Transformers for Graph Representation
Do Transformers Really Perform Badfor Graph Representation?
1 Introduction
作者们发现关键问题在于如何补回Transformer模型的自注意力层丢失掉的图结构信息!不同于序列数据(NLP, Speech)或网格数据(CV),图的结构信息是图数据特有的属性,且对图的性质预测起着重要的作用。
There are many attempts of leveraging Transformer into the graph domain, but the only effective way is replacing some key modules (e.g., feature aggregation) in classic GNN variants by the softmax attention[47,7,22,48,58,43,13]
- [47] Graph attention networks. ICLR, 2018.
- [7] Graph transformer for graph-to-sequence learning. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 34, pages 7464–7471, 2020.
- [22] Heterogeneous graph transformer. In Proceedings of The Web Conference 2020, pages 2704–2710, 2020.
- [48] Direct multi-hop attention based graph neural network.arXiv preprint arXiv:2009.14332, 2020.
- [58] Graph-bert: Only attention is needed forlearning graph representations.arXiv preprint arXiv:2001.05140, 2020.
- [43] Self-supervised graph transformer on large-scale molecular data. Advances in Neural Information ProcessingSystems, 33, 2020.
- [13] generalization of transformer networks to graphs. AAAI Workshop on Deep Learning on Graphs: Methods and Applications, 2021
- Centrality Encoding: capture the node importance in the graph. In particular, we leverage the degree centrality for the centrality encoding, where a learnable vectoris assigned to each node according to its degree and added to the node features in the input layer.
- Spatial Encoding: capture the structural relation between nodes.
- Edge Encoding
2 Graphormer
2.1 Structural Encodings in Graphormer
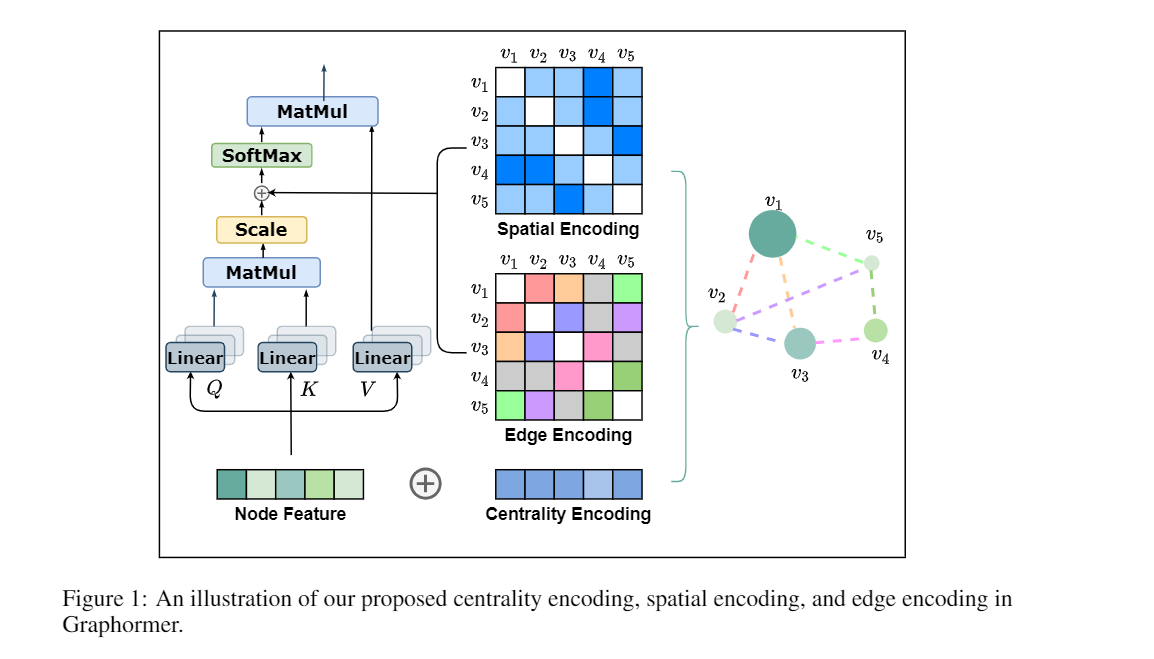
2.1.1 a Centrality Encoding
In Graphormer, we use the degree centrality, which is one of the standard centrality measures inliterature, as an additional signal to the neural network. To be specific, we develop a Centrality Encoding which assigns each node two real-valued embedding vectors according to its indegree and outdegree.

2.1.2 a Centrality Encoding
An advantage of Transformer is its global receptive field.
Spatial Encoding:
In this paper, we choose φ(vi,vj) to be the distance of the shortest path (SPD) between vi and vj if the two nodes are connected. If not, we set the output ofφto be a special value, i.e., -1. We assign each (feasible) output value a learnable scalar which will serve as a bias term in the self-attention module. Denote Aij as the (i,j)-element of the Query-Key product matrix A, we have:
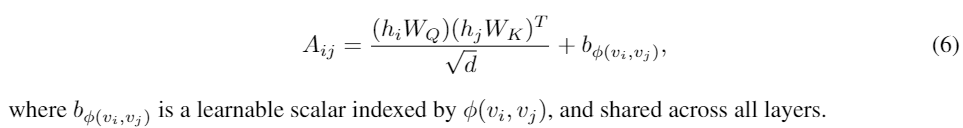
2.1.3 Edge Encoding in the Attention
In many graph tasks, edges also have structural features.
In the first method, the edge features areadded to the associated nodes’ features [21,29].
- [21] Open graph benchmark: Datasets for machine learning on graphs.arXiv preprintarXiv:2005.00687, 2020.
- [29] Deepergcn: All you need to train deepergcns.arXiv preprint arXiv:2006.07739, 2020
In the second method, for each node, its associated edges’ features will be used together with the node features in the aggregation [15,51,25].
- [51] How powerful are graph neural networks?InInternational Conference on Learning Representations, 2019.
- [25] Semi-supervised classification with graph convolutional networks.arXiv preprint arXiv:1609.02907, 2016
However, such ways of using edge feature only propagate the edge information to its associated nodes, which may not be an effective way to leverage edge information in representation of the whole graph.
a new edge encoding method in Graphormer:

3.2 Implementation Details of Graphormer
Graphormer Layer:
- MHA: multi-head self-attention (MHA)
- FFN: the feed-forward blocks
- LN: the layer normalization

Special Node:
生成一个VNODE连接图中所有的点,而它与所有节点的 spatial encodings 是 a distinct learnable scalar
3 Experiments
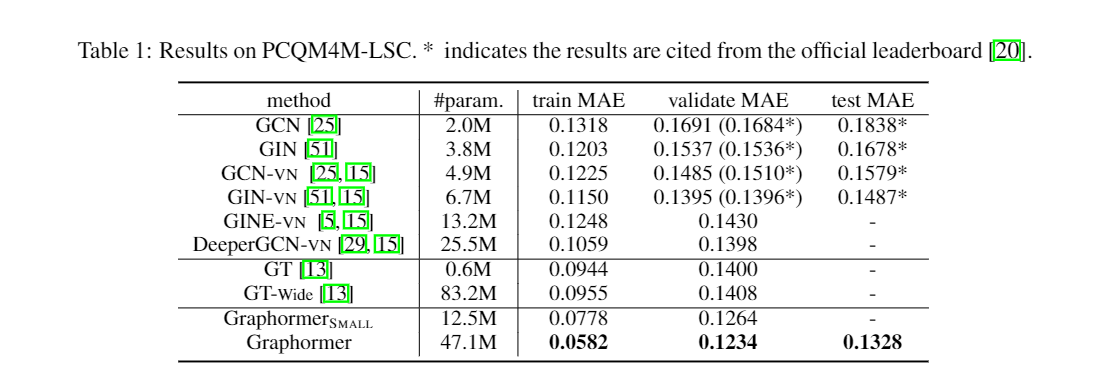
3.1 OGB Large-Scale Challenge
3.2 Graph Representation

Transformers for Graph Representation的更多相关文章
- 论文解读(Graphormer)《Do Transformers Really Perform Bad for Graph Representation?》
论文信息 论文标题:Do Transformers Really Perform Bad for Graph Representation?论文作者:Chengxuan Ying, Tianle Ca ...
- 论文解读GALA《Symmetric Graph Convolutional Autoencoder for Unsupervised Graph Representation Learning》
论文信息 Title:<Symmetric Graph Convolutional Autoencoder for Unsupervised Graph Representation Learn ...
- 论文解读(SUGRL)《Simple Unsupervised Graph Representation Learning》
Paper Information Title:Simple Unsupervised Graph Representation LearningAuthors: Yujie Mo.Liang Pen ...
- 论文解读(GMI)《Graph Representation Learning via Graphical Mutual Information Maximization》2
Paper Information 论文作者:Zhen Peng.Wenbing Huang.Minnan Luo.Q. Zheng.Yu Rong.Tingyang Xu.Junzhou Huang ...
- 论文解读(GMI)《Graph Representation Learning via Graphical Mutual Information Maximization》
Paper Information 论文作者:Zhen Peng.Wenbing Huang.Minnan Luo.Q. Zheng.Yu Rong.Tingyang Xu.Junzhou Huang ...
- 论文解读(GRCCA)《 Graph Representation Learning via Contrasting Cluster Assignments》
论文信息 论文标题:Graph Representation Learning via Contrasting Cluster Assignments论文作者:Chun-Yang Zhang, Hon ...
- 论文解读(MERIT)《Multi-Scale Contrastive Siamese Networks for Self-Supervised Graph Representation Learning》
论文信息 论文标题:Multi-Scale Contrastive Siamese Networks for Self-Supervised Graph Representation Learning ...
- 论文解读(SUBG-CON)《Sub-graph Contrast for Scalable Self-Supervised Graph Representation Learning》
论文信息 论文标题:Sub-graph Contrast for Scalable Self-Supervised Graph Representation Learning论文作者:Yizhu Ji ...
- 论文阅读 Dynamic Graph Representation Learning Via Self-Attention Networks
4 Dynamic Graph Representation Learning Via Self-Attention Networks link:https://arxiv.org/abs/1812. ...
随机推荐
- h5基本内容
一 简介 html 超文本标记语言 W3C 中立技术标准机构 W3C标准包括 结构化标准语言(HTML,XML) 表现标准语言(CSS) 行为标准(DOM,ECMAScript) 二 入门例子 < ...
- MyBatis Plus 实现多表分页模糊查询
项目中使用springboot+mybatis-plus来实现. 但是之前处理的时候都是一个功能,比如分页查询,条件查询,模糊查询. 这次将这个几个功能合起来就有点头疼,写下这边博客来记录自己碰到的问 ...
- Wampserver-添加虚拟主机
鼠标左键点击,之后点击第一个 localhost(有一个小房子) 添加虚拟地址 具体添加 完成界面 注意:这个时候一定需要重启一个Wampserver64 如果没有重启直接进入4这个步骤,会发现进入的 ...
- 学javaweb 先学Servlet 应用理论很重要
package cn.Reapsun.servlet; import java.io.IOException; import java.io.PrintWriter; import javax.ser ...
- 老师不讲的C语言知识
老师不讲的C语言知识 导语: 对于工科生,C语言是一门必修课.标准C(ANSI C)这个看似简单的语言在硬件底层编程.嵌入式开发领域还是稳坐头把交椅.在20年5月份,C语言就凭借其在医疗设备上的广泛应 ...
- 10-10-12分页机制(xp)
虚拟地址到物理地址 虚拟地址空间就是32位系统的那4GB,这4GB空间的地址称为虚拟地址.虚拟地址经过分段机制后转化为线性地址,一般虚拟地址都等于线性地址,因为大多数段寄存器的基地址都为0,只有FS段 ...
- python3读取文件指定行的三种方案
技术背景 考虑到深度学习领域中的数据规模一般都比较大,尤其是训练集,这个限制条件对应到实际编程中就意味着,我们很有可能无法将整个数据文件的内容全部都加载到内存中.那么就需要一些特殊的处理方式,比如:创 ...
- CentOS 7配置静态IP地址的两种方法 来自:互联网
CentOS 7配置静态IP地址的两种方法 来自:互联网 时间:2021-01-12 阅读:4 如果你想要为CentOS 7中的某个网络接口设置静态IP地址,有几种不同的方法,这取决于你是否想要使用网 ...
- Zabbix 常用术语
Zabbix 常用术语 1.主机(host) 一台你想监控的网络设备,用IP或域名表示 2.主机组(host group) 主机的逻辑组;它包含主机和模板.-个主机组里的主机和模板之间并没有任何直接的 ...
- xml 解析之 JDOM解析
JDOM 是一种使用 XML 的独特 Java 工具包,用于快速开发 XML 应用程序.JDOM 是一个开源项目,它基于树形结构,利用纯 Java 的技术对 XML 文档实现解析.生成.序列化及多种操 ...