【Python爬虫技巧】快速格式化请求头Request Headers
你好,我是 @马哥python说 。
我们在写爬虫时,经常遇到这种问题,从目标网站把请求头复制下来,粘贴到爬虫代码里,需要一点一点修改格式,因为复制的是字符串string格式,请求头需要用字典dict格式:
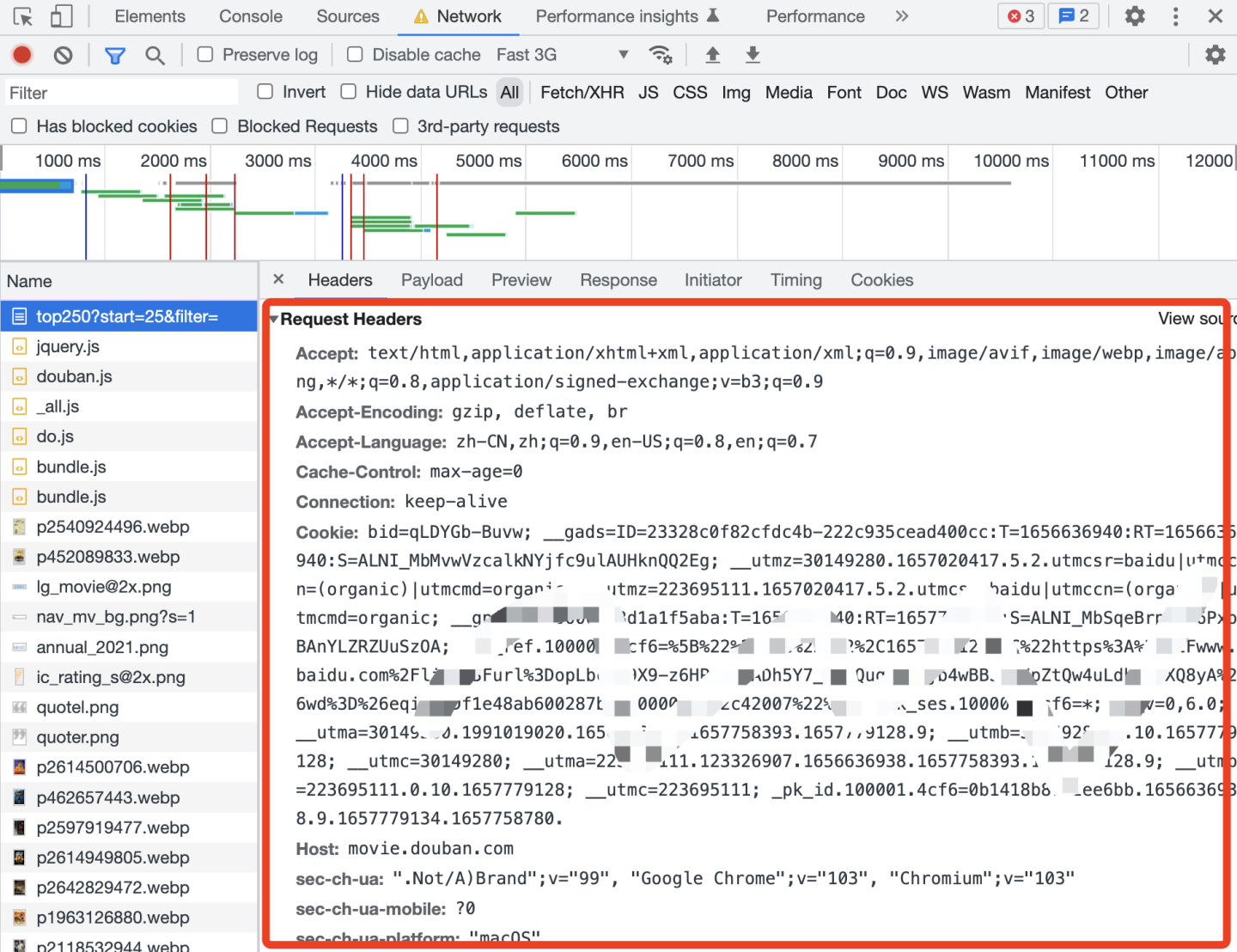
下面介绍一种简单的方法。
首先,把复制到的请求头放到一个字符串里:
# 请求头
headers = """
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9
Accept-Encoding: gzip, deflate, br
Accept-Language: zh-CN,zh;q=0.9,en-US;q=0.8,en;q=0.7
Cache-Control: max-age=0
Connection: keep-alive
Cookie: cookie值
Host: movie.douban.com
Referer: https://movie.douban.com/top250
sec-ch-ua: ".Not/A)Brand";v="99", "Google Chrome";v="103", "Chromium";v="103"
sec-ch-ua-mobile: ?0
sec-ch-ua-platform: "macOS"
Sec-Fetch-Dest: document
Sec-Fetch-Mode: navigate
Sec-Fetch-Site: same-origin
Sec-Fetch-User: ?1
Upgrade-Insecure-Requests: 1
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36
"""
然后,导入lxpy库:
from lxpy import copy_headers_dict
把刚才的字符串转换为字典:
# 转换请求头为字典格式
headers = copy_headers_dict(headers)
再看一眼现在的请求头,已经转成了字典格式:
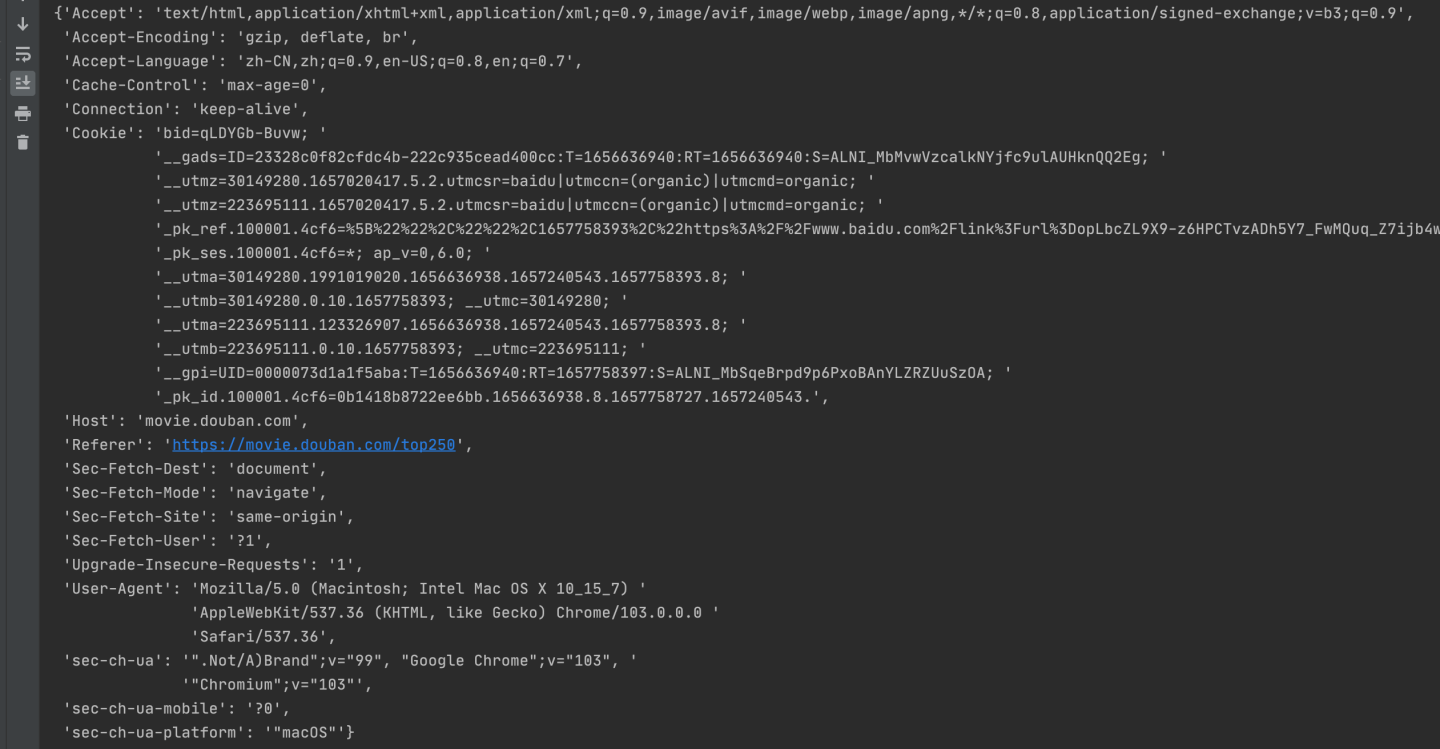
非常好用有没有!
下面,就可以继续开心的撸爬虫代码了~
同步讲解视频:
https://www.zhihu.com/zvideo/1530851114778210304
我是 @马哥python说 ,持续分享Python干货!
【Python爬虫技巧】快速格式化请求头Request Headers的更多相关文章
- Retrofit2.0+OkHttp设置统一的请求头(request headers)
有时候要求Retrofit2的接口中每个都要增加上headers,又不想做重复的事情,可以使用这种方法来为每个request请求都设置上相同的请求头header. 修改请求头request heade ...
- 请求头(request headers)和响应头(response headers)解析
*****************请求头(request headers)***************** POST /user/signin HTTP/1.1 --请求方式 文件名 http ...
- python爬虫之分析Ajax请求抓取抓取今日头条街拍美图(七)
python爬虫之分析Ajax请求抓取抓取今日头条街拍美图 一.分析网站 1.进入浏览器,搜索今日头条,在搜索栏搜索街拍,然后选择图集这一栏. 2.按F12打开开发者工具,刷新网页,这时网页回弹到综合 ...
- Python爬虫技巧
Python爬虫技巧一之设置ADSL拨号服务器代理 reference: https://zhuanlan.zhihu.com/p/25286144 爬取数据时,是不是只能每个网站每个网站的分析,有没 ...
- python爬虫之快速对js内容进行破解
python爬虫之快速对js内容进行破解 今天介绍下数据被js加密后的破解方法.距离上次发文已经过去半个多月了,我写文章的主要目的是把从其它地方学到的东西做个记录顺便分享给大家,我承认自己是个懒猪.不 ...
- Python3 自定义请求头消息headers
Python3 自定义请求头消息headers 使用python爬虫爬取数据的时候,经常会遇到一些网站的反爬虫措施,一般就是针对于headers中的User-Agent,如果没有对headers进行设 ...
- python爬虫爬取get请求的页面数据代码样例
废话不多说,上代码 #!/usr/bin/env python # -*- coding:utf-8 -*- # 导包 import urllib.request import urllib.pars ...
- requests快速构造请求头的方法
上图请求头内容,内容多不说,也不确认哪些数据是必须的,网上找到一个懒办法 快速一键生成 Python 爬虫请求头 实战演练 抓取网站:https://developer.mozilla.org... ...
- python爬虫(二)_HTTP的请求和响应
HTTP和HTTPS HTTP(HyperText Transfer Protocol,超文本传输协议):是一种发布和接收HTML页面的方法 HTTPS(HyperText Transfer Prot ...
随机推荐
- LINUX系统虚拟机环境的安装
安装VM和Centos Step 1 去BIOS里修改设置开启虚拟化设备支持 设置BIOS: 1.开机按F2.F12.DEL.ESC等进入BIOS,一般来说可以看屏幕的左下角有提示按键进入BIOS,进 ...
- clion 预编译文件的查看
看了一圈网上也没有我能一下就能看的懂的配置教程 我就手打一篇给在用clion的同学来参考一下 本文适用于g++编译 cmake Ninja生成器 clion 默认使用的是CMAKE来构建程序 生成器用 ...
- 审计 Linux 系统的操作行为的 5 种方案对比
点击上方"开源Linux",选择"设为星标" 回复"学习"获取独家整理的学习资料! 很多时候我们为了安全审计或者故障跟踪排错,可能会记录分析 ...
- Red Hat牵头推进NVFS文件系统
开源Linux 长按二维码加关注~ 上一篇:Linux中几个正则表达式的用法 由 Red Hat 工程师牵头的团队,正在为 Linux/开源社区研究名为 NVFS 的文件系统.NVFS 的目标是成为像 ...
- 【mq】从零开始实现 mq-07-负载均衡 load balance
前景回顾 [mq]从零开始实现 mq-01-生产者.消费者启动 [mq]从零开始实现 mq-02-如何实现生产者调用消费者? [mq]从零开始实现 mq-03-引入 broker 中间人 [mq]从零 ...
- python二分法、牛顿法求根
二分法求根 思路:对于一个连续函数,左值f(a)*右值f(b)如果<0,那么在这个区间内[a,b]必存在一个c使得f(c)=0 那么思路便是取中间点,分成两段区间,然后对这两段区间分别再比较,跳 ...
- 『现学现忘』Git基础 — 26、给Git命令设置别名
目录 1.什么是Git命令的别名 2.别名的全局配置 3.别名的局部配置 4.删除所有别名 5.小练习 1.什么是Git命令的别名 Git中命令很多,有些命令比较长,有些命令也不好记,也容易写错. 例 ...
- 234. Palindrome Linked List - LeetCode
Question 234. Palindrome Linked List Solution 题目大意:给一个链表,判断是该链表中的元素组成的串是否回文 思路:遍历链表添加到一个list中,再遍历lis ...
- 记 iTextSharp 剪裁 PDF 指定区域的方法
原文 引用 itextsharp 5.5.13.2 itextsharp.xtra 5.5.13.2 方法 /// <summary> /// 截取pdf文件,例如把A4截出指定的A6区域 ...
- df-查看磁盘目录空间大小
查看磁盘分区挂载情况. 语法 df [option] 选项 -T 显示文件系统类型. -h 带单位显示. 示例 [root@localhost ~]# df -Th Filesystem Type S ...