网页解析:Xpath 与 BeautifulSoup
1. Xpath
2. BeautifulSoup
1. Xpath
1.1 Xpath 简介
什么是 Xpath
XPath 即为 XML 路径语言(XML Path Language),它是一种用来定位 XML 文档中某部分内容的所处位置的语言。
XPath 基于 XML 的树状结构,提供在数据结构树中找寻节点的能力。起初 XPath 提出的初衷是将其作为一个通用的、介于 XPointer 与 XSL 间的语法模型。但是 XPath 很快的被开发者采用来当作小型查询语言。
Xpath 解析网页的流程
- 首先通过 Requests 库获取网页数据;
- 通过网页解析,得到想要的数据或者新的链接;
- 网页解析可以通过 Xpath 或者其它解析工具进行,Xpath 是一个非常好用的网页解析工具。

常用的网页解析
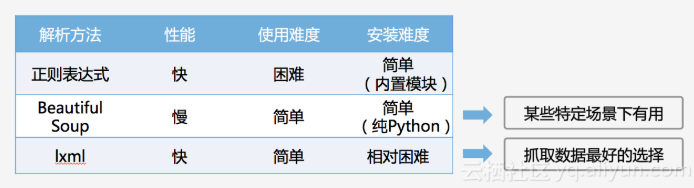
- 正则表达式:使用比较困难,学习成本较高。
- BeautifulSoup:性能较慢,相对于 Xpath 较难,在某些特定场景下有用。
- Xpath:使用简单,速度快(Xpath 是 lxml 里面的一种),是抓取数据最好的选择。
1.2 Xpath 使用
1)使用 Xpath 解析网页数据的步骤
- 从 lxml 导入 etree;
- 解析数据,返回 xml 结构;
- 使用 .xpath() 寻找和定位数据。
1 import requests
2 from lxml import etree
3 from fake_useragent import UserAgent # 伪装请求头的库
4
5 # 伪装请求头中的浏览器
6 ua = UserAgent()
7
8 url = "https://book.douban.com/subject/27147922/comments/"
9 # html数据,使用requests获取
10 # 写爬虫最实用的是可以随意变换headers,一定要有随机性。ua.random支持随机生成请求头
11 r = requests.get(url, headers={"User-Agent": ua.random}).text
12 # print(r)
13
14 # 解析html数据
15 s = etree.HTML(r)
16
17 # 使用.xpath()
18 print(s.xpath('//*[@id="comments"]/div[1]/ul/li[1]/div[2]/p/span'))
19 # [<Element span at 0x24ee3701a08>]
20
21 # 获取文本,加上/text()
22 print(s.xpath('//*[@id="comments"]/div[1]/ul/li[1]/div[2]/p/span/text()'))
23 # ['周而复始、如履薄冰的生活仍值得庆幸,因为无论是主动还是被动的脱轨,都可能导致万劫不复。吉根是描绘“日常灾难”的大师,所有绝望都薄如蝉翼,美得微妙。']
2)获取 Xpath 的方法
- 首先在浏览器上定位到需要爬取的数据;
- 右键,点击“检查”,在“Elements”下找到定位到所需数据;
- 右键——Copy——Copy Xpath,即可完成Xpath的复制。
- 获取文本内容用 text()。
- 获取注释用 comment()。
- 获取其它任何属性用@xx,如:src、value 等。
- 想要获取某个标签下所有的文本(包括子标签下的文本),使用 string。
- 如”< p>123< a>来获取我啊< /a>< /p>”,这边如果想要得到的文本为”123来获取我啊”,则需要使用 string。
- starts-with 匹配字符串前面相等。
- contains 匹配任何位置相等。

示例:
1 # 手写Xpath
2 import requests
3 from lxml import etree
4
5 url = 'https://book.douban.com/subject/1084336/comments/'
6 r = requests.get(url).text
7
8 s = etree.HTML(r)
9 print(s.xpath('//div[@class="comment"]/p/text()')[0])
3)案例:使用 Xpath 爬取豆瓣图书《小王子》短评网页
1 import requests
2 from lxml import etree
3 from fake_useragent import UserAgent # 伪装请求头的库
4
5 # 伪装请求头中的浏览器
6 ua = UserAgent()
7
8 url = 'https://book.douban.com/subject/1084336/comments/'
9 r = requests.get(url, headers={"User-Agent": ua.random}).text
10 s = etree.HTML(r)
11
12 # 从浏览器复制第一条评论的Xpath
13 print(s.xpath('//*[@id="comments"]/div[1]/ul/li[1]/div[2]/p/span/text()'))
14 # 从浏览器复制第二条评论的Xpath
15 print(s.xpath('//*[@id="comments"]/div[1]/ul/li[2]/div[2]/p/span/text()'))
16 # 从浏览器复制第三条评论的Xpath
17 print(s.xpath('//*[@id="comments"]/div[1]/ul/li[3]/div[2]/p/span/text()'))
18
19 # 掌握规律,删除li[]的括号,获取全部短评
20 # print(s.xpath('//*[@id="comments"]/div[1]/ul/li/div[2]/p/span/text()'))
21 # 手写Xpath获取全部短评
22 # print(s.xpath('//div[@class="comment"]/p/span/text()'))
执行效果:
['十几岁的时候渴慕着小王子,一天之间可以看四十四次日落。是在多久之后才明白,看四十四次日落的小王子,他有多么难过。']
['读了好多年,终于读完了,但是实在共鸣不起来,虽然知道那些道理,但真的觉得没什么了不起啊,是我还太幼稚吗?']
['我早该猜到,在她那可笑的伎俩后面是缱绻柔情啊。花朵是如此的天真无邪,可是,我毕竟太年轻了,不知该如何去爱她。']
总结:
通过对比可以发现从浏览器复制的 Xpath 中,“li[]”括号中的数字代表对应的第几条评论,直接删除括号,即可获取全部短评。
对于结构清晰的 html 网页,可以直接手写 Xpath,更加简洁且高效。
对于结构复杂的 html 网页,可以通过浏览器复制的方式获取 Xpath。
2. BeautifulSoup
2.1 BeautifulSoup 简介
BeautifulSoup 提供一些简单的、python 式的函数用来处理导航、搜索、修改分析树等功能。它是一个工具箱,通过解析文档为用户提供需要抓取的数据。
安装:pip install bs4
解析 HTML 文档:
soup = BeautifulSoup(html_doc, 'html.parser')
- html_doc:文档名称
- "html_parser":解析网页所需的解析器
用 soup.prettify 更友好地打印网页:
print(soup.prettify())
常用属性:
- soup.title:返回 title 部分的全部内容:<title>The Dormouse's story</title>
- soup.title.name:返回 title 标签的名称( name 标签):'title'
- soup.title.string:返回这个标签的内容:"The Dormouse's story"
- soup.find_all('a'):返回所有超链接的元素如下:
<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>,
<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>,
<a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]
- soup.find(id="link3"):返回 id=link3 部分的内容,如下:
<a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]
2.2 BeautifulSoup 使用案例
1)爬取“NATIONAL WEATHER”的天气数据
1 import requests
2 from bs4 import BeautifulSoup
3
4
5 # 通过requests来获取我们需要爬取的网页
6 weather_url = 'http://forecast.weather.gov/MapClick.php?lat=37.77492773500046&lon=-122.41941932299972'
7 try:
8 # 调用get函数对请求的url返回一个response对象
9 web_page = requests.get(weather_url).text
10 except Exception as e:
11 print('Error code:', e.code)
12
13 # 通过BeautifulSoup解析和获取已爬取的网页内容
14 soup = BeautifulSoup(web_page, 'html.parser')
15 soup_forecast = soup.find(id='seven-day-forecast-container')
16
17 # 找到所需要部分的内容
18 date_list = soup_forecast.find_all(class_='period-name')
19 desc_list = soup_forecast.find_all(class_='short-desc')
20 temp_list = soup_forecast.find_all(class_='temp')
21
22 # 将获取的内容更好地打印出来
23 for i in range(9):
24 date = date_list[i].get_text()
25 desc = desc_list[i].get_text()
26 temp = temp_list[i].get_text()
27 print('{} - {} - {}'.format(date, desc, temp))
执行效果:
Today - DecreasingClouds - High: 62 °F
Tonight - Mostly Clear - Low: 49 °F
Monday - Sunny - High: 70 °F
MondayNight - Mostly Clear - Low: 48 °F
Tuesday - Sunny - High: 68 °F
TuesdayNight - Mostly Clear - Low: 46 °F
Wednesday - Mostly Sunny - High: 64 °F
WednesdayNight - Mostly Clear - Low: 47 °F
Thursday - Sunny - High: 62 °F
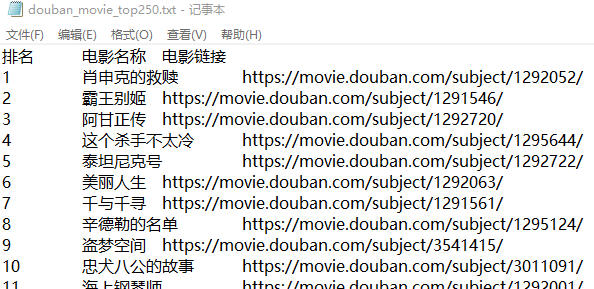
2)爬取豆瓣电影 TOP 250 的电影名与链接
1 import requests
2 from bs4 import BeautifulSoup
3 from fake_useragent import UserAgent # 伪装请求头的库
4
5 ua = UserAgent()
6
7 movie_top250 = 'https://movie.douban.com/top250?start={}'
8
9 with open('C:\\Users\\juno\\Desktop\\douban_movie_top250.txt', 'w') as file:
10 file.write('排名\t电影名称\t电影链接\n')
11
12 # 每页展示25部电影,因此需要遍历10页
13 for i in range(10):
14 start = i * 25
15 visit_url = movie_top250.format(start)
16 crawler_content = requests.get(visit_url, headers={"User-Agent": ua.random}).text
17
18 soup = BeautifulSoup(crawler_content, 'html.parser')
19
20 all_pic_divs = soup.find_all(class_='pic')
21 for index, each_pic_div in enumerate(all_pic_divs):
22 movie_name = each_pic_div.find('img')['alt']
23 movie_href = each_pic_div.find('a')['href']
24
25 print('{}\t{}\t{}\n'.format(index+1+start, movie_name, movie_href))
26 file.write('{}\t{}\t{}\n'.format(index+1+start, movie_name, movie_href))
执行效果:
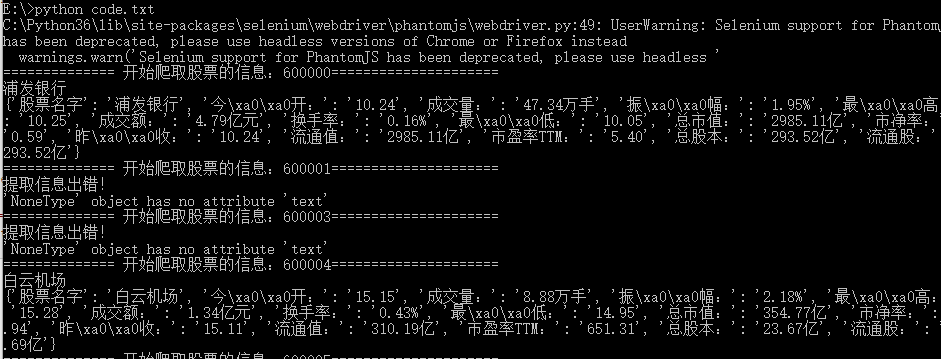
3)爬取股票信息
1 import requests
2 import re
3 from selenium import webdriver
4 from bs4 import BeautifulSoup
5 import time
6 import json
7
8
9 # 通过正则,从股票列表页面,获取所有的股票编号
10 def get_stock_no_list(url):
11 r = requests.get(url)
12 html = r.text
13 # print(html)
14 stock_codes = re.findall(r'php\?stockcode=(\d+)"', html)
15 return stock_codes
16
17 # print(get_stock_no_list(url))
18
19 # 使用无头浏览器获取页面js执行后的源码
20 def get_page_souce(driver, url):
21 driver.get(url)
22 html = driver.page_source
23 return html
24
25 # 用bs4把信息提取出来,保存到文件中,
26 def save_stock_info_to_file(html, file_path):
27 infoDict = {}
28 if html=="":
29 return None
30 soup = BeautifulSoup(html, 'html.parser')
31 # 通过find方法,使用h1标签和id属性,确定h1这个元素,在用find(i)找到它下面的i元素,
32 # 再用.text,取到i元素的文本---》股票名字
33 try:
34 print(soup.find("h1", attrs={'id':"stockName"}).find("i").text)
35 stock_name = soup.find("h1", attrs={'id':"stockName"}).find("i").text
36 infoDict["股票名字"]= stock_name
37 ths = soup.find("div", attrs={'id':"hqDetails"}).find_all("th")
38 tds = soup.find("div", attrs={'id':"hqDetails"}).find_all("td")
39 for i in range(len(ths)):
40 key = ths[i].text
41 value = tds[i].text
42 infoDict[key]=value
43 print(infoDict)
44 with open(file_path, "a", errors="ignore") as fp:
45 fp.write(json.dumps(infoDict, ensure_ascii=False))
46 except Exception as e:
47 print("提取信息出错!")
48 print(e)
49
50 # 股票列表的网址
51 stock_list_url = 'http://www.bestopview.com/stocklist.html'
52 # 股票详情页面网址
53 url = "http://finance.sina.com.cn/realstock/company/sh600121/nc.shtml"
54 # 浏览器所在位置
55 path = r'E:\phantomjs\bin\phantomjs.exe'
56 # 启动一个无头浏览器
57 driver = webdriver.PhantomJS(path)
58
59 # 获取指定网址的源码
60 # print(get_page_souce(driver, url))
61 stock_list = get_stock_no_list(stock_list_url)
62 for stock_no in stock_list[:20]:
63 stock_info_url = "http://finance.sina.com.cn/realstock/company/sh%s/nc.shtml" %stock_no
64 html = get_page_souce(driver, stock_info_url)
65 print("============== 开始爬取股票的信息:%s=====================" %stock_no)
66 save_stock_info_to_file(html, "e:\\stock_info.txt")
执行效果:
网页解析:Xpath 与 BeautifulSoup的更多相关文章
- 第6章 网页解析器和BeautifulSoup第三方插件
第一节 网页解析器简介作用:从网页中提取有价值数据的工具python有哪几种网页解析器?其实就是解析HTML页面正则表达式:模糊匹配结构化解析-DOM树:html.parserBeautiful So ...
- 3 爬虫解析 Xpath 和 BeautifulSoup
1.正则表达式 单字符: . : 除换行以外所有字符 [] :[aoe] [a-w] 匹配集合中任意一个字符 \d :数字 [-] \D : 非数字 \w :数字.字母.下划线.中文 \W : 非\w ...
- 转:Python网页解析:BeautifulSoup vs lxml.html
转自:http://www.cnblogs.com/rzhang/archive/2011/12/29/python-html-parsing.html Python里常用的网页解析库有Beautif ...
- 关于爬虫中常见的两个网页解析工具的分析 —— lxml / xpath 与 bs4 / BeautifulSoup
http://www.cnblogs.com/binye-typing/p/6656595.html 读者可能会奇怪我标题怎么理成这个鬼样子,主要是单单写 lxml 与 bs4 这两个 py 模块名可 ...
- 【Python爬虫】BeautifulSoup网页解析库
BeautifulSoup 网页解析库 阅读目录 初识Beautiful Soup Beautiful Soup库的4种解析器 Beautiful Soup类的基本元素 基本使用 标签选择器 节点操作 ...
- 【XPath Helper:chrome爬虫网页解析工具 Chrome插件】XPath Helper:chrome爬虫网页解析工具 Chrome插件下载_教程_安装 - 开发者插件 - Chrome插件网
[XPath Helper:chrome爬虫网页解析工具 Chrome插件]XPath Helper:chrome爬虫网页解析工具 Chrome插件下载_教程_安装 - 开发者插件 - Chrome插 ...
- 爬虫——网页解析利器--re & xpath
正则解析模块re re模块使用流程 方法一 r_list=re.findall('正则表达式',html,re.S) 方法二 创建正则编译对象 pattern = re.compile('正则表达式 ...
- 网页解析库-Xpath语法
网页解析库 简介 除了正则表达式外,还有其他方便快捷的页面解析工具 如:lxml (xpath语法) bs4 pyquery等 Xpath 全称XML Path Language, 即XML路径语言, ...
- Beautifulsoup网页解析——爬取豆瓣排行榜分类接口
我们在网页爬取的过程中,会通过requests成功的获取到所需要的信息,而且,在返回的网页信息中,也是通过HTML代码的形式进行展示的.HTML代码都是通过固定的标签组合来实现页面信息的展示,所以,最 ...
随机推荐
- 【Notes_4】现代图形学入门——光栅化、离散化三角形、深度测试与抗锯齿
光栅化 Viewport Transform(视口变换) 将经过MVP变换后得到的单位空间模型变换到屏幕上,屏幕左边是左下角为原点. 所以视口变换的矩阵 \[M_{viewport}=\begin{p ...
- Java后台防止客户端重复请求、提交表单
前言 在Web / App项目中,有一些请求或操作会对数据产生影响(比如新增.删除.修改),针对这类请求一般都需要做一些保护,以防止用户有意或无意的重复发起这样的请求导致的数据错乱. 常见处理方案 1 ...
- 小白养成记——Java比较器Comparable和Comparator
一.使用情景 1. 调用Arrays.sort()方法或Collections.sort()方法对自定义类的对象排序 以Arrays.sort()为例.假定有如下自定义的Person类 1 publ ...
- Go的switch
目录 go的switch 一.语法 二.默认情况 三.多表达式判断 四.无表达式 五.Fallthrough go的switch switch 是一个条件语句,用于多条件匹配,可以替换多个if els ...
- SENet详解及Keras复现代码
转: SENet详解及Keras复现代码 论文地址:https://arxiv.org/pdf/1709.01507.pdf 代码地址:https://github.com/hujie-frank/S ...
- PAT-1147(Heaps)最大堆和最小堆的判断+构建树
Heaps PAT-1147 #include<iostream> #include<cstring> #include<string> #include<a ...
- 基于 vagrant搭建移动端的开发环境
# 后端开发环境Homestead启动 Homestead 之前,确保 VirtualBox .Vagrant.Git 软件己安装. ## 安装 laravel/homesteadvagrant bo ...
- 主机回来以及,简单的环境配置(RTX3070+CUDA11.1+CUDNN+TensorRT)
紧接着前几天的事: 特殊的日子,想起了当年的双(1080TI)显卡装机实录 和 炼丹炉买不起了:聊一聊这段日子的显卡行情 之后,决定买一台整机玩玩. 而现在,主机终于回!来!了!主机回来干什么,当然是 ...
- WPF 基础 - 资源
为了避免丢失和损坏,编译器允许我们把外部文件编译进程序主体.成为程序主体不可分割的一部分,这就是传统意义上的程序资源,即二进制资源: WPF 的四个等级资源: 数据库里的数据 (仓库) 资源文件 (行 ...
- 使用dcmtk库读取.dcm文件并获取信息+使用OpenCV显示图像
借助VS2013和OpenCV的绘图功能,在工程DICOMReader.sln中实现了对单张.dcm图像的读取与显示,以下是详细步骤. 前期准备工作 编译器:VS2013 库:dcmtk-3.6.0( ...