kafka系列 -- 基础概念
kafka是一个分布式的、分区化、可复制提交的发布订阅消息系统
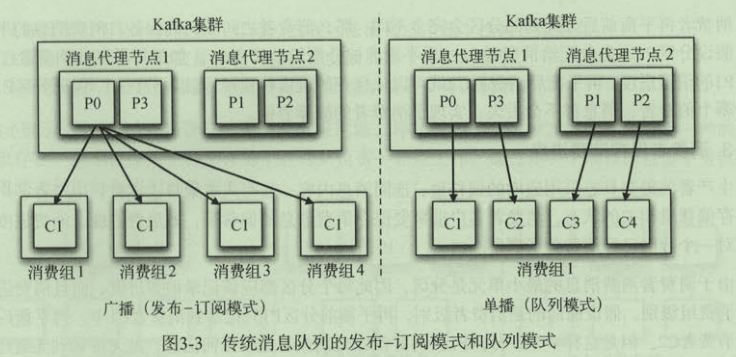
传统的消息传递方法包括两种:
- 排队:在队列中,一组用户可以从服务器中读取消息,每条消息都发送给其中一个人。
- 发布-订阅:在这个模型中,消息被广播给所有的用户。
kafka与传统的消息传递技术相比优势之处在于: - 快速:单一的Kafka代理可以处理成千上万的客户端,每秒处理数兆字节的读写操作。
- 可伸缩:在一组机器上对数据进行分区和简化,以支持更大的数据
- 持久:消息是持久性的,并在集群中进行复制,以防止数据丢失。
- 设计:它提供了容错保证和持久性
基本概念
- Topic(话题):Kafka中用于区分不同类别信息的类别名称。由producer指定
- Producer(生产者):将消息发布到Kafka特定的Topic的对象(过程)
- Consumers(消费者):订阅并处理特定的Topic中的消息的对象(过程)
- Broker(Kafka服务集群):已发布的消息保存在一组服务器中,称之为Kafka集群。集群中的每一个服务器都是一个代理(Broker). 消费者可以订阅一个或多个话题,并从Broker拉数据,从而消费这些已发布的消息。
- Partition(分区):Topic物理上的分组,一个topic可以分为多个partition,每个partition是一个有序的队列。partition中的每条消息都会被分配一个有序的id(offset)
- Message:消息,是通信的基本单位,每个producer可以向一个topic(主题)发送一些消息。
Log(日志)
日志是一个只能增加的,完全按照时间排序的一系列记录。
我们可以给日志的末尾添加记录,并且可以从左到右读取日志记录。
每一条记录都指定了一个唯一的有一定顺序的日志记录编号。
每个日志文件都是“log entries”序列,每一个log entry包含一个4字节整型数(值为N),其后跟N个字节的消息体。每条消息都有一个当前partition下唯一的64字节的offset,它指明了这条消息的起始位置
这个“log entries”并非由一个文件构成,而是分成多个segment,每个segment名为该segment第一条消息的offset和“.kafka”组成。另外会有一个索引文件,它标明了每个segment下包含的log entry的offset范围。
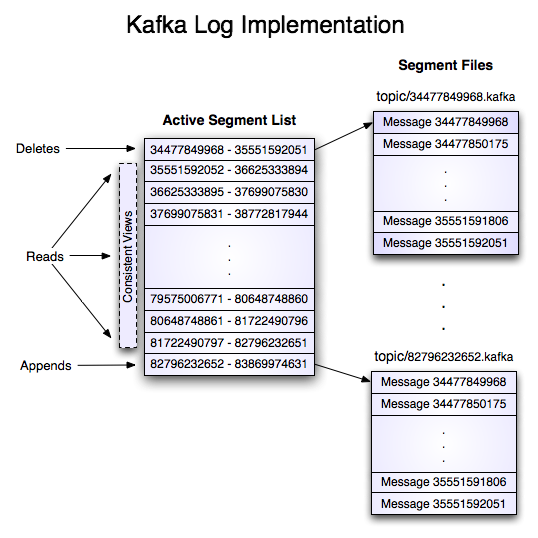
Topic & Partition
谈到kafka的存储,就不得不提到分区。
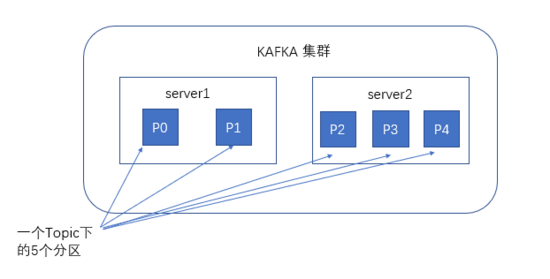
创建一个topic时,同时可以指定分区数目,分区数越多,其吞吐量也越大,但是需要的资源也越多,同时也会导致更高的不可用性,kafka在接收到生产者发送的消息之后,会根据均衡策略将消息存储到不同的分区中。
为了使得Kafka的吞吐率可以水平扩展,物理上把topic分成一个或多个partition,每个partition在物理上对应一个文件夹,该文件夹下存储这个partition的所有消息和索引文件。
消息以顺序存储:每一个分区都是一个顺序的、不可变的消息队列, 并且可以持续的添加,最晚接收的的消息会最后被消费。
分区中的消息都被分配了一个序列号,称之为偏移量(64字节的offset),在每个分区中此偏移量都是唯一的。
因为每条消息都被append到该partition中,是顺序写磁盘,因此效率非常高(经验证,顺序写磁盘效率比随机写内存还要高,这是Kafka高吞吐率的一个很重要的保证)
与生产者的交互
生产者在向kafka集群发送消息的时候,可以通过指定分区来发送到指定的分区中。
也可以通过指定均衡策略来将消息发送到不同的分区中。
如果不指定,就会采用默认的随机均衡策略,将消息随机的存储到不同的分区中。
每一条消息被发送到broker时,会根据paritition规则选择被存储到哪一个partition。
如果partition规则设置的合理,所有消息可以均匀分布到不同的partition里,这样就实现了水平扩展。(如果一个topic对应一个文件,那这个文件所在的机器I/O将会成为这个topic的性能瓶颈,而partition解决了这个问题)。
在发送一条消息时,可以指定这条消息的key,producer根据这个key和partition机制来判断将这条消息发送到哪个parition。
paritition机制可以通过指定producer的paritition. class这一参数来指定,该class必须实现kafka.producer.Partitioner接口。
本例中如果key可以被解析为整数则将对应的整数与partition总数取余,该消息会被发送到该数对应的partition。(每个parition都会有个序号)
与消费者交互
在消费者消费消息时,kafka使用offset来记录当前消费的位置。
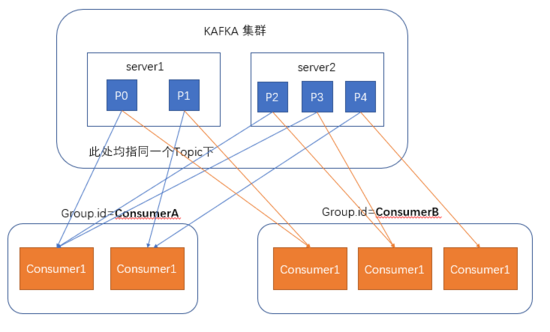
在kafka的设计中,可以有多个不同的group来同时消费同一个topic下的消息,
两个不同的group同时消费,他们消费的记录位置offset各不项目,不互相干扰。
对于一个group而言,消费者的数量不应该多于分区的数量,
因为每个分区被同一个group中的一个消费者所消费。所以:
- 一个消费者可以消费多个分区,但一个分区只能给同一个组的一个消费者消费。
- 同一个group下消费者对分区互斥,而不同消费组之间是共享的。
- 因此,若一个group中的消费者数量大于分区数量的话,多余的消费者将不会收到任何消息。
通过设置不同的消费者,可以实现传统的发布订阅模式和队列模式:
offset偏移量
- 在每个分区中此偏移量都是唯一的。
- 消费者所持有的仅有的元数据就是这个偏移量,也就是消费者在这个log中的位置。
- 偏移量由消费者控制。正常情况当消费者消费消息的时候,偏移量也线性的的增加。消费者可以将偏移量重置为更老的一个偏移量,重新读取消息。
- 一个消费者的操作不会影响其它消费者对此log的处理
- 一个topic中有100条数据,我消费了50条并且提交了,那么此时的kafka服务端记录提交的offset就是49(offset从0开始),那么下次消费的时候offset就从50开始消费。
手动控制Offest
首先了解一下消息传递保证:
- At most once 最多一次 --- 消息可能丢失,但绝不会重发。
- At least once 至少一次 --- 消息绝不会丢失,但有可能重新发送。
- Exactly once 正好一次 --- 这是人们真正想要的,每个消息传递一次且仅一次。
自动提交是在kafka拉取到数据完就直接提交数据偏移量。
而业务系统中,消费数据还伴随着一些逻辑业务处理,插入数据库等。
这事务过程,需要完成才提交。不然还没插进数据库,新的数据又来了。
加入插入数据库还失败了,就没法再消费一次失败的数据了。
所以要严格的不丢数据,需要手动控制offest。
- 手动commit offset,并针对partition_num启同样数目的consumer进程,这样就能保证一个consumer进程占有一个partition,commit offset的时候不会影响别的 partition 的 offset。但这个方法比较局限,因为partition和consumer进程的数目必须严格对应。
- 另一个方法同样需要手动commit offset,另外在consumer端再将所有fetch到的数据缓存到queue里,当把queue里所有的数据处理完之后,再批量提交offset,这样就能保证只有处理完的数据才被commit。
官网还说:
手动控制offest让我们能精确控制消息被消费(实现 提交了offest的不再消费,没提交过offest的数据会再次消费)。
但这一过程可能在 数据插入数据库后,但是还没commit offset到kafka时 失败了;那么下一次消费将还是从上次消费的起点取到数据,会重复插入数据库,造成重复。
kafka提供的是 "at-least once delivery" 保证, 即可能有两次三次被消费(我们项目就是这样)。
at-least once还有一个问题:
加入一个分区中先后进来 1,2 两条数据。在进来1时,网络不好导致插入失败,然后进行重试机制后网络还是不行,如果不停程序继续消费,这时2数据进来时网络好了,对2插入成功,那么偏移量就偏到数据2了,将1数据覆盖了,这时就不会再插入1数据了。就没法保证只at-least once了,除非停掉消费者,但是停了的话,同一组的消费者还会继续消费,这时又要实际到使用 assign模式还是subscribe模式订阅消息了。
kafka系列 -- 基础概念的更多相关文章
- WCF系列 基础概念
WCF全称Windows Communication Foundation,是微软构建面向服务的分布式编程框架.而它其实是统一了COM和.Net Remoting等分布式技术提供一个完整,通用,可靠的 ...
- MongoDB入门系列(一):基础概念和安装
概述 MongoDB是目前非常流行的一种非关系型数据库,作为入门系列的第一篇本篇文章主要介绍Mongdb的基础概念知识包括命名规则.数据类型.功能以及安装等. 环境: OS:Windows Versi ...
- .NET技术面试题系列(1) 基础概念
这是.NET技术面试题系列第一篇,今天主要分享基础概念. 1.简述 private. protected. public.internal 修饰符的访问权限 private : 私有成员, 在类的内部 ...
- Spring Cloud Security OAuth2.0 认证授权系列(一) 基础概念
世界上最快的捷径,就是脚踏实地,本文已收录[架构技术专栏]关注这个喜欢分享的地方. 前序 最近想搞下基于Spring Cloud的认证授权平台,总体想法是可以对服务间授权,想做一个基于Agent 的无 ...
- 快速入门系列--WCF--01基础概念
转眼微软的WCF已走过十个年头,它是微软通信框架的集大成者,将之前微软所有的通信框架进行了整合,提供了统一的应用方式.记得从自己最开始做MFC时,就使用过Named Pipe命名管道,之后做Winfo ...
- 理解 angular2 基础概念和结构 ----angular2系列(二)
前言: angular2官方将框架按以下结构划分: Module Component Template Metadata Data Binding Directive Service Dependen ...
- 关系型数据库基础概念:MySQL系列之开篇
一.基础概念 数据(Data)是描述事物的符号记录,是指利用物理符号记录下来的.可以鉴别的信息. 1.数据库(Database,DB)是指长期储存在计算机中的有组织的.可共享的数据集合.数据要按照一定 ...
- 【Machine Learning】机器学习及其基础概念简介
机器学习及其基础概念简介 作者:白宁超 2016年12月23日21:24:51 摘要:随着机器学习和深度学习的热潮,各种图书层出不穷.然而多数是基础理论知识介绍,缺乏实现的深入理解.本系列文章是作者结 ...
- iOS系列 基础篇 07 Action动作和输出口
iOS系列 基础篇 07 Action动作和输出口 目录: 1. 前言及案例说明 2. 什么是动作? 3. 什么是输出口? 4. 实战 5. 结尾 1. 前言及案例说明 上篇内容我们学习了标签和按钮 ...
随机推荐
- 18.OGNL与ValueStack(VS)-值栈入门
转自:https://wenku.baidu.com/view/84fa86ae360cba1aa911da02.html 下面我们建立struts2ognl项目来练习ognl的使用. 步骤一.搭建s ...
- java ee7 -- Java Bean验证
针对对象.对象成员.方法.构造函数的数据验证. 1. 一个验证的小例子 (1) 添加引用jar <dependency> <groupId>org.hibernate.vali ...
- 可视化库-seaborn-单变量绘图(第五天)
1. sns.distplot 画直方图 import numpy as np import pandas as pd from scipy import stats, integrate impor ...
- 前端-javascript-DOM(重点)文档对象模型
1.DOM概念-文档对象模型 // 什么是DOM ? /* Document Object Model 文档对象模型 面向对象: 三个特性 封装 继承 多态 一个对象: 属性和方法 说 万事万物皆对象 ...
- ABAP-HTTP支持
ABAP 中对HTTP的支持 SAP Web Application Server -> Internet Communication Framework. http://help.sap.c ...
- Haskell语言学习笔记(67)Gtk2Hs
Gtk2Hs $ brew cask install xquartz $ brew install glib cairo gtk gettext fontconfig freetype $ expor ...
- hibernate中1对1的注解配置
hibernate中1对1的注解配置分为:外键关联映射和主键关联映射 1.外键配置 //一方@Entity@Table(name="test_classinfo")public c ...
- Ansible Playbook Variables
虽然自动化存在使得更容易使事情重复,但所有的系统可能不完全一样. 在某些系统上,您可能需要设置一些与其他操作略有不同的行为或配置. 此外,一些观察到的远程系统的行为或状态可能需要影响如何配置这些系统. ...
- intellij idea 的安装与简单使用
1.将安装包拷贝到指定目录,特别注意不要有中文路径和空格,路径不要太深 2.点击安装(如果是win10系统要使用管理员权限安装) 3. 4.修改默认安装目录:一般来说我们都不要把软件安装在 ...
- Django入门-简单的登录
1.登录页面 2.项目目录结构 3.需要修改四个文件 urls.py-------路径与函数之间的对应关系 views.py-------函数定义与逻辑处理 加入一个login.html文件 ...