cephfs文件系统场景
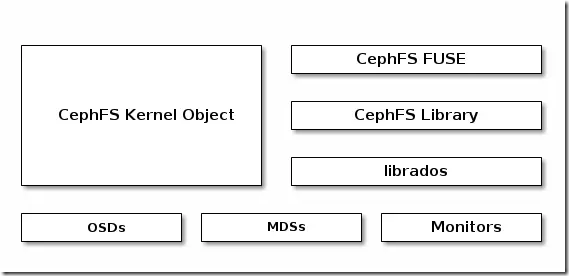
创建cephfs文件系统:
[cephfsd@ceph-admin ceph]$ cd /etc/ceph
[cephfsd@ceph-admin ceph]$ ceph fs ls
No filesystems enabled
# 创建三个mds
[cephfsd@ceph-admin ceph]$ ceph-deploy mds create ceph-node1 ceph-node2 ceph-node3
# cephfs需要两个pool:
# 1、data pool:存放object
# 2、meta data pool:存放元数据,可设置较高副本级别,也可调整pool的crush_ruleset,使其在ssd上存储,加快客户端响应速度,我这里直接使用默认crush_ruleset
# 创建pool存储池,这里两个pg_num必须保持一致,否则后面无法挂载。
[cephfsd@ceph-admin ceph]$ ceph osd pool create cephfs_data 64
pool 'cephfs_data' created
[cephfsd@ceph-admin ceph]$ ceph osd pool create cephfs_metadata 64
pool 'cephfs_metadata' created
# 注:
# 计算pg数量:
# 1、集群pg 总数 = (OSD 总数* 100 )/最大副本数
# 2、每个pool中pg总数=(OSD总数*100)/ 最大副本数 )/ 池数
# 3、pg数需要是2的指数幂 # 创建fs,这里new后面的cephfs就是文件系统名,可自定义。后面接的cephfs_metadata cephfs_data 就是上面创建的pool。
[cephfsd@ceph-admin ceph]$ ceph fs new cephfs cephfs_metadata cephfs_data
new fs with metadata pool 6 and data pool 5
# 创建成功,查看创建后的fs
[cephfsd@ceph-admin ceph]$ ceph fs ls
name: cephfs, metadata pool: cephfs_metadata, data pools: [cephfs_data ]
# 查看mds节点状态,active是活跃的,另1个是处于热备份的状态
[cephfsd@ceph-admin ceph]$ ceph mds stat
cephfs-1/1/1 up {0=ceph-node3=up:active}, 2 up:standby
[cephfsd@ceph-admin ceph]$
挂载cephfs文件系统(在任意客户端,我们这里直接在ceph的admin主机上挂载了)
# 创建挂载点
[cephfsd@ceph-admin ceph]$ mkdir /opt
# 去admin主机查看存储秘钥
[cephfsd@ceph-admin ceph]$ cat ceph.client.admin.keyring
[client.admin]
key = AQBIH+ld1okAJhAAmULVJM4zCCVAK/Vdi3Tz5Q==
# 将key的值复制下来,保存到客户端,我们这里保存在了/etc/ceph/admin.secret
[cephfsd@ceph-admin ceph]$ cat admin.secret
AQBIH+ld1okAJhAAmULVJM4zCCVAK/Vdi3Tz5Q==
# 挂载,有两种方式挂载,mount挂载和ceph-fuse挂载
# A.内核驱动挂载Ceph文件系统
[cephfsd@ceph-admin ceph]$ sudo mount.ceph 172.16.143.121:6789:/ /opt -o name=admin,secretfile=/etc/ceph/admin.secret
[cephfsd@ceph-admin ceph]$ df -Th
Filesystem Type Size Used Avail Use% Mounted on
devtmpfs devtmpfs 484M 0 484M 0% /dev
tmpfs tmpfs 496M 0 496M 0% /dev/shm
tmpfs tmpfs 496M 26M 470M 6% /run
tmpfs tmpfs 496M 0 496M 0% /sys/fs/cgroup
/dev/mapper/centos-root xfs 46G 1.9G 44G 4% /
/dev/sda1 xfs 497M 130M 368M 26% /boot
tmpfs tmpfs 100M 0 100M 0% /run/user/0
172.16.143.121:6789:/ ceph 8.5G 0 8.5G 0% /opt
# 注:
# mount时,mon节点有几个写几个,如果配置了hosts解析,可以使用主机名代替IP。
# 还可以使用fuse挂载方式,fuse其实坑挺多的,能不用暂时不用 # 由于kernel挂载方式目前不支持quota的配置,如果需要quota的配置,那么只好使用fuse挂载 # 卸载
[cephfsd@ceph-admin ceph]$ umount /opt
umount: /opt: umount failed: Operation not permitted
[cephfsd@ceph-admin ceph]$ sudo umount /opt
[cephfsd@ceph-admin ceph]$ df -Th
Filesystem Type Size Used Avail Use% Mounted on
devtmpfs devtmpfs 484M 0 484M 0% /dev
tmpfs tmpfs 496M 0 496M 0% /dev/shm
tmpfs tmpfs 496M 26M 470M 6% /run
tmpfs tmpfs 496M 0 496M 0% /sys/fs/cgroup
/dev/mapper/centos-root xfs 46G 1.9G 44G 4% /
/dev/sda1 xfs 497M 130M 368M 26% /boot
tmpfs tmpfs 100M 0 100M 0% /run/user/0
# 设置开机自动挂载/etc/fstab
[cephfsd@ceph-admin ceph]$ sudo vim /etc/fstab
172.16.143.121:6789:/ /opt ceph name=admin,secretfile=/etc/ceph/admin.secret,noatime,_netdev 0 2 # 注意:检查是否启用cephx认证方法,如果值为none为禁用,cephx为启用
[root@node1 ceph]# cat /etc/ceph/ceph.conf | grep auth | grep required
auth_cluster_required = cephx
auth_service_required = cephx
auth_client_required = cephx # B.用户控件挂载Ceph文件系统
# 安装ceph-fuse
[cephfsd@ceph-admin ceph]$ yum install -y ceph-fuse
# 挂载,挂载需要sudo权限,否则会报错。
[cephfsd@ceph-admin ceph]$ sudo ceph-fuse -m 172.16.143.121:6789 /opt
2019-12-06 08:29:52.137542 7f0e2edb20c0 -1 init, newargv = 0x55c37f3887e0 newargc=9ceph-fuse[50371]: starting ceph client ceph-fuse[50371]: starting fuse
[cephfsd@ceph-admin ceph]$ df -Th
Filesystem Type Size Used Avail Use% Mounted on
devtmpfs devtmpfs 484M 0 484M 0% /dev
tmpfs tmpfs 496M 0 496M 0% /dev/shm
tmpfs tmpfs 496M 26M 470M 6% /run
tmpfs tmpfs 496M 0 496M 0% /sys/fs/cgroup
/dev/mapper/centos-root xfs 46G 1.9G 44G 4% /
/dev/sda1 xfs 497M 130M 368M 26% /boot
tmpfs tmpfs 100M 0 100M 0% /run/user/0
ceph-fuse fuse.ceph-fuse 8.5G 0 8.5G 0% /opt
# 卸载
[cephfsd@ceph-admin ceph]$ fusermount -u /opt
fusermount: entry for /opt not found in /etc/mtab
[cephfsd@ceph-admin ceph]$ sudo fusermount -u /opt
[cephfsd@ceph-admin ceph]$ df -Th
Filesystem Type Size Used Avail Use% Mounted on
devtmpfs devtmpfs 484M 0 484M 0% /dev
tmpfs tmpfs 496M 0 496M 0% /dev/shm
tmpfs tmpfs 496M 26M 470M 6% /run
tmpfs tmpfs 496M 0 496M 0% /sys/fs/cgroup
/dev/mapper/centos-root xfs 46G 1.9G 44G 4% /
/dev/sda1 xfs 497M 130M 368M 26% /boot
tmpfs tmpfs 100M 0 100M 0% /run/user/0
[cephfsd@ceph-admin ceph]$
# 这里就是用ceph-fuse挂载时没有使用root权限,就挂载不上。
[cephfsd@ceph-admin ceph]$ ceph-fuse -m 172.16.143.121:6789 /opt
2019-12-06 08:29:28.606085 7f35fd5e60c0 -1 asok(0x5627d23481c0) AdminSocketConfigObs::init: failed: AdminSocket::bind_and_listen: failed to bind the UNIX domain socket to '/var/run/ceph/ceph-client.admin.asok': (13) Permission denied
2019-12-06 08:29:28.606957 7f35fd5e60c0 -1 init, newargv = 0x5627d24967e0 newargc=9
ceph-fuse[50325]: starting ceph client
fusermount: user has no write access to mountpoint /opt
ceph-fuse[50325]: fuse failed to start
2019-12-06 08:29:31.044358 7f35fd5e60c0 -1 fuse_mount(mountpoint=/opt) failed.
[cephfsd@ceph-admin ceph]$
[cephfsd@ceph-admin ceph]$ df -Th
Filesystem Type Size Used Avail Use% Mounted on
devtmpfs devtmpfs 484M 0 484M 0% /dev
tmpfs tmpfs 496M 0 496M 0% /dev/shm
tmpfs tmpfs 496M 26M 470M 6% /run
tmpfs tmpfs 496M 0 496M 0% /sys/fs/cgroup
/dev/mapper/centos-root xfs 46G 1.9G 44G 4% /
/dev/sda1 xfs 497M 130M 368M 26% /boot
tmpfs tmpfs 100M 0 100M 0% /run/user/0
[cephfsd@ceph-admin ceph]$
# 设置开机自动挂载/etc/fstab
[cephfsd@ceph-admin ceph]$ sudo vim /etc/fstab
id=admin,conf=/etc/ceph/ceph.conf /mnt fuse.ceph defaults 0 0
删除cephfs,需要先将mds置为failed。
[cephfsd@ceph-admin ceph]$ ceph fs rm 128
Error EINVAL: all MDS daemons must be inactive before removing filesystem
[cephfsd@ceph-admin ceph]$ ceph mds stat
128-1/1/1 up {0=ceph-node2=up:active(laggy or crashed)}
[cephfsd@ceph-admin ceph]$ ceph mds fail 0
failed mds gid 4147
[cephfsd@ceph-admin ceph]$ ceph mds stat
128-0/1/1 up , 1 failed
[cephfsd@ceph-admin ceph]$ ceph fs rm 128
Error EPERM: this is a DESTRUCTIVE operation and will make data in your filesystem permanently inaccessible. Add --yes-i-really-mean-it if you are sure you wish to continue.
[cephfsd@ceph-admin ceph]$ ceph fs rm 128 --yes-i-really-mean-it
[cephfsd@ceph-admin ceph]$ ceph fs ls
No filesystems enabled
[cephfsd@ceph-admin ceph]$
删除pg pool,需要先将使用该pool的cephfs删除。
[cephfsd@ceph-admin ceph]$ ceph osd pool rm cephfs_data2 cephfs_data2 --yes-i-really-mean-it
Error EPERM: WARNING: this will *PERMANENTLY DESTROY* all data stored in pool cephfs_data2. If you are *ABSOLUTELY CERTAIN* that is what you want, pass the pool name *twice*, followed by --yes-i-really-really-mean-it.
[cephfsd@ceph-admin ceph]$ ceph osd pool rm cephfs_data2 cephfs_data2 --yes-i-really-really-mean-it
Error EBUSY: pool 'cephfs_data2' is in use by CephFS
# 该pool被cephfs使用了,所以需要先删除该cephfs。 # 因为cephfs_data cephfs_metadata是挂载在128下的,cephfs_data2 cephfs_metadata2是挂载在cephfs下的,所以,删除cephfs
# 接下来,删除cephfs
[cephfsd@ceph-admin ceph]$ ceph fs rm cephfs
Error EPERM: this is a DESTRUCTIVE operation and will make data in your filesystem permanently inaccessible. Add --yes-i-really-mean-it if you are sure you wish to continue.
[cephfsd@ceph-admin ceph]$ ceph fs rm cephfs --yes-i-really-mean-it
[cephfsd@ceph-admin ceph]$ ceph fs ls
name: 128, metadata pool: cephfs_metadata, data pools: [cephfs_data ]
[cephfsd@ceph-admin ceph]$ # cephfs删除了,接下来删除pool cephfs_data2
[cephfsd@ceph-admin ceph]$ ceph osd pool delete cephfs_data2
Error EPERM: WARNING: this will *PERMANENTLY DESTROY* all data stored in pool cephfs_data2. If you are *ABSOLUTELY CERTAIN* that is what you want, pass the pool name *twice*, followed by --yes-i-really-really-mean-it.
[cephfsd@ceph-admin ceph]$ ceph osd pool delete cephfs_data2 cephfs_data2 --yes-i-really-really-mean-it
Error EPERM: pool deletion is disabled; you must first set the mon_allow_pool_delete config option to true before you can destroy a pool
# 这里需要修改配置,增加mon_allow_pool_delete = true
[cephfsd@ceph-admin ceph]$ vim ceph.conf
[cephfsd@ceph-admin ceph]$ cat ceph.conf
[global]
fsid = 6d3fd8ed-d630-48f7-aa8d-ed79da7a69eb
mon_initial_members = ceph-admin
mon_host = 172.16.143.121
auth_cluster_required = cephx
auth_service_required = cephx
auth_client_required = cephx mon_allow_pool_delete = true osd_pool_default_size = 3 [mgr]
mgr modules = dashboard
# 然后把配置推送到mon节点。(这里其实不需要了,因为mon节点只有一个,部署在ceph-admin里)
[cephfsd@ceph-admin ceph]$ ceph-deploy --overwrite-conf config push ceph-node1 ceph-node2 ceph-node3
[ceph_deploy.conf][DEBUG ] found configuration file at: /home/cephfsd/.cephdeploy.conf
[ceph_deploy.cli][INFO ] Invoked (2.0.1): /usr/bin/ceph-deploy --overwrite-conf config push ceph-node1 ceph-node2 ceph-node3
[ceph_deploy.cli][INFO ] ceph-deploy options:
[ceph_deploy.cli][INFO ] username : None
[ceph_deploy.cli][INFO ] verbose : False
[ceph_deploy.cli][INFO ] overwrite_conf : True
[ceph_deploy.cli][INFO ] subcommand : push
[ceph_deploy.cli][INFO ] quiet : False
[ceph_deploy.cli][INFO ] cd_conf : <ceph_deploy.conf.cephdeploy.Conf instance at 0x7f946bf4fa28>
[ceph_deploy.cli][INFO ] cluster : ceph
[ceph_deploy.cli][INFO ] client : ['ceph-node1', 'ceph-node2', 'ceph-node3']
[ceph_deploy.cli][INFO ] func : <function config at 0x7f946c18ac08>
[ceph_deploy.cli][INFO ] ceph_conf : None
[ceph_deploy.cli][INFO ] default_release : False
[ceph_deploy.config][DEBUG ] Pushing config to ceph-node1
[ceph-node1][DEBUG ] connection detected need for sudo
[ceph-node1][DEBUG ] connected to host: ceph-node1
[ceph-node1][DEBUG ] detect platform information from remote host
[ceph-node1][DEBUG ] detect machine type
[ceph-node1][DEBUG ] write cluster configuration to /etc/ceph/{cluster}.conf
[ceph_deploy.config][DEBUG ] Pushing config to ceph-node2
[ceph-node2][DEBUG ] connection detected need for sudo
[ceph-node2][DEBUG ] connected to host: ceph-node2
[ceph-node2][DEBUG ] detect platform information from remote host
[ceph-node2][DEBUG ] detect machine type
[ceph-node2][DEBUG ] write cluster configuration to /etc/ceph/{cluster}.conf
[ceph_deploy.config][DEBUG ] Pushing config to ceph-node3
[ceph-node3][DEBUG ] connection detected need for sudo
[ceph-node3][DEBUG ] connected to host: ceph-node3
[ceph-node3][DEBUG ] detect platform information from remote host
[ceph-node3][DEBUG ] detect machine type
[ceph-node3][DEBUG ] write cluster configuration to /etc/ceph/{cluster}.conf
[cephfsd@ceph-admin ceph]$ ceph osd pool delete cephfs_data2 cephfs_data2 --yes-i-really-really-mean-it
Error EPERM: pool deletion is disabled; you must first set the mon_allow_pool_delete config option to true before you can destroy a pool
# 依然报这个错,因为没有重启mon,所以这里需要重启一下mon服务。重启服务需要root权限。
[cephfsd@ceph-admin ceph]$ systemctl restart ceph-mon.target
==== AUTHENTICATING FOR org.freedesktop.systemd1.manage-units ===
Authentication is required to manage system services or units.
Authenticating as: root
Password:
==== AUTHENTICATION COMPLETE ===
[cephfsd@ceph-admin ceph]$
# 接下来就可以删除pool了。
[cephfsd@ceph-admin ceph]$ ceph osd pool delete cephfs_data2 cephfs_data2 --yes-i-really-really-mean-it
pool 'cephfs_data2' removed
[cephfsd@ceph-admin ceph]$ ceph osd pool delete cephfs_metadata2 cephfs_metadata2 --yes-i-really-really-mean-it
pool 'cephfs_metadata2' removed
挂载:
[cephfsd@ceph-admin ceph]$ !mount
mount -t ceph 172.16.143.121:6789:/ /opt -o name=admin,secretfile=/etc/ceph/admin.secret
mount: only root can use "--options" option
[cephfsd@ceph-admin ceph]$ mount.ceph 172.16.143.121:6789:/ /opt -o name=admin,secretfile=/etc/ceph/admin.secret
mount error 1 = Operation not permitted
# 需要root权限执行mount
注意问题:
1、ceph pg_num设置太大。
ceph使用cephfs
[cephfsd@ceph-admin ceph]$ ceph osd pool create cephfs_data 128
pool 'cephfs_data' already exists
[cephfsd@ceph-admin ceph]$ ceph osd pool create cephfs_metadata 128
Error ERANGE: pg_num 128 size 3 would mean 768 total pgs, which exceeds max 750 (mon_max_pg_per_osd 250 * num_in_osds 3)
[cephfsd@ceph-admin ceph]$
类似这种,应该就是ceph pg_num设置太大了,设置小一点就好了,如下:
[cephfsd@ceph-admin ceph]$ ceph osd pool create cephfs_metadata 64
pool 'cephfs_metadata' created
[cephfsd@ceph-admin ceph]$
2、 pg_num只能增加, 不能缩小.
[cephfsd@ceph-admin ceph]$ ceph osd pool set cephfs_data pg_num 64
Error EEXIST: specified pg_num 64 <= current 12
3、cephfs_data与cephfs_metadata的pg_num值必须保持一致,否则,即使pool创建成功,也无法挂载,就像下面一样:
[cephfsd@ceph-admin ceph]$ sudo mount.ceph 172.16.143.121:6789:/ /opt -o name=admin,secretfile=/etc/ceph/admin.secret ^C^C ^C^C ^C
^CKilled
[cephfsd@ceph-admin ceph]$
mount error 5 = Input/output error
mount error 110 = Connection timed out
参考:http://www.strugglesquirrel.com/2019/04/23/centos7%E9%83%A8%E7%BD%B2ceph/
http://docs.ceph.org.cn/cephfs/
cephfs文件系统场景的更多相关文章
- 013 CephFS文件系统
一.Ceph文件系统简介 CephFS提供兼容POSIX的文件系统,将其数据和与那数据作为对象那个存储在Ceph中 CephFS依靠MDS节点来协调RADOS集群的访问 元数据服务器 MDS管理元数据 ...
- ceph 008 ceph多区域网关(ceph对象容灾) cephfs文件系统
clienta作为集群的管理人员.一部分.他是需要秘钥与配置文件的 但真正服务端只需要通过curl就好 ceph 多区域网关 对象存储容灾解决方案 zone与zone会做数据同步. 把会做同步的rgw ...
- 6.Ceph 基础篇 - CephFS 文件系统
文章转载自:https://mp.weixin.qq.com/s?__biz=MzI1MDgwNzQ1MQ==&mid=2247485294&idx=1&sn=e9039504 ...
- Ceph 文件系统 CephFS 的实战配置,等你来学习 -- <4>
Ceph 文件系统 CephFS 的介绍与配置 CephFs介绍 Ceph File System (CephFS) 是与 POSIX 标准兼容的文件系统, 能够提供对 Ceph 存储集群上的文件访问 ...
- 分布式存储系统之Ceph集群CephFS基础使用
前文我们了解了ceph之上的RBD接口使用相关话题,回顾请参考https://www.cnblogs.com/qiuhom-1874/p/16753098.html:今天我们来聊一聊ceph之上的另一 ...
- Ceph RBD CephFS 存储
Ceph RBD CephFS 存储 环境准备: (这里只做基础测试, ceph-manager , ceph-mon, ceph-osd 一共三台) 10.6.0.140 = ceph-manag ...
- kubernetes多节点的pod挂载同一个cephfs目录
一.安装cephfs 方法一: 直接进入deploy目录,执行: ceph-deploy --overwrite-conf mds create ceph01:mds-daemon- 上面的ceph0 ...
- Centos7部署CephFS
标签(空格分隔): ceph环境,ceph,cephfs cephfs部署之前准备工作: 1. 一个 clean+active 的cluster cluster部署参考:centos7下搭建ceph ...
- IO解惑:cephfs、libaio与io瓶颈
最近笔者在对kernel cephfs客户端进行fio direct随机大io读测试时发现,在numjobs不变的情况下,使用libaio作为ioengine,无论怎么调节iodepth,测试结果都变 ...
随机推荐
- Ubuntu 16.04 curl 安装 使用
curl是利用URL语法在命令行方式显工作的开元文件传输工具. 安装 $ sudo apt install -y curl 使用 $ curl http://www.baidu.com 这是最简单的使 ...
- linux 内核源代码情景分析——Intel X86 CPU 系列的寻址方式
当我们说一个CPU是"16位"或"32"位时,指的是处理器中"算数逻辑单元"(ALU)的宽度.数据总线通常与ALU具有相同的宽度.当Inte ...
- Swoft+Docker
Docker 以下纯属个人理解: Docker就是一种虚拟机,将环境打包成镜像,等于做了一个Linux系统裁剪. 镜像就是我们安装系统的镜像,里面包含了你的代码和环境. 容器就是一个虚拟机,你可以用一 ...
- Java 代码执行流程
Java 代码执行流程 类加载过程 加载 -> 验证 -> 准备 -> 解析 -> 初始化 -> 使用 -> 卸载 类加载时机:代码使用到这个类时 验证阶段 &qu ...
- IO流(一)
内容概要: Java以流的形式处理所有输入和输出.流是随通信路径从源移动到目的地的字节序列. 内存与存储设备之间传输数据的通道 流的分类: 按方向 输入流:将存储空间中的内容读到内存中 硬盘--& ...
- Git项目迁移(把当前git项目迁移到新的git地址)
使用 git clone --bare 命令clone当前git git clone --bare http://gitlab.xxx/demo.git 推到新的git地址 cd demo.git g ...
- 天冷了,任务栏养只猫吧「GitHub 热点速览 v.21.46」
作者:HelloGitHub-小鱼干 运动能带来热量,盘猫也是,RunCat_for_windows 是一只奔跑在任务栏的猫,一定能给你的电脑带来一丝冬日的温暖.当然送温暖的除了任务栏小猫咪之外,还有 ...
- 深入理解Spring IOC容器及扩展
本文将从纯xml模式.xml和注解结合.纯注解的方式讲解Spring IOC容器的配置和相关应用. 纯XML模式 实例化Bean的三种方式: 使用无参构造函数 默认情况下,会使用反射调用无参构造函数来 ...
- 理解PHP的运行机制
PHP是一种纯解释型在服务端执行的可以内嵌HTML的脚本语言,尤其适合开发Web应用程序.请求一个 PHP 脚本时,PHP 会读取该脚本,并将其编译为 Zend 操作码,这是要执行的代码的一种二进制表 ...
- ICCV2021 | Vision Transformer中相对位置编码的反思与改进
前言 在计算机视觉中,相对位置编码的有效性还没有得到很好的研究,甚至仍然存在争议,本文分析了相对位置编码中的几个关键因素,提出了一种新的针对2D图像的相对位置编码方法,称为图像RPE(IRPE). ...