强化学习-学习笔记12 | Dueling Network
这是价值学习高级技巧第三篇,前两篇主要是针对 TD 算法的改进,而Dueling Network 对 DQN 的结构进行改进,能够大幅度改进DQN的效果。
Dueling Network 的应用范围不限于 DQN,本文只介绍其在 DQN上的应用。
12. Dueling Network
12.1 优势函数
Advantage Function.
回顾一些基础概念:
折扣回报:
\(U_t = R_t + \gamma \cdot R_{t+1} + \gamma^2R+...\)
动作价值函数:
\(Q_\pi(s_t,a_t)=\mathbb{E}[U_t|S_t=s_t,A_t=a_t]\)
消去了未来的状态 和 动作,只依赖于当前动作和状态,以及策略函数 \(\pi\)。
状态价值函数:
\(V_\pi(s_t)=\mathbb{E}[Q_\pi(s_t,A)]\)
只跟策略函数 \(\pi\) 和当前状态 \(s_t\) 有关。
最优动作价值函数
\(Q^*(s,a)=\mathop{max}\limits_{\pi}Q_\pi(s,a)\)
只依赖于 s,a,不依赖策略函数。
最优状态价值函数
\(V^*(s)=\mathop{max}\limits_{a}V_\pi(S)\)
只依赖 S。
下面就是这次的主角之一:
Optimal Advantage function 优势函数:
\(A^*(s,a)=Q^*(s,a)-V^*(s)\)
V* 作为 baseline ,优势函数的意思是动作 a 相对 V* 的优势,A*越好,那么优势就越大。
下面介绍一个优势函数有关的定理:
定理一:\(V^*(s)=\mathop{max}\limits_a Q^*(s,a)\)
这一点从上面的回顾不难看出,求得最优的路径不同,但是相等。
上面提到了优势函数的定义:\(A^*(s,a)=Q^*(s,a)-V^*(s)\)
同时对左右求最大值:\(\mathop{max}\limits_{a}A^*(s,a)=\mathop{max} \limits_{a}Q^*(s,a)-V^*(s)\),而等式右侧正是上面定理,所以右侧==0;因此优势函数关于a的最大值=0,即:
\(\mathop{max}\limits_{a}A^*(s,a)=0\)
我们把这个 0 值式子加到定义上,进行简单变形:
定理二:\(Q^*(s,a)=V^*(s)+A^*(s,a)-\mathop{max}\limits_{a}A^*(s,a)\)
Dueling Network 就是由定理二得到的。
12.2 Dueling Network 原理
此前 DQN 用\(Q(s,a;w)\) 来近似 \(D^*(s,a)\) ,结构如下:
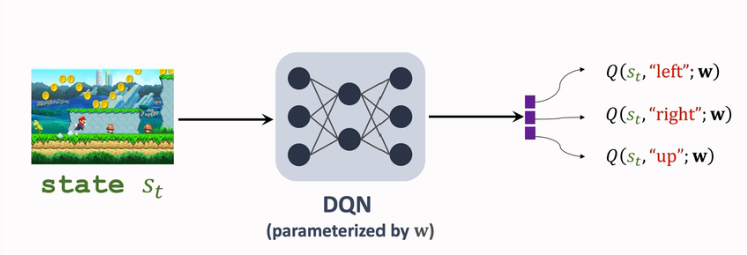
而 Dueling Network 对 DQN 的结构改进原理是:
我们对于DQN的改进思路就是基于上面的定理2:\(Q^*(s,a)=V^*(s)+A^*(s,a)-\mathop{max}\limits_{a}A^*(s,a)\)
- 分别用神经网络 V 和 A 近似 V-star 和 A-star
- 即:\(Q(s,a;w^A,w^V)=V(s;w^V)+A(s,a;w^A)-\mathop{max}\limits_{a}A(s,a;w^A)\)
- 这样也完成了对于 Q-star 的近似,与 DQN 的功能相同。
首先需要用一个神经网络 \(V(s;w^V)\) 来近似 \(V^*(s)\):
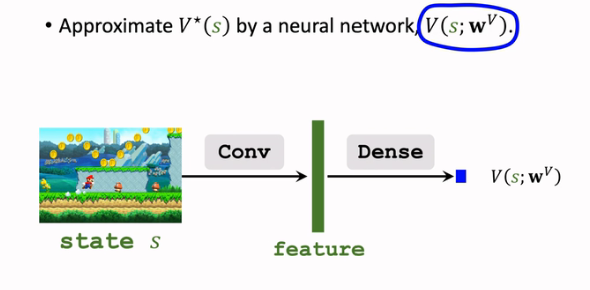
注意这里的输出是一个实数,是对状态的打分,而非向量;
- 用另一个神经网络\(A(s,a;w^A)\) 对\(A^*(s,a)\) 进行近似:
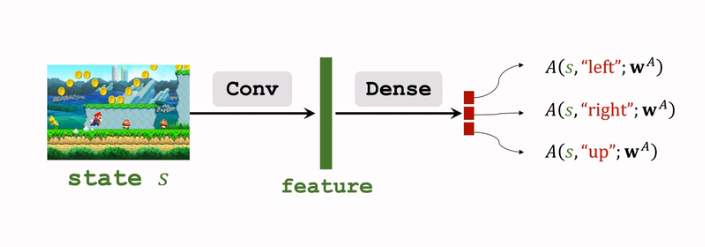
这个网络和上面的网络 \(V\) 结构有一定的相像,可以共享卷积层的参数;
后续为了方便,令 \(w=(w^A,w^V)\),即:
\]
现在 左侧 与 DQN 的表示就一致了。下面搭建Dueling Network,就是上面 V 和 A 的拼接与计算:
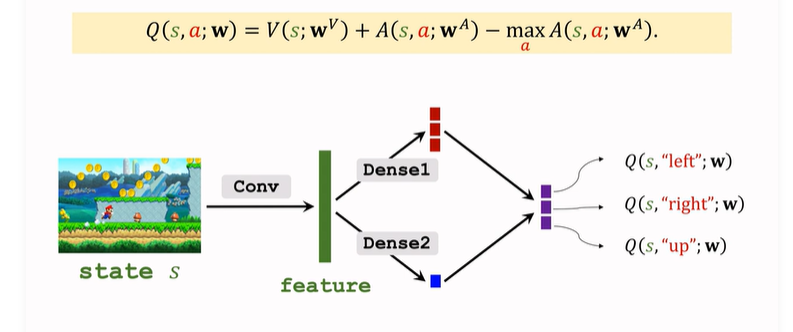
- 输入 状态 s,V 和 A 共享一些 卷积层,得到特征向量;
- 分别通过不同的全连接层,A输出向量,V输出实数;
- 通过上面的式子运算输出最终结果,是对所有动作的打分;
可见Dueling Network 的输入 和 输出 和 DQN 完全一样,功能也完全一样;但是内部的结构不同,Dueling Network 的结构更好,所以表现要比 DQN好;
注意,Dueling Network 和 DQN 都是对 最优动作价值函数 的近似。
12.3 训练 Dueling Network
接下来训练参数 \(w=(w^A,w^v)\),采用与 DQN 相同的思路,也就是采用 TD算法训练 Dueling Network。
之前介绍的 TD算法 的三种优化方法:
- 经验回放 / 优先经验回放
- Double DQN
- M-step TD target
都可以用在 训练 Dueling Network 上。
12.4 数学原理与不唯一性
之前推导 Dueling Network 原理的时候,有如下两个式子:
- \(Q^*(s,a)=V^*(s)+A^*(s,a)\)
- \(Q^*(s,a)=V^*(s)+A^*(s,a)-\mathop{max}\limits_{a}A^*(s,a)\)
我们为什么一定要用等式 2 而不是等式 1 呢?也就是为什么要加上一个 值为 0 的 \(\mathop{max}\limits_{a}A^*(s,a)\)?
这是因为 等式1 有一个问题。
即我们无法通过学习 Q-star 来 唯一确定 V-star 和 A-star,即对于求得的 Q-star 值,可以分解成无数组 V-star 和 A-star。
\(Q(s,a;w^A,w^V)=V(s;w^V)+A(s,a;w^A)-\mathop{max}\limits_{a}A(s,a;w^A)\)
我们是对 左侧Q 来训练整个 Dueling Network 的。如果 V 网络 向上波动 和 A 网络向下波动幅度相同,那么 Dueling Network 的输出完全相同,但是V-A两个网络都发生了波动,训练不好。
而加上最大化这一项就能避免不唯一性;即如果 V-star 向上波动10,A-star 向下波动10,那么整个式子的值会发生改变
因为max项随着A-star 的变化 也减少了10,总体上升了10
在上面的数学推导中,我们使用的是 \(\max \limits_{a}A(s,a;w^A)\)来近似最大项\(\max\limits_{a}A(s,a)\),而在实际应用中,用 \(\mathop{mean}\limits_{a}A(S,a;w^A)\)来近似效果更好;这种替换没有理论依据,但是实际效果好。
x. 参考教程
- 视频课程:深度强化学习(全)_哔哩哔哩_bilibili
- 视频原地址:https://www.youtube.com/user/wsszju
- 课件地址:https://github.com/wangshusen/DeepLearning
强化学习-学习笔记12 | Dueling Network的更多相关文章
- 强化学习读书笔记 - 12 - 资格痕迹(Eligibility Traces)
强化学习读书笔记 - 12 - 资格痕迹(Eligibility Traces) 学习笔记: Reinforcement Learning: An Introduction, Richard S. S ...
- ng-深度学习-课程笔记-12: 深度卷积网络的实例探究(Week2)
1 实例探究( Cast Study ) 这一周,ng对几个关于计算机视觉的经典网络进行实例分析,LeNet-5,AlexNet,VGG,ResNet,Inception. 2 经典网络( Class ...
- 强化学习读书笔记 - 13 - 策略梯度方法(Policy Gradient Methods)
强化学习读书笔记 - 13 - 策略梯度方法(Policy Gradient Methods) 学习笔记: Reinforcement Learning: An Introduction, Richa ...
- 强化学习系列之:Deep Q Network (DQN)
文章目录 [隐藏] 1. 强化学习和深度学习结合 2. Deep Q Network (DQN) 算法 3. 后续发展 3.1 Double DQN 3.2 Prioritized Replay 3. ...
- 强化学习-学习笔记14 | 策略梯度中的 Baseline
本篇笔记记录学习在 策略学习 中使用 Baseline,这样可以降低方差,让收敛更快. 14. 策略学习中的 Baseline 14.1 Baseline 推导 在策略学习中,我们使用策略网络 \(\ ...
- 深度学习课程笔记(十五)Recurrent Neural Network
深度学习课程笔记(十五)Recurrent Neural Network 2018-08-07 18:55:12 This video tutorial can be found from: Yout ...
- 深度学习课程笔记(十三)深度强化学习 --- 策略梯度方法(Policy Gradient Methods)
深度学习课程笔记(十三)深度强化学习 --- 策略梯度方法(Policy Gradient Methods) 2018-07-17 16:50:12 Reference:https://www.you ...
- Ext.Net学习笔记12:Ext.Net GridPanel Filter用法
Ext.Net学习笔记12:Ext.Net GridPanel Filter用法 Ext.Net GridPanel的用法在上一篇中已经介绍过,这篇笔记讲介绍Filter的用法. Filter是用来过 ...
- 强化学习读书笔记 - 02 - 多臂老O虎O机问题
# 强化学习读书笔记 - 02 - 多臂老O虎O机问题 学习笔记: [Reinforcement Learning: An Introduction, Richard S. Sutton and An ...
随机推荐
- PostgreSQL 锁 之 关系级锁
1.关于锁的基本信息 PostgreSQL 有各种各样的技术来锁定某些东西(或者至少是这样称呼的).因此,我将首先用最笼统的术语解释为什么需要锁,可用的锁类型以及它们之间的区别.然后我们将弄清楚 Po ...
- [AcWing 821] 跳台阶
点击查看代码 #include<iostream> using namespace std; int n, ans = 0; void f(int k) { if (k == n) ans ...
- celery介绍、架构、快速使用、包结构,celery执行异步、延迟、定时任务,django中使用celery,定时更新首页轮播图效果实现,数据加入redis缓存的坑及解决
今日内容概要 celery介绍,架构 celery 快速使用 celery包结构 celery执行异步任务 celery执行延迟任务 celery执行定时任务 django中使用celery 定时更新 ...
- ChCore Lab2 内存管理 实验笔记
本文为上海交大 ipads 研究所陈海波老师等人所著的<现代操作系统:原理与实现>的课程实验(LAB)的学习笔记的第二篇.所有章节的笔记可在此处查看:chcore | 康宇PL's Blo ...
- go-micro集成RabbitMQ实战和原理
在go-micro中异步消息的收发是通过Broker这个组件来完成的,底层实现有RabbitMQ.Kafka.Redis等等很多种方式,这篇文章主要介绍go-micro使用RabbitMQ收发数据的方 ...
- Element中使用el-select选中后不显示值
<el-select v-model="form.data" placeholder="选择参数" @change="changeThis&qu ...
- 流量治理神器-Sentinel 究竟是怎么做到让业务方接入简单?
大家好,我是架构摆渡人,这是流量治理系列的第10篇原创文章,如果有收获,还请分享给更多的朋友. 做业务开发,需要考虑业务的扩展性.做基础框架开发,需要考虑如何让业务方接入,使用简单,尽量不要耦合在业务 ...
- docker 1.2 之docker基本用法
1.docker的基本用法 镜像相关操作:dockerhub查找镜像,例如查找centos的镜像 [root@elk ~]# docker search centos NAME DESCRIPTION ...
- 安装Speedtest到Python
Speedtest模块可以测试主机的网络带宽大小. 运行环境 系统版本:CentOS Linux release 7.3.1611 (Core) 软件版本:无 硬件要求:无 安装过程 1.安装Spee ...
- 用python解决打标签时将xml文件的标签名打错
用python解决打标签时将xml文件的标签名打错 问题描述:再进行达标签时将magnetic_tile的标签名错误的打成了magnetic_title,又不想一张一张的修改 出现问题的xml文件 & ...