Spark(二)【sc.textfile的分区策略源码分析】
sparkcontext.textFile()返回的是HadoopRDD!
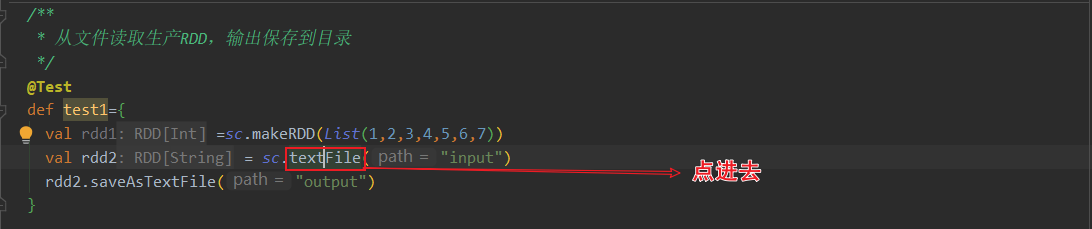
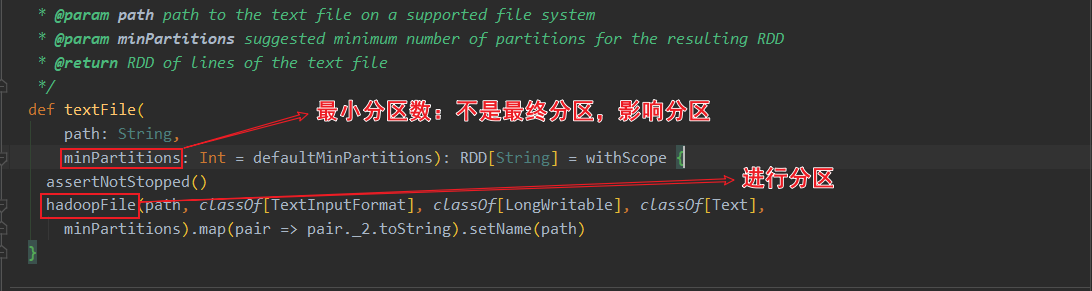
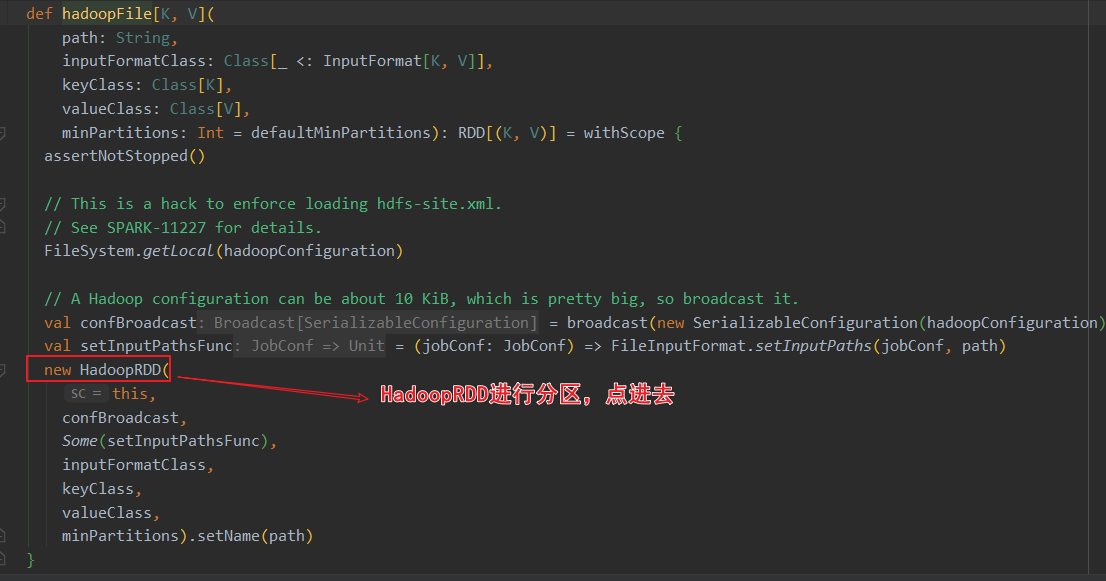
关于HadoopRDD的官方介绍,使用的是旧版的hadoop api

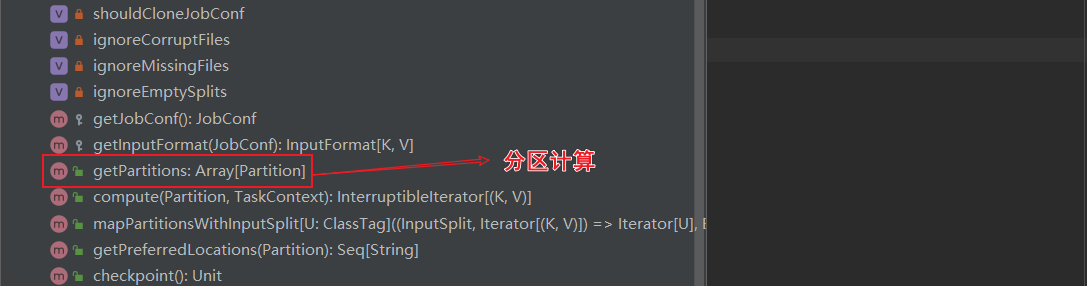
ctrl+F12搜索 HadoopRDD的getPartitions方法,这里进行了分区计算
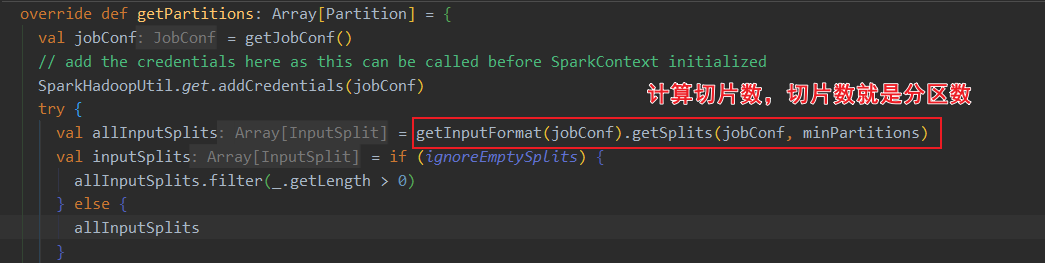
读取的是txt文件,用的是TextInputFormat的切片规则
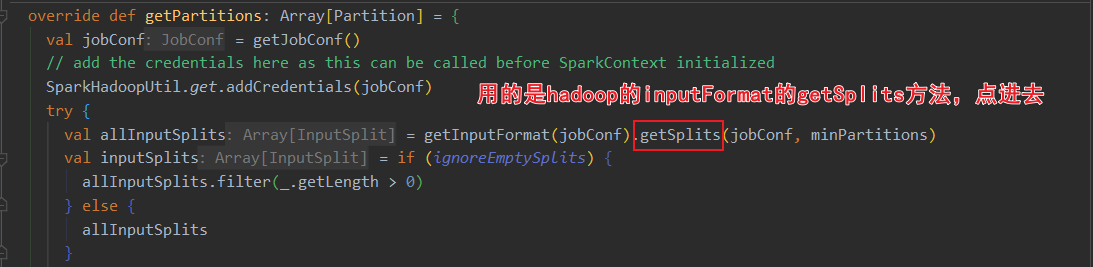
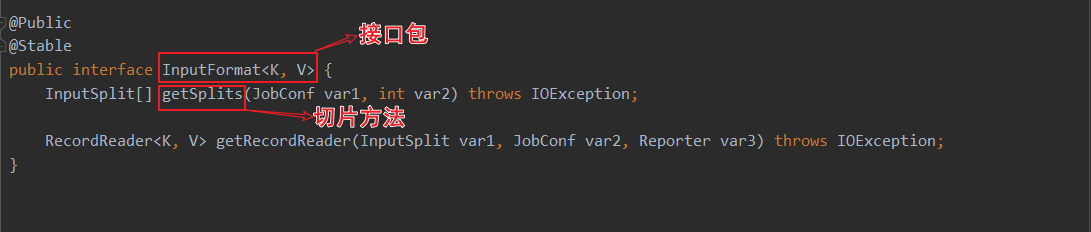
当前spark3.0的HadoopRDD依赖于hadoop的切片规则。其中HadoopRDD用的是旧版hadoop API,还有个NewHadoopRDD用的是新版hadoop API

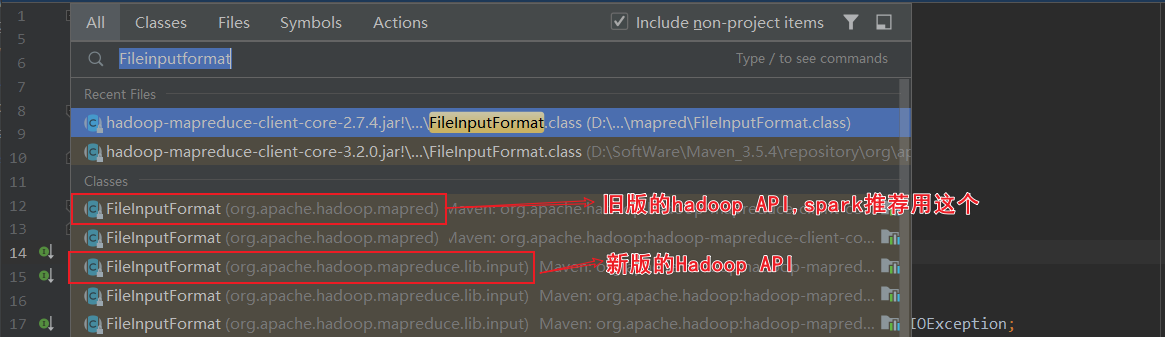
进去TextInputFromat的查看split方法
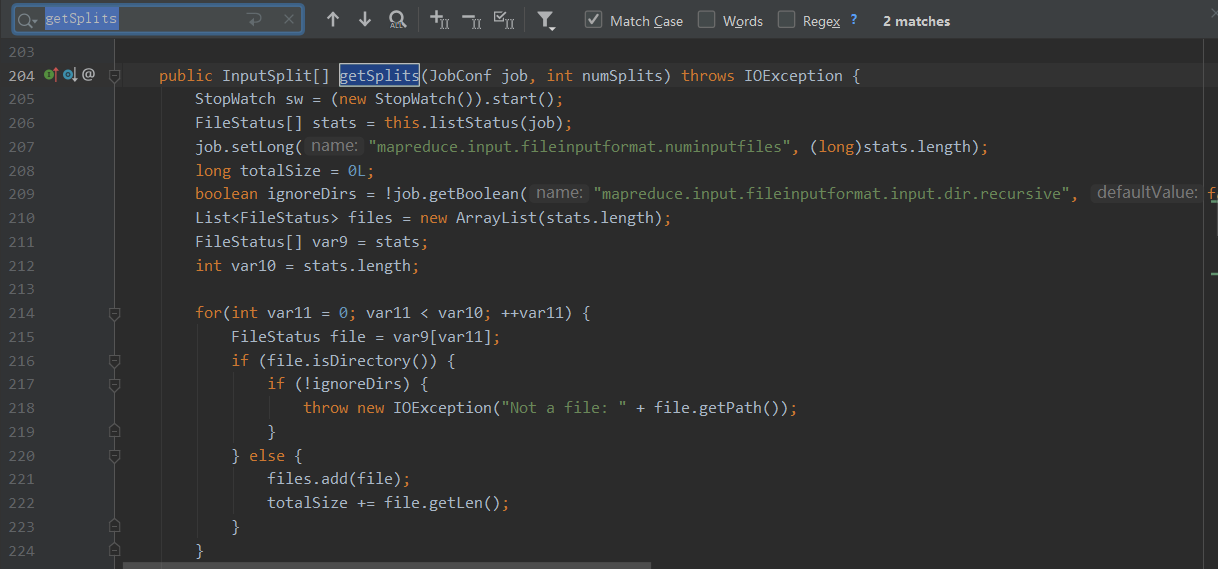
public InputSplit[] getSplits(JobConf job, int numSplits)
throws IOException {
// 获取要操作的所有文件的属性信息
FileStatus[] files = listStatus(job);
// 所有文件的总大小
long totalSize = 0; // compute total size
// 目标切片大小 numSplits=defaultMinPartitions
long goalSize = totalSize / (numSplits == 0 ? 1 : numSplits);
//默认为1
long minSize = Math.max(job.getLong(org.apache.hadoop.mapreduce.lib.input.
FileInputFormat.SPLIT_MINSIZE, 1), minSplitSize);
// generate splits
ArrayList<FileSplit> splits = new ArrayList<FileSplit>(numSplits);
NetworkTopology clusterMap = new NetworkTopology();
// 切片是以文件为单位切
for (FileStatus file: files) {
//获取文件大小
long length = file.getLen();
//文件不为空
if (length != 0) {
// 文件是否可切,一般普通文件都可切,如果是压缩格式,只有lzo,Bzip2可切
if (isSplitable(fs, path)) {
// 获取文件的块大小 默认128M
long blockSize = file.getBlockSize();
// 计算片大小
long splitSize = computeSplitSize(goalSize, minSize, blockSize);
long bytesRemaining = length;
// 循环切片,以splitSize为基础进行切片 , 切的片大小,最后一片有可能小于片大小的1.1倍
while (((double) bytesRemaining)/splitSize > SPLIT_SLOP) {
String[][] splitHosts = getSplitHostsAndCachedHosts(blkLocations,
length-bytesRemaining, splitSize, clusterMap);
// makeSplit()切片
splits.add(makeSplit(path, length-bytesRemaining, splitSize,
splitHosts[0], splitHosts[1]));
bytesRemaining -= splitSize;
}
//剩余部分,不够一片,全部作为1片
if (bytesRemaining != 0) {
String[][] splitHosts = getSplitHostsAndCachedHosts(blkLocations, length
- bytesRemaining, bytesRemaining, clusterMap);
splits.add(makeSplit(path, length - bytesRemaining, bytesRemaining,
splitHosts[0], splitHosts[1]));
}
} else {
String[][] splitHosts = getSplitHostsAndCachedHosts(blkLocations,0,length,clusterMap);
splits.add(makeSplit(path, 0, length, splitHosts[0], splitHosts[1]));
}
} else {
// 文件为空,创建一个空的切片
//Create empty hosts array for zero length files
splits.add(makeSplit(path, 0, length, new String[0]));
}
}
sw.stop();
if (LOG.isDebugEnabled()) {
LOG.debug("Total # of splits generated by getSplits: " + splits.size()
+ ", TimeTaken: " + sw.now(TimeUnit.MILLISECONDS));
}
return splits.toArray(new FileSplit[splits.size()]);
}
计算片大小:片大小的计算以所有文件的总大小计算,切片时以文件为单位进行切片。
protected long computeSplitSize(long goalSize, long minSize,
long blockSize) {
// minSize默认为1
return Math.max(minSize, Math.min(goalSize, blockSize));
}
总结:在大数据的计算领域,一般情况下,块大小就是片大小!
分区数过多,会导致切片大小 < 块大小。
分区数过少,task个数也会少,数据处理效率低,合理设置分区数。
Spark(二)【sc.textfile的分区策略源码分析】的更多相关文章
- RocketMQ中Broker的HA策略源码分析
Broker的HA策略分为两部分①同步元数据②同步消息数据 同步元数据 在Slave启动时,会启动一个定时任务用来从master同步元数据 if (role == BrokerRole.SLAVE) ...
- 66、Spark Streaming:数据处理原理剖析与源码分析(block与batch关系透彻解析)
一.数据处理原理剖析 每隔我们设置的batch interval 的time,就去找ReceiverTracker,将其中的,从上次划分batch的时间,到目前为止的这个batch interval ...
- Netty源码分析 (十二)----- 心跳服务之 IdleStateHandler 源码分析
什么是心跳机制? 心跳说的是在客户端和服务端在互相建立ESTABLISH状态的时候,如何通过发送一个最简单的包来保持连接的存活,还有监控另一边服务的可用性等. 心跳包的作用 保活Q:为什么说心跳机制能 ...
- 【一起学源码-微服务】Nexflix Eureka 源码十二:EurekaServer集群模式源码分析
前言 前情回顾 上一讲看了Eureka 注册中心的自我保护机制,以及里面提到的bug问题. 哈哈 转眼间都2020年了,这个系列的文章从12.17 一直写到现在,也是不容易哈,每天持续不断学习,输出博 ...
- Java - "JUC线程池" 线程状态与拒绝策略源码分析
Java多线程系列--“JUC线程池”04之 线程池原理(三) 本章介绍线程池的生命周期.在"Java多线程系列--“基础篇”01之 基本概念"中,我们介绍过,线程有5种状态:新建 ...
- java容器二:List接口实现类源码分析
一.ArrayList 1.存储结构 动态数组elementData transient Object[] elementData; 除此之外还有一些数据 //默认初始容量 private stati ...
- okhttp缓存策略源码分析:put&get方法
对于OkHttp的缓存策略其实就是在下一次请求的时候能节省更加的时间,从而可以更快的展示出数据,那在Okhttp如何使用缓存呢?其实很简单,如下: 配置一个Cache既可,其中接收两个参数:一个是缓存 ...
- 小记--------spark的Master的Application注册机制源码分析及Master的注册机制原理分析
原理图解: Master类位置所在:spark-core_2.11-2.1.0.jar的org.apache.spark.deploy.master下的Master类 //截取了部分代码 //处理 ...
- Spring Ioc源码分析系列--Bean实例化过程(二)
Spring Ioc源码分析系列--Bean实例化过程(二) 前言 上篇文章Spring Ioc源码分析系列--Bean实例化过程(一)简单分析了getBean()方法,还记得分析了什么吗?不记得了才 ...
随机推荐
- 斐波那契数列 牛客网 剑指Offer
斐波那契数列 牛客网 剑指Offer 题目描述 大家都知道斐波那契数列,现在要求输入一个整数n,请你输出斐波那契数列的第n项(从0开始,第0项为0). n<=39 class Solution: ...
- 大数据中必须要掌握的 Flink SQL 详细剖析
Flink SQL 是 Flink 实时计算为简化计算模型,降低用户使用实时计算门槛而设计的一套符合标准 SQL 语义的开发语言. 自 2015 年开始,阿里巴巴开始调研开源流计算引擎,最终决定基于 ...
- lumen、laravel问题汇总
框架报500 1.chmod 777 -R storage 将日志目录权限设置下. 2.修改fastcgi,将代码目录包含进去. fastcgi_param PHP_ADMIN_VALUE " ...
- 执行新程序 execve()
新程序的执行 一:execve() 之所以叫新程序的执行,原因是这部分内容一般发生在fork()和vfork()之后,在子进程中通过系统调用execve()可以将新程序加载到子进程的内存空间.这个操作 ...
- crond 任务调度
crontab 进行定时任务的设置 任务调度:是指系统在某个时间执行的特定的命令或程序. 任务调度分类: 系统工作:有些重要的工作必须周而复始地执行.如病毒扫描等 个别用户工作:个别用户可能希望执行某 ...
- C++ substr 的两个用法
substr是C++语言函数,主要功能是复制子字符串,要求从指定位置开始,并具有指定的长度. basic_string substr(size_type _Off = 0,size_type _C ...
- 【JavaScript实用技巧(二)】Js操作DOM(由问题引发的文章改版,新人大佬都可)
[JavaScript实用技巧(二)]Js操作DOM(由问题引发的文章改版,新人大佬都可!) 博客说明 文章所涉及的资料来自互联网整理和个人总结,意在于个人学习和经验汇总,如有什么地方侵权,请联系本人 ...
- 【JAVA】笔记(7)--- 数组精讲
数组的静态初始化: 1.一维数组: int [ ] arr = { 1,2,3,4 } ; Object [ ] arr = { new Object ( ) , new Object ( ) , ...
- Windows漏洞:MS08-067远程代码执行漏洞复现及深度防御
摘要:详细讲解MS08-067远程代码执行漏洞(CVE-2008-4250)及防御过程 本文分享自华为云社区<Windows漏洞利用之MS08-067远程代码执行漏洞复现及深度防御>,作者 ...
- 菜鸡的Java笔记 图书馆
图书大厦 开发要求 现在要求模拟一个图书大厦图书管理的程序结构,可以在图书大厦实现某一类图书的上架操作,下架操作,以及关键字模糊查询的操作 注 ...