[Cnoi2019]雪松果树 (长链剖分)
题面 一棵以 1 1 1 为根的 N N N 个节点的有根树, Q Q Q 次询问,每次问一个点 u u u 的 k k k 级兄弟有多少个(第 k k k 代祖先的第 k k k 代孩子),如果没有 ...
- vivo 基于 JaCoCo 的测试覆盖率设计与实践
作者:vivo 互联网服务器团队- Xu Shen 本文主要介绍vivo内部研发平台使用JaCoCo实现测试覆盖率的实践,包括JaCoCo原理介绍以及在实践过程中遇到的新增代码覆盖率统计问题和频繁发布 ...
- python进阶__struct数据处理详解
一.此模块可以执行 Python 值和以 Python bytes 对象表示的 C 结构之间的转换 二.打包解包时,需要按照特定的方式来打包或者解包.该方式就是格式化字符串,它指定了数据类型,除此之外 ...
- Java中数组
数组的定义格式: 1: 数据类型[] 数组名 2: 数据类型 数组名 动态初始化: 初始化的时候 系统会默认给数组赋值 数据类型[] 变量名 = new 数据类型[数组长度] int[] arr = ...
- openstack中Nova组件简解
一.Nova组件概述 计算节点通过Nova Computer进行虚拟机创建,通过libvirt调用kvm创建虚拟机,nova之间通信通过rabbitMQ队列进行通信. Nova位于Openstack架 ...
- 富莱尔ERP
微型版本 按年付费模式 980包含5个用户,后续每增加一个用户加298元. 适合创业型企业,想尝试用下ERP软件解决打送货单问题,客户自动生成账单,自动统计业务员每月业绩功能. 试用账号:wxadmi ...
- KingbaseES 转义字符
在SQL标准中字符串是用单引号括起来的,在KingbaseES中遵守了该标准,如果在字符串中需要使用到单引号,就需要对其进行转义. 方式一:使用E和反斜杠进行转义 方式二:直接用一个单引号来转义 在K ...
- K8S_三种Port区别总结
nodePort: 外部流量访问K8S集群中Service入口的一种方式 比如外部用户要访问k8s集群中的一个Web应用,那么我们可以配置对应service的type=NodePort,nodePor ...
- ORM增删改查并发性能测试
这两天在对一些ORM进行性能测试(涉及SqlSugar.FreeSql.Fast.Framework.Dapper.LiteSql),测试用的是Winform程序,别人第一眼看到我的程序,说,你这测试 ...
- 云原生之旅 - 2)Docker 容器化你的应用
前言 上文中我们用Golang写了一个HTTP server,本篇文章我们讲述如何容器化这个应用,为后续部署到kubernetes 做准备. 关键词:Docker, Containerization, ...