Oracle(一)执行计划
目录
一、什么是执行计划
二、如何查看执行计划
三、如何读懂执行计划
1. 执行顺序的原则
2. 执行计划中字段解释
3. 谓词说明
4. JOIN方式
4.1 HASH JOIN(散列连接)
4.2 SORT MERGE JOIN(排序合并连接)
4.3 NESTED LOOP(嵌套循环连接)
5. 表访问方式
5.1 全表扫描(Full Table Scans, FTS)
5.2 通过ROWID访问表(table access by ROWID)
5.3 索引扫描
一、什么是执行计划
执行计划是一条查询语句在Oracle中的执行过程或访问路径的描述。即是对一个查询任务,做出一份怎样去完成任务的详细方案。
如果要分析某条SQL的性能问题,通常我们要先看SQL的执行计划,看看SQL的每一步执行是否存在问题。 看懂执行计划也就成了SQL优化的先决条件。 通过执行计划定位性能问题,定位后就通过建立索引、修改SQL等解决问题。
二、如何查看执行计划
查看Oracle执行计划的方式有很多,常见的客户端工具如PL/SQL Developer,Navicat,Toad都支持查看解释计划,接下来就通过PL/SQL来学习如何查看执行计划。
在PL/SQL上按F5即可查看执行计划。
PL/SQL默认的设置只能查看耗费、基础、字节等基本指标,若要更深层次地分析执行计划,需要更多的数据支持,幸好PL/SQL提供了丰富的分析指标,我们可以在PL/SQL的“首选项”里面进行设置。
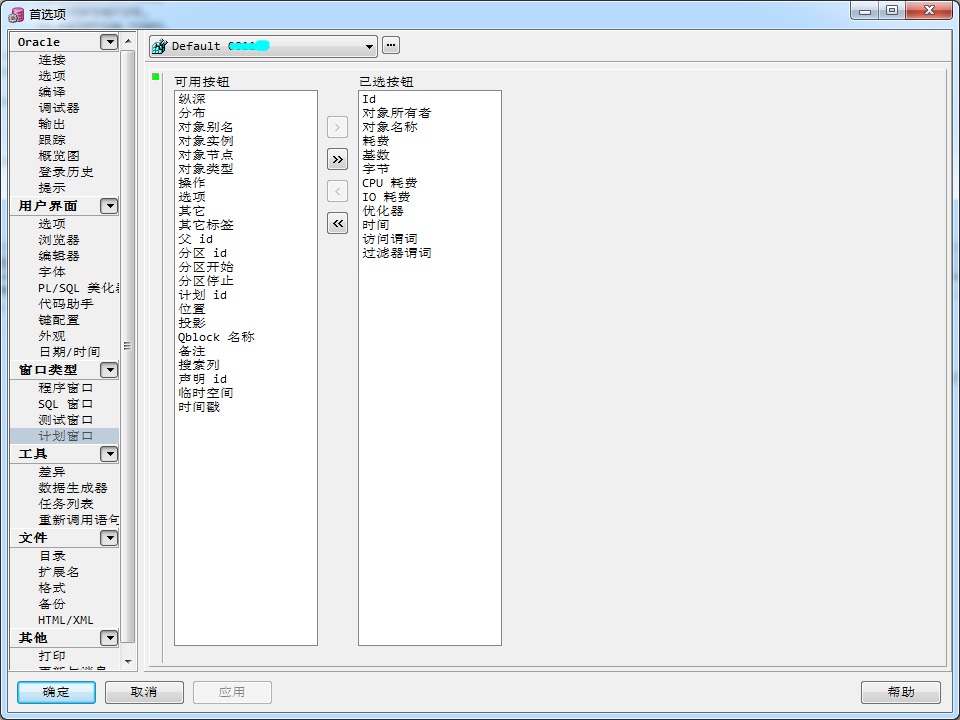
三、如何读懂执行计划
SELECT T1.CODE,
T1.EVENTTYPE,
T1.STATUS AS EXC_STATUS,
T1.EVENTSTARTTIME,
T1.EVENTENDTIME,
T1.EXCEPTION_TIMES,
T2.STATUS AS E_STATUS
FROM E_EXCEPTION T1
INNER JOIN E_INFO T2
ON T1.CODE = T2.CODE
WHERE T1.STATUS = 0
AND T1.EVENTTYPE = 'LOST_S'
AND T1.EVENTENDTIME IS NULL
AND T2.STATUS = 1
ORDER BY T1.EVENTSTARTTIME


上图是某条SQL语句的执行计划示意图,图中的左右箭头可以演示该SQL的执行顺序,当然,这是PL/SQL提供的便利操作,我们还是应该熟悉SQL执行顺序的原则。
1. 执行顺序的原则
执行顺序的原则是:由上至下,从右向左。
由上至下:在执行计划中一般含有多个节点,相同级别(或并列)的节点,靠上的优先执行,靠下的后执行。
从右向左:在某个节点下还存在多个子节点,先从最靠右的子节点开始执行。
一般按缩进长度来判断,缩进最大的最先执行,如果有2行缩进一样,那么就先执行上面的。
2. 执行计划中字段解释
| Description | 操作描述,即当前操作的内容 |
| 对象所有者(Object Owner) | 当前操作对象的所有者 |
| 对象名称(Object Name) | 当前操作的对象,对象可能是一个表,一个索引,也可能是一个子查询 |
| 耗费(Cost) |
没有单位,是一个相对值,是SQL以CBO方式解析执行计划时,供ORACLE来评估CBO成本,选择执行计划用的。没有明确的含义,但是在对比是就非常有用 公式:COST=(Single Block I/O COST + MultiBlock I/O Cost + CPU Cost)/ Sreadtim |
| 基数(Cardinality) | Oracle估计当前操作的返回结果集,10g版本以前叫做基数(Cardinality),10g版本以后叫做行数(Rows) |
| 字节(Bytes) | 执行该步骤后返回的字节数 |
| CPU耗费(Cost(CPU)) | 执行到该步骤的一个执行成本,用于说明SQL执行的代价 |
| Id | 一个序号,但不是执行的先后顺序。执行的先后根据缩进来判断 |
| IO耗费(Cost(IO)) | IO层面的执行成本 |
| 时间(Time) | Oracle 估计当前操作的时间 |
在看执行计划的时候,除了看执行计划本身,还需要看谓词和统计信息。 通过整体信息来判断SQL效率。
3. 谓词说明
访问谓词(Access predicate)
- 通过某种方式定位了需要的数据,然后读取出这些结果集,叫做Access
- 表示这个谓词条件的值将会影响数据的访问路劲(表还是索引)
过滤器谓词(Filter predicate)
- 把所有的数据都访问了,然后过滤掉不需要的数据,这种方式叫做Filter
- 表示谓词条件的值不会影响数据的访问路劲,只起过滤的作用
在谓词中主要注意Access,要考虑谓词的条件,使用的访问路径是否正确。
4. JOIN方式
4.1 HASH JOIN(散列连接)
Hash join散列连接是CBO 做大数据集连接时的常用方式,优化器使用两个表中较小的表(通常是小一点的那个表或数据源)利用连接键(JOIN KEY)在内存中建立散列表,将列数据存储到hash列表中,然后扫描较大的表,同样对JOIN KEY进行HASH后探测散列表,找出与散列表匹配的行。需要注意的是:如果HASH表太大,无法一次构造在内存中,则分成若干个partition,写入磁盘的temporary segment,则会多一个写的代价,会降低效率。
这种方式适用于较小的表完全可以放于内存中的情况,这样总成本就是访问两个表的成本之和。但是在表很大的情况下并不能完全放入内存,这时优化器会将它分割成若干不同的分区,不能放入内存的部分就把该分区写入磁盘的临时段,此时要有较大的临时段从而尽量提高I/O 的性能。
可以用USE_HASH(table_name1 table_name2)提示来强制使用散列连接。
适用情况:
- Hash join在两个表的数据量差别很大的时候。
4.2 SORT MERGE JOIN(排序合并连接)
Merge Join 是先将关联表的关联列各自做排序,然后从各自的排序表中抽取数据,到另一个排序表中做匹配。
因为merge join需要做更多的排序,所以消耗的资源更多。 通常来讲,能够使用merge join的地方,hash join都可以发挥更好的性能,即散列连接的效果都比排序合并连接要好。然而如果行源已经被排过序,在执行排序合并连接时不需要再排序了,这时排序合并连接的性能会优于散列连接。
可以使用USE_MERGE(table_name1 table_name2)来强制使用排序合并连接.
适用情况:
- RBO模式;
- 不等价关联(>,<,>=,<=,<>);
- HASH_JOIN_ENABLED=false;
- 用在没有索引,并且数据已经排序的情况。
4.3 NESTED LOOP(嵌套循环连接)
Nested loops 工作方式是循环从一张表中读取数据(驱动表outer table),然后访问另一张表(被查找表 inner table,通常有索引)。驱动表中的每一行与inner表中的相应记录JOIN。类似一个嵌套的循环。
对于被连接的数据子集较小的情况,嵌套循环连接是个较好的选择。在嵌套循环中,内表被外表驱动,外表返回的每一行都要在内表中检索找到与它匹配的行,因此整个查询返回的结果集不能太大(大于1 万不适合),要把返回子集较小表的作为外表(CBO 默认外表是驱动表),而且在内表的连接字段上一定要有索引。当然也可以用ORDERED 提示来改变CBO默认的驱动表。
使用USE_NL(table_name1 table_name2)可是强制CBO 执行嵌套循环连接。
适用情况:
- 驱动表的记录集比较小(<10000)而且inner表需要有有效的访问方法(Index),并且索引选择性较好的时候;
- JOIN的顺序很重要,驱动表的记录集一定要小,返回结果集的响应时间是最快的。
5. 表访问方式
5.1 全表扫描(Full Table Scans, FTS)
全表扫描(Full Table Scans,又叫Table Access Full)是指Oracle在访问目标表里的数据时,会从该表所占用的第一个区(EXTENT)的第一个块(BLOCK)开始扫描,一直扫描到该表的高水位线(HWM,High Water Mark),Oracle会对这期间读到的所有数据施加目标SQL的where条件中指定的过滤条件,最后只返回那些满足过滤条件的数据。
不是说全表扫描不好,事实上Oracle在做全表扫描操作时会使用多块读,ORACLE采用一次读入多个数据块 (database block)的方式优化全表扫描,而不是只读取一个数据块,这极大的减少了I/O总次数,提高了系统的吞吐量,所以利用多块读的方法可以十分高效地实现全表扫描。这在目标表的数据量不大时执行效率是非常高的,但全表扫描最大的问题就在于走全表扫描的目标SQL的执行时间会不稳定、不可控,这个执行时间一定会随着目标表数据量的递增而递增。因为随着目标表数据量的递增,它的高水位线会一直不断往上涨,所以全表扫描该表时所需要读取的数据块的数量也会不断增加,这意味着全表扫描该表时所需要耗费的I/O资源会随之不断增加,当然完成对该表的全表扫描操作所需要耗费的时间也会随之增加。
在Oracle中,如果对目标表不停地插入数据,当分配给该表的现有空间不足时高水位线就会向上移动,但如果你用DELETE语句从该表删除数据, 则高水位线并不会随之往下移动(这在某种程度上契合了"高水位线"的定义,就好比水库的水位,当水库涨水时,水位会往上移,当水库放水后,曾经的最高水位 的痕迹还是会清晰可见)。高水位线的这种特性所带来的副作用是,即使使用DELETE语句删光了目标表中的所有数据,高水位线还是会在原来的位置,这意味着全表扫描该表时Oracle还是需要扫描该表高水位线下的所有数据块,所以此时对该表的全表扫描操作所耗费的时间与之前相比并不会有明显的改观。
使用FTS的前提条件:在较大的表上不建议使用全表扫描,除非取出数据的比较多,超过总量的5% -- 10%,或你想使用并行查询功能时。
5.2 通过ROWID访问表(table access by ROWID)
ROWID是一个伪列,即是一个非用户定义的列,而又实际存储于数据库之中。每一个表都有一个ROWID列,一个ROWID值用于唯一确定数据库表中的的一条记录。因此通过ROWID 方式来访问数据也是 Oracle 数据库访问数据的实现方式之一。一般情况下,ROWID方式的访问一定以索引访问或用户指定ROWID作为先决条件,因为所有的索引访问方式最终都会转换为通过ROWID来访问数据记录。(注:index full scan 与index fast full scan除外)由于Oracle ROWID能够直接定位一条记录,因此使用ROWID方式来访问数据,极大提高数据的访问效率
ROWID扫描是指Oracle在访问目标表里的数据时,直接通过数据所在的ROWID去定位并访问这些数据。
从严格意义上来说,Oracle中的ROWID扫描有两层含义:一种是根据用户在SQL语句中输入的ROWID的值直接去访问对应的数据行记录;另外一种是先去访问相关的索引,然后根据访问索引后得到的ROWID再回表去访问对应的数据行记录。
对Oracle中的堆表而言,我们可以通过Oracle内置的ROWID伪列得到对应行记录所在的ROWID的值(注意,这个ROWID只是一个伪 列,在实际的表块中并不存在该列),然后我们还可以通过DBMS_ROWID包中的相关方法(dbms_rowid.rowid_object,dbms_rowid.rowid_relative_fno、dbms_rowid.rowid_block_number和 dbms_rowid.rowid_row_number)将上述ROWID伪列的值翻译成对应数据行的实际物理存储地址。
5.3 索引扫描
索引范围扫描(INDEX RANGE SCAN)
索引范围扫描(INDEX RANGE SCAN)适用于所有类型的B树索引,当扫描的对象是唯一性索引时,此时目标SQL的where条件一定是范围查询(谓词条件为 BETWEEN、<、>等);当扫描的对象是非唯一性索引时,对目标SQL的where条件没有限制(可以是等值查询,也可以是范围查询)。 索引范围扫描的结果可能会返回多条记录,其实这就是索引范围扫描中"范围"二字的本质含义。
索引唯一性扫描(INDEX UNIQUE SCAN)
索引唯一性扫描(INDEX UNIQUE SCAN)是针对唯一性索引(UNIQUE INDEX)的扫描,它仅仅适用于where条件里是等值查询的目标SQL。因为扫描的对象是唯一性索引,所以索引唯一性扫描的结果至多只会返回一条记录。
索引全扫描(INDEX FULL SCAN)
所谓的索引全扫描(INDEX FULL SCAN)就是指要扫描目标索引所有叶子块的所有索引行。这里需要注意的是,索引全扫描需要扫描目标索引的所有叶子块,但这并不意味着需要扫描该索引的所有分支块。在默认情况下,Oracle在做索引全扫描时只需要通过访问必要的分支块定位到位于该索引最左边的叶子块的第一行索引行,就可以利用该索引叶子块之间的双向指针链表,从左至右依次顺序扫描该索引所有叶子块的所有索引行了。
索引快速全扫描(INDEX FAST FULL SCAN)
索引快速全扫描(INDEX FAST FULL SCAN)和索引全扫描(INDEX FULL SCAN)极为类似,它也适用于所有类型的B树索引(包括唯一性索引和非唯一性索引)。和索引全扫描一样,索引快速全扫描也需要扫描目标索引所有叶子块的所有索引行。
索引快速全扫描与索引全扫描相比有如下三点区别。
(1)索引快速全扫描只适用于CBO。
(2)索引快速全扫描可以使用多块读,也可以并行执行。
(3)索引快速全扫描的执行结果不一定是有序的。这是因为索引快速全扫描时Oracle是根据索引行在磁盘上的物理存储顺序来扫描,而不是根据索引行的逻辑顺序来扫描的,所以扫描结果才不一定有序(对于单个索引叶子块中的索引行而言,其物理存储顺序和逻辑存储顺序一致;但对于物理存储位置相邻的索引叶子块而言,块与块之间索引行的物理存储顺序则不一定在逻辑上有序)。
索引跳跃式扫描(INDEX SKIP SCAN)
索引跳跃式扫描(INDEX SKIP SCAN)适用于所有类型的复合B树索引(包括唯一性索引和非唯一性索引),它使那些在where条件中没有对目标索引的前导列指定查询条件但同时又对该 索引的非前导列指定了查询条件的目标SQL依然可以用上该索引,这就像是在扫描该索引时跳过了它的前导列,直接从该索引的非前导列开始扫描一样(实际的执行过程并非如此),这也是索引跳跃式扫描中"跳跃"(SKIP)一词的含义。
为什么在where条件中没有对目标索引的前导列指定查询条件但Oracle依然可以用上该索引呢?这是因为Oracle帮你对该索引的前导列的所有distinct值做了遍历。
参考:
Oracle(一)执行计划的更多相关文章
- 怎样看懂Oracle的执行计划
怎样看懂Oracle的执行计划 一.什么是执行计划 An explain plan is a representation of the access path that is taken when ...
- 【ORACLE】记录通过执行Oracle的执行计划查询SQL脚本中的效率问题
记录通过执行Oracle的执行计划查询SQL脚本中的效率问题 问题现象: STARiBOSS5.8.1R2版本中,河北对帐JOB执行时,无法生成发票对帐文件. 首先,Quartz表达式培植的启 ...
- (转)Oracle定时执行计划任务
Oracle定时执行计划任务 在日常工作中,往往有些事情是需要经常重复地做的,例如每天更新业务报表.每天从数据库中提取符合条件的数据.每天将客户关系管理系统中的数据分配给员工做数据库营销……因此我们就 ...
- Oracle的执行计划(来自百度文库)
如何开启oracle执行计划 http://wenku.baidu.com/view/7d1ff6bc960590c69ec37636.html怎样看懂Oracle的执行计划 http://wenku ...
- Oracle sql执行计划解析
Oracle sql执行计划解析 https://blog.csdn.net/xybelieve1990/article/details/50562963 Oracle优化器 Oracle的优化器共有 ...
- 分析oracle的执行计划(explain plan)并对对sql进行优化实践
基于oracle的应用系统很多性能问题,是由应用系统sql性能低劣引起的,所以,sql的性能优化很重要,分析与优化sql的性能我们一般通过查看该sql的执行计划,本文就如何看懂执行计划,以及如何通过分 ...
- oracle sql 执行计划分析
转自http://itindex.net/detail/45962-oracle-sql-%E8%AE%A1%E5%88%92 一.首先创建表 SQL> show user USER is &q ...
- Oracle 11g 执行计划管理1
1. 执行计划管理的工作原理 1.1控制执行计划的稳定性 11g之前,可以使用存储大纲(stored outline)和SQL Profile来固定某条SQL语句的执行计划,防止由于执行计划发生变化而 ...
- oracle稳定执行计划1
稳定执行计划 1 策略: Oracle的sql 执行计划在一些场景下会发生变化,导致系统会发生不可知的情况,影响系统的稳定性,特别是关键业务的sql. 比如下面的场景: 统计信息过老,重新收集了统计信 ...
- Oracle 查看执行计划
刚刚开始接触Oracle,使用的工具是Sql Developer.在看执行计划的的时候,选中SQL语句,直接F5即可. 但是这里的执行计划不是最终的执行计划,它使用的是 explain for 命令. ...
随机推荐
- mysql索引类型normal,unique,full text的区别
normal:表示普通索引 unique:表示唯一的,不允许重复的索引,如果该字段信息保证不会重复例如身份证号用作索引时,可设置为unique full textl: 表示 全文搜索的索引. FULL ...
- js设置光标插入文字和HTML
原文链接:js设置光标插入文字和HTML 在一个textarea的某个光标位置插入文字或者在某个编辑器中插入图片html内容,我最近经常和这些打交道,但总是一团模糊,今天整理一下关于如何插入文字,设置 ...
- js处理包含中文的字符串
场景: js中String类型自带的属性length获取的是字符串的字符数目,但是前端经常会需要限制字符串的显示长度,一个中文字符又大概占两个英文小写字符的显示位置,所以中英文混合的情况下用lengt ...
- CRM 安装过程 AD+SQL+CRM
AD: 通过服务器管理器添加域服务,配置域服务器域名为crm5.lab. 注意:使用高级模式安装. 说明:服务器是windows server 2003 那么就选windows server 2003 ...
- webapp开发绝对定位引发的问题
最近做了一个webapp 需求是要滑动页面翻页,我使用了大量绝对定位 当遇到输入框时,在部分手机上发现了问题.虚拟键盘收回时,整个body全部下移了,经过多次测试, 发现是fixed布局的音乐按钮造成 ...
- 安装android-sdk,gradle mac 篇
安装包管理器 Homebrew /usr/bin/ruby -e "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/insta ...
- leetCode Detect Capital
1.问题描述 Given a word, you need to judge whether the usage of capitals in it is right or not. We defin ...
- TestNG 判断文件下载成功
用WatchService写一个方法放在onTestStart()方法里监听文件夹的变化. 但是判断下载成功还需要写一个方法, 用来判断什么时候文件从.xlsx.rcdownload改成.xlsx才行 ...
- wopihost
项目介绍 基于wopi协议开发的WopiHost, 支持word, excel,ppt(仅支持预览)等文档的预览和编辑. 运行环境 需要安装Office online 2016才可以使用,基于jdk ...
- Linux查看磁盘读写
---------- 查看磁盘读写---------iostat -k 1 SQL> ho iostatLinux 2.6.32-279.el6.x86_64 (server-92) 08/1 ...