端到端TVM编译器(下)
端到端TVM编译器(下)
4.3 Tensorization
DL工作负载具有很高的运算强度,通常可以分解为张量运算符,如矩阵乘法或一维卷积。这些自然分解导致了最近的添加张量计算原语。这些新的原语带来了机遇和挑战调度;为了
提高性能,编译框架必须无缝集成。称之为张量化:类似于SIMD体系结构的矢量化,但是
有显著差异。指令输入是多维的,具有固定或可变的长度,每个输入都有不同的数据布局。更重要的是,不能支持一组固定的原语,因为新的加速器是张量指令变体。
需要一个可扩展的解决方案。通过分离张量内在声明机制,从调度中获取目标内部硬件。用同样的方法,用张量表达式语言来声明两者的行为,每一个新的硬件内在特性和与之相关的降低规则。下面的代码显示了如何声明8×8张量硬件。
此外,引入了一个tensorize调度原语,用相应的内部函数替换计算单元。编译器匹配计算
模式,降低到相应的硬件本身。张量化将调度表与特定的硬件原语,便于扩展TVM支持新的硬件架构。
生成的紧绷调度表代码与高性能计算实践保持一致:打破一系列微内核调用复杂运算。利用手工制作的tensorize微内核原语,在某些平台上是有益的。例如,利用一个位串行矩阵向量乘微内核,实现了超低精度算子据类型的移动CPU的算子。这个微内核将结果累积成越来越大的数据类型,最小化内存占用。呈现TVM固有的张量微内核,产生高达1.5× 加速比非张量化的版本。
4.4 Explicit Memory Latency Hiding
延迟隐藏是指将内存操作与计算重叠,最大限度地提高内存和计算资源利用率的过程。需要不同目标硬件后端的策略。在CPU上,内存延迟隐藏是通过多线程或硬件隐式预取实现的。GPU依赖于许多线程的快速上下文切换。相比之下,像TPU这样的专用DL加速器,通常更受欢迎,具有解耦访问执行(DAE)的精简控制架构,同步卸载细粒度与软件。
图9显示了一个DAE硬件管道,减少了runtime延迟。与单片硬件设计相比,流水线可以隐藏大部分内存访问开销,几乎可以充分利用计算资源。为了获得更高的利用率,指令流必须添加同步细粒度操作。否则,依赖关系就无法强制执行,导致错误的执行。因此,DAE硬件管道,需要在管道阶段之间进行细粒度依赖的排队/出列操作,保证正确执行,如图9指令流所示。

图8: TVM虚拟线程降低,将虚拟线程并行程序转换为单个指令流;这个流包含显式的低级同步,硬件可以解释这些同步,以恢复管道并行性,需要隐藏内存访问延迟。

图9:在硬件隐藏中执行解耦访问,通过允许内存和计算重叠。执行正确性是通过低级别的同步来实现的,同步的形式是依赖令牌排队/出列操作,这编译器堆栈必须插入到指令流中。

图10:运行ResNet推断,基于FPGA的DL加速器的roofline。由于TVM启用了延迟隐藏,基准测试的性能得到了提高,更接近roofline,显示出更高的计算和内存带宽效率。
编程需要显式低层同步是困难的。在减少编程负担方面,引入了虚拟线程,指定高级数据并行程序,将是一个支持多线程的硬件后端。TVM通过低级别显式同步,自动将程序降低到单个指令流,如图8所示。该算法从高级多线程程序调度开始,插入必要的低级同步操作,
保证在每个线程内正确执行。接下来,将所有虚拟线程的操作交织到单个指令流中。最后,硬件恢复可用的管道并行性,该并行性在低级指令流中的同步。
延迟隐藏的硬件评估。在一个定制的基于FPGA的加速器,设计演示了延迟隐藏的有效性
详见第6.4小节。在加速器上,运行ResNet的每一层,使用TVM生成两个调度:一个具有延迟隐藏,另一个不具有延迟隐藏。这个用延迟隐藏调度并行化调度,使用虚拟线程公开管道并行性和隐藏内存访问延迟。显示结果在图10中作为roofline图;roofline性能图提供了一个给定不同的基准测试使用计算和内存资源的系统。总的来说,延迟隐藏得到了改善所有ResNet层的性能。峰值计算利用率从没有延迟隐藏的70%提高到88%延迟隐藏。
5. Automating Optimization
考虑到一组丰富的调度原语,剩下的问题是,如何找到最佳的算子,实现DL模型的每一层。这里,TVM为与每个层相关联的特定输入形状和布局,创建一个专门的算子。这样的专业化提供了显著的性能优势(与手工制作相比),以较小的形状和形状多样性为目标代码,也带来了自动化的挑战。这个系统需要选择调度优化。
例如,修改循环顺序或优化内存层次结构,以及调度特定的参数,如平铺大小和循环展开因子。这样的组合选择,创造了一个每个硬件后端的算子实现的巨大搜索空间。
为了应对这一挑战,构建了一个自动化的调度优化器,包含两个主要组件:一个调度资源管理器,用于提出有前向新配置;另一个预测给定配置性能的机器学习cost model。本节介绍
这些组件和TVM的自动优化流量(图11)。

图11:自动化优化框架概述。通过RPC在分布式设备群集上运行,使用基于ML的成本模型并选择实验,调度表explore检查调度表空间。为了提高预测能力,ML模型定期更新使用收集记录在数据库中的数据。

表1:自动化方法的比较。模型偏差指由于建模而导致的不准确。
5.1 Schedule Space Specification
构建了一个调度表模板规范API,让开发人员在调度表空间中声明旋钮。模板规范允许将开发人员在指定可能的调度表时,根据需要掌握特定领域的知识。还为每个硬件后端创建了一个通用主模板,该模板根据计算自动提取可能的旋钮,用张量表达式语言描述。在高层次上,需要考虑,让优化器管理选择的负载。因此,优化器必须在数十亿个可能的配置中搜索真实实验中使用的世界DL工作负载。
5.2 ML-Based Cost Model
从大的配置空间中,通过黑盒优化,即自动调整,找到最佳调度的一种方法。此方法用于调整高性能计算库。然而,自动调谐需要许多实验来确定一个好的配置。
另一种方法是建立一个预定义的cost model,指导搜索特定的硬件后端,而不是运行所有的可能性和性能测量。
理想情况下,完美的cost model会考虑所有影响性能的因素:内存访问模式、数据重用、管道依赖关系和线程模式等。不幸的是,由于日益复杂,这种现代硬件方法很麻烦。此外,每一个新的硬件目标,需要新的(预定义的)cost model。
相反,采用统计方法来解决cost model建模问题。在这种方法中,调度explore,提出可提高算子操作效率的配置性能。对于每个调度配置,使用一种最大似然模型,以降低的循环程序作为输入,预测在给定硬件上的runtime后端。该模型使用勘探期间收集的runtime测量数据进行训练,不需要用户输入详细的硬件信息。在优化过程中,当探索更多配置时,会定期更新模型,从而提高精度,以及其它相关的工作负载。这样,ML模型的质量随着实验的进行而提高预判。
表1总结了自动化方法。从相关工作量,基于ML的cost model在自动调整和预定义的cost建模之间取得了平衡。
机器学习模型设计选择。
在选择哪种ML时,进度管理器将使用的机器学习模型,要考虑两个关键因素:质量和速度。
调度管理器经常查询cost model,由于模型预测时间和模型改装时间的原因,会产生开销。这些开销必须小于在实际硬件上测量性能所需的时间,可以找到取决于特定的工作负载/硬件目标秒数order顺序。这个调度要求区分传统的超参数优化问题,与模型开销相比,执行测量的cost非常高,而且更昂贵的模型可能被使用。除了模型的选择,还需要选择一个目标函数来训练模型,例如,作为配置的预测runtime中的误差error。

图12:Titan X上ResNet-18中的conv2d算子,不同自动化方法的比较。基于ML的模型从没有训练数据开始使用,收集数据改进自身。Y轴是相对于cuDNN加速。对于其它工作负载,观察到类似的趋势。

图13: ML cost model工作流示例。XGBoost根据循环程序特性预测成本。
TreeRNN直接归纳AST。
但是,由于explore选择了最重要的候选对象,基于预测的相对顺序(A运行比B更快),不需要预测直接重复的绝对执行。相反,使用等级目标来预测runtime cost的相对顺序。在ML优化器中实现了几种类型的模型。采用了一种基于梯度树的boosting模型XGBoost),从循环程序中提取特征进行预测。这些特性包括每种方法的内存访问计数和重用率,每个循环级别的内存缓冲区,以及一个one-hot循环注释的编码,如“矢量化”、“展开”和“并行”。评估了一个神经网络,使用TreeRNN总结循环的模型程序,没有特征工程的AST。
图13总结了cost model的工作流程。发现tree boosting and TreeRNN有相似的预测能力。然而,前者执行两次预测,同样的速度和花费更少的时间来训练。因此,选择了gradient tree boosting梯度树提升作为默认的cost model的实验。尽管如此,相信这两种方法都是有价值的,并期待着今后更多这个问题的研究。
一般们来说,树推进模型可以在0.67毫秒内进行预测,比运行真正的测量更快。图12比较了基于ML的优化器和blackbox自动调优方法。发现前者比后者快得多的配置。
5.3 Schedule Exploration
一旦选择了cost model,就可以选择迭代运行real的配置测量。每次迭代中,explore都使用ML模型预测,在其上选择一批候选样本运行测量。收集的数据作为训练数据更新模型。如果不存在初始训练数据,explore将随机挑选候选对象进行测量。最简单的搜索算法枚举和通过cost model运行每个配置,选择前k个预测执行者。然而,在搜索空间大的情况下,策略变得很难处理。
相反,运行了一个并行模拟退火算法。资源管理器从随机配置开始,在每一步中,随机走到附近的配置。如果成本降低,这种转变是成功的,正如cost model所预测的那样。如果目标配置的成本较高,很可能失败(拒绝)。随机的walk倾向于收敛于具有较低性能cost model预测成本的配置。勘探状态持续更新cost model,继续执行最后一次更新后的配置。
5.4 Distributed Device Pool and RPC
分布式设备池可扩展硬件上试运行,在多个优化作业中,支持细粒度资源共享。TVM实现
自定义的、基于RPC的分布式设备池,使客户端能够在特定类型的设备上运行程序。可以用这个接口在主编译器上编译程序,请求一个远程设备,远程运行函数,访问相同脚本中的结果。TVM的RPC支持动态上传,运行交叉编译的模块和使用runtime约定函数。因此,相同的基础架构可以执行单个工作负载优化,端到端图形推理。自动化了跨多个设备编译、运行和配置步骤。

表2:ResNet-18和MobileNet中用于单核实验的所有深度conv2d算子的配置。高/宽表示高度和宽度、IC输入通道、OC输出通道、K内核大小和S步长。所有算子使用“相同”填充。所有纵深操作通道乘数为1。
这种基础架构对于嵌入式设备尤其重要,因为嵌入式设备通常需要繁琐的手动操作,用于交叉编译、代码部署和度量。
6. Evaluation
TVM核心是用C++实现的(∼5万LoC)。提供到Python和Java的语言绑定。本文早期评估了TVM的几个单独优化和组件的影响,即,图4中的算子融合,图10中的延迟隐藏,以及图12中基于ML的cost model。现在关注的是一个端到端的评估,旨在回答以下问题:
•TVM能否在多个服务器上优化DL工作负载平台?
•在每个后端,TVM与现有DL框架(依赖于高度优化的库)相比如何?
•TVM能否支持新出现的DL工作负载(例如深度卷积、低精度运算)?
•TVM是否能够支持和优化新的专业应用程序加速器?
回答这些问题,从四个方面评估了TVM平台类型:
(1)服务器级GPU;
(2)嵌入式GPU;
(3)嵌入式CPU;
(4)在低功耗FPGA SoC上实现的DL加速器。
基准是基于真实世界的DL推理工作负载,包括ResNet、MobileNet、LSTM语言模型、Deep Q网络(DQN)和深层卷积生成对抗网络(DCGAN)。

图14: 在英伟达Titan-X上,TVM的GPU端到端MXNet、Tensorflow和Tensorflow XLA评估测试。
将上述方法与现有的DL框架(包括MxNet[9]和TensorFlow[2])进行比较,后者依赖于高度工程化的、特定于算子的技术库。TVM执行端到端的自动优化和代码生成,而不需要外部设备算子库。
6.1 Server-Class GPU Evaluation
首先比较了Nvidia Titan上的深度神经网络TVM、MXNet(v1.1)、Tensorflow(v1.7)和Tensorflow XLA。MXNet和Tensorflow都使用cudnnv7作为卷积算子;实现深度卷积,因为它是相对新的和不支持最新的库。使用矩阵乘法cuBLAS v8。
另一方面,TensorFlowXLA使用JIT编译。
图14显示了TVM的性能优于基线,加速范围为1.6× 至3.8× ,由于联合图优化和自动优化,生成高性能的融合算子。DQN的3.8倍加速,使用了未经cuDNN优化的非常规算子(4×4 conv2d,步幅=2);ResNet工作负载更传统。两种情况下,TVM自动查找优化算子。
为了评估算子级优化的有效性,还对ResNet和MobileNet中的每个张量算子,如图15所示。包括TensorComprehension(TC,commit:ef644ba),每一个算子包含10 generations × 100 population × 2 random seeds,一种最近引入的自动调优框架,作为额外的基线。2 TC结果包括最佳kernel(即,每个操作员2000次试验)。

图15:所有conv2d运算符的相对加速比。ResNet-18和MobileNet中的所有depthwise conv2d算子。在Titan-X上测试。算子配置见表2,包括3x3 conv2d(TVM PT)的权重预变形Winograd。
二维卷积,2D convolution,最重要的DL算子,通过cuDNN优化。然而,TVM仍然可以为大多数层的内核kernel生成更好的GPU。深度卷积是一种新引入的结构更简单的算子。在这种情况下,与MXNet的手工内核相比,TVM和TC都可以找到快速内核。TVM的改进主要得益于,对大调度空间的探索和一种有效的基于ML的搜索算法。
6.2 Embedded CPU Evaluation
评估了TVM在Cortex A53(四核1.2GHz)上的性能。用的是Tensorflow Lite(TFLite,commit:7558b085)作为基线系统。
图17比较了TVM算子和ResNet和MobileNet的手工优化算子。观察到TVM生成性能优于手动优化的算子两种神经网络工作负载的TFLite版本。结果表明,TVM的能力,快速优化新兴的张量算子,如深卷积算子。最后,图16显示了三种工作负载的端到端比较,其中TVM优于TFLite基线。
超低精度算子
展示TVM通过生成高度优化的算子,支持超低精度推理的能力。对于小于8位的定点数据类型。低精度网络取代昂贵的乘法矢量化位串行乘法,由按位和popcount减少。要实现有效的低精度推理,需要进行量化包装,将数据类型转换为更广泛的标准数据类型,如int8或int32。系统生成的代码比来自Caffe2的手工优化库(commit:39e07f7)。实现了一个特定于ARM的张量化,利用ARM指令构建高效、低精度的矩阵向量微内核,使用TVM的自动优化器搜索调度空间。

图16: 在ARM A53上对TVM和TFLite评估。
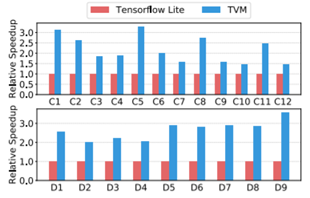
图17:所有conv2d运算符的相对加速比。ResNet-18和mobilenet中的所有depthwise conv2d算子。在ARM A53上测试。这些算子的配置见表2。

图18:ResNet中单线程和多线程低精度conv2d运算符的相对加速比。基线是来自Caffe2的单线程、手工优化的实现(commit:39e07f7)。C5、C3为1x1卷积,计算强度较小,多线程导致加速较慢。
图18将TVM与ResNet上的Caffe2超低精度库进行了2位激活、1位权重推理比较。因为基线是单线程的,与单线程TVM版本进行了比较。单线程TVM优于基线,特别是对于C5、C8和C11层;这些是卷积内核大小为1的层×1和2的步长,超低精度基线库未对此进行优化。此外,利用额外的TVM功能来生成一个并行库实现,显示出比基线有所改善。除了2-bit+1-bit配置,TVM可以生成和优化不支持的其它精度配置的基线库,提高了灵活性。
6.3 Embedded GPU Evaluation
对于移动GPU实验,运行了端到端的Firefly-RK3399板上ARM-T860MP4 GPU的管道配备。基线是一个算子提供的ARM计算库(v18.03)。

图19: MaliT860MP4上的端到端实验结果。有两种数据类型float32和float16评价的。
如图19所示,在性能上优于基线。三种适用于float16和float32的型号(基线还不支持DCGAN和LSTM)。加速比为1.2× 至1.6×.
6.4 FPGA Accelerator Evaluation
Vanilla深度学习加速器
TVM如何处理特定于加速器的代码生成,在FPGA上,进行原型化的通用推理加速器设计。在这个评估中,使用了Vanilla学习加速器(VDLA)–从以前的加速器中,提取特征
成为一个极简主义的硬件架构-演示可以瞄准专门的加速器,TVM生成高效调度表的能力。图20显示了VDLA体系结构的高级硬件组织。VDLA被编程为一个张量处理器。高效地执行高计算强度的算子(例如,矩阵乘法、高维卷积)。可以执行加载/存储操作,将三维张量从DRAM阻塞到SRAM的相邻区域。还为网络参数、层输入(窄数据类型)和层输出(宽数据类型)提供专门的onchip存储器。最后,VDLA提供了显式的同步控制,在连续的加载、计算和存储中最大化内存和计算算子之间的重叠。
方法论
在一个平台上实现了VDLA设计,低功耗PYNQ板,采用ARM Cortex A9双核CPU,时钟频率667MHz和Artix-7,基于FPGA结构。在这些有限的FPGA资源上,实施了16×16矩阵矢量单元,200MHz,执行8位值的乘积,并在每个周期累加到32位寄存器中。VDLA设计的理论峰值吞吐量约为102.4加仑/秒。激活存储分配了32kB的资源,微码缓冲区,以及128kB的寄存器文件,参数存储分配了32kB的资源。这些片内缓冲区决不足以提供一层ResNet。可以对有效的内存重用进行案例研究和潜伏期隐藏。

Figure 20: VDLA 硬件设计架构。
用C runtime为VDLA构建一个驱动程序库构造指令,推送到执行的目标加速器。代码生成算法将加速器程序转换为一系列调用,并将这些调用转换为运行时API。添加专门的加速器后端∼Python中的2k LoC。
End-to-End ResNet Evaluation.
在PYNQ平台上,用TVM生成ResNet推理内核,尽可能多的层卸载到VDLA。为CPU生成两个调度,仅限CPU+FPGA实现。由于卷积深度较浅,第一个ResNet卷积层无法在FPGA上有效卸载,而是在CPU上计算。然而,ResNet中的所有其它卷积层,可以进行有效的卸载。残余层和激活等算子也在CPU上执行,因为VDLA不支持这些操作。

图21将ResNet推理时间分解为仅CPU执行和CPU+FPGA执行。最多计算花费在卷积层上,可以卸载到VDLA。对于那些卷积层,实现的加速比是40×. 不幸的是,根据Amdahl定律,对FPGA的整体性能进行了分析。加速系统的瓶颈,必须在CPU上执行的工作负载。设想扩展VDLA设计,支持这些其它算子,有助于进一步降低成本。
基于FPGA的实验验证了TVM的性能,适应新的体系结构和硬件本质。
7. Related Work
深度学习框架提供了便利,很容易在不同的硬件后端,用于用户表示DL工作负载和部署的接口。现有的框架,目前依赖于特定于算子的Tensor算子库,来执行工作负载。可以为大量的硬件设备利用TVM的堆栈。高级计算图dsl是一个典型的表示和执行高级优化的方法。Tensorflow的XLA和最近引入的DLVM属于这一类。这些工作中计算图的表示是相似的,本文还使用了高级计算图DSL论文。图级表示则是一个很好的选择,对于高级优化,级别太高,无法在不同的硬件后端下优化张量算子。之前的工作取决于具体的降低直接生成低级LLVM或诉诸于算子库。这些方法需要对每个硬件后端进行大量的工程工作和算子变量组合。
Halide引入了将计算和调度分离的思想。采用Halid的方法,再利用编译器中现有的有用的调度原语。张量算子调度也与其它算子有关。研究GPU的DSL和多面体回路变换。TACO介绍一种生成稀疏张量算子的通用中央处理器方法。Weld是用于数据处理任务的DSL。特别关注于为GPU和专用加速器解决DL工作负载的新调度挑战。通过优化这些工程中的管线,新原语有可能被采纳。
高性能库,如ATLAS和FFTW使用自动调谐以获得最佳性能。张量理解应用黑盒自动调谐和多面体优化CUDA内核。OpenTuner和现有超参数调整算法应用领域无关搜索。预定义的cost model用于在中自动调度图像处理管道Halid。TVM的ML模型使用有效的考虑程序结构的域感知cost model。
图21:在ResNet中卸载了卷积,基于FPGA的加速器的工作负载。灰色输出条对应于不能加速的层,必须在CPU上运行。这个FPGA在Cortex A9 上的卸载卷积层上提供了40倍的加速。
模型的分布式调度优化器,可扩展到更大的搜索空间,在大范围的支持后端,可以找到最先进的内核。更重要的是,提供了一个端到端堆栈,可以直接从DL框架中获取描述,并与图级堆栈一起进行联合优化。尽管深入学习加速器越来越流行,有效地针对这些设备,仍然不清楚如何构建编译堆栈。提供了一种总结类TPU性质的通用方法,评估中使用的VDLA设计,加速器和使具体的案例研究如何为加速器编译代码。可以潜在的好处是编译深度学习FPGA。本文提供了一个通过张量化和编译器驱动的延迟隐藏,有效地瞄准加速器的通用解决方案。
8. Conclusion
跨越一系列不同的硬件后端,提出了一个端到端编译堆栈来解决深度学习的基本优化挑战。。系统包括自动端到端优化,历史上,这是一项劳动密集型和高度专业化的任务。
希望这项工作将鼓励更多的研究,端到端编译方法为DL系统软硬件协同设计,提供了新的技术。
端到端TVM编译器(下)的更多相关文章
- 端到端TVM编译器(上)
端到端TVM编译器(上) 摘要 将机器学习引入到各种各样的硬件设备中.AI框架依赖于特定于供应商的算子库,针对窄范围的服务器级gpu进行优化.将工作负载部署到新平台,例如手机.嵌入式设备和加速器(例如 ...
- TVM:一个端到端的用于开发深度学习负载以适应多种硬件平台的IR栈
TVM:一个端到端的用于开发深度学习负载以适应多种硬件平台的IR栈 本文对TVM的论文进行了翻译整理 深度学习如今无处不在且必不可少.这次创新部分得益于可扩展的深度学习系统,比如 TensorFlo ...
- 用TVM在硬件平台上部署深度学习工作负载的端到端 IR 堆栈
用TVM在硬件平台上部署深度学习工作负载的端到端 IR 堆栈 深度学习已变得无处不在,不可或缺.这场革命的一部分是由可扩展的深度学习系统推动的,如滕索弗洛.MXNet.咖啡和皮托奇.大多数现有系统针对 ...
- GPU端到端目标检测YOLOV3全过程(下)
GPU端到端目标检测YOLOV3全过程(下) Ubuntu18.04系统下最新版GPU环境配置 安装显卡驱动 安装Cuda 10.0 安装cuDNN 1.安装显卡驱动 (1)这里采用的是PPA源的安装 ...
- Android IOS WebRTC 音视频开发总结(七八)-- 为什么WebRTC端到端监控很关键?
本文主要介绍WebRTC端到端监控(我们翻译和整理的,译者:weizhenwei,校验:blacker),最早发表在[编风网] 支持原创,转载必须注明出处,欢迎关注我的微信公众号blacker(微信I ...
- 端到端 vs 点到点
比较(转自 百度经验) 端到端与点到点是针对网络中传输的两端设备间的关系而言的.端到端传输指的是在数据传输前,经过各种各样的交换设备,在两端设备问建立一条链路,就僚它们是直接相连的一样,链路建立后,发 ...
- 详解APM数据采样与端到端
高驰涛 云智慧首席架构师 据云智慧统计,APM从客户端采集的性能数据可能占到业务数据的50%,而企业要做到从Request到Response整个链路中涉及到的所有数据的准确采集,并进行有效串接,进而实 ...
- [Asp.net 开发系列之SignalR篇]专题二:使用SignalR实现酷炫端对端聊天功能
一.引言 在前一篇文章已经详细介绍了SignalR了,并且简单介绍它在Asp.net MVC 和WPF中的应用.在上篇博文介绍的都是群发消息的实现,然而,对于SignalR是为了实时聊天而生的,自然少 ...
- 基于tensorflow的‘端到端’的字符型验证码识别源码整理(github源码分享)
基于tensorflow的‘端到端’的字符型验证码识别 1 Abstract 验证码(CAPTCHA)的诞生本身是为了自动区分 自然人 和 机器人 的一套公开方法, 但是近几年的人工智能技术的发展 ...
随机推荐
- 1045 Favorite Color Stripe
Eva is trying to make her own color stripe out of a given one. She would like to keep only her favor ...
- PDF转HTML工具——用springboot包装pdf2htmlEX命令行工具
Convert PDF to HTML without losing text or format. 用springboot把pdf2htmlEX命令行工具包装为web服务, 使得PDF转HTML更方 ...
- MySQL批量删除数据表
SELECT CONCAT('drop table ',table_name,';') FROM information_schema.`TABLES` WHERE table_schema='数据库 ...
- POJ2195费用流+BFS建图
题意: 给你一个n*m的地图,上面有w个人,和w个房子,每个人都要进房子,每个房子只能进一个人,问所有人都进房子的路径总和最少是多少? 思路: 比较简单的最大流,直接建立两排, ...
- web自动化框架—BasePage 类的简单封装
优秀的框架都有属于自己的思想,在搭建web自动化测试框架时,我们通常都遵循 PO(Page Object)思想. 简单理解就是我们会把每个页面看成一个对象,一切皆对象,面向对象编码,这样会让我们更好的 ...
- Java_集合之一
1.Collection集合 1.1数组和集合的区别[理解] 相同点 都是容器,可以存储多个数据 不同点 数组的长度是不可变的,集合的长度是可变的 数组可以存基本数据类型和引用数据类型 集合只能存引用 ...
- 在C++中调用Python
技术背景 虽然现在Python编程语言十分的火爆,但是实际上非要用一门语言去完成所有的任务,并不是说不可以,而是不合适.在一些特定的.对于性能要求比较高的场景,还是需要用到传统的C++来进行编程的.但 ...
- SpringBoot整合shiro系列-SpingBoot是如何将shiroFilter注册到servlet容器中的
一.先从配置类入手,主要是@Bean了一个ShiroFilterFactoryBean: @Data @Configuration @Slf4j @EnableConfigurationPropert ...
- [bug] Maven:No valid Maven installation found.maven
原因 从别处复制来的项目,maven路径没有改过来 参考 https://blog.csdn.net/qq_40846086/article/details/81252736
- [bug] PowerDesigner的association按钮灰色不能使用
参考 https://blog.csdn.net/markely/article/details/44873301