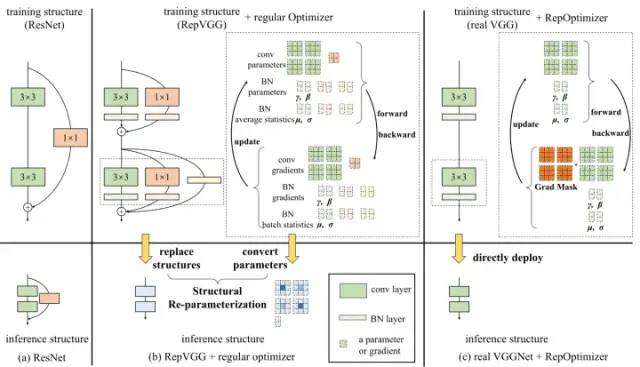
yolov6在结构中大量使用了重参数结构,导致数据分布过差,PTQ精度急剧下降。另外,重参数化结构网络无法直接使用QAT进行微调提升量化性能。
因为Deploy部署的模型无BN,不利于训练;Train模式进行QAT之后无法进行分支融合。
1、Train模式训练中真的无法量化吗?能否量化后跟踪参数,从而进行融合?看起来不太现实。
2、Deploy部署的模型无BN,仅仅是不利于训练,还是能训练,能否从这里进行改善。看起来可行。
3、从后量化着手,不断降低这个损失度了。这个方向看起来比较实际一点。

添加图片注释,不超过 140 字(可选)
思路一:RepVGG推理的时候由于速度的要求采用单路网络,训练的时候能否将推理模型的单路网络训练的效果拔高呢?(Deploy部署的模型无BN,仅仅是不利于训练,还是能训练,能否从这里进行改善。看起来可行。)
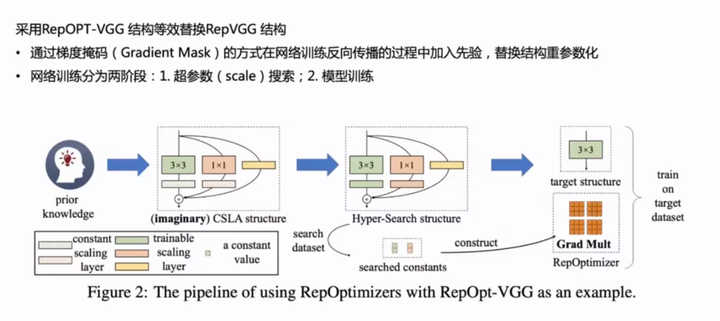
YOLOv6用了RepOpt-VGG 网络,这个工作与 RepVGG 相当于是两个不同的改进方向,一个是单网络变多分支来提高训练效果,另一个则是还是单网络通过训练手段提高训练效果。即:
RepVGG + 常规的优化器=VGG + RepOptimizer。
1) RepVGG加入了结构先验(如1x1,identity分支),并使用常规优化器训练。而RepOptVGG则是将这种先验知识加入到优化器实现中。
2) RepVGG 虽然在推理时拥有极简的 VGG 类型架构,但是训练时却是一个较为复杂的模型,并且需要更多的时间和内存来训练。相比之下,RepOpt-VGG 在训练时也是一个极简的 VGG 类型架构。
3) RepOpt 扩展和深化了结构重参数化技术,即使训练时候的模型也是一个极简的 VGG 类型架构,依然能够通过定制的优化器实现等效的训练动态。这就意味着:当输入和其他训练的设置相同时,RepVGG 和 RepOpt 在训练过程中的任何迭代中产生理论上相同的输出。
添加图片注释,不超过 140 字(可选)
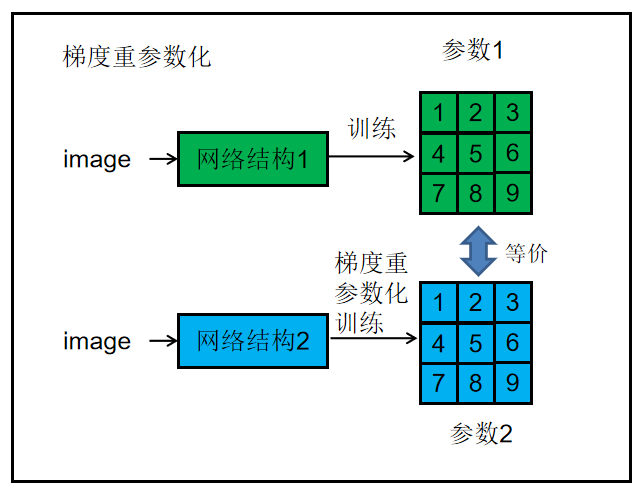
RepVGG是实际搭建出多分支网络,而RepOpt-VGG则是假想多分支网络。
实际搭建出多分支网络训练后自然得出对应的参数,而假想(imaginary)多分支网络则是通过参数转化得出前置的参数。
RepOPT结果改善了数据分布,有效提升了PTQ量化精度。

添加图片注释,不超过 140 字(可选)
定义:通过根据一组特定于模型的超参数修改梯度来添加先验知识,称为梯度重新参数化,优化器称为重新优化器。
RepOptimizer是一种针对 SGD 型优化器的方法:SGD 的核心是用梯度更新参数,在更新可训练参数之前,通过一组特定于模型的超参数 "修改" 梯度,使得优化器成为 model-specific 的。为了获得这样的超参数,提出了一种叫做超参数搜索的方法。
VGG 风格的架构,只使用 3×3 卷积这一种操作,经过梯度重参数化的 RepOptimizer 训练之后,得到的 RepOpt-VGG 模型的精度可以与 RegNet 和 EfficientNet 这种有更丰富的结构先验模型的精度相媲美。
添加图片注释,不超过 140 字(可选)
添加图片注释,不超过 140 字(可选)
RepOpt唯一计算开销是梯度与预先计算的乘数 Grad Mult的逐元素乘法。
推理时间 RepVGG 难以通过训练后量化(PTQ)来量化。RepOpt- VGG 对量化是友好的,并从训练模型的结构转换揭示量化 RepVGG 结果的问题。因为 RepOpt-VGG 根本没有进行结构转换。
步骤1:定义先验知识并想象一个复杂的结构来反映知识。
步骤2:用更简单的目标结构实现等效的训练动态,该目标结构的梯度根据一些超参数而被修改,通过超搜索获得超参数。
步骤3:建立再优化器,使用 RepOpt 进行训练。
添加图片注释,不超过 140 字(可选)
CSLA:在特殊情况下,每个分支包含一个线性可训练参数,加一个常量缩放值,只要该缩放值设置合理,则模型性能依旧会很高。我们将这个线性块称为恒定比例线性加法Constant-Scale Linear Addition(CSLA)。
可以用单个算子代替 CSLA 块,并通过将梯度乘以一些常数实现等效的训练动态,即在给定相同训练数据的情况下,在任意数量的训练迭代之后,它们总是产生相同的输出。
这种乘数称为 Grad Mult,用Grad Mult 修改梯度可以看作是 优化器重参数化(GR)的具体实现。
CSLA 块+常规优化器=单个运算符+带 GR的优化器。
考虑一个输入,经过2个卷积分支+线性缩放,并加到一个输出中。
设 αA,αB 是两个常数标量,W(A),W(B)是相同尺寸的卷积核,X 和 Y 是输入和输出,*表示卷积,CSLA 块的计算流程:
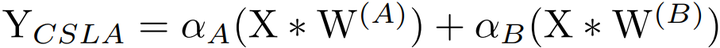
添加图片注释,不超过 140 字(可选)
对应 GR ,直接训练用 W’参数化的目标结构,使得
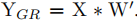
添加图片注释,不超过 140 字(可选)
添加图片注释,不超过 140 字(可选)
添加图片注释,不超过 140 字(可选)
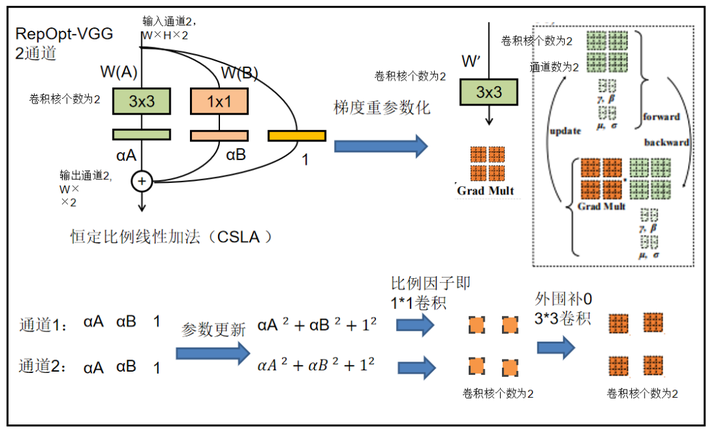
单路网络训练想要得到对应的CSLA参数,只需要根据CSLA的卷积核进行参数初始化,然后在更新参数的时候乘一个比例系数即可。
添加图片注释,不超过 140 字(可选)
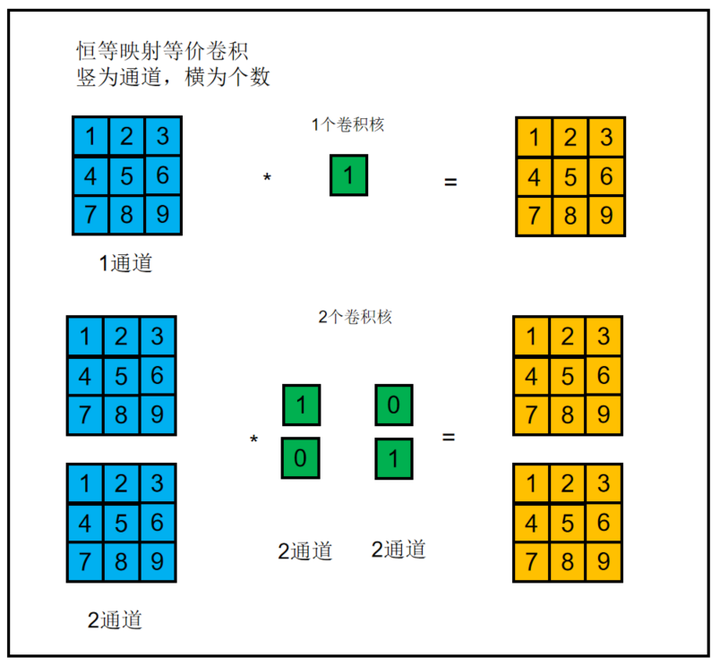
对应的CSLA块则是将RepVGG块中的3x3卷积,1x1卷积,bn层替换为带可学习缩放参数的3x3卷积,1x1卷积。此外一个恒等映射也可以单做一个单位1的1*1卷积,而1*1卷积可以补0扩张为3*3卷积。
进一步拓展到多分支中,假设s,t分别是3x3卷积,1x1卷积的缩放系数,那么对应的更新规则,即比例系数为:
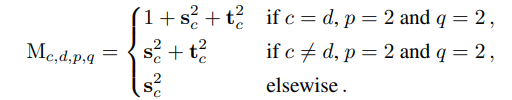
添加图片注释,不超过 140 字(可选)
第一条公式,此时一共有3个分支,分别是identity,conv3x3, conv1x1。
第二条公式,此时只有conv3x3, conv1x1两个分支。
添加图片注释,不超过 140 字(可选)
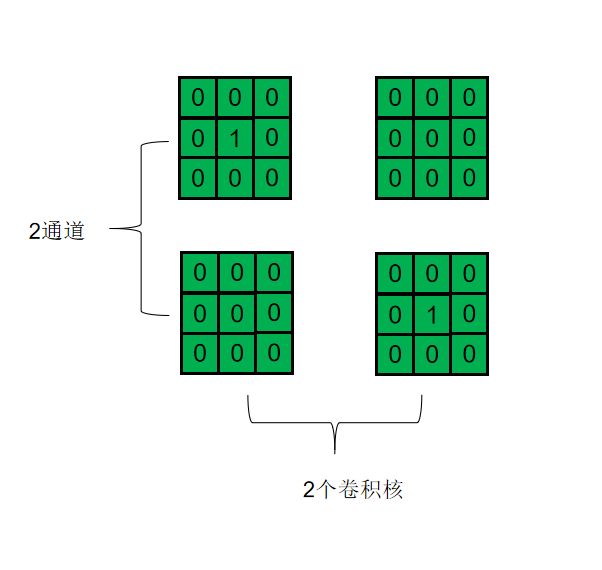
由于可训练的信道方向缩放可以被视为“深度1×1 conv”,然后是常数缩放因子1,因此在“对角线”位置向Grad Mult添加1。(缩放比例即1*1卷积)
对于恒等映射,缩放因子就是1,对应的Grad Mult就是(输入2通道,输出2通道,1*1卷积周围补0):
添加图片注释,不超过 140 字(可选)
添加图片注释,不超过 140 字(可选)
需要注意的是CSLA没有BN这种训练期间非线性算子(training-time nonlinearity),也没有非顺序性(non sequential)可训练参数,CSLA在这里只是一个描述RepOptimizer的间接工具。
添加图片注释,不超过 140 字(可选)
在一个小数据集(如CIFAR100)上进行训练,在小数据上训练完毕后,将这些可训练参数固定为常数。
将优化器的超参数与辅助模型和搜索的可训练参数相关联,因此称为超搜索(HS)。具体地,给定一个再优化器,通过用可训练的尺度替换再优化器的相应 CSLA 模型中的常数来构建辅助超搜索模型。可训练参数的最终值是模型期望它们变成的值,因此可训练标度的最终值被视为假想 CSLA 模型中的期望常数值。由于 CSLA = GR,CSLA 模型中的预期常数正是我们构建再优化器的预期梯度乘法所需的常数。
在超搜索之后,使用搜索到的常数标度为每个算子(在 RepOpt-VGG 的情况下,每个3×3 conv 层)构建报告优化器的梯度乘子,包括 4 个阶段的 3×3 conv 层数和通道数,以及理论推断-时间 FLOPs 和参数数。
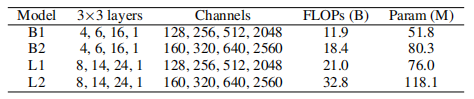
添加图片注释,不超过 140 字(可选)
重新优化器是特定于模型的,但与数据集无关,在 CIFAR-100 上搜索的超参数可转移到 ImageNet。
在 ImageNet 上搜索并不意味着在ImageNet 上对同一个模型进行两次训练,因为第二次训练仅将 HS 模型的训练比例继承到重新优化器中,而不会继承其他训练参数。
在目标数据集上搜索的再优化器的超参数并不比在不同数据集上获得的结果更好。
对于不同的超参数源,再优化器在目标数据集上提供相似的结果,这表明再优化器是数据集不可知的。
(答:梯度重参数化这个方法只适用于线性变换,但是BN这个操作本身不是线性的,而直接去掉又不好训练。所以会在一个小数据集带上bn训练,得到一个合适的线性缩放值(就当作是起到BN的作用),然后将这个线性缩放值作为可学习参数的初始化值,来进行完整训练。)
因为bn不是一个linear scale操作,不能直接参与repoptimizer使用。 所以是先按照常规的训练方式在小数据集找到一个合适的scale,在repoptimizer里,这个scale固定住,充当bn的功能。
RepOpt-VGG是多个卷积融合但是解决了训练过程中BN层融合的问题。
目标数据集上的目标模型的初始化独立于 HS 模型中的 conv 核的初始值。
换句话说,从 HS 模型继承的唯一知识是经过训练的量表,我们不需要记录 HS 模型的任何其他初始信息。
添加图片注释,不超过 140 字(可选)
RepOpt-VGG将模型的先验知识转移到优化器中。但该方法是经验验证的。
另一个主要限制是,这个实现依赖于运算的线性,因为要将单个算子的训练动态等效为一个复杂的块。
重新优化器是特定于模型的,但与数据集无关,在其他数据集上得出超参数,可以用到目标数据集上。
RepOpt-VGG将参数乘一个比例因子,本质上超参数(比例因子)在替代BN的作用。
公众号《AI大道理》征稿函mp.weixin.qq.com/s?__biz=MzU5NTg2MzIxMw==&mid=2247489802&idx=1&sn=228c18ad3a11e731e8f325821c184a82&chksm=fe6a2ac8c91da3dec311bcde280ad7ee760c0c3e08795604e0f221ff23c89c43a86c6355390f&scene=21#wechat_redirect
留言吧mp.weixin.qq.com/cgi-bin/appmsg?t=media/appmsg_edit&action=edit&type=77&appmsgid=100008532&isMul=1&replaceScene=0&isSend=0&isFreePublish=0&token=655411939&lang=zh_CN
- #Deep Learning回顾#之LeNet、AlexNet、GoogLeNet、VGG、ResNet
CNN的发展史 上一篇回顾讲的是2006年Hinton他们的Science Paper,当时提到,2006年虽然Deep Learning的概念被提出来了,但是学术界的大家还是表示不服.当时有流传的段 ...
- 【深度学习系列】用PaddlePaddle和Tensorflow实现经典CNN网络Vgg
上周我们讲了经典CNN网络AlexNet对图像分类的效果,2014年,在AlexNet出来的两年后,牛津大学提出了Vgg网络,并在ILSVRC 2014中的classification项目的比赛中取得 ...
- 经典卷积神经网络(LeNet、AlexNet、VGG、GoogleNet、ResNet)的实现(MXNet版本)
卷积神经网络(Convolutional Neural Network, CNN)是一种前馈神经网络,它的人工神经元可以响应一部分覆盖范围内的周围单元,对于大型图像处理有出色表现. 其中 文章 详解卷 ...
- Spark MLib:梯度下降算法实现
声明:本文参考< 大数据:Spark mlib(三) GradientDescent梯度下降算法之Spark实现> 1. 什么是梯度下降? 梯度下降法(英语:Gradient descen ...
- [机器学习]梯度提升决策树--GBDT
概述 GBDT(Gradient Boosting Decision Tree) 又叫 MART(Multiple Additive Regression Tree),是一种迭代的决策树算法,该算法由 ...
- Pytorch1.0入门实战二:LeNet、AleNet、VGG、GoogLeNet、ResNet模型详解
LeNet 1998年,LeCun提出了第一个真正的卷积神经网络,也是整个神经网络的开山之作,称为LeNet,现在主要指的是LeNet5或LeNet-5,如图1.1所示.它的主要特征是将卷积层和下采样 ...
- 深度学习原理与框架-卷积网络细节-图像分类与图像位置回归任务 1.模型加载 2.串接新的全连接层 3.使用SGD梯度对参数更新 4.模型结果测试 5.各个模型效果对比
对于图像的目标检测任务:通常分为目标的类别检测和目标的位置检测 目标的类别检测使用的指标:准确率, 预测的结果是类别值,即cat 目标的位置检测使用的指标:欧式距离,预测的结果是(x, y, w, h ...
- Distill详述「可微图像参数化」:神经网络可视化和风格迁移利器!
近日,期刊平台 Distill 发布了谷歌研究人员的一篇文章,介绍一个适用于神经网络可视化和风格迁移的强大工具:可微图像参数化.这篇文章从多个方面介绍了该工具. 图像分类神经网络拥有卓越的图像生成能力 ...
- CNN Architectures(AlexNet,VGG,GoogleNet,ResNet,DenseNet)
AlexNet (2012) The network had a very similar architecture as LeNet by Yann LeCun et al but was deep ...
- 跟我学算法-图像识别之图像分类(上)(基础神经网络, 卷积神经网络(CNN), AlexNet,NIN, VGG)
1.基础神经网络: 输入向量x,权重向量w, 偏置标量b, 激活函数sigmoid(增加非线性度) 优化手段: 梯度下降优化, BP向后传播(链式规则) 梯度下降优化: 1. 使用得目标函数是交叉熵 ...
随机推荐
- Spring Boot2中如何优雅地个性化定制Jackson
概述 本文的编写初衷,是想了解一下Spring Boot2中,具体是怎么序列化和反序列化JSR 310日期时间体系的,Spring MVC应用场景有如下两个: 使用@RequestBody来获取JSO ...
- python 排序的几种方式(内置排序函数, 选择排序, 冒泡排序)
#python 排序的方法 #Python 列表有一个内置的 list.sort() 方法可以直接修改列表 list1 = [1,3,5,10,2,1] list1.sort() print(list ...
- Bouncy Castle密码算法库
Bouncy Castle密码算法库 一.开发背景 Bouncy Castle 是一种用于 Java 平台的开放源码的轻量级密码术包.它支持大量的密码术算法,并提供 JCE 1.2.1 的实现.因为 ...
- No.1.9
项目样式补充 精灵图(场景:项目中将多张小图片,合并成一张大图片,这张大图片称之为精灵图) (优点:减少服务器发送次数,减轻服务器的压力,提高页面加载速度) 精灵图的使用步骤:1.创建一个盒子,设置盒 ...
- sql语句顺序/包含执行顺序和书写顺序
分页查询 如果一页记录为10条,希望查看第3页记录应该怎么查呢? 第一页记录起始行为0,一共查询10行: 第二页记录起始行为10,一共查询10行: 第三页记录起始行为20,一共查询10行: ...
- Mysql习题系列(一):基本select语句与运算符
Mysql8.0习题系列 软件下载地址 提取码:7v7u 数据下载地址 提取码:e6p9 文章目录 Mysql8.0习题系列 1. 基本select语句 1.1 题目 1.2答案 1.查询员工12个月 ...
- Python 20个常用库
Requests.Kenneth Reitz写的最富盛名的http库.每个Python程序员都应该有它. Scrapy.如果你从事爬虫相关的工作,那么这个库也是必不可少的.用过它之后你就不会再想用别的 ...
- ES-DSL
GET index_name/_search{ "track_total_hits":true} 可以查询总记录数,不加只能展示最多10000条
- js获取的 后端的列表。
1.引号被转码 处理办法 {% autoescape off %} var tmp = '{{ data1 }}'; var tmp = '{{ data2 }}'; {% endautoescape ...
- WPF ItemsControl Command 绑定操作
视图模型: using System.Collections.ObjectModel; using System.Diagnostics; using System.Windows.Input; us ...