Kaggle(一):房价预测
Kaggle(一) 房价预测 (随机森林、岭回归、集成学习)
代码有不明白的 欢迎来微信公众号“他她自由行”找我,回复任何话都可以 我都会回你哒~
项目介绍:通过79个解释变量描述爱荷华州艾姆斯的住宅的各个方面,然后通过这些变量训练模型,
来预测房价。
kaggle项目链接:https://www.kaggle.com/c/house-prices-advanced-regression-techniques
数据描述:
train.csv - 训练集
test.csv - 测试集
一.加载数据
#加载必要库
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
#读取数据集
df_train=pd.read_csv('train.csv')
df_test=pd.read_csv('test.csv')
二.数据清洗
把train与test两个数据集合并到一起来处理79个解释变量,等用test来进行预测时就不需再次处理了。
df_train.shape,df_test.shape
y_train=df_train.pop('SalePrice') #删除并返回数据集中SalePrice标签列
all_df=pd.concat((df_train,df_test),axis=0) #要处理的整体数据集
total=all_df.isnull().sum().sort_values(ascending=False) #每列缺失数量
percent=(all_df.isnull().sum()/len(all_df)).sort_values(ascending=False) #每列缺失率
miss_data=pd.concat([total,percent],axis=1,keys=['total','percent'])
miss_data #显示每个列及其对应的缺失率
1.除去缺失率达40%以上的 (不除去的话,补齐数据误差偏大)
all_df=all_df.drop(miss_data[miss_data['percent']>0.4].index,axis=1) #去除了percent>0.4的列
2. 由于有些房子没有车库,造成车库相关的属性缺失,对于这种情况,我们有missing填充,同时对于车库建造时间的缺失,我们用1900填充,表示车库是年久的,使其变得不重要。
garage_obj=['GarageType','GarageFinish','GarageQual','GarageCond'] #列出车库这一类
for garage in garage_obj:
all_df[garage].fillna('missing',inplace=True)
#把1900标签填入空缺处表示年代久远
all_df['GarageYrBlt'].fillna(1900.,inplace=True)
3.装修类中,装修类型为空的表示没装修过,用missing表示;装修面积为0;
all_df['MasVnrType'].fillna('missing',inplace=True) #用missing标签表示没装修过
all_df['MasVnrArea'].fillna(0,inplace=True) #用0表示没装修过的装修面积
#再次查看数据缺失率,最高为0.16,是LotFrontage列
(all_df.isnull().sum()/len(all_df)).sort_values(ascending=False)
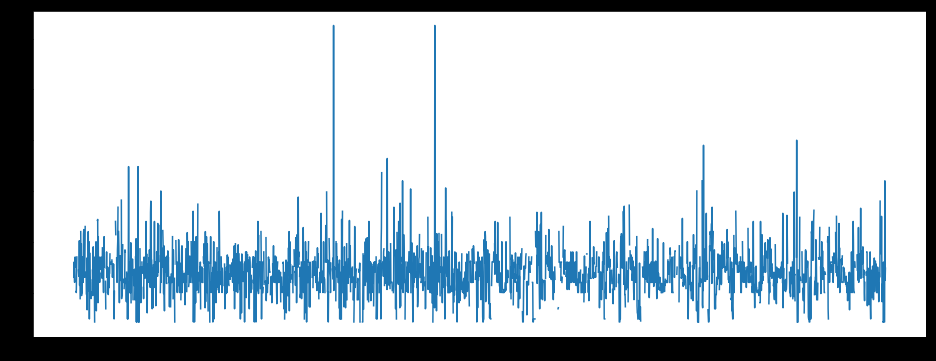
#从图中看出LotFrontage分布较均匀,可以用均值补齐缺失值
plt.figure(figsize=(16,6))
plt.plot(all_df['Id'],all_df['LotFrontage'])
图一:
#均值补齐LotFrontage列
all_df['LotFrontage'].fillna(all_df['LotFrontage'].mean(),inplace=True)
4.离散值进行one-hot处理
#还有部分少量的缺失值,不是很重要,可以用one-hotd转变离散值,然后均值补齐
all_dummies_df=pd.get_dummies(all_df)
mean_col=all_dummies_df.mean()
all_dummies_df.fillna(mean_col,inplace=True)
三.数值转换
找出类型为数值的所有列,进行标准化处理
#数据集中数值类型为int和float
all_dummies_df['Id']=all_dummies_df['Id'].astype(str) #先排除ID列,不对Id列进行处理
a=all_dummies_df.columns[all_dummies_df.dtypes=='int64'] #数值为int型
b=all_dummies_df.columns[all_dummies_df.dtypes=='float64'] #数值为float型
#进行标准化处理,符合0-1分布
a_mean=all_dummies_df.loc[:,a].mean()
a_std=all_dummies_df.loc[:,a].std()
all_dummies_df.loc[:,a]=(all_dummies_df.loc[:,a]-a_mean)/a_std #使数值型为int的所有列标准化
b_mean=all_dummies_df.loc[:,b].mean()
b_std=all_dummies_df.loc[:,b].std()
all_dummies_df.loc[:,b]=(all_dummies_df.loc[:,b]-b_mean)/b_std #使数值型为float的所有列标准化
最终处理完的数据集:
其中包含自己把train数据集中按0.8:0.2分为train_train和train_test俩数据集,来比较哪个模型能更好预测数据,然后再用来预测最终的test数据集。
#处理后的训练集(不含Saleprice)
df_train1=all_dummies_df.iloc[:1460,:]
df_train_train=df_train1.iloc[0:int(0.8*len(df_train1)),:] #train中的训练集(不含Saleprice)
df_train_test=df_train1.iloc[int(0.8*len(df_train1)):,:] #train中的测试集(不含Saleprice)
df_train_train_y=y_train.iloc[0:int(0.8*len(y_train))] #train中训练集的target
df_train_test_y=y_train.iloc[int(0.8*len(df_train1)):] #train中测试集的target
#处理后的测试集
df_test1=all_dummies_df.iloc[1460:,:]
四.建模
分析,显然是回归问题,本项目中解决回归问题的方法:岭回归、随机森林、集成学习
1.岭回归
这里要用的特征较多,适合岭回归进行建模,把所有特征放进去就行,无需进行特征选取
#加载相关库
from sklearn.linear_model import Ridge
from sklearn.model_selection import cross_val_score
#对岭回归的正则化度进行调参,用到k折交叉验证
alphas=np.logspace(-2,2,50)
test_scores1=[]
test_scores2=[]
for alpha in alphas:
clf=Ridge(alpha)
scores1=np.sqrt(cross_val_score(clf,df_train_train,df_train_train_y,cv=5))
scores2=np.sqrt(cross_val_score(clf,df_train_train,df_train_train_y,cv=10))
test_scores1.append(1-np.mean(scores1))
test_scores2.append(1-np.mean(scores2))
#从图中找出当正则化参数alpha为多少时,误差最小
%matplotlib inline
plt.plot(alphas,test_scores1,color='red') #交叉验证k为5时,误差最小
plt.plot(alphas,test_scores2,color='green')
图二
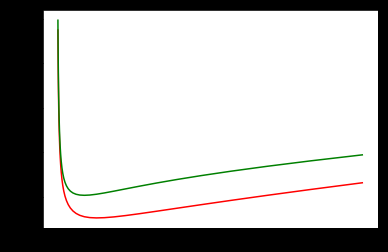
当alpha在0~10之间时,整体结构风险最小。(猜测可能在alpha=5时最小
训练好的岭回归对train_test进行预测,用误差平方和来衡量模型好坏
ridge=Ridge(alpha=5)
ridge.fit(df_train_train,df_train_train_y)
#用均方误差来判断模型好坏,结果越小越好
(((df_train_test_y-ridge.predict(df_train_test))**2).sum())/len(df_train_test_y)
Out[ ]:
1983899445.438339
2.随机森林
随机森林也可预测回归,对处理高维度效果较好,不要特征选择
#调参,对随机森林的最大特征选择进行调试 ,也需要用到交叉验证
from sklearn.ensemble import RandomForestRegressor
max_features=[.1,.2,.3,.4,.5,.6,.7,.8,.9]
test_score=[]
for max_feature in max_features:
clf=RandomForestRegressor(max_features=max_feature,n_estimators=100)
score=np.sqrt(cross_val_score(clf,df_train_train,df_train_train_y,cv=5))
test_score.append(1-np.mean(score))
plt.plot(max_features,test_score) #得出误差得分图
图三
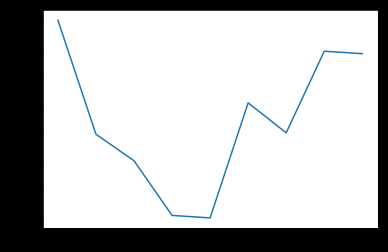
通过图可知,当max_features最大特征数为0.5时,误差最小,所以代入max_feature=0.5
训练好的随机森林对train_test进行预测,用误差平方和来衡量模型好坏
rf=RandomForestRegressor(max_features=0.5,n_estimators=100)
rf.fit(df_train_train,df_train_train_y)
#用均方误差来判断模型好坏,结果越小越好
(((df_train_test_y-rf.predict(df_train_test))**2).sum())/len(df_train_test_y)
Out[ ]:
1108361750.5652797
集成学习
用Bagging(bootstrap aggregatin)集成框架来对岭回归进行融合计算
调参1:寻找合适子模型数量
#加载相关库
from sklearn.ensemble import BaggingRegressor
#调参,寻找合适子模型数量
ridge=Ridge(5)
params=[10,20,30,40,50,60,70,80,90,100]
test_scores=[]
for param in params:
clf=BaggingRegressor(n_estimators=param,base_estimator=ridge)
score=np.sqrt(cross_val_score(clf,df_train_train,df_train_train_y,cv=5))
test_scores.append(1-np.mean(score))
plt.plot(params,test_scores)
图四
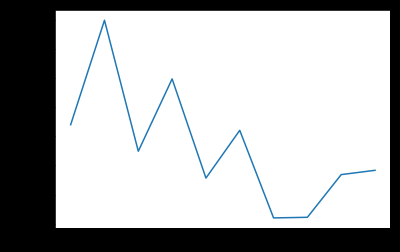
当训练的模型个数为70时,数据误差最小
调参2:寻找合适最大特征数
max_features=[.1,.2,.3,.4,.5,.6,.7,.8,.9]
test_scores=[]
for max_feature in max_features:
clf=BaggingRegressor(n_estimators=70,base_estimator=ridge,max_features=max_feature)
score=np.sqrt(cross_val_score(clf,df_train_train,df_train_train_y,cv=5))
test_scores.append(1-np.mean(score))
plt.plot(max_features,test_scores)
图五
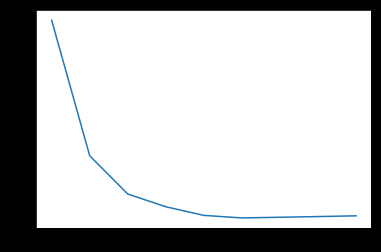
最大特征数为0.6时,误差最小
调参结束,进行模型检验
Bagging=BaggingRegressor(n_estimators=70,base_estimator=ridge,max_features=0.6)
Bagging.fit(df_train_train,df_train_train_y)
#用均方误差来判断模型好坏,结果越小越好
(((df_train_test_y-Bagging.predict(df_train_test))**2).sum())/len(df_train_test_y)
Out[ ]:
1960180964.6378567
结果:
分析结果:三个结果,取均方误差最小的,即 随机森林 算法
提交后,误差为0.1485
四千多中排名50%。还有很多可以优化的地方,等过段时间继续优化~
更详细代码:github https://github.com/xubin97/Data-Mining_exp2/tree/master
代码有不明白的 欢迎来微信公众号“他她自由行”找我,回复任何话都可以 我都会回你哒~
Kaggle(一):房价预测的更多相关文章
- Kaggle竞赛 —— 房价预测 (House Prices)
完整代码见kaggle kernel 或 Github 比赛页面:https://www.kaggle.com/c/house-prices-advanced-regression-technique ...
- 通过房价预测入门Kaggle
今天看了个新闻,说是中国社会科学院城市发展与环境研究所及社会科学文献出版社共同发布<房地产蓝皮书:中国房地产发展报告No.16(2019)>指出房价上涨7.6%,看得我都坐不住了,这房价上 ...
- 梯度消失、梯度爆炸以及Kaggle房价预测
梯度消失.梯度爆炸以及Kaggle房价预测 梯度消失和梯度爆炸 考虑到环境因素的其他问题 Kaggle房价预测 梯度消失和梯度爆炸 深度模型有关数值稳定性的典型问题是消失(vanishing)和爆炸( ...
- Ames房价预测特征工程
最近学人工智能,讲到了Kaggle上的一个竞赛任务,Ames房价预测.本文将描述一下数据预处理和特征工程所进行的操作,具体代码Click Me. 原始数据集共有特征81个,数值型特征38个,非数值型特 ...
- 动手学深度学习17-kaggle竞赛实践小项目房价预测
kaggle竞赛 获取和读取数据集 数据预处理 找出所有数值型的特征,然后标准化 处理离散值特征 转化为DNArray后续训练 训练模型 k折交叉验证 预测样本,并提交结果 kaggle竞赛 本节将动 ...
- 机器学习实战二:波士顿房价预测 Boston Housing
波士顿房价预测 Boston housing 这是一个波士顿房价预测的一个实战,上一次的Titantic是生存预测,其实本质上是一个分类问题,就是根据数据分为1或为0,这次的波士顿房价预测更像是预测一 ...
- 使用sklearn进行数据挖掘-房价预测(4)—数据预处理
在使用机器算法之前,我们先把数据做下预处理,先把特征和标签拆分出来 housing = strat_train_set.drop("median_house_value",axis ...
- 使用sklearn进行数据挖掘-房价预测(6)—模型调优
通过上一节的探索,我们会得到几个相对比较满意的模型,本节我们就对模型进行调优 网格搜索 列举出参数组合,直到找到比较满意的参数组合,这是一种调优方法,当然如果手动选择并一一进行实验这是一个十分繁琐的工 ...
- 使用sklearn进行数据挖掘-房价预测(1)
使用sklearn进行数据挖掘系列文章: 1.使用sklearn进行数据挖掘-房价预测(1) 2.使用sklearn进行数据挖掘-房价预测(2)-划分测试集 3.使用sklearn进行数据挖掘-房价预 ...
随机推荐
- 设计模式之状态模式(State Pattern)
一.什么是状态模式? 把所有动作都封装在状态对象中,状态持有者将行为委托给当前状态对象 也就是说,状态持有者(比如汽车,电视,ATM机都有多个状态)并不知道动作细节,状态持有者只关心自己当前所处的状态 ...
- 关于Java连接SQL Sever数据库
1.前提条件 需要: 1>本机上装有SQL Sever数据库(2005.2008或者更高版本) 2>eclipse或者myeclipse开发环境 3>jar文件(名为sql_jdbc ...
- WebAPI开发中的定时处理
https://blog.csdn.net/lordwish/article/details/77931897
- Layui 手册一
icon-图标 1:√2:×3:问号4:锁5:哭脸6:笑脸7:感叹号 使用layer.msg('',{ icon:1 }); 目前只提供7种图标可选,用的适当还是很好看的. 表格刷新 parent. ...
- 【Selenium专题】元素定位之一简单定位
UI自动化工具千变万化.架构千变万化,但都逃离不开的关键一步就是元素定位.下面以Selenium为例介绍常见的几个元素定位方法 ID -元素id属性 WebElement El = driver.fi ...
- log4j学习(一)最简单的例子
前言: 之前笔者一直是在System.out中打日志的,由于笔者大部分时候是编写在tomcat容器里运行的一些个小web应用,所以这么做似乎没什么问题:打印出来的日志都可以在tomcat自己的log目 ...
- kolla-ansible 源码下载
下载地址: https://pypi.org/project/kolla-ansible/ ansible下载: https://releases.ansible.com/ansible/rpm/re ...
- 世界线(bzoj2894)(广义后缀自动机)
由于春希对于第二世代操作的不熟练,所以刚使用完\(invasion process\)便掉落到了世界线之外,错综复杂的平行世界信息涌入到春希的意识中.春希明白了事件的真相. 在一个冬马与雪菜同时存在的 ...
- BZOJ 1008--[HNOI2008]越狱(容斥&快速幂)
1008: [HNOI2008]越狱 Time Limit: 1 Sec Memory Limit: 162 MBSubmit: 12593 Solved: 5439[Submit][Status ...
- (2)特征点匹配,并求旋转矩阵R和位移向量t
include头文件中有slamBase.h # pragma once // 各种头文件 // C++标准库 #include <fstream> #include <vector ...