详解SQL中Groupings Sets 语句的功能和底层实现逻辑
摘要:本文首先简单介绍 Grouping Sets 的用法,然后以 Spark SQL 作为切入点,深入解析 Grouping Sets 的实现机制。
本文分享自华为云社区《深入理解 SQL 中的 Grouping Sets 语句》,作者:元闰子。
前言
SQL 中 Group By 语句大家都很熟悉,根据指定的规则对数据进行分组,常常和聚合函数一起使用。
比如,考虑有表 dealer,表中数据如下:
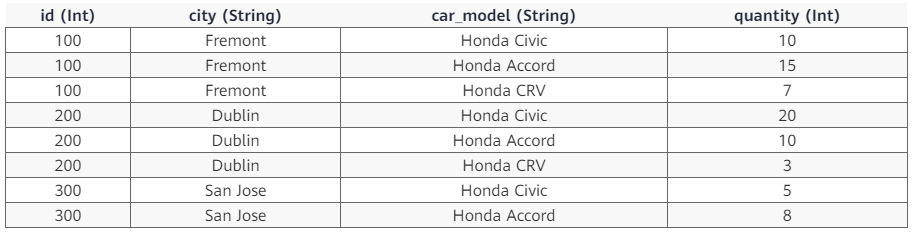
如果执行 SQL 语句 SELECT id, sum(quantity) FROM dealer GROUP BY id ORDER BY id,会得到如下结果:
+---+-------------+
| id|sum(quantity)|
+---+-------------+
|100| 32|
|200| 33|
|300| 13|
+---+-------------+
上述 SQL 语句的意思就是对数据按 id 列进行分组,然后在每个分组内对 quantity 列进行求和。
Group By 语句除了上面的简单用法之外,还有更高级的用法,常见的是 Grouping Sets、RollUp 和 Cube,它们在 OLAP 时比较常用。其中,RollUp 和 Cube 都是以 Grouping Sets 为基础实现的,因此,弄懂了 Grouping Sets,也就理解了 RollUp 和 Cube 。
本文首先简单介绍 Grouping Sets 的用法,然后以 Spark SQL 作为切入点,深入解析 Grouping Sets 的实现机制。
Spark SQL 是 Apache Spark 大数据处理框架的一个子模块,用来处理结构化信息。它可以将 SQL 语句翻译多个任务在 Spark 集群上执行,允许用户直接通过 SQL 来处理数据,大大提升了易用性。
Grouping Sets 简介
Spark SQL 官方文档中 SQL Syntax 一节对 Grouping Sets 语句的描述如下:
Groups the rows for each grouping set specified after GROUPING SETS. (... 一些举例) This clause is a shorthand for a
UNION ALLwhere each leg of theUNION ALLoperator performs aggregation of each grouping set specified in theGROUPING SETSclause. (... 一些举例)
也即,Grouping Sets 语句的作用是指定几个 grouping set 作为 Group By 的分组规则,然后再将结果联合在一起。它的效果和,先分别对这些 grouping set 进行 Group By 分组之后,再通过 Union All 将结果联合起来,是一样的。
比如,对于 dealer 表,Group By Grouping Sets ((city, car_model), (city), (car_model), ()) 和 Union All((Group By city, car_model), (Group By city), (Group By car_model), 全局聚合) 的效果是相同的:
先看 Grouping Sets 版的执行结果:
spark-sql> SELECT city, car_model, sum(quantity) AS sum FROM dealer
> GROUP BY GROUPING SETS ((city, car_model), (city), (car_model), ())
> ORDER BY city, car_model;
+--------+------------+---+
| city| car_model|sum|
+--------+------------+---+
| null| null| 78|
| null|Honda Accord| 33|
| null| Honda CRV| 10|
| null| Honda Civic| 35|
| Dublin| null| 33|
| Dublin|Honda Accord| 10|
| Dublin| Honda CRV| 3|
| Dublin| Honda Civic| 20|
| Fremont| null| 32|
| Fremont|Honda Accord| 15|
| Fremont| Honda CRV| 7|
| Fremont| Honda Civic| 10|
|San Jose| null| 13|
|San Jose|Honda Accord| 8|
|San Jose| Honda Civic| 5|
+--------+------------+---+
再看 Union All 版的执行结果:
spark-sql> (SELECT city, car_model, sum(quantity) AS sum FROM dealer GROUP BY city, car_model) UNION ALL
> (SELECT city, NULL as car_model, sum(quantity) AS sum FROM dealer GROUP BY city) UNION ALL
> (SELECT NULL as city, car_model, sum(quantity) AS sum FROM dealer GROUP BY car_model) UNION ALL
> (SELECT NULL as city, NULL as car_model, sum(quantity) AS sum FROM dealer)
> ORDER BY city, car_model;
+--------+------------+---+
| city| car_model|sum|
+--------+------------+---+
| null| null| 78|
| null|Honda Accord| 33|
| null| Honda CRV| 10|
| null| Honda Civic| 35|
| Dublin| null| 33|
| Dublin|Honda Accord| 10|
| Dublin| Honda CRV| 3|
| Dublin| Honda Civic| 20|
| Fremont| null| 32|
| Fremont|Honda Accord| 15|
| Fremont| Honda CRV| 7|
| Fremont| Honda Civic| 10|
|San Jose| null| 13|
|San Jose|Honda Accord| 8|
|San Jose| Honda Civic| 5|
+--------+------------+---+
两版的查询结果完全一样。
Grouping Sets 的执行计划
从执行结果上看,Grouping Sets 版本和 Union All 版本的 SQL 是等价的,但 Grouping Sets 版本更加简洁。
那么,Grouping Sets 仅仅只是 Union All 的一个缩写,或者语法糖吗?
为了进一步探究 Grouping Sets 的底层实现是否和 Union All 是一致的,我们可以来看下两者的执行计划。
首先,我们通过 explain extended 来查看 Union All 版本的 Optimized Logical Plan:
spark-sql> explain extended (SELECT city, car_model, sum(quantity) AS sum FROM dealer GROUP BY city, car_model) UNION ALL(SELECT city, NULL as car_model, sum(quantity) AS sum FROM dealer GROUP BY city) UNION ALL (SELECT NULL as city, car_model, sum(quantity) AS sum FROM dealer GROUP BY car_model) UNION ALL (SELECT NULL as city, NULL as car_model, sum(quantity) AS sum FROM dealer) ORDER BY city, car_model;
== Parsed Logical Plan ==
...
== Analyzed Logical Plan ==
...
== Optimized Logical Plan ==
Sort [city#93 ASC NULLS FIRST, car_model#94 ASC NULLS FIRST], true
+- Union false, false
:- Aggregate [city#93, car_model#94], [city#93, car_model#94, sum(quantity#95) AS sum#79L]
: +- Project [city#93, car_model#94, quantity#95]
: +- HiveTableRelation [`default`.`dealer`, ..., Data Cols: [id#92, city#93, car_model#94, quantity#95], Partition Cols: []]
:- Aggregate [city#97], [city#97, null AS car_model#112, sum(quantity#99) AS sum#81L]
: +- Project [city#97, quantity#99]
: +- HiveTableRelation [`default`.`dealer`, ..., Data Cols: [id#96, city#97, car_model#98, quantity#99], Partition Cols: []]
:- Aggregate [car_model#102], [null AS city#113, car_model#102, sum(quantity#103) AS sum#83L]
: +- Project [car_model#102, quantity#103]
: +- HiveTableRelation [`default`.`dealer`, ..., Data Cols: [id#100, city#101, car_model#102, quantity#103], Partition Cols: []]
+- Aggregate [null AS city#114, null AS car_model#115, sum(quantity#107) AS sum#86L]
+- Project [quantity#107]
+- HiveTableRelation [`default`.`dealer`, ..., Data Cols: [id#104, city#105, car_model#106, quantity#107], Partition Cols: []]
== Physical Plan ==
...
从上述的 Optimized Logical Plan 可以清晰地看出 Union All 版本的执行逻辑:
执行每个子查询语句,计算得出查询结果。其中,每个查询语句的逻辑是这样的:
在 HiveTableRelation 节点对
dealer表进行全表扫描。在 Project 节点选出与查询语句结果相关的列,比如对于子查询语句
SELECT NULL as city, NULL as car_model, sum(quantity) AS sum FROM dealer,只需保留quantity列即可。在 Aggregate 节点完成
quantity列对聚合运算。在上述的 Plan 中,Aggregate 后面紧跟的就是用来分组的列,比如Aggregate [city#902]就表示根据city列来进行分组。
在 Union 节点完成对每个子查询结果的联合。
最后,在 Sort 节点完成对数据的排序,上述 Plan 中
Sort [city#93 ASC NULLS FIRST, car_model#94 ASC NULLS FIRST]就表示根据city和car_model列进行升序排序。

接下来,我们通过 explain extended 来查看 Grouping Sets 版本的 Optimized Logical Plan:
spark-sql> explain extended SELECT city, car_model, sum(quantity) AS sum FROM dealer GROUP BY GROUPING SETS ((city, car_model), (city), (car_model), ()) ORDER BY city, car_model;
== Parsed Logical Plan ==
...
== Analyzed Logical Plan ==
...
== Optimized Logical Plan ==
Sort [city#138 ASC NULLS FIRST, car_model#139 ASC NULLS FIRST], true
+- Aggregate [city#138, car_model#139, spark_grouping_id#137L], [city#138, car_model#139, sum(quantity#133) AS sum#124L]
+- Expand [[quantity#133, city#131, car_model#132, 0], [quantity#133, city#131, null, 1], [quantity#133, null, car_model#132, 2], [quantity#133, null, null, 3]], [quantity#133, city#138, car_model#139, spark_grouping_id#137L]
+- Project [quantity#133, city#131, car_model#132]
+- HiveTableRelation [`default`.`dealer`, org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe, Data Cols: [id#130, city#131, car_model#132, quantity#133], Partition Cols: []]
== Physical Plan ==
...
从 Optimized Logical Plan 来看,Grouping Sets 版本要简洁很多!具体的执行逻辑是这样的:
在 HiveTableRelation 节点对
dealer表进行全表扫描。在 Project 节点选出与查询语句结果相关的列。
接下来的 Expand 节点是关键,数据经过该节点后,多出了
spark_grouping_id列。从 Plan 中可以看出来,Expand 节点包含了Grouping Sets里的各个 grouping set 信息,比如[quantity#133, city#131, null, 1]对应的就是(city)这一 grouping set。而且,每个 grouping set 对应的spark_grouping_id列的值都是固定的,比如(city)对应的spark_grouping_id为1。在 Aggregate 节点完成
quantity列对聚合运算,其中分组的规则为city, car_model, spark_grouping_id。注意,数据经过 Aggregate 节点后,spark_grouping_id列被删除了!最后,在 Sort 节点完成对数据的排序。

从 Optimized Logical Plan 来看,虽然 Union All 版本和 Grouping Sets 版本的效果一致,但它们的底层实现有着巨大的差别。
其中,Grouping Sets 版本的 Plan 中最关键的是 Expand 节点,目前,我们只知道数据经过它之后,多出了 spark_grouping_id 列。而且从最终结果来看,spark_grouping_id 只是 Spark SQL 的内部实现细节,对用户并不体现。那么:
Expand 的实现逻辑是怎样的,为什么能达到
Union All的效果?Expand 节点的输出数据是怎样的?
spark_grouping_id列的作用是什么?
通过 Physical Plan,我们发现 Expand 节点对应的算子名称也是 Expand:
== Physical Plan ==
AdaptiveSparkPlan isFinalPlan=false
+- Sort [city#138 ASC NULLS FIRST, car_model#139 ASC NULLS FIRST], true, 0
+- Exchange rangepartitioning(city#138 ASC NULLS FIRST, car_model#139 ASC NULLS FIRST, 200), ENSURE_REQUIREMENTS, [plan_id=422]
+- HashAggregate(keys=[city#138, car_model#139, spark_grouping_id#137L], functions=[sum(quantity#133)], output=[city#138, car_model#139, sum#124L])
+- Exchange hashpartitioning(city#138, car_model#139, spark_grouping_id#137L, 200), ENSURE_REQUIREMENTS, [plan_id=419]
+- HashAggregate(keys=[city#138, car_model#139, spark_grouping_id#137L], functions=[partial_sum(quantity#133)], output=[city#138, car_model#139, spark_grouping_id#137L, sum#141L])
+- Expand [[quantity#133, city#131, car_model#132, 0], [quantity#133, city#131, null, 1], [quantity#133, null, car_model#132, 2], [quantity#133, null, null, 3]], [quantity#133, city#138, car_model#139, spark_grouping_id#137L]
+- Scan hive default.dealer [quantity#133, city#131, car_model#132], HiveTableRelation [`default`.`dealer`, ..., Data Cols: [id#130, city#131, car_model#132, quantity#133], Partition Cols: []]
带着前面的几个问题,接下来我们深入 Spark SQL 的 Expand 算子源码寻找答案。
Expand 算子的实现
Expand 算子在 Spark SQL 源码中的实现为 ExpandExec 类(Spark SQL 中的算子实现类的命名都是 XxxExec 的格式,其中 Xxx 为具体的算子名,比如 Project 算子的实现类为 ProjectExec),核心代码如下:
/**
* Apply all of the GroupExpressions to every input row, hence we will get
* multiple output rows for an input row.
* @param projections The group of expressions, all of the group expressions should
* output the same schema specified bye the parameter `output`
* @param output The output Schema
* @param child Child operator
*/
case class ExpandExec(
projections: Seq[Seq[Expression]],
output: Seq[Attribute],
child: SparkPlan)
extends UnaryExecNode with CodegenSupport {
...
// 关键点1,将child.output,也即上游算子输出数据的schema,
// 绑定到表达式数组exprs,以此来计算输出数据
private[this] val projection =
(exprs: Seq[Expression]) => UnsafeProjection.create(exprs, child.output)
// doExecute()方法为Expand算子执行逻辑所在
protected override def doExecute(): RDD[InternalRow] = {
val numOutputRows = longMetric("numOutputRows")
// 处理上游算子的输出数据,Expand算子的输入数据就从iter迭代器获取
child.execute().mapPartitions { iter =>
// 关键点2,projections对应了Grouping Sets里面每个grouping set的表达式,
// 表达式输出数据的schema为this.output, 比如 (quantity, city, car_model, spark_grouping_id)
// 这里的逻辑是为它们各自生成一个UnsafeProjection对象,通过该对象的apply方法就能得出Expand算子的输出数据
val groups = projections.map(projection).toArray
new Iterator[InternalRow] {
private[this] var result: InternalRow = _
private[this] var idx = -1 // -1 means the initial state
private[this] var input: InternalRow = _
override final def hasNext: Boolean = (-1 < idx && idx < groups.length) || iter.hasNext
override final def next(): InternalRow = {
// 关键点3,对于输入数据的每一条记录,都重复使用N次,其中N的大小对应了projections数组的大小,
// 也即Grouping Sets里指定的grouping set的数量
if (idx <= 0) {
// in the initial (-1) or beginning(0) of a new input row, fetch the next input tuple
input = iter.next()
idx = 0
}
// 关键点4,对输入数据的每一条记录,通过UnsafeProjection计算得出输出数据,
// 每个grouping set对应的UnsafeProjection都会对同一个input计算一遍
result = groups(idx)(input)
idx += 1
if (idx == groups.length && iter.hasNext) {
idx = 0
}
numOutputRows += 1
result
}
}
}
}
...
}
ExpandExec 的实现并不复杂,想要理解它的运作原理,关键是看懂上述源码中提到的 4 个关键点。
关键点 1 和 关键点 2 是基础,关键点 2 中的 groups 是一个 UnsafeProjection[N] 数组类型,其中每个 UnsafeProjection 代表了 Grouping Sets 语句里指定的 grouping set,它的定义是这样的:
// A projection that returns UnsafeRow.
abstract class UnsafeProjection extends Projection {
override def apply(row: InternalRow): UnsafeRow
}
// The factory object for `UnsafeProjection`.
object UnsafeProjection
extends CodeGeneratorWithInterpretedFallback[Seq[Expression], UnsafeProjection] {
// Returns an UnsafeProjection for given sequence of Expressions, which will be bound to
// `inputSchema`.
def create(exprs: Seq[Expression], inputSchema: Seq[Attribute]): UnsafeProjection = {
create(bindReferences(exprs, inputSchema))
}
...
}
UnsafeProjection 起来了类似列投影的作用,其中, apply 方法根据创建时的传参 exprs 和 inputSchema,对输入记录进行列投影,得出输出记录。
比如,前面的 GROUPING SETS ((city, car_model), (city), (car_model), ()) 例子,它对应的 groups 是这样的:

其中,AttributeReference 类型的表达式,在计算时,会直接引用输入数据对应列的值;Iteral 类型的表达式,在计算时,值是固定的。
关键点 3 和 关键点 4 是 Expand 算子的精华所在,ExpandExec 通过这两段逻辑,将每一个输入记录,扩展(Expand)成 N 条输出记录。
关键点 4中groups(idx)(input)等同于groups(idx).apply(input)。
还是以前面 GROUPING SETS ((city, car_model), (city), (car_model), ()) 为例子,效果是这样的:

到这里,我们已经弄清楚 Expand 算子的工作原理,再回头看前面提到的 3 个问题,也不难回答了:
Expand 的实现逻辑是怎样的,为什么能达到
Union All的效果?如果说
Union All是先聚合再联合,那么 Expand 就是先联合再聚合。Expand 利用groups里的 N 个表达式对每条输入记录进行计算,扩展成 N 条输出记录。后面再聚合时,就能达到与Union All一样的效果了。Expand 节点的输出数据是怎样的?
在 schema 上,Expand 输出数据会比输入数据多出
spark_grouping_id列;在记录数上,是输入数据记录数的 N 倍。spark_grouping_id列的作用是什么?spark_grouping_id给每个 grouping set 进行编号,这样,即使在 Expand 阶段把数据先联合起来,在 Aggregate 阶段(把spark_grouping_id加入到分组规则)也能保证数据能够按照每个 grouping set 分别聚合,确保了结果的正确性。
查询性能对比
从前文可知,Grouping Sets 和 Union All 两个版本的 SQL 语句有着一样的效果,但是它们的执行计划却有着巨大的差别。下面,我们将比对两个版本之间的执行性能差异。
spark-sql 执行完 SQL 语句之后会打印耗时信息,我们对两个版本的 SQL 分别执行 10 次,得到如下信息:
// Grouping Sets 版本执行10次的耗时信息
// SELECT city, car_model, sum(quantity) AS sum FROM dealer GROUP BY GROUPING SETS ((city, car_model), (city), (car_model), ()) ORDER BY city, car_model;
Time taken: 0.289 seconds, Fetched 15 row(s)
Time taken: 0.251 seconds, Fetched 15 row(s)
Time taken: 0.259 seconds, Fetched 15 row(s)
Time taken: 0.258 seconds, Fetched 15 row(s)
Time taken: 0.296 seconds, Fetched 15 row(s)
Time taken: 0.247 seconds, Fetched 15 row(s)
Time taken: 0.298 seconds, Fetched 15 row(s)
Time taken: 0.286 seconds, Fetched 15 row(s)
Time taken: 0.292 seconds, Fetched 15 row(s)
Time taken: 0.282 seconds, Fetched 15 row(s)
// Union All 版本执行10次的耗时信息
// (SELECT city, car_model, sum(quantity) AS sum FROM dealer GROUP BY city, car_model) UNION ALL (SELECT city, NULL as car_model, sum(quantity) AS sum FROM dealer GROUP BY city) UNION ALL (SELECT NULL as city, car_model, sum(quantity) AS sum FROM dealer GROUP BY car_model) UNION ALL (SELECT NULL as city, NULL as car_model, sum(quantity) AS sum FROM dealer) ORDER BY city, car_model;
Time taken: 0.628 seconds, Fetched 15 row(s)
Time taken: 0.594 seconds, Fetched 15 row(s)
Time taken: 0.591 seconds, Fetched 15 row(s)
Time taken: 0.607 seconds, Fetched 15 row(s)
Time taken: 0.616 seconds, Fetched 15 row(s)
Time taken: 0.64 seconds, Fetched 15 row(s)
Time taken: 0.623 seconds, Fetched 15 row(s)
Time taken: 0.625 seconds, Fetched 15 row(s)
Time taken: 0.62 seconds, Fetched 15 row(s)
Time taken: 0.62 seconds, Fetched 15 row(s)
可以算出,Grouping Sets 版本的 SQL 平均耗时为 0.276s;Union All 版本的 SQL 平均耗时为 0.616s,是前者的 2.2 倍!
所以,Grouping Sets 版本的 SQL 不仅在表达上更加简洁,在性能上也更加高效。
RollUp 和 Cube
Group By 的高级用法中,还有 RollUp 和 Cube 两个比较常用。
首先,我们看下 RollUp 语句。
Spark SQL 官方文档中 SQL Syntax 一节对 RollUp 语句的描述如下:
Specifies multiple levels of aggregations in a single statement. This clause is used to compute aggregations based on multiple grouping sets.
ROLLUPis a shorthand forGROUPING SETS. (... 一些例子)
官方文档中,把 RollUp 描述为 Grouping Sets 的简写,等价规则为:RollUp(A, B, C) == Grouping Sets((A, B, C), (A, B), (A), ())。
比如,Group By RollUp(city, car_model) 就等同于 Group By Grouping Sets((city, car_model), (city), ())。
下面,我们通过 expand extended 看下 RollUp 版本 SQL 的 Optimized Logical Plan:
spark-sql> explain extended SELECT city, car_model, sum(quantity) AS sum FROM dealer GROUP BY ROLLUP(city, car_model) ORDER BY city, car_model;
== Parsed Logical Plan ==
...
== Analyzed Logical Plan ==
...
== Optimized Logical Plan ==
Sort [city#2164 ASC NULLS FIRST, car_model#2165 ASC NULLS FIRST], true
+- Aggregate [city#2164, car_model#2165, spark_grouping_id#2163L], [city#2164, car_model#2165, sum(quantity#2159) ASsum#2150L]
+- Expand [[quantity#2159, city#2157, car_model#2158, 0], [quantity#2159, city#2157, null, 1], [quantity#2159, null, null, 3]], [quantity#2159, city#2164, car_model#2165, spark_grouping_id#2163L]
+- Project [quantity#2159, city#2157, car_model#2158]
+- HiveTableRelation [`default`.`dealer`, ..., Data Cols: [id#2156, city#2157, car_model#2158, quantity#2159], Partition Cols: []]
== Physical Plan ==
...
从上述 Plan 可以看出,RollUp 底层实现用的也是 Expand 算子,说明 RollUp 确实是基于 Grouping Sets 实现的。 而且 Expand [[quantity#2159, city#2157, car_model#2158, 0], [quantity#2159, city#2157, null, 1], [quantity#2159, null, null, 3]] 也表明 RollUp 符合等价规则。
下面,我们按照同样的思路,看下 Cube 语句。
Spark SQL 官方文档中 SQL Syntax 一节对 Cube 语句的描述如下:
CUBEclause is used to perform aggregations based on combination of grouping columns specified in theGROUP BYclause.CUBEis a shorthand forGROUPING SETS. (... 一些例子)
同样,官方文档把 Cube 描述为 Grouping Sets 的简写,等价规则为:Cube(A, B, C) == Grouping Sets((A, B, C), (A, B), (A, C), (B, C), (A), (B), (C), ())。
比如,Group By Cube(city, car_model) 就等同于 Group By Grouping Sets((city, car_model), (city), (car_model), ())。
下面,我们通过 expand extended 看下 Cube 版本 SQL 的 Optimized Logical Plan:
spark-sql> explain extended SELECT city, car_model, sum(quantity) AS sum FROM dealer GROUP BY CUBE(city, car_model) ORDER BY city, car_model;
== Parsed Logical Plan ==
...
== Analyzed Logical Plan ==
...
== Optimized Logical Plan ==
Sort [city#2202 ASC NULLS FIRST, car_model#2203 ASC NULLS FIRST], true
+- Aggregate [city#2202, car_model#2203, spark_grouping_id#2201L], [city#2202, car_model#2203, sum(quantity#2197) ASsum#2188L]
+- Expand [[quantity#2197, city#2195, car_model#2196, 0], [quantity#2197, city#2195, null, 1], [quantity#2197, null, car_model#2196, 2], [quantity#2197, null, null, 3]], [quantity#2197, city#2202, car_model#2203, spark_grouping_id#2201L]
+- Project [quantity#2197, city#2195, car_model#2196]
+- HiveTableRelation [`default`.`dealer`, ..., Data Cols: [id#2194, city#2195, car_model#2196, quantity#2197], Partition Cols: []]
== Physical Plan ==
...
从上述 Plan 可以看出,Cube 底层用的也是 Expand 算子,说明 Cube 确实基于 Grouping Sets 实现,而且也符合等价规则。
所以,RollUp 和 Cube 可以看成是 Grouping Sets 的语法糖,在底层实现和性能上是一样的。
最后
本文重点讨论了 Group By 高级用法 Groupings Sets 语句的功能和底层实现。
虽然 Groupings Sets 的功能,通过 Union All 也能实现,但前者并非后者的语法糖,它们的底层实现完全不一样。Grouping Sets 采用的是先联合再聚合的思路,通过 spark_grouping_id 列来保证数据的正确性;Union All 则采用先聚合再联合的思路。Grouping Sets 在 SQL 语句表达和性能上都有更大的优势。
Group By 的另外两个高级用法 RollUp 和 Cube 则可以看成是 Grouping Sets 的语法糖,它们的底层都是基于 Expand 算子实现,在性能上与直接使用 Grouping Sets 是一样的,但在 SQL 表达上更加简洁。
参考
[1] Spark SQL Guide, Apache Spark
[2] apache spark 3.3 版本源码, Apache Spark, GitHub
详解SQL中Groupings Sets 语句的功能和底层实现逻辑的更多相关文章
- 深入详解SQL中的Null
深入详解SQL中的Null NULL 在计算机和编程世界中表示的是未知,不确定.虽然中文翻译为 “空”, 但此空(null)非彼空(empty). Null表示的是一种未知状态,未来状态,比如小明兜里 ...
- 详解SQL中的GROUP BY语句
下面为您介绍SQL语句中GROUP BY 语句,GROUP BY 语句用于结合合计函数,根据一个或多个列对结果集进行分组. 希望对您学习SQL语句有所帮助. SQL GROUP BY 语法 SELEC ...
- 详解Python中的循环语句的用法
一.简介 Python的条件和循环语句,决定了程序的控制流程,体现结构的多样性.须重要理解,if.while.for以及与它们相搭配的 else. elif.break.continue和pass语句 ...
- [Android新手区] SQLite 操作详解--SQL语法
该文章完全摘自转自:北大青鸟[Android新手区] SQLite 操作详解--SQL语法 :http://home.bdqn.cn/thread-49363-1-1.html SQLite库可以解 ...
- [转帖]【Oracle】详解Oracle中NLS_LANG变量的使用
[Oracle]详解Oracle中NLS_LANG变量的使用 https://www.cnblogs.com/HDK2016/p/6880560.html NLS_LANG=LANGUAGE_TERR ...
- (数据科学学习手札140)详解geopandas中基于pyogrio的矢量读写引擎
本文示例代码已上传至我的Github仓库https://github.com/CNFeffery/DataScienceStudyNotes 1 简介 大家好我是费老师,前不久我在一篇文章中给大家分享 ...
- 用IDEA详解Spring中的IoC和DI(挺透彻的,点进来看看吧)
用IDEA详解Spring中的IoC和DI 一.Spring IoC的基本概念 控制反转(IoC)是一个比较抽象的概念,它主要用来消减计算机程序的耦合问题,是Spring框架的核心.依赖注入(DI)是 ...
- 详解Linux中的cat文本输出命令用法
作系统 > LINUX > 详解Linux中的cat文本输出命令用法 Linux命令手册 发布时间:2016-01-14 14:14:35 作者:张映 我要评论 这篇 ...
- jQuery:详解jQuery中的事件(二)
上一篇讲到jQuery中的事件,深入学习了加载DOM和事件绑定的相关知识,这篇主要深入讨论jQuery事件中的合成事件.事件冒泡和事件移除等内容. 接上篇jQuery:详解jQuery中的事件(一) ...
随机推荐
- k8s面试1-27
目录 1.k8s常用命令有哪些? 2.报错查看各种日志方法? 3.k8s的组建有哪些? 4.k8s中安全机制是什么? 5.常用的控制器有哪些? 6.service类型有哪些? 7.ingress-Ng ...
- 解决go-micro与其它gRPC框架之间的通信问题
在之前的文章中分别介绍了使用gRPC官方插件和go-micro插件开发gRPC应用程序的方式,都能正常走通.不过当两者混合使用的时候,互相访问就成了问题.比如使用go-micro插件生成的gRPC客户 ...
- 【多线程与高并发原理篇:3_java内存模型】
1. 概述 Java 内存模型即 Java Memory Model,简称 JMM.从抽象的角度来看,JMM 定义了线程和主内存之间的抽象关系,线程之间的共享变量存储在主内存中,每个线程都有一个私有的 ...
- macOS 安装 Nebula Graph 看这篇就够了
本文首发于 Nebula Graph Community 公众号 背景 刚学习图数据的内容,当前网上充斥大量的安装文档,参差不齐,部署起来令人十分头疼. 现整理一份比较完整的安装文档,供大家学习参考, ...
- 论文解读(SUBG-CON)《Sub-graph Contrast for Scalable Self-Supervised Graph Representation Learning》
论文信息 论文标题:Sub-graph Contrast for Scalable Self-Supervised Graph Representation Learning论文作者:Yizhu Ji ...
- 全场景AI推理引擎MindSpore Lite, 助力HMS Core视频编辑服务打造更智能的剪辑体验
移动互联网的发展给人们的社交和娱乐方式带来了很大的改变,以vlog.短视频等为代表的新兴文化样态正受到越来越多人的青睐.同时,随着AI智能.美颜修图等功能在图像视频编辑App中的应用,促使视频编辑效率 ...
- 团队Beta演示
组长博客 本组(组名)所有成员 短学号 姓名 2236 王耀鑫(组长) 2210 陈超颖 2209 陈湘怡 2228 许培荣 2204 滕佳 2205 何佳琳 2237 沈梓耀 2233 陈志荣 22 ...
- C++进阶-1-模板基础(函数模板、类模板)
C++进阶 模板 1.1 函数模板 1 #include<iostream> 2 using namespace std; 3 4 // 模板 5 6 // 模板的简单实例 7 // 要求 ...
- 函数式接口和@FunctionalInterface
函数式接口的特点 接口有且仅有一个抽象方法 允许定义静态方法和默认方法(这两个都不是抽象方法) 允许java.lang.Object中的public方法(因为任何一个函数式接口的实现,默认都继承了Ob ...
- 使用WebDriverManager实现自动获取浏览器驱动程序
原理: 自动到指定的地址下载相应的浏览器驱动保存到缓存区 ~/.cache/selenium 痛点: 解决因Chrome浏览器升级,driver需要同步升级,要重新下载驱动的问题 区别: 传统方式 需 ...