The Limitations of Deep Learning in Adversarial Settings
概
利用Jacobian矩阵构造adversarial samples,计算量比较大.
主要内容
目标:
\mathop{\arg \min} \limits_{\delta_X} \|\delta_X\|, \mathbf{s.t.} \: F(X+\delta_X)=Y^*.
\]
简而言之, 在原图像\(X\)上加一个扰动\(\delta_X\), 使得\(F\)关于\(X+\delta_X\)的预测为\(Y^*\)而非\(Y\).
若\(Y \in \mathbb{R}^M\)是一个\(M\)维的向量, 类别由下式确定
\]
\(F(X)=Y\)关于\(X\)的Jacobian矩阵为
\]
注意, 这里作者把\(X\)看成一个\(N\)维向量(只是为了便于理解).
因为我们的目的是添加扰动\(\delta_X\), 使得\(X+\delta_X\)的标签为我们指定的\(t\), 即我们希望
\]
作者希望改动部分元素, 即\(\|\delta_X\|_0\le \Upsilon\), 作者是构造了一个saliency_map来选择合适的\(i\), 并在其上进行改动, 具体算法如下:

saliency_map的构造之一是:
\begin{array}{ll}
0, & if \: \frac{\partial{F_t(X)}}{\partial X_i} <0 \:or \: \sum_{j \not= t} \frac{\partial F_j(X)}{\partial X_i} >0, \\
\frac{\partial{F_t(X)}}{\partial X_i} |\sum_{j \not= t} \frac{\partial F_j(X)}{\partial X_i}|, & otherwise.
\end{array}
\]
可以很直观的去理解, 改变标签, 自然希望\(F_t(X)\)增大, 其余部分减少, 故 \(\frac{\partial{F_t(X)}}{\partial X_i} <0 \:or \: \sum_{j \not= t} \frac{\partial F_j(X)}{\partial X_i} >0\)所对应的\(X_i\)自然是不重要的, 其余的是重要的, 其重要性用\(\frac{\partial{F_t(X)}}{\partial X_i} |\sum_{j \not= t} \frac{\partial F_j(X)}{\partial X_i}|\)来表示.
alg2, alg3
作者顺便提出了一个更加具体的算法, 应用于Mnist, max_iter 中的\(784\)即为图片的大小\(28 \times 28\), \(\Upsilon=50\), 相当于图片中\(50\%\)的像素发生了改变, 且这里采用了一种新的saliency_map, 其实质为寻找俩个指标\(p,q\)使得:
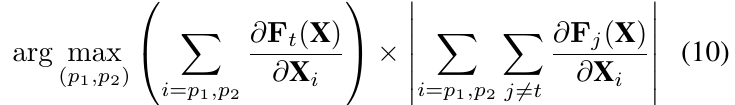
其实际的操作流程根据算法3. \(\theta\)是每次改变元素的量.


一些有趣的实验指标
Hardness measure
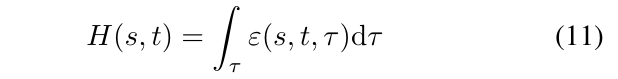
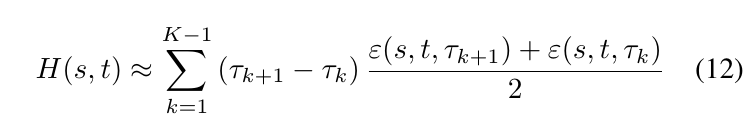
其中\(\epsilon(s,t,\tau)\)中, \(s\):图片标签, \(t\):目标标签, \(\tau\):成功率, \(\epsilon\)为改变像素点的比例. (12)是(11)的一个梯形估计, \(\tau_k\)由选取不同的\(\Upsilon_k\)来确定, \(H(s, t)\)越大说明将类别s改变为t的难度越大.
Adversarial distance
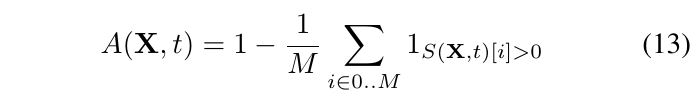
\(A(X,t)\)越大, 说明将图片\(X\)的标签变换至\(t\)的难度越大, 而一个模型的稳定性可以用下式衡量
R(F)=\min_{X,t} A(X,t).
\]
The Limitations of Deep Learning in Adversarial Settings的更多相关文章
- What are some good books/papers for learning deep learning?
What's the most effective way to get started with deep learning? 29 Answers Yoshua Bengio, ...
- Applied Deep Learning Resources
Applied Deep Learning Resources A collection of research articles, blog posts, slides and code snipp ...
- (转)Deep Learning Research Review Week 1: Generative Adversarial Nets
Adit Deshpande CS Undergrad at UCLA ('19) Blog About Resume Deep Learning Research Review Week 1: Ge ...
- 论文笔记之:UNSUPERVISED REPRESENTATION LEARNING WITH DEEP CONVOLUTIONAL GENERATIVE ADVERSARIAL NETWORKS
UNSUPERVISED REPRESENTATION LEARNING WITH DEEP CONVOLUTIONAL GENERATIVE ADVERSARIAL NETWORKS ICLR 2 ...
- Towards Deep Learning Models Resistant to Adversarial Attacks
目录 概 主要内容 Note Madry A, Makelov A, Schmidt L, et al. Towards Deep Learning Models Resistant to Adver ...
- (转) The major advancements in Deep Learning in 2016
The major advancements in Deep Learning in 2016 Pablo Tue, Dec 6, 2016 in MACHINE LEARNING DEEP LEAR ...
- 博弈论揭示了深度学习的未来(译自:Game Theory Reveals the Future of Deep Learning)
Game Theory Reveals the Future of Deep Learning Carlos E. Perez Deep Learning Patterns, Methodology ...
- [C3] Andrew Ng - Neural Networks and Deep Learning
About this Course If you want to break into cutting-edge AI, this course will help you do so. Deep l ...
- 0.读书笔记之The major advancements in Deep Learning in 2016
The major advancements in Deep Learning in 2016 地址:https://tryolabs.com/blog/2016/12/06/major-advanc ...
随机推荐
- python 多态、组合、反射
目录 多态.多态性 多态 多态性 鸭子类型 父类限制子类的行为 组合 面向对象的内置函数 反射 多态.多态性 多态 多态通俗理解起来,就像迪迦奥特曼有三种形态一样,怎么变还是迪迦奥特曼 定义:多态指的 ...
- [C++] vptr, where are you?
Search(c++在线运行). 有的网站很慢--不是下面的程序有问题. #include <string.h> #include <stdio.h> #include < ...
- day14搭建博客系统项目
day14搭建博客系统项目 1.下载代码包 [root@web02 opt]# git clone https://gitee.com/lylinux/DjangoBlog.git 2.使用pid安装 ...
- day05文件编辑命令
day05文件编辑命令 mv命令:移动文件 mv命令:mv命令用来对文件或目录重新命名,或者将文件从一个目录移到另一个目录中. 格式:mv [原来的文件路径] [现在的文件路径] mv命令后面既可以跟 ...
- Linux学习 - 修改、查询文件内容
一.显示文件内容 cat [-n] [文件名] 正向显示 -n 显示行号 tac [文件名] 反向显示 more [文件名] 可实现分页显示 (空格)或(f) 翻页 (Enter) 换行 (q ...
- clickhouse安装数据导入及查询测试
官网 https://clickhouse.tech/ quick start ubantu wget https://repo.yandex.ru/clickhouse/deb/lts/main/c ...
- 【Linux】【Shell】【text】文本处理工具
文本查看及处理工具:wc, cut, sort, uniq, diff, patch wc:word count wc [OPTION]... [FILE]... -l: lines -w:words ...
- 【JavaScript】创建全0的Array
1.创建一个长度为m的全0数组 var arr = new Array(m).fill(0); 2.创建一个m行n列的全0数组 var arr = new Array(m).fill(new Arra ...
- 【C/C++】最长不下降子序列/动态规划
#include <iostream> #include <vector> using namespace std; int main() { //输入 int tmp; ve ...
- .net core Winform 添加DI和读取配置、添加log
首先新建配置类 public class CaptureOption { /// <summary> /// 是否自启 /// </summary> public bool A ...