Storm Trident状态
Trident中有对状态数据进行读取和写入操作的一流抽象工具。状态既可以保存在拓扑内部,比如保存在内容中并由HDFS存储,也可以通过外部存储(比如Memcached或Cassandra)存储在数据库中。而对于Trident的API而言,这两种机制没有任何区别。
Trident以容错的方式来管理状态,当遇到重试或则错误时状态的更新是幂等的,在数据统计分析中,幂等性是一个很重要的指标,因为它可以保证即使数据被处理了多次,但是站在结果的角度看和处理一次完全一样。
我们来看一个例子,假定你正在对一个流做计数处理,并把计算结果写入到数据库。如果在数据库中使用一个值来表示这个计数,然后每处理一个tuple,就将这个计数值加1.当错误发生时,tuple会被重新处理。这就引发了一个问题,当进行状态更新时,你完全不知道事前是否已经处理成功这个tuple。这样就可能导致,原来处理过的tuple在这里对应的存储计数值任然加了1。
当然,若数据库中值存一个计数的话,是区分不出来这个tuple之前是否被正确处理的,这就需要更多的信息来支持。Trident提供了下面几个原语来实现只处理一次的语义。
1.tuples是被分成一组组小的集合来处理的。
2.每一个batch会给分配一个唯一的id(事物id,txid),当batch被重新处理时,txid是不变的
3.batch之间的状态更新是严格有序的,就是说batch2没有处理万的情况下batch3绝对不会被处理
有了这些原语就,在处理状态更新的时候就能知道这个batch之前有没有被处理过。然后采取合适的操作即可。下面我们看看每一种Spout类型都支持什么样的容错级别。
事务性Spout
Trident是以batch的方式来处理tuple的,同时每个batch会分配一个唯一的transaction id,Spout的特性根据他们所提供容错性保证机制来决定的,而且这种机制也会对每个批次发生作用。事务型Spout有如下特性:
1.一个batch无论被重发多少次,只有一个唯一且相同的事物id,同事所包含的tuple都是完全一致的
2.每个tuple必须且至多属于一个batch
事务性Spout很容易理解,但是在极端的情况下也会有一些问题。假设一批消息在被Bolt消费的过程中失败了,需要Spout重发,这时,如果刚好消息发送的中间件故障,Spout为了保证重发的时候每个batch包含的tuple一致,就智能等待消息中间件恢复了,整个处理就这样阻塞了。
来看一个例子
设计一个计算WordCount的Topology,将单词的出现的次数以KV的形式存储到数据库中。Key就是单词,V 对应单词出现的次数。可以将Value和事物ID一起存储到数据库中。每次更新Value前,先将当前的事物ID和数据库中存储的事物ID进行比较。如果一样就忽略,否则执行存储操作。例如下面的一个batch
- batch(事物ID为3)
- .["man"]
- .["man"]
- .["dog"]
数据库中保存的信息如下:
- .man => [count=,txid=]
- .dog => [count=,txid=]
- .apple => [count=,txid=]
单词"man"对应的txid为3,而当前的txid为1,可以确定没有为这个batch中的tuple更新过这个单词的数量,所以直接更新txid为3,而dog对应的txid和当前的txid相同忽略更新,单词apple保持不变,更新后的数据如下:
- 1.man => [count=,txid=]
- .dog => [count=,txid=]
- .apple => [count=,txid=]
不透明事务性Spout
不透明事务型Spout不能保证相同txid对应的批次中的元组数据完全一致,有一下特性
tuple只在一个batch中被成功处理,如果tuple在一个batch中被处理失败,有可能会在另一个batch中被成功处理。也就是说一个tuple第一次在txid为2的batch中出现,以后有可能在txid为4的batch中再次出现。
不透明事务性Spout有很好的容错性,但是需要额外的存储空间。出了Value和txid,你还需要在数据库中存储之前的数据,我们还以数据库中存储计数为例。假设当前数据库中存储的信息如下:
- {
- value=,
- preValue=,
- txid=
- }
下一次batch的txid为3,计数值为2,和数据库中的txid不同这种情况下将value中的值放入到preValue中,新增的值加到Value上去,更新后的数据库信息如下:
- {
- value=,
- preValue=,
- txid=
- }
如果当前batch的txid任然为2,与数据库中存储的相同,怎么操作呢?我们知道,数据库中的value值是通过与这次的txid相同的上个batch更新而来的,但是batch可能已经变化了所以我们要忽略它,这种情况下需要做的就是更新value的值为prevalue加上本次的batch值,结果应该是这样的
- {
- value=,
- preValue=,
- txid=
- }
此方式的正确定是基于Trident保证了batch的强顺序性。Trident处理一个batch时,一定不会重复或则回溯到之前的batch。每个tuple只会在一个batch中被成功处理,所以更新是原子的。
非事物型Spout
非事务型Spout不能为批次提供任何保证。所以可能出现”至多一次”的处理,即在某个批次处理过程中失败了,但是不会在重新处理;也可能提供“至少一次”的处理,即可能会有多个批次分别处理某个元组。也就是没有办法实现“恰好一次”的语义。
Spout和State类型小结
下面是不同的spout/状态组合是否支持“恰好一次”处理语义:
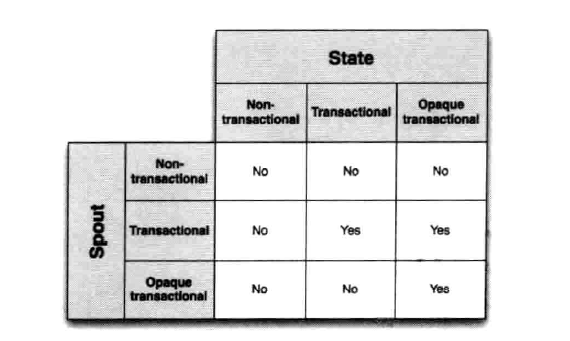
不透明事务状态有最强的容错性,但是因为存储txid和两个结果带来更大的开销。事务型状态只需要存储一个状态结果,但是只对事务型Spout有效。非事务型状态要求存储的数据更少,但是不能实现“恰好一次”的处理语义。所以在选择容错与存储空间中,需要根据具体的需要选择合适的组合。
Storm Trident状态的更多相关文章
- storm trident 示例
Storm Trident的核心数据模型是一批一批被处理的“流”,“流”在集群的分区在集群的节点上,对“流”的操作也是并行的在每个分区上进行. Trident有五种对“流”的操作: 1. 不 ...
- Storm Trident API
在Storm Trident中有五种操作类型 Apply Locally:本地操作,所有操作应用在本地节点数据上,不会产生网络传输 Repartitioning:数据流重定向,单纯的改变数据流向,不会 ...
- Storm专题二:Storm Trident API 使用具体解释
一.概述 Storm Trident中的核心数据模型就是"Stream",也就是说,Storm Trident处理的是Stream.可是实际上Stream是被成批处理的. ...
- storm trident merger
import java.util.List; import backtype.storm.Config; import backtype.storm.LocalCluster; import back ...
- storm trident的filter和函数
目的:通过kafka输出的信息进行过滤,添加指定的字段后,进行打印 SentenceSpout: package Trident; import java.util.HashMap; import j ...
- storm trident function函数
package cn.crxy.trident; import java.util.List; import backtype.storm.Config; import backtype.storm. ...
- Strom-7 Storm Trident 详细介绍
一.概要 1.1 Storm(简介) Storm是一个实时的可靠地分布式流计算框架. 具体就不多说了,举个例子,它的一个典型的大数据实时计算应用场景:从Kafka消息队列读取消息( ...
- Storm入门(十三)Storm Trident 教程
转自:http://blog.csdn.net/derekjiang/article/details/9126185 英文原址:https://github.com/nathanmarz/storm/ ...
- Storm Trident详解
Trident是基于Storm进行实时留处理的高级抽象,提供了对实时流4的聚集,投影,过滤等操作,从而大大减少了开发Storm程序的工作量.Trident还提供了针对数据库或则其他持久化存储的有状态的 ...
随机推荐
- 谈谈我对Ui设计师的一些观点
做ui设计师3年多了,对ui设计师在工作中也了解了许多. 作为UI设计师,在工作中需要清楚了解设计的目的,尤其是你做的不是大众化产品,不能以个人认知.很强的主题性来确定. 例如针对儿童人群的app时, ...
- win8 app code中设置Resources里定义好的Style
WPF中应该可以用这个: rectangle.Style = (Style)FindResource("FormLabelStyle"); 但 Win8.1 App是个精简框架,F ...
- 项目管理心得:一个项目经理的个人体会、经验总结(zz)
本人做项目经理工作多年,感到做这个工作最要紧的就是要明白什么是因地制宜.因势利导,只有最合适的,没有什么叫对的,什么叫错的,项目经理最忌讳 的就是完美主义倾向,尤其是做技术人员出身的,喜欢寻找标准答案 ...
- 解决启动nginx时报80端口被占用的问题
如何解决启动nginx时报80端口被占用 最近公司的的一个服务器上需要部署多个项目,但80端口只有一个,所有只有使用Nginx来代理,当访问域名时就可以自动 转到IP:端口号,而不需要在域名后面加端口 ...
- 2018.09.16 spoj104Highways (矩阵树定理)
传送门 第一次写矩阵树定理. 就是度数矩阵减去邻接矩阵之后得到的基尔霍夫矩阵的余子式的行列式值. 这个可以用高斯消元O(n3)" role="presentation" ...
- <%@ include file=""%>与<jsp:include page=""/>
https://www.cnblogs.com/sharpest/p/6117629.html
- Hadoop分布式远程Debug方式
1.进入目录修改配置文件 cd /cloud/hadoop-2.2.0/etc/hadoop vim hadoop-env.sh2.加入内容(文本最后): #远程调试NameNode export H ...
- 3) Maven 目录结构
进入maven根目录 cmd 命令 tree E:. │ LICENSE.txt │ NOTICE.txt │ README.txt │ ├─bin │ m2.conf │ mvn │ mvn.bat ...
- ubuntu 14.04查看java的安装路径
有时候,使用apt-get install 安装了某个软件之后,却不知道这个软件的安装路径在哪里. 那怎么样去找出这个软件的安装路径呢? 下面我们java 这个软件为例, 找出ubuntu 14.04 ...
- PAT 甲 1005. Spell It Right (20) 2016-09-09 22:53 42人阅读 评论(0) 收藏
1005. Spell It Right (20) 时间限制 400 ms 内存限制 65536 kB 代码长度限制 16000 B 判题程序 Standard 作者 CHEN, Yue Given ...