论文翻译:2019_Deep Neural Network Based Regression Approach for A coustic Echo Cancellation
论文地址:https://dl.acm.org/doi/abs/10.1145/3330393.3330399
基于深度神经网络的回声消除回归方法
摘要
声学回声消除器(AEC)的目的是消除近端传声器接收到的混合信号中的声学回声。传统的方法是使用自适应有限脉冲响应(FIR)滤波器来识别房间脉冲响应(RIR),因为房间脉冲响应对各种野外场景都不具有鲁棒性。在本文中,我们提出了一种基于深度神经网络的回归方法,从近端和远端混合信号中提取的特征直接估计近端目标信号的幅值谱。利用深度学习强大的建模和泛化能力,可以很好地消除复杂的回声信号。实验结果表明,该方法在双讲、背景噪声、RIR变化和非线性失真场景下是有效的。此外,该方法对真实的车辆声学回声具有较好的泛化性。
关键字:回声消除;深度学习;神经网络;回归。
1 引言
在通信系统中,回声问题已经讨论了几十年。由于扬声器与近端麦克风之间的声耦合,麦克风从近端扬声器中接收到混合了延迟声音的目标信号,或者说是来自远端扬声器的回声信号。回声信号的音素和音节都是清晰可识别的,这使得混合语音具有误导性。因此,回声的存在极大地损害了目标语音的感知能力和可理解性。
为了解决这个问题,传统的声学回声消除(AEC)方法估计扬声器和近端麦克风的回声脉冲响应(也称为房间脉冲响应(RIR)),利用远端说话者的参考信号和近端麦克风的混合信号。传统的估计RIR的方法是采用一种自适应有限脉冲响应(FIR)滤波器,并通过几种自适应算法[1][2]更新滤波器系数。
装备AEC的通信系统广泛应用于许多野外场景。双讲是现实世界中比较复杂的一种情况,即来自近端扬声器的参考信号与来自近端扬声器的目标信号同时处于活动状态。近端语音信号的存在严重降低了自适应算法的收敛性。为了解决这一问题,提出了双讲检测器(DTD)[3][4]来抑制双讲期间的自适应。此外,在近端麦克风接收到的信号中,除了回声和近端语音外,通常还存在背景噪声。然而,自适应回声消除器不能单独抑制背景噪声,因此在[5]中引入了后置滤波器。同时,回放设备造成的回声信号非线性失真不可避免地增加了AEC的难度。因此,提出了残差回波抑制(RES)[6][7]来抑制非线性回波失真。
考虑到实际场景中存在多种干扰,建议采用具有鲁棒性、低延迟、低复杂度和良好性能的AEC估计算法。除了传统的AEC方法,最近出现的深度学习技术有望解决复杂的回声问题,这是我们感兴趣的。
受新引入的监督语音分离范式[8]的启发,我们尝试采用基于深度学习的方法从近端麦克风接收到的混合信号中分离近端目标语音。同时,远端参考语音可以作为附加信息。利用深度神经网络(DNN)强大的建模和泛化能力,我们提出的方法可以很好地直接分离混合语音,而无需进行上述额外的操作,既可以处理模拟情况,也可以处理真实生活中的复杂场景,包括双讲、背景噪声和非线性失真。
本文的其余部分组织如下。第2节介绍了相关工作。第3节介绍了所提出的方法。第4节给出了实验结果。第5节是论文的总结和下一步工作。
2 相关工作
在之前的研究中,M. Muller提出了一种频率相关的语音活动检测(VAD),利用[8]中混合信号训练的2层DNN检测近端信号的活动。基于DNN的VAD模型是对传统回声消除技术的补充,其实质仍然是通过预测RIR来减小回声。尽管如此,DNN增强方法的性能仍优于传统方法。
在[9]中,Guillaume Carbajal提出了一种基于神经网络的方法,直接从多个输入中估计相位敏感掩模(PSM),包括AEC输出、远端语音和AEC计算的回声。该方法在回声损耗增强(ERLE)[12]和信号失真比(SDR)[13]方面均显著优于Valin[10]和Schwar [11] RES。
在研究的后期,我们注意到最近提出了一种非常类似于我们的方法[14],其中AEC也被视为一种监督式语音分离问题。本文利用双向长短时记忆循环神经网络(BLSTM),在双讲、背景噪声和非线性失真的情况下,从近端和远端混合信号中提取特征来估计理想的比率掩码。基于BLSTM的语音质量感知评价方法在ERLE和语音质量感知评价[15]方面均优于传统方法,后者与主观评分具有较高的相关性。然而,考虑到AEC算法的低延迟和低复杂度要求,基于BLSTM的方法需要整个语音,消耗大量的计算资源,不适合实际应用。我们从一开始就着眼于AEC的真实场景,使用DNN对目标信号的对数幅值谱进行预测,这是一种简单而有效的在线方法。
3 提出方法
3.1 基于DNN的回声消除回归模型
近端麦克风\(y(n)\)的混合信号由近端扬声器的目标信号\(s(n)\)、背景噪声\(v(n)\)和回声信号\(d(n)\)组成。回声信号由远端扬声器的参考信号\(x(n)\)与RIR卷积产生:
\]
\]
传统的回声消除尝试使用自适应滤波器合成回声信号的副本,并从混合信号中减去它。与此有很大不同的是,我们的方法引入了基于DNN的回归模型,以麦克风信号\(y(n)\)预测目标信号\(s(n)\),并将信号\(x(n)\)作为输入。具体来说,DNN直接输出目标信号经\(\mu\)律压缩后的估计对数谱图。最后,利用提取的混合信号相位和估计的目标信号幅度谱,利用短时傅里叶反变换(ISTFT)对估计的目标信号进行重构。。
3.2 DNN 模型建立
模型结构如图1所示,包括输入层、隐藏层和输出层。
首先将输入信号(\(y(n)\)和\(x(n)\))以16khz采样,分成32ms帧,帧移16ms。然后对输入信号的每个时间帧应用512点短时傅里叶变换(STFT),产生257个频率点。最后,对每帧的幅值响应进行\(\mu\)律压缩,得到幅值光谱特征。在该方法中,输入的帧上下文为27帧(13个未来帧和13个过去帧);将混合信号和参考信号的特征串接起来作为输入特征。因此输入的维数为\(257 \times 27 \times 2 = 13554\)。
该模型包含五层:输入层,输入大小为13554,三个隐藏层,每层有2048个节点,输出层有257个节点。校正线性单元(ReLU)激活函数[16]用于隐藏层和输出层的数值范围。在激活函数[17]之前,对每个隐层进行批处理规范化。采用Adam优化器[18]使均方误差(MSE)代价函数最小。设置学习速率为\(1e-5\),设置训练epoch数为100。
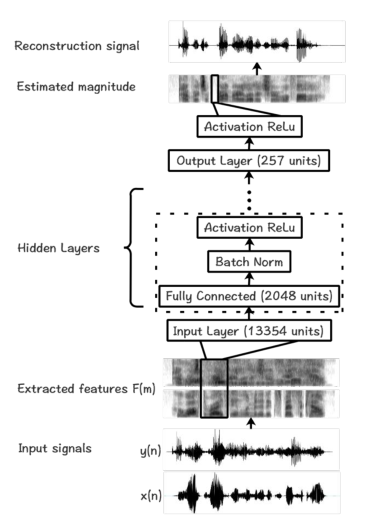
图1 所提出的基于DNN的方法示意图
4 实验
下面,比较我们的方法与传统的AEC: Valin[10]实现的SpeexDSP,一个使用可变步长的AEC鲁棒双讲检测,在各种场景下。
4.1 数据集
在实验中,我们主要使用仿真数据,因为很多情况下,包括双讲,背景噪声和非线性失真可以方便地合成。此外,我们还在真实数据集上检验了我们的模型的泛化能力。
模拟时,首先根据预先设定的房间配置生成RIR\(r(n)\);然后将选定的参考信号\(x(n)\)与\(r(n)\)卷积,生成回声信号\(d(n)\);最后将\(d(n)\)与目标信号\(s(n)\)进行移位相加生成混合信号\(y(n)\),以模拟目标信号与参考信号之间的延时。
对于RIR,我们使用基于图像源方法[20]的python工具包Pyroomacoustics [19]来生成RIR,给出了房间的形状、大小、温度、湿度、气压、墙壁的吸收系数、麦克风位置和扬声器位置等房间配置。由于实际情况,该方法优于基于RT60[21]的方法。在我们的实验中,模拟室的大小(长×宽×高)为\(5 \times 4 \times 3 m\)。各边的吸收系数为0.1,室内温度、相对湿度、气压分别为\(20^{\circ} \mathrm{C} 、 0 、 10^{5} \mathrm{~Pa}\)。
对于原始信号,我们选择目标信号并参考TIMIT数据集[22]中的信号,该数据集包含630个美国英语八种主要方言的说话者的宽带录音,每个人阅读10个语音丰富的句子。TIMIT语料库包括时间对齐的正字法、语音和单词转录,以及每个话语的16位、16kHz语音波形文件。官方将TIMIT分为两部分:训练和测试。训练包含462个扬声器,测试包含剩余的168个扬声器。从TIMIT列中随机选取6000对近端信号和远端信号作为训练集,从TIMIT列中随机选取200对验证集,从TIMIT列中随机选取200对测试集。
4.2 在双讲情况下的表现
在双讲的情况下,目标信号和参考信号同时活跃。显然,回声信号的功率越大,从混合信号中分离目标信号就越困难。这里的信号回声比(SER)水平是在双讲周期上评估的。定义为:
\]
同时,回声信号与目标信号重叠越多,从混合信号中分离目标信号就越困难。这里的相对重叠率(ROR)水平是根据双讲周期来评估的。定义为:
\]
对于相同的ROR,回声信号可以在目标信号之前开始,反之亦然。由于传统方法的自适应算法的限制,开始的顺序将导致不同的结果。
我们评估了双讲情况下的提出方法,并将其与传统方法进行比较。为了进行训练和测试,通过将参考信号与RIR卷积来产生回波信号,源位置和麦克风位置分别(2.5,2,2)和(2.5,2,1)。并且目标信号与来自-15到5dB(间隔为0.1)的SER范围的回声信号混合,ROR范围为0.5到1(间隔为0.001)。
图2-(a)显示了不同SER条件下的两种方法的平均PESQ值。本图所示的结果表明,基于DNN的方法优于所有条件下PESQ改善的传统方法,并且较大的SER,得到的提升越大。
图2-(b)显示了不同ROR条件下两种方法的平均PESQ值。本图所示的结果表明,基于DNN的方法在PESQ方面优于传统方法。当回声信号在目标信号之前开始时,将更容易分离目标信号。更重要的是,我们方法的不同开始顺序之间的间隙小于所有条件中的传统方法。
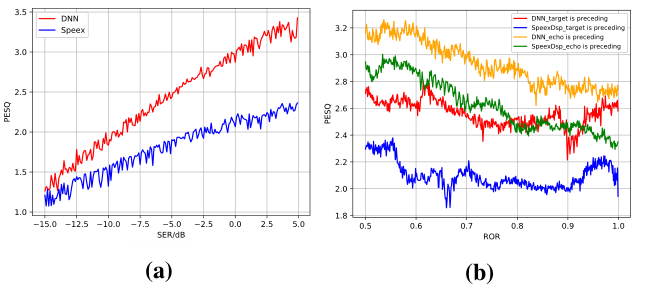
图2 在双讲情况下,SER(a)和ROR(b)的平均PESQ值
4.3 双讲,背景噪声情况下的性能
第二个实验研究了双讲和背景噪音的情况。高斯白噪声以不同的信号噪声比(SNR)添加到混合信号中,该信号被定义为:
\]
对于训练,SER设定为5; ROR设置为1,SNR范围为-5至5,间隔为0.1。对于测试,SER设置为5; ROR设置为1,SNR随机选自{-4.55,-2.55,0.55,2.55,4.55}。在训练和测试中使用的RIR与第一个实验相同。
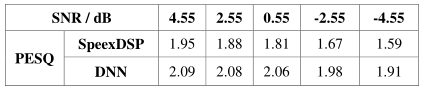
表1中示出了具有5dB SER水平的不同SNR条件下的常规方法和基于DNN的方法的平均PESQ值。从表1中可以看出,基于DNN的方法优于传统方法,对于所有条件,PESQ产生平均改善最高可达0.96。结果表明,基于DNN的方法比传统方法对抗噪声更具鲁棒性。
表1 在双讲和背景噪音情况下的平均PESQ值
4.4 在双讲,RIR变异情况下的性能
由于设备的移动,RIR可能在句子期间改变。我们使用第三个实验比较我们的方法和传统方法在RIR变异,双讲情况下的性能。
我们使用分段卷积来模拟RIR的变化。首先,我们通过使用零填充将引用信号划分为多个段,然后通过使用零填充将每个子引用信号填充到原始信号的长度。然后使用不同的RIR卷积子参考信号以获得子回声信号。最后,副回声信号被连接以获得回声信号。
我们在水平接地上直观地选择6000点作为麦克风和源头位置的水平分量。麦克风和源极位置的垂直分量分别限制为2M和1M。对于训练,RIR更改无法看到(换句话说,RIRS的数量更改为0),并且RIR变化的数量是随机选择用于测试的{0,1,11}。实验结果如表2所示。
表2 双讲和RIR变化情况下的平均PESQ值

从表可以看出,基于DNN的方法优于传统方法,并且PESQ几乎是我们在所有条件下的方法的常数。结果表明,基于DNN的方法对RIR短时变化具有比传统方法更好的鲁棒。
在我们看来,这个结果的主要原因如下。我们的方法是逐帧操作,一帧的时间仅为32毫秒。只有几个帧包含两个RIR,并且对于大多数帧,只包含一个RIR。
4.4 在双讲,非线性失真情况下的性能
我们使用第三个实验来比较我们的方法和传统方法在RIR短时改变、双讲情况中的性能。该实验评估了基于DNN的方法在用双讲,非线性失真的情况下的性能。由于简化,通过以下非线性函数处理参考信号以模拟由功率放大器和扬声器引入的非线性失真。
\]
\]
\]
\]
为了训练,处理参考信号以获取非线性处理的参考信号,然后将该非线性处理的远端信号与RIR卷积生成回声信号,其源位置和麦克风位置分别为(3,2,1)和(3.8,2,1.6)。SER设置为0 dB,ROR设置为\(>0.5\)。实验结果如表3所示。
表3 双讲和非线性失真情况下的平均PESQ值

从表3中可以看出,我们的方法比传统方法在四个非线性失真的条件下,PESQ得分大约高0.5。
4.6 真实数据集上的性能
在我们的最后一个实验中,测试和分析了我们方法的泛化能力。我们分别在模拟数据集和实时数据集上训练DNN模型,然后分别在不同的实时数据集上进行评估。有两个数据集,一个名为Car echoic数据集,录制在汽车中用于训练和测试,另一个是名为Studio echoic数据集,该数据集记录在Studio中仅用于测试。
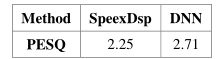
在汽车回声数据集中,通过汽车扬声器播放参考信号,并且目标信号由人造口在主驱动位置上播放。外部环境包括市中心,郊区,高速公路和高架桥。汽车型号包括雪佛兰克鲁泽,奇瑞蒂戈,吉普车,丰田,别克GL8和宝马。速度包括0,\(\leq 40\),41至60,100,120 km / h。总持续时间为18446s,根据18054:205:187的比例分为训练集,验证组和测试集。实验结果如表4所示。
表4 汽车回声数据集的平均PESQ值
在Studio echoic数据集中,工作室的可用大小是\(548.08 \times 419.46 \times 287.21 \mathrm{~cm}^{3}\)。我们在水平接地上挑选12个点作为麦克风和源头位置的水平分量。麦克风和光源位置的垂直分量分别限于79.54cm和58.12cm。使用的SER包括-15,-10,-5,0,5 dB。总持续时间为157s,仅用于测试。给定的仿真数据与Studio echoic数据集相同的配置用于训练。实验结果如表5所示。
表5 在Studio Echoic数据集的平均PESQ值

从表4中可以看出,训练的DNN在实际测试数据上超过了传统方法,在PESQ上产生高达0.46的改进。
从表5中可以看出,传统方法优于除SER为5dB之外的实际测试数据上的模拟数据上训练的DNN。与表4中显示的结果相比,即使我们在仿真中使用相同的参数,模拟数据和实际数据也存在很大的区别。我们的方法在实际录音中产生了鼓舞人心的表现,虽然该模型仅在模拟数据上训练而不访问真正的录音。
5 结论和未来的工作
我们提出了一种基于DNN的AEC方法,它提供了比传统自适应滤波方法更好的声学回声消除效果,在双讲、背景噪声、RIR变化和非线性失真的情况下。更重要的是,所提出的方法显示了其能够去除声学回声的实际记录。未来的工作主要是优化网络结构,并添加一些预处理和后处理方法,希望提高基于深度学习的方法的性能。
6 参考文献
[1] Benesty, J., Gänsler, T., Morgan, D. R., Sondhi, M. M., & Gay, S. L. (2001). Advances in network and acoustic echo cancellation. Berlin: Springer.
[2] Benesty, J., Paleologu, C., Gänsler, T., & Ciochină, S. (2011). A perspective on stereophonic acoustic echo cancellation (Vol. 4). Springer Science & Business Media.
[3] D. Duttweiler. A Twelve-Channel Digital Echo Canceler. In IEEE Transactions on Communications vol. 26, no. 5, pp. 647-653, May 1978
[4] Mahfoud Hamidia, Abderrahmane Amrouche. A new robust double-talk detector based on the Stockwell transform for acoustic echo cancellation. In Digital Signal Processing, Vol. 60, ISSN 1051-2004, Pages 99-112, 2017
[5] Turbin, V., Gilloire, A., & Scalart, P. (1997, April). Comparison of three post-filtering algorithms for residual acoustic echo reduction. In icassp (p. 307). IEEE.
[6] Schwarz, A., Hofmann, C., & Kellermann, W. (2013, October). Spectral feature-based nonlinear residual echo suppression. In Applications of Signal Processing to Audio and Acoustics (WASPAA), 2013 IEEE Workshop on (pp. 1-4). IEEE.
[7] Kuech, F., & Kellermann, W. (2007, April). Nonlinear residual echo suppression using a power filter model of the acoustic echo path. In Acoustics, Speech and Signal Processing, 2007. ICASSP 2007. IEEE International Conference on (Vol. 1, pp. I-73). IEEE.
[8] Xu, Y., Du, J., Dai, L. R., & Lee, C. H. (2015). A regression approach to speech enhancement based on deep neural networks. IEEE/ACM Transactions on Audio, Speech and Language Processing (TASLP), 23(1), 7-19.
[9] Carbajal, G., Serizel, R., Vincent, E., & Humbert, E. (2018, April). Multiple-input neural network-based residual echo suppression. In ICASSP 2018-IEEE International Conference on Acoustics, Speech and Signal Processing (pp. 1-5).
[10] Valin, J. M. (2007). On adjusting the learning rate in frequency domain echo cancellation with double-talk. IEEE Transactions on Audio, Speech, and Language Processing, 15(3), 1030-1034.
[11] Schwarz, A., Hofmann, C., & Kellermann, W. (2013, October). Spectral feature-based nonlinear residual echo suppression. In Applications of Signal Processing to Audio and Acoustics (WASPAA), 2013 IEEE Workshop on (pp. 1-4). IEEE.
[12] Enzner, G., Buchner, H., Favrot, A., & Kuech, F. (2014). Acoustic echo control. In Academic press library in signal processing (Vol. 4, pp. 807-877). Elsevier.
[13] Vincent, E., Gribonval, R., & Févotte, C. (2006). Performance measurement in blind audio source separation. IEEE transactions on audio, speech, and language processing, 14(4), 1462-1469.
[14] Zhang, H., & Wang, D. (2018). Deep Learning for Acoustic Echo Cancellation in Noisy and Double-Talk Scenarios. Training, 161(2), 322.
[15] Rix, A. W., Beerends, J. G., Hollier, M. P., & Hekstra, A. P. (2001). Perceptual evaluation of speech quality (PESQ)-a new method for speech quality assessment of telephone networks and codecs. In Acoustics, Speech, and Signal Processing, 2001. Proceedings. (ICASSP'01). 2001 IEEE International Conference on (Vol. 2, pp. 749-752). IEEE.
[16] Glorot, X., Bordes, A., & Bengio, Y. (2011, June). Deep sparse rectifier neural networks. In Proceedings of the fourteenth internationalconference on artificial intelligence and statistics (pp. 315-323).
[17] Ioffe, S., & Szegedy, C. (2015). Batch normalization: Accelerating deep network training by reducing internal covariate shift. arXiv preprint arXiv:1502.03167.
[18] Kingma, D. P., & Ba, J. (2014). Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980.
[19] Scheibler, R., Bezzam, E., & Dokmanić, I. (2018, April). Pyroomacoustics: A python package for audio room simulation and array processing algorithms. In 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) (pp. 351-355). IEEE.
[20] Allen, J. B., & Berkley, D. A. (1979). Image method for efficiently simulating small‐room acoustics. The Journal of the Acoustical Society of America, 65(4), 943-950.
[21] Lehmann, E. A., & Johansson, A. M. (2010). Diffuse reverberation model for efficient image-source simulation of
room impulse responses. IEEE Transactions on Audio, Speech, and Language Processing, 18(6), 1429-1439.
[22] Lamel, L. F., Kassel, R. H., & Seneff, S. (1989). Speech database development: Design and analysis of the acousticphonetic corpus. In Speech Input/Output Assessment and Speech Databases.
论文翻译:2019_Deep Neural Network Based Regression Approach for A coustic Echo Cancellation的更多相关文章
- 论文笔记:ReNet: A Recurrent Neural Network Based Alternative to Convolutional Networks
ReNet: A Recurrent Neural Network Based Alternative to Convolutional Networks2018-03-05 11:13:05 ...
- 论文笔记系列-Neural Network Search :A Survey
论文笔记系列-Neural Network Search :A Survey 论文 笔记 NAS automl survey review reinforcement learning Bayesia ...
- DeepCoder: A Deep Neural Network Based Video Compression
郑重声明:原文参见标题,如有侵权,请联系作者,将会撤销发布! Abstract: 在深度学习的最新进展的启发下,我们提出了一种基于卷积神经网络(CNN)的视频压缩框架DeepCoder.我们分别对预测 ...
- 论文阅读笔记六十四: Architectures for deep neural network based acoustic models defined over windowed speech waveforms(INTERSPEECH 2015)
论文原址:https://pdfs.semanticscholar.org/eeb7/c037e6685923c76cafc0a14c5e4b00bcf475.pdf 摘要 本文研究了利用深度神经网络 ...
- 论文翻译:Speech Enhancement Based on the General Transfer Function GSC and Postfiltering
论文地址:基于通用传递函数GSC和后置滤波的语音增强 博客作者:凌逆战 博客地址:https://www.cnblogs.com/LXP-Never/p/12232341.html 摘要 在语音增强应 ...
- 论文翻译:Neural Networks With Few Multiplications
目录 Abstract 1. Introduction 2.Related Work 3.Binary And Ternary Connect 3.1 BINARY CONNECT REVISITED ...
- pytorch --Rnn语言模型(LSTM,BiLSTM) -- 《Recurrent neural network based language model》
论文通过实现RNN来完成了文本分类. 论文地址:88888888 模型结构图: 原理自行参考论文,code and comment: # -*- coding: utf-8 -*- # @time : ...
- 论文阅读 | Probing Neural Network Understanding of Natural Language Arguments
[code&data] [pdf] ARCT 任务是 Habernal 等人在 NACCL 2018 中提出的,即在给定的前提(premise)下,对于某个陈述(claim),相反的两个依据( ...
- 论文翻译:2020_RESIDUAL ACOUSTIC ECHO SUPPRESSION BASED ON EFFICIENT MULTI-TASK CONVOLUTIONAL NEURAL NETWORK
论文翻译:https://arxiv.53yu.com/abs/2009.13931 基于高效多任务卷积神经网络的残余回声抑制 摘要 在语音通信系统中,回声会降低用户体验,需要对其进行彻底抑制.提出了 ...
随机推荐
- 5 — springboot中的yml多环境配置
1.改文件后缀 2.一张截图搞定多环境编写和切换
- 3步!完成WordPress博客迁移与重新部署
本文来自于轻量应用服务器征文活动的用户投稿,已获得作者(昵称nstar)授权发布. 由于现有的服务器已经到期,并且活动已经取消,续费一个月145元比较贵,于是参加了阿里云的活动购买一台轻量应用服务器. ...
- adverb
An adverb is a word or an expression that modifies a verb, adjective, another adverb, determiner [限定 ...
- 利用python爬取城市公交站点
利用python爬取城市公交站点 页面分析 https://guiyang.8684.cn/line1 爬虫 我们利用requests请求,利用BeautifulSoup来解析,获取我们的站点数据.得 ...
- 银联acp手机支付总结
总结: 1.手机调用后台服务端接口,获取银联返回的流水号tn 银联支付是请求后台,后台向银联下单,返回交易流水号,然后返回给用户,用户通过这个交易流水号,向银联发送请求,获取订单信息,然后再填写银行卡 ...
- mysql explain using filesort
创建表,字段tid上无索引(mysql 5.7) CREATE TABLE `test` ( `tid` int(11) DEFAULT NULL, `tname` varchar(12) DEFAU ...
- 基于阿里云ecs(centos 7) 安装jenkins
1. 安装好 jdk 2. 官网(https://pkg.jenkins.io/redhat-stable/)下载rpm包(稳定版): wget https://pkg.jenkins.io/redh ...
- SQL注入 (1) SQL注入类型介绍
SQL注入 SQL注入介绍与分类 1. 什么是sql注入 通过把SQL命令插入到Web表单提交或输入域名或页面请求的查询字符串,最终达到欺骗服务器执行恶意的SQL命令. 2. sql注入类型 按照注入 ...
- JAVA日志发展史
JAVA日志发展史 第一阶段 2001年以前,Java是没有日志库的,打印日志全凭System.out和System.err 缺点: 产生大量的IO操作同时在生产环境中无法合理的控制是否需要输出 输出 ...
- 关于Mysql java.sql.SQLException: Access denied for user 'root'@'localhost' (using password: YES)的问题
问题所在: 1.连接数据库一个是密码是否正确, 2.driver是否对, 3.有么有jar包冲突,