3. scala-spark wordCount 案例
1. 创建maven 工程
2. 相关依赖和插件
<dependencies>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>2.1.1</version>
</dependency>
</dependencies>
<build>
<finalName>wordCount</finalName>
<plugins>
<plugin>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<version>4.2.0</version>
<executions>
<execution>
<goals>
<goal>compile</goal>
<goal>testCompile</goal>
</goals>
</execution>
</executions>
</plugin> <plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-assembly-plugin</artifactId>
<version>3.1.0</version>
<configuration>
<archive>
<manifest>
<mainClass>wordCount</mainClass>
</manifest>
</archive>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
3. wordCount 案例
package com.atgu.bigdata.spark
import org.apache.spark._
import org.apache.spark.rdd.RDD
object wordCount extends App {
// local模式
// 1.创建sparkConf 对象
val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("wordCount")
// 2. 创建spark 上下文对象
val sc:SparkContext=new SparkContext(config = conf)
// 3. 读取文件
val lines: RDD[String] = sc.textFile("file:///opt/data/1.txt")
// 4. 切割单词
val words: RDD[String] = lines.flatMap(_.split(" "))
// words.collect().foreach(println)
// map
private val keycounts: RDD[(String, Int)] = words.map((_, 1))
//
private val results: RDD[(String, Int)] = keycounts.reduceByKey(_ + _)
private val res: Array[(String, Int)] = results.collect
res.foreach(println) }
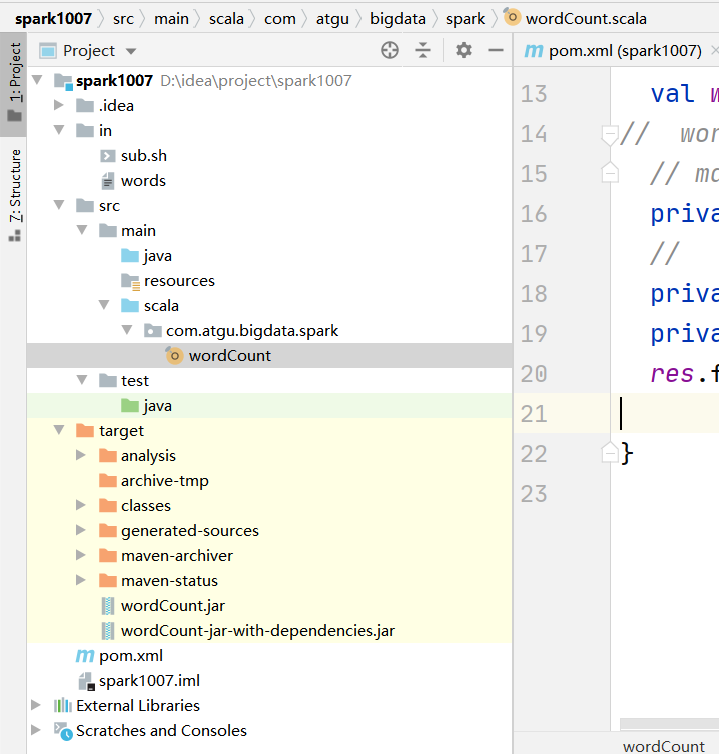
4. 项目目录结构
3. scala-spark wordCount 案例的更多相关文章
- Scala Spark WordCount
Scala所需依赖 <dependency> <groupId>org.scala-lang</groupId> <artifactId>scala-l ...
- 大数据学习day18----第三阶段spark01--------0.前言(分布式运算框架的核心思想,MR与Spark的比较,spark可以怎么运行,spark提交到spark集群的方式)1. spark(standalone模式)的安装 2. Spark各个角色的功能 3.SparkShell的使用,spark编程入门(wordcount案例)
0.前言 0.1 分布式运算框架的核心思想(此处以MR运行在yarn上为例) 提交job时,resourcemanager(图中写成了master)会根据数据的量以及工作的复杂度,解析工作量,从而 ...
- brdd 惰性执行 mapreduce 提取指定类型值 WebUi 作业信息 全局临时视图 pyspark scala spark 安装
[rdd 惰性执行] 为了提高计算效率 spark 采用了哪些机制 1-rdd 基于分布式内存数据集进行运算 2-lazy evaluation :惰性执行,即rdd的变换操作并不是在运行该代码时立 ...
- (升级版)Spark从入门到精通(Scala编程、案例实战、高级特性、Spark内核源码剖析、Hadoop高端)
本课程主要讲解目前大数据领域最热门.最火爆.最有前景的技术——Spark.在本课程中,会从浅入深,基于大量案例实战,深度剖析和讲解Spark,并且会包含完全从企业真实复杂业务需求中抽取出的案例实战.课 ...
- [Spark内核] 第36课:TaskScheduler内幕天机解密:Spark shell案例运行日志详解、TaskScheduler和SchedulerBackend、FIFO与FAIR、Task运行时本地性算法详解等
本課主題 通过 Spark-shell 窥探程序运行时的状况 TaskScheduler 与 SchedulerBackend 之间的关系 FIFO 与 FAIR 两种调度模式彻底解密 Task 数据 ...
- Spark Wordcount
1.Wordcount.scala(本地模式) package com.Mars.spark import org.apache.spark.{SparkConf, SparkContext} /** ...
- Spark WordCount的两种方式
Spark WordCount的两种方式. 语言:Java 工具:Idea 项目:Java Maven pom.xml如下: <properties> <spark.version& ...
- 3、spark Wordcount
一.用Java开发wordcount程序 1.开发环境JDK1.6 1.1 配置maven环境 1.2 如何进行本地测试 1.3 如何使用spark-submit提交到spark集群进行执行(spar ...
- indows Eclipse Scala编写WordCount程序
Windows Eclipse Scala编写WordCount程序: 1)无需启动hadoop,因为我们用的是本地文件.先像原来一样,做一个普通的scala项目和Scala Object. 但这里一 ...
- spark wordcount程序
spark wordcount程序 IllegalAccessError错误 这个错误是权限错误,错误的引用方法,比如方法中调用private,protect方法. 当然大家知道wordcount业务 ...
随机推荐
- 【LeetCode】611. Valid Triangle Number 解题报告(Python)
作者: 负雪明烛 id: fuxuemingzhu 个人博客: http://fuxuemingzhu.cn/ 题目地址:https://leetcode.com/problems/valid-tri ...
- 【LeetCode】399. Evaluate Division 解题报告(Python)
作者: 负雪明烛 id: fuxuemingzhu 个人博客: http://fuxuemingzhu.cn/ 目录 题目描述 题目大意 解题方法 日期 题目地址:https://leetcode.c ...
- 人脸识别中的重要环节-对齐之3D变换-Java版(文末附开源地址)
一.人脸对齐基本概念 人脸对齐通过人脸关键点检测得到人脸的关键点坐标,然后根据人脸的关键点坐标调整人脸的角度,使人脸对齐,由于输入图像的尺寸是大小不一的,人脸区域大小也不相同,角度不一样,所以要通过坐 ...
- oracle函数listagg使用
作用 可以实现将多列记录聚合为一列记录,实现数据的压缩 语法结构 listagg(measure_expr,delimiter) within group ( order by order_by_cl ...
- [C++]vector去除重复元素
#include <iostream> #include <vector> #include <algorithm> #include <set> us ...
- linux端口开放关闭 firewalld 使用
systemctl status firewalld # 查看防火墙状态 firewall-cmd --zone=public --add-port=27017/tcp --permanent # m ...
- SpringCloud创建Eureka Client服务注册
1.说明 本文详细介绍微服务注册到Eureka的方法, 即Eureka Client注册到Eureka Server, 这里用任意一个Spring Cloud服务为例, 比如下面已经创建好的Confi ...
- .net core中EFCore发出警告:More than twenty 'IServiceProvider' instances have been created for internal use by Entity Framework
最近使用.net core k开发时,碰到个问题,Ef使用中程序发出了一个警告: More than twenty 'IServiceProvider' instances have been cre ...
- CSS基础-5 伪类
一.伪类 我们以a标签为例 伪类标签分为4类 1. 设置超链接默认的样式 a:link {属性:值;.....} 或者 a { 属性: 值;} 推荐使用这种方式 2 ...
- Sentry 企业级数据安全解决方案 - Relay 监控 & 指标收集
内容整理自官方文档 系列 Sentry 企业级数据安全解决方案 - Relay 入门 Sentry 企业级数据安全解决方案 - Relay 运行模式 Sentry 企业级数据安全解决方案 - Rela ...