Robust De-noising by Kernel PCA
引
这篇文章是基于对Kernel PCA and De-Noisingin Feature Spaces的一个改进。
针对高斯核:
\]
我们希望最小化下式(以找到\(x\)的一个近似的原像):
\]
获得了一个迭代公式:
\]
其中\(w_i=\sum_{h=1}^Hy_h u_i^h\),\(u\)通过求解kernel PCA获得(通常是用\(\alpha\)表示的),\(z(0)=x\)。
主要内容
虽然我们可以通过撇去小特征值对应的方向,但是这对于去噪并不足够。Kernel PCA and De-Noisingin Feature Spaces中所提到的方法,也就是上面的那个迭代的公式,也没有很好地解决这个问题。既然\(\{y_h\}\)并没有改变——也就是说,我们可能一直在试图用带噪声的数据去恢复一个不带噪声的数据。
所以,作者论文,在迭代更新过程中,\(y_h\)也应该进行更新。
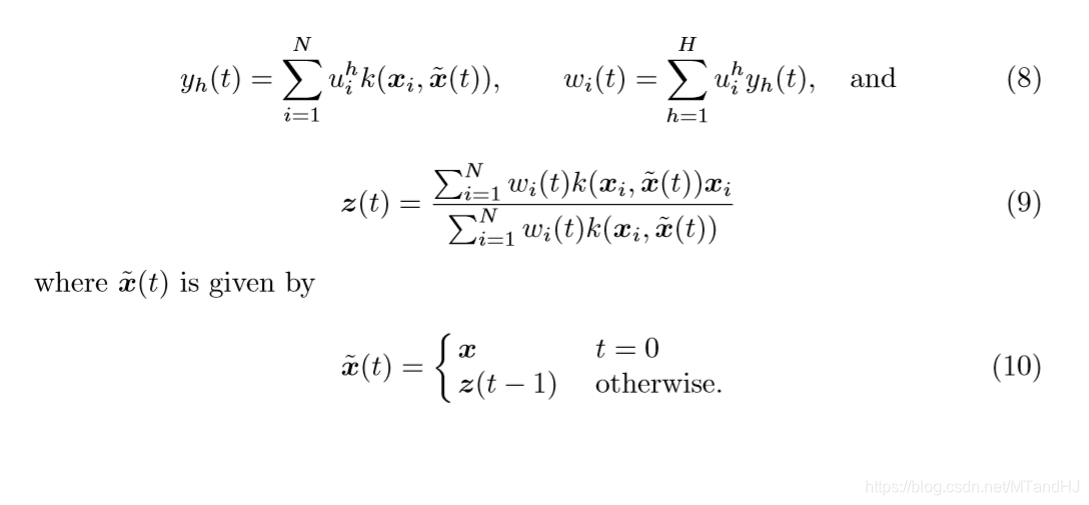
这样,每一步我们都可以看作是在寻找:
\]
的最小值。
从\((10)\)可以发现,除非\(\widetilde{x}(t)=z(t-1)\)是\(x\)的一个比较好的估计,否则,通过这种方式很有可能会失败(这里的失败定义为,最后的结果与\(x\)差距甚远)。这种情况我估计是很容易发生的。所以,作者提出了一种新的,更新\(\widetilde{x}(t)\)的公式:
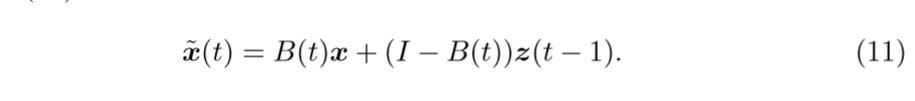
其中\(B(t)\)为确定度,是一个\(M \times M\)的矩阵,定义为:
\beta_j(t) = \exp (-(x_j - z_j (t-1))^2/2\sigma_j^2)
\]
对角线元素,反映了\(x_j\)和\(z_j(t-1)\)的差距,如果二者差距不大,说明\(P_H(x)\)和\(x\)的差距不大,\(x\)不是异常值点,所以,结果和\(x\)的差距也不会太大,否则\(x\)会被判定为一个异常值点,自然\(z\)应该和\(x\)的差别大一点。
\(\sigma_j\)的估计是根据另一篇论文来的,这里只给出估计的公式:
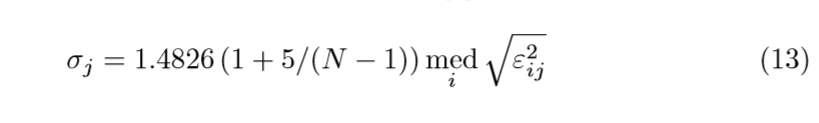
\(\mathrm{med}(x)\)表示\(x\)的中位数,\(\varepsilon_{ij}\)表示第\(i\)个训练样本第\(j\)个分量与其重构之间平方误差。话说,这个重构如何获得呢?
Robust De-noising by Kernel PCA的更多相关文章
- A ROBUST KERNEL PCA ALGORITHM
目录 引 主要内容 问题一 问题二 Lu C, Zhang T, Du X, et al. A robust kernel PCA algorithm[C]. international confer ...
- Kernel Methods (5) Kernel PCA
先看一眼PCA与KPCA的可视化区别: 在PCA算法是怎么跟协方差矩阵/特征值/特征向量勾搭起来的?里已经推导过PCA算法的小半部分原理. 本文假设你已经知道了PCA算法的基本原理和步骤. 从原始输入 ...
- Kernel PCA 原理和演示
Kernel PCA 原理和演示 主成份(Principal Component Analysis)分析是降维(Dimension Reduction)的重要手段.每一个主成分都是数据在某一个方向上的 ...
- 【模式识别与机器学习】——PCA与Kernel PCA介绍与对比
PCA与Kernel PCA介绍与对比 1. 理论介绍 PCA:是常用的提取数据的手段,其功能为提取主成分(主要信息),摒弃冗余信息(次要信息),从而得到压缩后的数据,实现维度的下降.其设想通过投影矩 ...
- Probabilistic PCA、Kernel PCA以及t-SNE
Probabilistic PCA 在之前的文章PCA与LDA介绍中介绍了PCA的基本原理,这一部分主要在此基础上进行扩展,在PCA中引入概率的元素,具体思路是对每个数据$\vec{x}_i$,假设$ ...
- Kernel PCA and De-Noisingin Feature Spaces
目录 引 主要内容 Kernel PCA and De-Noisingin Feature Spaces 引 kernel PCA通过\(k(x,y)\)隐式地将样本由输入空间映射到高维空间\(F\) ...
- Kernel PCA for Novelty Detection
目录 引 主要内容 的选择 数值实验 矩形框 spiral 代码 Hoffmann H. Kernel PCA for novelty detection[J]. Pattern Recognitio ...
- Missing Data in Kernel PCA
目录 引 主要内容 关于缺失数据的导数 附录 极大似然估计 代码 Sanguinetti G, Lawrence N D. Missing data in kernel PCA[J]. europea ...
- 核化主成分分析(Kernel PCA)应用及调参
核化这个概念在很多机器学习方法中都有应用,如SVM,PCA等.在此结合sklearn中的KPCA说说核函数具体怎么来用. KPCA和PCA都是用来做无监督数据处理的,但是有一点不一样.PCA是降维,把 ...
随机推荐
- 日常Java 2021/11/6
Java多线程编程 Java给多线程编程提供了内置的支持.一条线程指的是进程中一个单一顺序的控制流,一个进程中可以并发多个钱程,每条线程并行执行不同的任务.多线程是多任务的一种特别的形式,但多线程使用 ...
- 学习java 7.16
学习内容: 线程安全的类 Lock锁 生产者消费者模式 Object类的等待唤醒方法 明天内容: 网络编程 通信程序 遇到问题: 无
- Flink(六)【ParameterTool类】
ParameterTool 工具类 object ParameterToolTest { def main(args: Array[String]): Unit = { val params: Par ...
- Spark 广播变量和累加器
Spark 的一个核心功能是创建两种特殊类型的变量:广播变量和累加器 广播变量(groadcast varible)为只读变量,它有运行SparkContext的驱动程序创建后发送给参与计算的节点.对 ...
- Swift alert 倒计时
let title: String = "您的开奖时间为" let time: String = "2017-10-23 12:23:18" let count ...
- vue项目windows环境初始化
下载nodejs zip包并加载到环境变量 nodejs的版本最好使用12版,而不是最新版 npm install webpack -gnpm install -g yarnyarn config s ...
- Linux系统分区及挂载点
一.关于Linux的分区情况 虽然硬盘分区表中最多能存储四个分区,但我们实际使用时一般只分为两个分区,一个是主分区(Primary Partion)一个是扩展分区(extended partition ...
- JSP中声明变量、方法
在JSP页面中声明局部变量,全局变量,方法等 代码示例: <%@ page language="java" contentType="text/html; char ...
- Docker从入门到精通(一)——初识
1.Docker 是什么? Docker 是一个开源的应用容器引擎,基于 Go 语言 并遵从 Apache2.0 协议开源. Docker 可以让开发者打包他们的应用以及依赖包到一个轻量级.可移植的容 ...
- Mysql状态信息查询
目录 一.连接相关 二.show status 三.其它 一.连接相关 查看连接线程相关的系统变量的设置值 show variables like 'thread%'; 查看系统被连接的次数 show ...