SAM 做题笔记(各种技巧,持续更新,SA)
这里是 SAM 做题笔记。
本来是在一篇随笔里面,然后 Latex 太多加载不过来就分成了两篇。
标 * 的是推荐一做的题目。
trick 是我总结的技巧。
I. P3804 【模板】后缀自动机 (SAM)
题意简述:求一个字符串 \(s\) 的所有子串长度乘上其出现次数的最大值。
代码还没写过,到时候来补一下。
update:尝试只看自己的博客写出代码,然而失败了 >.<
update:好家伙,第二次跳 \(p\) 的时候(即把 \((p_i,q)\) 变为 \((p_i,q')\) 的时候)忘记跳了(即 \(p\gets \mathrm{link}(p)\)),并且连边的 vector 开小了(应该开 \(2\times 10^6\))。
- 额外信息:设在构造 SAM 时,每个前缀所表示的状态(也就是每次的 \(cur\))为终点节点。这样我们可以得到 \(n\) 个终点节点。
结论 4:在 \(\mathrm{link}\) 树上,每个节点的 \(\mathrm{endpos}\) 集合等于其子树内所有终点节点对应的终点的集合。感性理解,证明略。(之前的结论可以看 SAM 感性瞎扯)
- 将状态 \(p\) 所表示的 \(\mathrm{endpos}\) 集合大小记为 \(ed_p\)。
对于一个状态 \(p\),我们怎么求它所代表的子串在 \(s\) 中的出现次数呢?其实很简单,根据定义,我们只需求出该状态 \(\mathrm{endpos}\) 集合的大小即可。根据结论 4,即在 \(\mathrm{link}\) 树上 \(p\) 的子树所包含的终点节点个数。这样,我们可以在构造 SAM 时顺便记录一下每个点是否是终点节点。构造完成后我们建出 \(\mathrm{link}\) 树,并通过一次 dfs 求出每个点的 \(\mathrm{endpos}\) 集合大小。那么答案为
\]
代码奉上,手捏的 SAM 版本(doge):
SAM version 1.0
const int N=1e6+5;
struct node{
int nxt[26],len,link,ed;
}sam[N<<1];
int cur,cnt;
void init(){
sam[0].link=-1;
}
void ins(char s){
int las=cur,p=las,it=s-'a'; sam[cur=++cnt].ed=1; // cur 是终点节点
sam[cur].len=sam[las].len+1; // init
while(~p&&!sam[p].nxt[it])sam[p].nxt[it]=cur,p=sam[p].link; // jump link
if(p==-1)return; // case 1
int q=sam[p].nxt[it];
if(sam[p].len+1==sam[q].len){ // case 2
sam[cur].link=q;
return;
} int cl=sam[cur].link=++cnt; // case 3 : clone
sam[cl].len=sam[p].len+1;
sam[cl].link=sam[q].link;
for(int i=0;i<26;i++)sam[cl].nxt[i]=sam[q].nxt[i];
sam[q].link=cl;
while(~p&&sam[p].nxt[it]==q)sam[p].nxt[it]=cl,p=sam[p].link;
}
vector <int> e[N<<1];
ll ans;
void dfs(int id){
for(int it:e[id])dfs(it),sam[id].ed+=sam[it].ed;
if(sam[id].ed>1)ans=max(ans,1ll*sam[id].len*sam[id].ed);
}
char s[N];
int n;
int main(){
scanf("%s",s+1),n=strlen(s+1),init();
for(int i=1;i<=n;i++)ins(s[i]);
for(int i=1;i<=cnt;i++)e[sam[i].link].pb(i);
dfs(0),cout<<ans<<endl;
return 0;
}
当然,用结构体来表示一个节点的信息有时太过麻烦,所以当需要储存的信息不多时,我们可以直接用数组储存。下面是简化过的版本。
SAM version 1.1
const int N=2e6+5;
const int S=26;
int cur,cnt;
int son[N][S],fa[N],len[N],ed[N];
void ins(char s){
int las=cur,p=cur,it=s-'a';
ed[cur=++cnt]=1,len[cur]=len[las]+1;
while(~p&&!son[p][it])son[p][it]=cur,p=fa[p];
if(p==-1)return;
int q=son[p][it];
if(len[p]+1==len[q]){
fa[cur]=q;
return;
} int c=fa[cur]=++cnt;
len[c]=len[p]+1,fa[c]=fa[q],fa[q]=c;
for(int i=0;i<26;i++)son[c][i]=son[q][i];
while(~p&&son[p][it]==q)son[p][it]=c,p=fa[p];
}
void build(char *s){
int n=strlen(s+1); fa[0]=-1;
for(int i=1;i<=n;i++)ins(s[i]);
}
vector <int> e[N<<1];
ll ans;
void dfs(int id){
for(int it:e[id])dfs(it),ed[id]+=ed[it];
if(ed[id]>1)ans=max(ans,1ll*len[id]*ed[id]);
}
char s[N];
int n;
int main(){
scanf("%s",s+1),build(s);
for(int i=1;i<=cnt;i++)e[fa[i]].pb(i);
dfs(0),cout<<ans<<endl;
return 0;
}
这难道不更好看么?
II. P3975 [TJOI2015]弦论
给出 \(s,t,k\),求 \(s\) 字典序第 \(k\) 小子串,不存在输出 \(\texttt{-1}\)。\(t=0\) 表示不同位置的相同子串算一个,\(t=1\) 表示不同位置的相同子串算多个。
算是一道经典题了。
根据结论 2,可知 \(s\) 不同子串的个数等于从 \(T\) 出发的不同路径的条数,且每一条路径对应一个子串。设 \(d_p\) 表示从状态 \(i\) 开始的路径数量(包括长度为 \(0\) 的数量),可以通过拓扑排序 + DP 计算,即
\]
如果 \(t=0\),那么我们要找的就是 SAM 中从 \(T\) 开始的字典序第 \(k\) 小的路径,这可以通过贪心轻松实现。如果 \(t=1\),那么将上述转移式中的 \(1\) 修改为 \(ed_p\) 即可。代码如下:
Luogu P3975 代码
/*
Powered by C++11.
Author : Alex_Wei.
*/
#include <bits/stdc++.h>
using namespace std;
const int N=1e6+5;
const int S=26;
// Suffix_Automaton
int cur,cnt;
int son[N][S],f[N],len[N],ed[N];
int deg[N],val[N];
vector <int> le[N],se[N];
void ins(char s){
int las=cur,p=cur,it=s-'a';
ed[cur=++cnt]=1,len[cur]=len[las]+1;
while(p&&!son[p][it])son[p][it]=cur,p=f[p];
if(p==0){
f[cur]=1;
return;
} int q=son[p][it];
if(len[p]+1==len[q]){
f[cur]=q;
return;
} int c=++cnt;
f[c]=f[q],f[q]=f[cur]=c,len[c]=len[p]+1;
for(int i=0;i<26;i++)son[c][i]=son[q][i];
while(p&&son[p][it]==q)son[p][it]=c,p=f[p];
} void build(char *s){
int n=strlen(s+1); cnt=cur=1;
for(int i=1;i<=n;i++)ins(s[i]);
for(int i=1;i<=cnt;i++){
le[f[i]].emplace_back(i);
for(int j=0;j<26;j++)if(son[i][j])
se[son[i][j]].emplace_back(i),deg[i]++;
}
}
void dfs(int id){
for(int it:le[id])dfs(it),ed[id]+=ed[it];
}
char s[N],ans[N];
int t,k;
void find1(int p,int l){
for(int i=0;i<26;i++){
if(!son[p][i])continue;
if(k>val[son[p][i]])k-=val[son[p][i]];
else if(k>(t?ed[son[p][i]]:1)){
k-=(t?ed[son[p][i]]:1),ans[l]=i+'a';
find1(son[p][i],l+1);
return;
} else{
ans[l]=i+'a',cout<<ans<<endl;
return;
}
}
}
int main(){
scanf("%s",s+1),build(s);
cin>>t>>k; dfs(1);
queue <int> q;
for(int i=1;i<=cnt;i++)if(!deg[i])q.push(i);
while(!q.empty()){
int tt=q.front(); q.pop();
val[tt]+=(t?ed[tt]:1);
for(int it:se[tt]){
val[it]+=val[tt];
if(!--deg[it])q.push(it);
}
}
if(val[1]<k)puts("-1");
else find1(1,0);
return 0;
}
/*
aabcd
1 15
*/
然后你会发现它竟然 TLE 了!太离谱了!!!!111
经过不断地调试之后我发现 vector 连边耗时竟然这么大(大概 800ms,就离谱),可是不用 vector 连边就要写非常麻烦的链式前向星,巨麻烦无比,否则没法求出来 \(ed\) 和 \(d\),怎么办?逛了一圈题解区,有一个特别 nb 的技巧:
trick 1:将编号按照 \(\mathrm{len}(i)\) 降序排序,得到的就是 SAM DAG 反图的拓扑序,这样直接循环更新 \(ed\) 和 \(d\) 就可以了。可是这样会破坏 SAM \(\mathcal{O}(n)\) 的优秀时间复杂度(其实常数巨大,还没 SA 跑得快),那么直接鸡基排就好了。
SAM version 2.0
/*
Powered by C++11.
Author : Alex_Wei.
*/
#include <bits/stdc++.h>
using namespace std;
const int N=1e6+5;
const int S=26;
// Suffix_Automaton
int cur,cnt;
int son[N][S],f[N],len[N],ed[N];
int val[N],id[N],buc[N];
void ins(char s){
int las=cur,p=cur,it=s-'a';
ed[cur=++cnt]=1,len[cur]=len[las]+1;
while(p&&!son[p][it])son[p][it]=cur,p=f[p];
if(p==0){
f[cur]=1;
return;
} int q=son[p][it];
if(len[p]+1==len[q]){
f[cur]=q;
return;
} int c=++cnt;
f[c]=f[q],f[q]=f[cur]=c,len[c]=len[p]+1;
for(int i=0;i<26;i++)son[c][i]=son[q][i];
while(p&&son[p][it]==q)son[p][it]=c,p=f[p];
} void build(char *s){
int n=strlen(s+1); cnt=cur=1;
for(int i=1;i<=n;i++)ins(s[i]);
for(int i=1;i<=cnt;i++)buc[len[i]]++;
for(int i=1;i<=cnt;i++)buc[i]+=buc[i-1];
for(int i=cnt;i;i--)id[buc[len[i]]--]=i;
for(int i=cnt;i;i--)ed[f[id[i]]]+=ed[id[i]];
}
char s[N],ans[N];
int t,k;
void find(int p,int l){
for(int i=0;i<26;i++){
if(!son[p][i])continue;
if(k>val[son[p][i]])k-=val[son[p][i]];
else if(k>(t?ed[son[p][i]]:1)){
k-=(t?ed[son[p][i]]:1),ans[l]=i+'a';
find(son[p][i],l+1);
return;
} else{
ans[l]=i+'a',cout<<ans<<endl;
return;
}
}
}
int main(){
scanf("%s",s+1),build(s);
cin>>t>>k;
for(int i=cnt;i;i--){
val[id[i]]=(t?ed[id[i]]:1);
for(int j=0;j<26;j++)val[id[i]]+=val[son[id[i]][j]];
}
if(val[1]-ed[1]<k)puts("-1");
else find(1,0);
return 0;
}
III. P3763 [TJOI2017]DNA
题意简述:求 \(S\) 有多少个长度为 \(|S_0|\) 的子串满足与 \(S_0\) 至多有 \(3\) 个对应位置上的字符不等。(字符集为 \(\texttt{\{A,C,G,T\}}\))
用 SAM 口胡一波。因为我是用 SA 写的(怎么混进了一个奇怪的东西)。
SAM 的话,一个想法是直接暴力 dfs,向四个方向都搜索一遍,如果转移方向字符与当前匹配的位置上的字符不同就计数器自增 \(1\) ,匹配完成就答案加上 \(ed_p\)(\(p\) 是匹配到的状态)即可。不过不会分析时间复杂度。
SA 的话直接用 \(height\) 数组的区间 RMQ 加速匹配,这样匹配就是 \(\mathcal{O}(n)\) 的。SA 又好想又好写,何乐而不为呢?
Luogu P3763 代码
/*
Powered by C++11.
Author : Alex_Wei.
*/
#include <bits/stdc++.h>
using namespace std;
#define mem(x,v) memset(x,v,sizeof(x))
const int N=2e5+5;
const int K=18;
// Suffix_Array
int n,sa[N],rk[N<<1],ht[N],ind[N];
int buc[N],px[N],id[N],ork[N<<1],mi[N][K];
char s[N];
void clear(){
mem(sa,0),mem(rk,0),mem(ind,0),mem(buc,0),mem(mi,0);
}
bool cmp(int a,int b,int w){
return ork[a]==ork[b]&&ork[a+w]==ork[b+w];
}
void build(){
int m=1<<7,p=0;
for(int i=1;i<=n;i++)buc[rk[i]=s[i]]++;
for(int i=1;i<=m;i++)buc[i]+=buc[i-1];
for(int i=n;i;i--)sa[buc[rk[i]]--]=i;
for(int w=1;w<n;w<<=1,m=p,p=0){
for(int i=n;i>n-w;i--)id[++p]=i;
for(int i=1;i<=n;i++)if(sa[i]>w)id[++p]=sa[i]-w;
for(int i=0;i<=m;i++)buc[i]=0;
for(int i=1;i<=n;i++)buc[px[i]=rk[id[i]]]++;
for(int i=1;i<=m;i++)buc[i]+=buc[i-1];
for(int i=n;i;i--)sa[buc[px[i]]--]=id[i];
memcpy(ork,rk,sizeof(rk)),p=0;
for(int i=1;i<=n;i++)rk[sa[i]]=cmp(sa[i],sa[i-1],w)?p:++p;
if(p==n)break;
}
for(int i=1,k=0;i<=n;i++){
if(k)k--;
while(s[i+k]==s[sa[rk[i]-1]+k])k++;
ht[rk[i]]=k;
}
for(int j=0;j<K;j++)
for(int i=1;i+(j?1<<j-1:0)<=n;i++)
mi[i][j]=(j==0?ht[i]:min(mi[i][j-1],mi[i+(1<<j-1)][j-1]));
}
int gmin(int l,int r){
if(l>r)swap(l,r);
int d=log2(r-l);
return min(mi[l+1][d],mi[r-(1<<d)+1][d]);
}
int t,ans;
int main(){
cin>>t;
while(t--){
clear(),ans=0,scanf("%s",s+1);
int l=strlen(s+1);
for(int i=1;i<=l;i++)ind[i]=1;
scanf("%s",s+l+2),s[l+1]=127,n=strlen(s+1);
for(int i=l+2;i<=n;i++)ind[i]=2;
build();
for(int i=1;i<=n;i++){
if(ind[sa[i]]==1&&sa[i]+(n-l-1)-1<=l){
int p=l+2,id=sa[i];
for(int k=0;k<4;k++){
int d=gmin(rk[id],rk[p]);
id+=d+(k<3),p+=d+(k<3);
if(p>=n+1)break;
} ans+=p>=n+1;
}
}
cout<<ans<<endl;
}
return 0;
}
IV. P4070 [SDOI2016]生成魔咒
求 \(s\) 的每一个前缀的本质不同子串个数。
这题一看就很 SAM。然而我就是要用 SA 做!!!!1111!!!然后成功 WA 掉。
一开始的想法是直接正着做,然后维护一下所有相邻后缀的 \(height\)(统计有多少 \(lcp\) 是因为后面被截掉而没有计算完的,每次向右移动就要减去这些 \(lcp\) 的数量,直到其中的 \(lcp\) 到了相应的位置)。然而,\(s[1:i]\) 后缀排序后所有后缀排名的相对位置,在 \(s[1:n]\) 中可能会改变。一个例子是 \(s=[1,1,2,1,2]\),那么 \(s[1:4]\) 时 \(s_4\) 排在 \(s_1\) 前面,而 \(s[1:5]\) 时 \(s_4\) 排在 \(s_1\) 的后面。这样就悲催了。看了题解后发现了新大陆一个小技巧:
trick 2:将 \(s\) 翻转后,从后往前添加后缀。这样可以避免在末尾添加字符时导致所有后缀原有的顺序改变,而翻转不会影响到一个字符串的本质不同子串个数。
这样就做完了。又是用 SA 水 SAM 题目的一天。
Luogu P4070 代码
/*
Powered by C++11.
Author : Alex_Wei.
*/
#include <bits/stdc++.h>
using namespace std;
#define se second
#define ll long long
const int N=1e5+5;
const int K=17;
// Suffix_Array
int n,sa[N],rk[N<<1],ht[N],s[N];
map <int,int> buc;
int px[N],id[N],ork[N<<1],mi[N][K];
bool cmp(int a,int b,int w){
return ork[a]==ork[b]&&ork[a+w]==ork[b+w];
}
void build(){
int p=0;
for(int i=1;i<=n;i++)buc[rk[i]=s[i]]++;
for(auto it=++buc.begin(),pre=buc.begin();it!=buc.end();it++,pre++)(*it).se+=(*pre).se;
for(int i=n;i;i--)sa[buc[rk[i]]--]=i;
for(int w=1;w<n;w<<=1,p=0){
for(int i=n;i>n-w;i--)id[++p]=i;
for(int i=1;i<=n;i++)if(sa[i]>w)id[++p]=sa[i]-w;
buc.clear(); for(int i=1;i<=n;i++)buc[px[i]=rk[id[i]]]++;
for(auto it=++buc.begin(),pre=buc.begin();it!=buc.end();it++,pre++)(*it).se+=(*pre).se;
for(int i=n;i;i--)sa[buc[px[i]]--]=id[i];
memcpy(ork,rk,sizeof(rk)),p=0;
for(int i=1;i<=n;i++)rk[sa[i]]=cmp(sa[i],sa[i-1],w)?p:++p;
if(p==n)break;
}
for(int i=1,k=0;i<=n;i++){
if(k)k--;
while(s[i+k]==s[sa[rk[i]-1]+k])k++;
ht[rk[i]]=k;
}
for(int j=0;j<K;j++)
for(int i=1;i+(j?1<<j-1:0)<=n;i++)
mi[i][j]=(j==0?ht[i]:min(mi[i][j-1],mi[i+(1<<j-1)][j-1]));
}
int lcp(int l,int r){
int d=log2(r-l);
return min(mi[l+1][d],mi[r-(1<<d)+1][d]);
}
ll cur;
set <int> st;
int main(){
cin>>n;
for(int i=1;i<=n;i++)cin>>s[i];
reverse(s+1,s+n+1);
build(),st.insert(rk[n]);
cout<<1<<endl;
for(int i=n-1;i;i--){
st.insert(rk[i]);
auto it=st.lower_bound(rk[i]);
if(it!=st.begin()&&it!=--st.end()){
auto pre=--it,suf=++++it;
cur+=-lcp(*pre,*suf)+lcp(*pre,rk[i])+lcp(rk[i],*suf);
} else if(it!=st.begin()){
auto pre=--it;
cur+=lcp(*pre,rk[i]);
} else{
auto suf=++it;
cur+=lcp(rk[i],*suf);
} cout<<1ll*(n-i+1)*(n-i+2)/2-cur<<endl;
}
return 0;
}
SAM 的话直接 \(ans\gets ans+\mathrm{len}(cur)-\mathrm{len}(\mathrm{link}(cur))\) 就好了。
*V. CF1037H Security
题意简述:给出 \(s,q\),\(q\) 次询问每次给出 \(l,r,t\),求字典序最小的 \(s[l:r]\) 的子串 \(s'\) 使得 \(s'>t\)。
神仙题,又让我学会了一个神奇的操作(其实是我菜没见过套路)。
就是对于这种区间子串的题目,我们直接在 SAM 上贪心的时候,不知道当前的选择是否可行(即选一个字符后判断可不可能当前选取的整个字符串落在区间 \([l,r]\) 里面),那么可以……
trick 3:用线段树合并维护 \(\mathrm{endpos}\) 集合。
如果有了 \(\mathrm{endpos}\) 集合,直接贪心选取就好了。注意要贪到第 \(|T|+1\) 位(因为可能当前 \(s'=t\),那么再选一个字符就好了)。
为了写这道题目甚至去学了一下线段树合并。
CF1037H 代码
/*
Powered by C++11.
Author : Alex_Wei.
*/
#include <bits/stdc++.h>
using namespace std;
//#pragma GCC optimize(3)
//using int = long long
//using i128 = __int128;
using uint = unsigned int;
using ll = long long;
using ull = unsigned long long;
using db = double;
using ld = long double;
using pii = pair <int,int>;
using pll = pair <ll,ll>;
using pdd = pair <double,double>;
using vint = vector <int>;
using vpii = vector <pii>;
#define fi first
#define se second
#define pb emplace_back
#define mpi make_pair
#define all(x) x.begin(),x.end()
#define sor(x) sort(all(x))
#define rev(x) reverse(all(x))
#define mem(x,v) memset(x,v,sizeof(x))
#define mcpy(x,y) memcpy(x,y,sizeof(y))
#define Time 1.0*clock()/CLOCKS_PER_SEC
pii operator + (pii a,pii b){return {a.fi+b.fi,a.se+b.se};}
pll operator + (pll a,pll b){return {a.fi+b.fi,a.se+b.se};}
const int N=2e5+5;
const int S=26;
// Suffix_Automaton
int las,tot;
int son[N][S],fa[N],len[N];
int ed[N],id[N],buc[N];
void insS(char s){
int cur=++tot,p=las,it=s-'a';
len[cur]=len[las]+1,las=cur,ed[cur]=1;
while(p&&!son[p][it])son[p][it]=cur,p=fa[p];
if(!p)return fa[cur]=1,void();
int q=son[p][it];
if(len[p]+1==len[q])return fa[cur]=q,void();
int c=++tot;
fa[c]=fa[q],fa[q]=c,fa[cur]=c,len[c]=len[p]+1;
for(int i=0;i<26;i++)son[c][i]=son[q][i];
while(p&&son[p][it]==q)son[p][it]=c,p=fa[p];
} void build(char *s){
int n=strlen(s+1); las=tot=1;
for(int i=1;i<=n;i++)insS(s[i]),ed[las]=i;
for(int i=1;i<=tot;i++)buc[len[i]]++;
for(int i=1;i<=tot;i++)buc[i]+=buc[i-1];
for(int i=tot;i;i--)id[buc[len[i]]--]=i;
}
// Chairman_Tree
int node,rt[N],ls[N<<5],rs[N<<5];
void insC(int l,int r,int p,int ori,int &x){
x=++node;
if(l==r)return;
int m=l+r>>1;
if(p<=m)insC(l,m,p,ls[ori],ls[x]),rs[x]=rs[ori];
else insC(m+1,r,p,rs[ori],rs[x]),ls[x]=ls[ori];
} int merge(int l,int r,int x,int y){
if(!x||!y)return x|y;
if(x==y)return x;
int m=l+r>>1,z=++node;
ls[z]=merge(l,m,ls[x],ls[y]),rs[z]=merge(m+1,r,rs[x],rs[y]);
return z;
} bool query(int l,int r,int ql,int qr,int x){
if(!x||ql>qr)return 0;
if(ql<=l&&r<=qr)return 1;
int m=l+r>>1; bool ans=0;
if(ql<=m)ans|=query(l,m,ql,qr,ls[x]);
if(m<qr)ans|=query(m+1,r,ql,qr,rs[x]);
return ans;
}
char s[N],t[N],ans[N];
int q,n,l,r,tag;
bool dfs(int i,int p){
if(i==n+2)return 0;
int it=(i>n?0:t[i]-'a'),q=son[p][it];
for(int j=it;j<26;j++){
q=son[p][j];
if(q&&query(1,tot,l+i-1,r,rt[q])){
if(j==it&&i<=n&&!dfs(i+1,q))continue;
ans[i]=j+'a';
return 1;
}
} return 0;
}
int main(){
scanf("%s",s+1),build(s);
for(int i=1;i<=tot;i++)if(ed[i])insC(1,tot,ed[i],0,rt[i]);
for(int i=tot;i;i--)rt[fa[id[i]]]=merge(1,tot,rt[fa[id[i]]],rt[id[i]]);
cin>>q;
while(q--){
cin>>l>>r,tag=1;
scanf("%s",t+1),n=strlen(t+1);
if(dfs(1,1))cout<<(ans+tag)<<endl;
else puts("-1");
for(int i=1;ans[i];i++)ans[i]=0;
}
return 0;
}
*VI. P4770 [NOI2018] 你的名字
题意简述:给出 \(s,q\),\(q\) 次询问 \(l,r,t\),求 \(t\) 有多少个本质不同子串没有在 \(s[l:r]\) 中出现过。
一写写一天,最后还是看了题解。
记 \(pre_i\) 为与 \(s[l:r]\) 匹配的所有 \(t[1:i]\) 后缀的最长的长度,直接在 \(s\) 的 SAM 上面跳即可。设当前位置为 \(p\),匹配长度为 \(L\),区间为 \(l,r\),那么直接查询是否存在一个位置 \(x\) 使得 \(x\in[l+L-1,r]\) 且 \(x\in\mathrm{endpos}(p)\) 即可(保证当前状态当前长度的字符串在 \(s[l:r]\) 中出现过),如果存在直接跳,不存在就将匹配长度减小 \(1\)(注意不是直接跳 \(\mathrm{link}\)!可能状态 \(p\) 时当前长度不满足,但是长度减小就满足了),如果长度减小到 \(\mathrm{len(link}(p))\) 再向上跳。根据上面一题的套路用线段树合并维护 \(\mathrm{endpos}\) 即可。
然后对 \(t\) 建 SAM,那么答案即为 \(\sum \max(0,\mathrm{len}(p)-\max(\mathrm{len(link}(p)),pre_{\mathrm{minr}(p)}))\)。其中 \(\mathrm{minr}(p)\) 表示 \(p\) 的 \(\mathrm{endpos}\) 集合中最小的位置。
稍微解释一下:该位置只能表示长度为 \((\mathrm{len(link}(p),\mathrm{len}(p)]\) 的子串,而如果长度不大于 \(pre_{\mathrm{minr}(p)}\) 就能被 \(s[l,r]\) 匹配,不符合题意。当然,如果不是 \(\mathrm{minr}\) 也可以,因为如果存在 \(pos,pos'\in \mathrm{endpos}(p)\) 使得 \(pre_{pos}\neq pre_{pos'}\),那么 \(pre_{pos'}\) 显然不小于 \(\mathrm{len}(p)\),因此可以推出 \(pre_{pos}\geq \mathrm{len}(p)\),对答案没有贡献,只不过 \(\mathrm{minr}\) 好维护一点。
\(\mathrm{minr}\) 可以在建出 SAM 的时候一并维护。
Luogu P4770 代码
/*
Powered by C++11.
Author : Alex_Wei.
*/
#include <bits/stdc++.h>
using namespace std;
//#pragma GCC optimize(3)
//using int = long long
//using i128 = __int128;
using uint = unsigned int;
using ll = long long;
using ull = unsigned long long;
using db = double;
using ld = long double;
using pii = pair <int,int>;
using pll = pair <ll,ll>;
using pdd = pair <double,double>;
using vint = vector <int>;
using vpii = vector <pii>;
#define fi first
#define se second
#define pb emplace_back
#define mpi make_pair
#define all(x) x.begin(),x.end()
#define sor(x) sort(all(x))
#define rev(x) reverse(all(x))
#define mem(x,v) memset(x,v,sizeof(x))
#define mcpy(x,y) memcpy(x,y,sizeof(y))
#define Time 1.0*clock()/CLOCKS_PER_SEC
pii operator + (pii a,pii b){return {a.fi+b.fi,a.se+b.se};}
pll operator + (pll a,pll b){return {a.fi+b.fi,a.se+b.se};}
const int N=1e6+5;
const int S=26;
const int K=N*50;
struct SegTreeFusion{
int node,rt[N],ls[K],rs[K];
void ins(int l,int r,int p,int ori,int &x){
x=++node;
if(l==r)return void();
int m=l+r>>1;
if(p<=m)ins(l,m,p,ls[ori],ls[x]),rs[x]=rs[ori];
else ins(m+1,r,p,rs[ori],rs[x]),ls[x]=ls[ori];
} int merge(int l,int r,int x,int y){
if(!x||!y)return x|y;
if(l==r)return x;
int m=l+r>>1,z=++node;
ls[z]=merge(l,m,ls[x],ls[y]);
rs[z]=merge(m+1,r,rs[x],rs[y]);
return z;
} bool query(int l,int r,int ql,int qr,int x){
if(!x||ql>qr)return 0;
if(ql<=l&&r<=qr)return 1;
int m=l+r>>1,ans=0;
if(ql<=m)ans|=query(l,m,ql,qr,ls[x]);
if(m<qr)ans|=query(m+1,r,ql,qr,rs[x]);
return ans;
}
}st;
int n,q;
struct SAM{
int cnt,las;
int son[N][S],fa[N],len[N];
int buc[N],id[N],minr[N];
void clear(){
mem(son[1],0),cnt=las=1;
} void ins(char s,bool seg){
int p=las,cur=++cnt,it=s-'a'; mem(son[las=cur],0);
minr[cur]=len[cur]=len[p]+1;
if(seg)st.ins(1,n,len[cur],0,st.rt[cur]);
while(p&&!son[p][it])son[p][it]=cur,p=fa[p];
if(!p)return fa[cur]=1,void();
int q=son[p][it];
if(len[p]+1==len[q])return fa[cur]=q,void();
int c=++cnt;
fa[c]=fa[q],fa[q]=fa[cur]=c,len[c]=len[p]+1,minr[c]=minr[q];
for(int i=0;i<26;i++)son[c][i]=son[q][i];
while(p&&son[p][it]==q)son[p][it]=c,p=fa[p];
} void build(char *s,int ln,bool seg){
clear();
for(int i=1;i<=ln;i++)ins(s[i],seg);
for(int i=0;i<=ln;i++)buc[i]=0;
for(int i=1;i<=cnt;i++)buc[len[i]]++;
for(int i=1;i<=ln;i++)buc[i]+=buc[i-1];
for(int i=cnt;i;i--)id[buc[len[i]]--]=i;
if(seg)for(int i=cnt;i>1;i--)
st.rt[fa[id[i]]]=st.merge(1,n,st.rt[fa[id[i]]],st.rt[id[i]]);
} void trans(int &p,int &ln,int l,int r,int c){
while(1){
if(son[p][c]&&st.query(1,n,l+ln,r,st.rt[son[p][c]]))
return ln++,p=son[p][c],void();
if(!ln)return;
if(--ln==len[fa[p]])p=fa[p];
}
} ll cal(int p[]){
ll ans=0;
for(int i=2;i<=cnt;i++)ans+=max(0,len[i]-max(len[fa[i]],p[minr[i]]));
return ans;
}
}sams,samt;
int p[N];
char s[N],t[N];
int main(){
scanf("%s",s+1),n=strlen(s+1);
sams.build(s,n,1),cin>>q;
for(int i=1,l,r;i<=q;i++){
scanf("%s",t+1),cin>>l>>r;
int len=strlen(t+1),pos=1;
samt.build(t,len,0);
for(int i=1;i<=len;i++)sams.trans(pos,p[i]=p[i-1],l,r,t[i]-'a');
cout<<samt.cal(p)<<endl;
}
return 0;
}
*VII. CF666E Forensic Examination
题意简述:给出字符串 \(s\) 与 \(t_{1,2,\cdots,m}\),\(q\) 次询问,求出 \(t_{[l,r]}\) 中出现 \(s[pl:pr]\) 次数最多的字符串编号最小值与次数。
码题十分钟,debug de 一年。
首先有这样一个技巧:
trick 4:找到 \(s[l:r]\) 在一个 SAM 中的状态,可以记录 \(s[1:r]\) 在 SAM 中匹配的的状态,然后在 \(link\) 树上倍增。需要特判 \(s[1:r]\) 在 SAM 中匹配长度小于 \(r-l+1\) 的情况,这时 \(s[l:r]\) 在 SAM 里面是没有的(如果 \(s\) 也在 SAM 中就不需要了,因为一定存在这个状态)。
将所有 \(t_i\) 建出一个广义 SAM,然而我不会广义 SAM,那么每次添加一个新字符串时,将 \(las\) 设为 \(1\) 即可。
多串 SAM 如果直接 \(las=1\) 不能判重!会挂掉!!
除此以外,假设跳到了表示 \(s[pl:pr]\) 的状态 \(p\),那我们还需找到一个最小的 \(i\in[l,r]\) 使得 \(p\) 及 \(p\) 的子树中 \(t_i\) 的结束状态的个数最大,显然要线段树合并维护一个状态的 \(endpos\) 集合中出现在每个 \(t_i\) 中的位置个数,然后直接用线段树维护区间最大值和区间最大值的编号最小值即可。
注意点:如果多串 SAM 直接将 \(las\) 设为 \(1\) 并且不判重(即直接 \(cur=las+1\) 而不判断是否 \(las\) 已经有当前字符的转移)(只能不判重!!否则会破坏原有 SAM 的结构!),那么如果两个字符串的开头字符相同,可能会导致一个节点成了空节点(即没有入边,不包含任何字符串),从而使 \(len(link(i))=len(i)\)。这时就不能用桶排求拓扑序了,必须用 dfs。
这玩意调了 1.5h,刻骨铭心。
当然如果直接把 \(s\) 也塞进 SAM 也可以,不过会慢一些。
时间复杂度 \(\mathcal{O}((|s|+\sum|t_i|+q)\log \sum|t_i|)\)。
CF666E 代码
/*
Powered by C++11.
Author : Alex_Wei.
*/
#include <bits/stdc++.h>
using namespace std;
//#pragma GCC optimize(3)
//using int = long long
//using i128 = __int128;
using uint = unsigned int;
using ll = long long;
using ull = unsigned long long;
using db = double;
using ld = long double;
using pii = pair <int,int>;
using pll = pair <ll,ll>;
using pdd = pair <double,double>;
using vint = vector <int>;
using vpii = vector <pii>;
#define fi first
#define se second
#define pb emplace_back
#define mpi make_pair
#define all(x) x.begin(),x.end()
#define sor(x) sort(all(x))
#define rev(x) reverse(all(x))
#define mem(x,v) memset(x,v,sizeof(x))
#define mcpy(x,y) memcpy(x,y,sizeof(y))
#define Time 1.0*clock()/CLOCKS_PER_SEC
pii operator + (pii a,pii b){return {a.fi+b.fi,a.se+b.se};}
pll operator + (pll a,pll b){return {a.fi+b.fi,a.se+b.se};}
namespace IO{
char buf[1<<23],*p1=buf,*p2=buf,obuf[1<<24],*O=obuf;
#ifdef __WIN32
#define gc getchar()
#else
#define gc (p1==p2&&(p2=(p1=buf)+fread(buf,1,1<<22,stdin),p1==p2)?EOF:*p1++)
#endif
#define pc(x) (*O++=x)
#define flush() fwrite(obuf,O-obuf,1,stdout)
inline ll read(){
ll x=0; bool sign=0; char s=gc;
while(!isdigit(s))sign|=s=='-',s=gc;
while(isdigit(s))x=(x<<1)+(x<<3)+(s-'0'),s=gc;
return sign?-x:x;
}
inline void print(ll x){
if(x<0)pc('-'),print(-x);
else{
if(x>9)print(x/10);
pc(x%10+'0');
}
}
} using namespace IO;
const int N=2e6+5;
const int M=5e4+5;
const int S=26;
int node,rt[N],ls[M<<6],rs[M<<6];
pii val[M<<6];
pii merge(pii x,pii y){
int z=max(x.fi,y.fi);
if(x.se>y.se)swap(x,y);
return {z,x.fi==z?x.se:y.se};
} void ins(int l,int r,int p,int &x){
if(!x)x=++node;
if(l==r)return val[x].fi++,val[x].se=p,void();
int m=l+r>>1;
if(p<=m)ins(l,m,p,ls[x]);
else ins(m+1,r,p,rs[x]);
val[x]=merge(val[ls[x]],val[rs[x]]);
} int merge(int l,int r,int x,int y){
if(!x||!y)return x|y;
int z=++node,m=l+r>>1;
if(l==r){
val[z].fi=val[x].fi+val[y].fi;
val[z].se=min(val[x].se,val[y].se);
return z;
} ls[z]=merge(l,m,ls[x],ls[y]),rs[z]=merge(m+1,r,rs[x],rs[y]);
return val[z]=merge(val[ls[z]],val[rs[z]]),z;
} pii query(int l,int r,int ql,int qr,int x){
if(!x)return {0,0};
if(ql<=l&&r<=qr)return val[x];
int m=l+r>>1; pii ans={0,0};
if(ql<=m)ans=query(l,m,ql,qr,ls[x]);
if(m<qr)ans=merge(ans,query(m+1,r,ql,qr,rs[x]));
return ans;
}
int n,m,cnt,las;
int son[N][S],fa[N],len[N];
int buc[N],id[N],f[N][S],ed[N],mxl[N];
vector <int> e[N];
void ins(char s,int id){
int p=las,it=s-'a',cur=++cnt;
len[cur]=len[las]+1,las=cur,ins(1,m,id,rt[cur]);
while(p&&!son[p][it])son[p][it]=cur,p=fa[p];
if(!p)return fa[cur]=1,void();
int q=son[p][it];
if(len[p]+1==len[q])return fa[cur]=q,void();
int c=++cnt;
fa[c]=fa[q],fa[q]=fa[cur]=c,len[c]=len[p]+1;
for(int i=0;i<26;i++)son[c][i]=son[q][i];
while(p&&son[p][it]==q)son[p][it]=c,p=fa[p];
} void build(char *s,int id){
int n=strlen(s+1); las=1;
if(id==1)cnt=1;
for(int i=1;i<=n;i++)ins(s[i],id);
} void dfs(int id){
for(int it:e[id])dfs(it),rt[id]=merge(1,m,rt[id],rt[it]);
}
int p,q,pl,pr,l,r;
char s[N],t[N];
int main(){
scanf("%s",s+1),cin>>m;
n=strlen(s+1);
for(int i=1;i<=m;i++)scanf("%s",t+1),build(t,i);
for(int i=1,p=1,l=0;i<=n;i++){
while(p&&!son[p][s[i]-'a'])p=fa[p],l=len[p];
if(!p)p=1,l=0; else p=son[p][s[i]-'a'],l++;
ed[i]=p,mxl[i]=l;
}
for(int j=0;1<<j<=cnt;j++)for(int i=1;i<=cnt;i++)f[i][j]=j?f[f[i][j-1]][j-1]:fa[i];
for(int i=2;i<=cnt;i++)e[fa[i]].pb(i); dfs(1);
cin>>q; while(q--){
l=read(),r=read(),pl=read(),pr=read(),p=ed[pr];
if(mxl[pr]<pr-pl+1){
cout<<l<<" 0\n";
continue;
} for(int i=log2(cnt);~i;i--)if(pr-len[f[p][i]]+1<=pl)p=f[p][i];
pii ans=query(1,m,l,r,rt[p]);
cout<<max(l,ans.se)<<" "<<ans.fi<<"\n";
}
return 0;
}
VIII. P4022 [CTSC2012]熟悉的文章
题意简述:给出字典 \(T_{1,2,\cdots,m}\),多次询问一个字符串 \(s\) 的 \(L_0\),其中 \(L_0\) 表示:将 \(s\) 分为若干子串,使得所有长度不小于 \(l\) 且在字典 \(T\) 中出现过的子串长度之和不小于 \(0.9|s|\) 的 \(l\) 的最大值。
首先这个 \(L_0\) 显然具有可二分性,那我们将题目转化为给出 \(l\) 求满足条件的长度最大值。设 \(f_i\) 表示 \(s[1:i]\) 能匹配的最大值,那么显然有 \(f_i=\max(f_{i-1},\max_{j=i-pre_i}^{i-l} f_j+1)\),其中 \(pre_i\) 是 \(s[1:i]\) 在字典 \(T\) 中的最大匹配长度。可以发现决策点单调不减(因为每向右移动一位,\(pre\) 最多增加一位,所以 \(i-pre_i\) 单调不减),那么单调队列就好了。
求 \(pre_i\) 直接广义 SAM 即可。注意如果在插入新字符串时直接 \(las=1\),是不能判断当前状态是否已有转移并直接跳过去(而不是新建一个状态)的,因为这样会破坏原有的 SAM 的结构。
时间复杂度 \(\mathcal{O}(\sum |T_i|+\sum |s|\log \sum |s|)\)。
Luogu P4022 代码
/*
Powered by C++11.
Author : Alex_Wei.
*/
#include <bits/stdc++.h>
using namespace std;
#define mcpy(x,y) memcpy(x,y,sizeof(y))
const int N=2.2e6+5;
// Suffix_Automaton
int n,m;
int cnt,las;
int fa[N],len[N],son[N][2];
void ins(int it){
int p=las,cur=++cnt;
len[cur]=len[las]+1,las=cur;
while(p&&!son[p][it])son[p][it]=cur,p=fa[p];
if(!p)return fa[cur]=1,void();
int q=son[p][it];
if(len[p]+1==len[q])return fa[cur]=q,void();
int cl=++cnt;
fa[cl]=fa[q],fa[q]=fa[cur]=cl,len[cl]=len[p]+1;
son[cl][0]=son[q][0],son[cl][1]=son[q][1];
while(p&&son[p][it]==q)son[p][it]=cl,p=fa[p];
} void build(char *s){
int n=strlen(s+1); las=1;
for(int i=1;i<=n;i++)ins(s[i]-'0');
}
int f[N],d[N],hd,tl;
char s[N];
int check(int x){
int n=strlen(s+1),p=1,l=0,ans=0; hd=1,tl=0;
for(int i=1;i<=n;i++){
int it=s[i]-'0';
while(p&&!son[p][it])p=fa[p],l=len[p];
if(!p)p=1,l=0;
else p=son[p][it],l++;
if(i>=x){
while(hd<=tl&&f[d[tl]]+(i-x-d[tl])<=f[i-x])tl--;
d[++tl]=i-x;
} while(hd<=tl&&d[hd]+l<i)hd++;
if(hd<=tl)f[i]=max(f[i-1],f[d[hd]]+(i-d[hd]));
else f[i]=f[i-1];
ans=max(ans,f[i]);
} return ans;
}
int main(){
cin>>n>>m,cnt=1;
for(int i=1;i<=m;i++)scanf("%s",s+1),build(s);
for(int i=1;i<=n;i++){
scanf("%s",s+1);
int n=strlen(s+1),l=0,r=n;
while(l<r){
int m=(l+r>>1)+1;
if(check(m)>=n*0.9)l=m;
else r=m-1;
} cout<<l<<"\n";
}
return 0;
}
IX. CF616F Expensive Strings
题意简述:给出 \(t_{1,2,\cdots,n}\) 和 \(c_{1,2,\cdots,n}\),求 \(\max f(s)=\sum_i^n c_i\times p_{s,i} \times |s|\) 的最大值,其中 \(s\) 为任意字符串,\(p_{s,i}\) 为 \(s\) 在 \(t_i\) 中的出现次数。
广义 SAM 板子题。
考虑 SAM 上每个状态所表示的意义:出现位置相同的字符串集合。也就是说,对于 SAM 上的一个状态 \(t\),它所表示的所有字符串 \(s\) 的 \(\sum_{i=1}^n c_i\times p_{s,i}\) 是相同的,所以它对答案的可能贡献就是 \(\sum_{i=1}^n c_i\times p_{s,i}\times len(t)\)。\(\sum_{i=1}^n c_i\times p_{s,i}\) 可以直接在 \(link\) 树上树形 DP 求出。我一开始还以为要线段树合并,做题做傻了。
一些注意点:如果你写的是 \(las=1\) 版本的伪广义 SAM,如果不判重,可能会建空节点 \(p\),此时 \(len(link(p))=len(p)\)。所以特判一下这种情况就行了,否则会 WA on 16,并且 “expected 0,found 500”。
同时,答案的初始值应赋为 \(0\) 而不是 \(-\infty\),因为只要让 \(s\) 不在任何一个 \(t_i\) 中出现过就可以 \(f(s)=0\)。
一开始直接拿 P4022 熟悉的文章 的广义 SAM 写的,那个题目是 01 串,所以复制儿子只复制了 0 和 1(这题就是 a 和 b),然后过了 43 个测试点。
CF616F 代码
/*
Powered by C++11.
Author : Alex_Wei.
*/
#include <bits/stdc++.h>
using namespace std;
//#pragma GCC optimize(3)
//using int = long long
//using i128 = __int128;
using uint = unsigned int;
using ll = long long;
using ull = unsigned long long;
using db = double;
using ld = long double;
using pii = pair <int,int>;
using pll = pair <ll,ll>;
using pdd = pair <double,double>;
using vint = vector <int>;
using vpii = vector <pii>;
#define fi first
#define se second
#define pb emplace_back
#define mpi make_pair
#define all(x) x.begin(),x.end()
#define sor(x) sort(all(x))
#define rev(x) reverse(all(x))
#define mem(x,v) memset(x,v,sizeof(x))
#define mcpy(x,y) memcpy(x,y,sizeof(y))
#define Time 1.0*clock()/CLOCKS_PER_SEC
const int N=1e6+5;
// Suffix_Automaton
int cnt,las;
int fa[N],len[N],son[N][26];
ll val[N];
vector <int> e[N];
void ins(int it,int v){
int p=las,cur=++cnt;
len[cur]=len[las]+1,las=cur,val[cur]=v;
while(p&&!son[p][it])son[p][it]=cur,p=fa[p];
if(!p)return fa[cur]=1,void();
int q=son[p][it];
if(len[p]+1==len[q])return fa[cur]=q,void();
int cl=++cnt;
fa[cl]=fa[q],fa[q]=fa[cur]=cl,len[cl]=len[p]+1;
mcpy(son[cl],son[q]);
while(p&&son[p][it]==q)son[p][it]=cl,p=fa[p];
} void build(string s,int v){
las=1;
for(int i=0;i<s.size();i++)ins(s[i]-'a',v);
} void dfs(int id){
for(int it:e[id])dfs(it),val[id]+=val[it];
}
int n;
ll ans;
string s[N];
int main(){
cin>>n,cnt=1;
for(int i=1;i<=n;i++)cin>>s[i];
for(int i=1,c;i<=n;i++)cin>>c,build(s[i],c);
for(int i=1;i<=cnt;i++)e[fa[i]].pb(i);
dfs(1); for(int i=1;i<=cnt;i++)if(len[fa[i]]!=len[i])ans=max(ans,len[i]*val[i]);
cout<<ans<<endl;
return 0;
}
X. P4094 [HEOI2016/TJOI2016]字符串
题意简述:给出字符串 \(s\),多次询问 \(a,b,c,d\) 求 \(s[a:b]\) 的所有子串与 \(s[c:d]\) 的最长公共前缀的最大值。
这个 SAM 套路见多了的话还是挺简单的吧。
首先,SAM 不太方便处理前缀,所以将整个串翻转(询问不要忘记翻转),这样就转化为了最长公共后缀。接下来求 \(s[1:d]\) 所代表的状态,设为 \(p\),直接在建 SAM 时预处理即可。
直接不管 \(c\) 的限制,问题转化为求出 \(s[a:b]\) 所有子串与 \(s[1:d]\) 的最长公共后缀长度,并与 \(d-c+1\) 取 \(\min\)。
根据 SAM 的性质,\(link\) 树上所有 \(p\) 的祖先都表示 \(s[1:d]\) 的一个或多个后缀。我们可以找到一个状态 \(q\) 满足 \(q\) 是 \(p\) 的祖先且 \(\left(\max_{x\in endpos(q),x\leq b}x\right)-a+1\leq len(q)\)(也就是该状态所表示的字符串在 \(b\) 或 \(b\) 之前出现的最靠右的结束位置,至于为什么要最靠右显而易见(右边的出现位置肯定优于左边的出现位置,因为有左端点 \(a\) 的限制),读者可自行理解),且 \(len(q)\) 的值最小,那么最长公共后缀肯定在 \(q\) 或 \(link(q)\) 所表示的子串中。
先说说为什么要 \(len(q)\) 最小:假设存在 \(q'\) 满足上述条件,但 \(len(q')>len(q)\),即 \(q\) 是 \(q'\) 的祖先(同时 \(q'\) 是 \(p\) 的祖先)。记 \(\max_{x\in endpos(q),x\leq b}x\) 为 \(maxp(q,b)\),那么根据 \(endpos\) 和 \(link\) 的性质,即 \(endpos(q')\subsetneq endpos(q)\),因此,\(maxp(q',b)\leq maxp(q,b)\),即 \(q'\) 点所表示字符串在 \(b\) 或 \(b\) 之前出现的最大结束位置,一定不大于 \(q\) 点所表示的字符串在 \(b\) 或 \(b\) 之前出现的最大结束位置。因此 \(maxp(q',b)-a+1\leq maxp(q,b)-a+1\)。又因为 \(len(q)\ (len(q'))\geq maxp(q,b)\ (maxp(q',b)) -a+1\),即 \(q\) 和 \(q'\) 所表示的的最长字符串超出了 \(a\) 的限制,所以我们是用 \(maxp\) 值 \(-a+1\) 求出在 \(a\) 的限制下该状态对答案的贡献。故 \(q\) 一定比 \(q'\) 更优。
再说说为什么要算上 \(link(q)\):
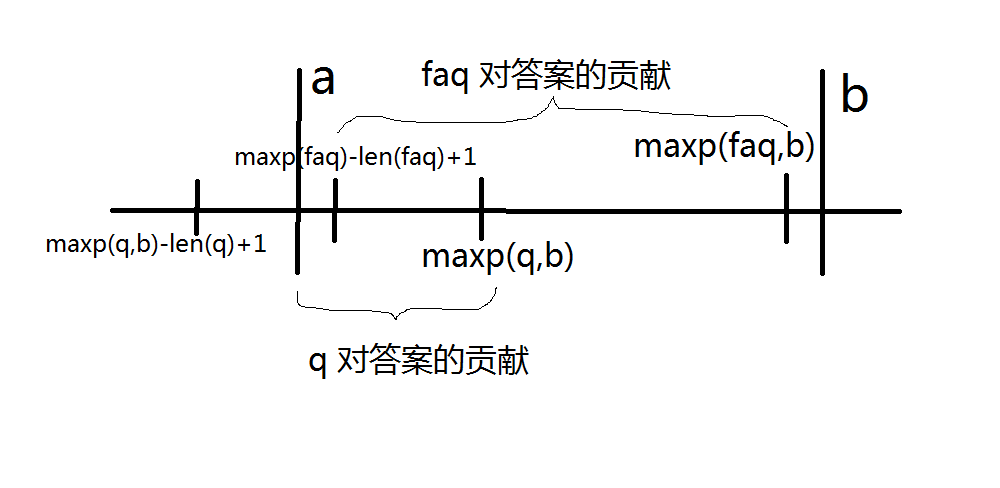
一 目 了 然,不 言 而 喻。
同时,因为 \(link(q)\) 的贡献已经是 \(len(q)\) 了,如果再往上跳 \(maxp\) 递增,贡献也一定是该点的 \(len\) 值,这是递减的,所以不需要再往上考虑。
说完了思路,接下来讲讲怎么实现:用线段树合并维护 \(endpos\) 集合可以轻松在 \(\log\) 时间内求出 \(maxp\)。同时,因为满足条件的 \(q\) 满足二分条件,所以求 \(q\) 直接用 \(p\) 在 \(link\) 树上倍增即可。那么最后答案即为 \(\min(\max(maxp(q,b)-a+1,len(link(q))),d-c+1)\)。(不需要特判答案为 \(0\) 的情况,因为此时 \(maxp(q,b)-a+1\) 不小于 \(0\),而 \(len(link(q))\) 显然为 \(0\))
时间复杂度 \(\mathcal{O}(q\log^2 n)\)。
Luogu P4094 代码
/*
Powered by C++11.
Author : Alex_Wei.
*/
#include <bits/stdc++.h>
using namespace std;
//#pragma GCC optimize(3)
//using int = long long
//using i128 = __int128;
using uint = unsigned int;
using ll = long long;
using ull = unsigned long long;
using db = double;
using ld = long double;
using pii = pair <int,int>;
using pll = pair <ll,ll>;
using pdd = pair <double,double>;
using vint = vector <int>;
using vpii = vector <pii>;
#define fi first
#define se second
#define pb emplace_back
#define mpi make_pair
#define all(x) x.begin(),x.end()
#define sor(x) sort(all(x))
#define rev(x) reverse(all(x))
#define mem(x,v) memset(x,v,sizeof(x))
#define mcpy(x,y) memcpy(x,y,sizeof(y))
const int N=2e5+5;
const int S=26;
int node,rt[N],ls[N<<5],rs[N<<5],val[N<<5];
void push(int x){
val[x]=max(val[ls[x]],val[rs[x]]);
} void ins(int l,int r,int p,int &x){
x=++node;
if(l==r)return val[x]=p,void();
int m=l+r>>1;
if(p<=m)ins(l,m,p,ls[x]);
else ins(m+1,r,p,rs[x]);
push(x);
} int merge(int l,int r,int x,int y){
if(!x||!y)return x|y;
int z=++node,m=l+r>>1;
if(l==r)return val[z]=max(val[x],val[y]),z;
ls[z]=merge(l,m,ls[x],ls[y]),rs[z]=merge(m+1,r,rs[x],rs[y]);
return push(z),z;
} int query(int l,int r,int ql,int qr,int x){
if(!x)return 0;
if(ql<=l&&r<=qr)return val[x];
int m=l+r>>1,ans=0;
if(ql<=m)ans=query(l,m,ql,qr,ls[x]);
if(m<qr)ans=max(ans,query(m+1,r,ql,qr,rs[x]));
return ans;
}
// Suffix_Automaton
int a,b,c,d;
int n,m,K,cnt,las;
int fa[N],len[N],son[N][S];
int buc[N],id[N],f[N][S],ed[N];
vector <int> e[N];
void ins(int it){
int p=las,cur=++cnt;
len[cur]=len[las]+1,las=cur;
ins(1,n,len[cur],rt[cur]),ed[len[cur]]=cur;
while(p&&!son[p][it])son[p][it]=cur,p=fa[p];
if(!p)return fa[cur]=1,void();
int q=son[p][it];
if(len[p]+1==len[q])return fa[cur]=q,void();
int cl=++cnt;
fa[cl]=fa[q],fa[q]=fa[cur]=cl,len[cl]=len[p]+1;
mcpy(son[cl],son[q]);
while(p&&son[p][it]==q)son[p][it]=cl,p=fa[p];
} void build(char *s){
las=cnt=1,K=log2(n);
for(int i=1;i<=n;i++)ins(s[i]-'a');
for(int i=1;i<=cnt;i++)buc[len[i]]++;
for(int i=1;i<=n;i++)buc[i]+=buc[i-1];
for(int i=cnt;i;i--)id[buc[len[i]]--]=i;
for(int i=cnt;i>1;i--)rt[fa[id[i]]]=merge(1,n,rt[fa[id[i]]],rt[id[i]]);
for(int j=0;j<=K;j++)for(int i=1;i<=cnt;i++)f[i][j]=j?f[f[i][j-1]][j-1]:fa[i];
} int qpos(int pos){
return query(1,n,1,b,rt[pos]);
}
char s[N];
int main(){
cin>>n>>m,scanf("%s",s+1);
reverse(s+1,s+n+1),build(s);
while(m--){
cin>>a>>b>>c>>d;
a=n-a+1,b=n-b+1,c=n-c+1,d=n-d+1,swap(a,b),swap(c,d);
int p=ed[d];
for(int i=K;~i;i--)if(f[p][i]){
int pp=f[p][i],pos=qpos(pp);
if(len[pp]>=pos-a+1)p=pp;
} int pos=qpos(p);
cout<<min(d-c+1,max(pos-a+1,len[f[p][0]]))<<endl;
}
return 0;
}
*XI. P5284 [十二省联考2019]字符串问题
题意自己看吧,懒得简述了。
这题目一看就很 SAM,而且 SAM 套路做多了就是一眼题。
首先看到 “\(B\) 类串为 \(t_{i+1}\) 的前缀” 直接建出反串的 SAM,因此以一个 \(B\) 类串 \(B_i\) 为后缀的所有 \(S\) 的子串为在 SAM 上 \(B_i\) 所表示状态 \(p\) 在 fail 树上的子树。因此一个 \(A\) 类串 \(A_i\) 可以和若干个 fail 树的子树接在一起。那么直接向能接在一起的所有相邻的子串连边,然后如果出现环则无解。可是这样连边是 \(\mathcal{O}(n^2)\) 的。
trick 5:使用 SAM 的 fail 树优化建图。
既然是一个点向所有子树连边,那么直接在原 fail 树的基础上将该点与子树的根节点连起来即可。这样就可做到 \(\mathcal{O}(n)\) 规模。
一个注意点:注意到一个状态可能对应多个子串,那么将该状态的所有 \(A,B\) 类串按长度从小到大为第一关键字,是否是 \(B\) 类串为第二关键字排序,然后按顺序拆点即可(所在状态相同的长度相同 \(A,B\) 类串相等,\(A\) 串可以作 \(B\) 串的子串,所以 \(B\) 串要是 \(A\) 串的祖先)
然而我没有想到在 fail 树上建图,是直接用线段树优化建图,线段树优化 DAG 上 DP,于是 2h 码了细节巨大多的 5k。看到题解后才学会这样的技巧。好题!
能看懂代码算我输。
Luogu P5284 代码
/*
Powered by C++11.
Author : Alex_Wei.
*/
#include <bits/stdc++.h>
using namespace std;
using ll = long long;
using vint = vector <int>;
#define pb emplace_back
#define all(x) x.begin(),x.end()
#define rev(x) reverse(all(x))
#define mem(x,v) memset(x,v,sizeof(x))
#define mcpy(x,y) memcpy(x,y,sizeof(y))
const int N=4e5+5;
const int S=26;
const int inf=1e9+7;
// Segtree_Min
int deg[N],val[N<<2],laz[N<<2];
void up(int x){
val[x]=min(val[x<<1],val[x<<1|1]);
} void down(int x){
if(laz[x]){
val[x<<1]-=laz[x],val[x<<1|1]-=laz[x];
laz[x<<1]+=laz[x],laz[x<<1|1]+=laz[x];
} laz[x]=0;
} void build(int l,int r,int x){
laz[x]=val[x]=0;
if(l==r)return val[x]=deg[l],void();
int m=l+r>>1;
build(l,m,x<<1),build(m+1,r,x<<1|1),up(x);
} void modify(int l,int r,int ql,int qr,int x){
if(ql<=l&&r<=qr)return val[x]--,laz[x]++,void();
int m=l+r>>1; down(x);
if(ql<=m)modify(l,m,ql,qr,x<<1);
if(m<qr)modify(m+1,r,ql,qr,x<<1|1); up(x);
} int query(int l,int r,int x){
if(l==r)return val[x]=inf,l;
int m=l+r>>1,ans; down(x);
if(!val[x<<1])ans=query(l,m,x<<1);
else ans=query(m+1,r,x<<1|1);
return up(x),ans;
}
// SegTree_Max
ll ini[N<<2],val2[N<<2],laz2[N<<2];
void cmax(ll &x,ll y){
x=max(x,y);
} void up2(int x){
val2[x]=max(val2[x<<1],val2[x<<1|1]);
} void down2(int x){
if(laz[x]!=-1){
cmax(laz2[x<<1],laz2[x]),cmax(laz2[x<<1|1],laz2[x]);
cmax(val2[x<<1],laz2[x]),cmax(val2[x<<1|1],laz2[x]);
} laz2[x]=-1;
} void build2(int l,int r,int x){
val2[x]=laz2[x]=-1;
if(l==r)return val2[x]=ini[l],void();
int m=l+r>>1;
build2(l,m,x<<1),build2(m+1,r,x<<1|1),up2(x);
} void modify2(int l,int r,int ql,int qr,int x,ll v){
if(ql<=l&&r<=qr)return cmax(val2[x],v),cmax(laz2[x],v),void();
int m=l+r>>1; down2(x);
if(ql<=m)modify2(l,m,ql,qr,x<<1,v);
if(m<qr)modify2(m+1,r,ql,qr,x<<1|1,v); up2(x);
} ll query2(int l,int r,int p,int x){
if(l==r)return val2[x];
int m=l+r>>1; down2(x);
if(p<=m)return query2(l,m,p,x<<1);
return query2(m+1,r,p,x<<1|1);
}
// Suffix_Automaton
int n,K,cnt,las;
int fa[N],len[N],ed[N],son[N][S],ff[N][S];
vint FAIL[N];
void ins(char s){
int p=las,cur=++cnt,it=s-'a';
len[cur]=len[las]+1,ed[len[cur]]=cur,las=cur;
while(p&&!son[p][it])son[p][it]=cur,p=fa[p];
if(!p)return fa[cur]=1,void();
int q=son[p][it];
if(len[p]+1==len[q])return fa[cur]=q,void();
int cl=++cnt;
fa[cl]=fa[q],fa[q]=fa[cur]=cl,len[cl]=len[p]+1;
mcpy(son[cl],son[q]);
while(son[p][it]==q)son[p][it]=cl,p=fa[p];
} void build(char *s){
for(int i=1;i<=n;i++)ins(s[i]);
for(int i=2;i<=cnt;i++)FAIL[fa[i]].pb(i),ff[i][0]=fa[i];
K=log2(cnt);
for(int i=1;i<=K;i++)for(int j=1;j<=cnt;j++)ff[j][i]=ff[ff[j][i-1]][i-1];
} int getpos(int l,int r){
int p=ed[r];
for(int i=K;~i;i--)if(r-len[ff[p][i]]+1<=l)p=ff[p][i];
return p;
}
char s[N];
int na,nb,tot,m;
int dnum,lens[N],tmp[N],rev[N],id[N],sz[N];
vint DAG[N],tag[N];
bool cmp(int a,int b){
return lens[a]!=lens[b]?lens[a]<lens[b]:a>b;
} int dfs(int d){
int z=tag[d].size(),l=dnum+1,r=dnum+z;
sort(all(tag[d]),cmp);
for(int it:tag[d])id[it]=++dnum;
for(int it:FAIL[d])z+=dfs(it);
for(int i=l;i<=r;i++)sz[i]=z-(i-l);
return z;
}
void clear(){
for(int i=1;i<=cnt;i++)mem(son[i],0),mem(ff[i],0),ed[i]=len[i]=fa[i]=0;
for(int i=1;i<=cnt;i++)FAIL[i].clear(),tag[i].clear();
for(int i=1;i<=tot+1;i++)lens[i]=id[i]=sz[i]=deg[i]=0;
for(int i=1;i<=na;i++)DAG[i].clear();
las=cnt=1,dnum=na=nb=tot=0;
} void init(){
scanf("%s%d",s+1,&na),n=strlen(s+1);
reverse(s+1,s+n+1),build(s);
for(int i=1;i<=na;i++){
int l,r; scanf("%d%d",&l,&r);
l=n-l+1,r=n-r+1,swap(l,r),lens[i]=r-l+1;
tag[getpos(l,r)].pb(i);
} scanf("%d",&nb),tot=na+nb;
for(int i=1;i<=nb;i++){
int l,r; scanf("%d%d",&l,&r);
l=n-l+1,r=n-r+1,swap(l,r),lens[i+na]=r-l+1;
tag[getpos(l,r)].pb(i+na);
} scanf("%d",&m);
for(int i=1;i<=m;i++){
int x,y; scanf("%d%d",&x,&y);
DAG[x].pb(y+na);
} dfs(1);
for(int i=1;i<=tot;i++)tmp[id[i]]=lens[i];
for(int i=1;i<=tot;i++)lens[i]=tmp[i],rev[id[i]]=i;
}
queue <int> q;
bool update(){
if(val[1])return 0;
int p=query(1,tot,1);
return ini[p]=0,q.push(p),1;
} bool calc_deg(){
for(int i=1;i<=na;i++)
for(int it:DAG[i]){
int l=id[it],r=l+sz[l]-1;
if(l<=id[i]&&id[i]<=r)return 1;
deg[l]++,deg[r+1]--;
}
for(int i=1;i<=tot;i++)deg[i]+=deg[i-1];
for(int i=na+1;i<=tot;i++)deg[id[i]]=inf;
return build(1,tot,1),0;
} ll topo(){
for(int i=1;i<=tot;i++)ini[i]=-1;
while(update()); build2(1,tot,1);
ll ans=0;
while(!q.empty()){
ll t=q.front(),v=query2(1,tot,t,1)+lens[t]; q.pop();
cmax(ans,v);
for(int it:DAG[rev[t]]){
int l=id[it],r=l+sz[l]-1;
modify(1,tot,l,r,1),modify2(1,tot,l,r,1,v);
while(update());
}
} return val[1]<1e6?-1:ans;
}
void solve(){
clear(),init();
if(calc_deg())return puts("-1"),void();
cout<<topo()<<endl;
} int main(){
int t; cin>>t;
while(t--)solve();
return 0;
}
XII. CF235C Cyclical Quest
题意简述:给出 \(s\),多次询问给出字符串 \(t\) 所有循环同构串去重后在 \(s\) 中出现次数之和。
如果没有循环同构那么就是 ACAM/SA/SAM 板子题。关于循环同构的一个常见套路就是将 \(t\) 复制一份在后面。那么我们如法炮制,用 \(2t\) 在 SAM 上跑匹配。如果当前长度大于 \(|t|\),那么就不断将匹配长度 \(d\) 减一,同时判断当前状态是否能表示长度为 \(d\) 的字符串(即是否有 \(len(link(p))<d\leq len(p)\)),如果没有就要向上跳。
注意到题目需要去重,同时两个长度为 \(|t|\) 的 \(s\) 的不同子串一定被不同的状态表示,所以计算一个位置贡献后打上标记,后面再遇到这个位置就不算贡献了,每次查询后撤销标记即可(可以用 vector 记录打上标记的位置)。
时间复杂度为 \(\mathcal{O}(|s||\Sigma|+\sum|t|)\),其中 \(\Sigma\) 为字符集。
CF235C 代码
/*
Powered by C++11.
Author : Alex_Wei.
*/
#include <bits/stdc++.h>
using namespace std;
#define ll long long
#define pb emplace_back
const int N=2e6+5;
const int S=26;
int las,cnt;
int son[N][S],len[N],fa[N],ed[N];
int buc[N],id[N],vis[N];
void ins(char s){
int p=las,cur=++cnt,it=s-'a';
len[cur]=len[p]+1,ed[cur]++,las=cur;
while(p&&!son[p][it])son[p][it]=cur,p=fa[p];
if(!p)return fa[cur]=1,void();
int q=son[p][it];
if(len[p]+1==len[q])return fa[cur]=q,void();
int cl=++cnt;
fa[cl]=fa[q],fa[q]=fa[cur]=cl,len[cl]=len[p]+1;
memcpy(son[cl],son[q],sizeof(son[q]));
while(son[p][it]==q)son[p][it]=cl,p=fa[p];
} void build(char *s){
int n=strlen(s+1); las=cnt=1;
for(int i=1;i<=n;i++)ins(s[i]);
for(int i=1;i<=cnt;i++)buc[len[i]]++;
for(int i=1;i<=cnt;i++)buc[i]+=buc[i-1];
for(int i=cnt;i;i--)id[buc[len[i]]--]=i;
for(int i=cnt;i;i--)ed[fa[id[i]]]+=ed[id[i]];
}
int n;
char s[N];
int main(){
scanf("%s%d",s+1,&n),build(s);
for(int i=1;i<=n;i++){
scanf("%s",s+1);
ll p=1,l=strlen(s+1),d=0,ans=0;
vector <int> del;
for(int i=1;i<l*2;i++){
int it=s[i>l?i-l:i]-'a';
while(p&&!son[p][it])p=fa[p],d=len[p];
if(p){
p=son[p][it],d++;
while(d>l)if((--d)<=len[fa[p]])p=fa[p];
if(d>=l&&!vis[p])ans+=ed[p],vis[p]=1,del.pb(p);
} else p=1;
} cout<<ans<<endl;
for(int it:del)vis[it]=0;
}
return 0;
}
XIII. CF1073G Yet Another LCP Problem
见 CF1073G 题解。
怎么混进来一道 SA。
XIV. CF802I Fake News (hard)
题意简述:给出 \(s\),求所有 \(s\) 的子串 \(p\) 在 \(s\) 中的出现次数平方和,重复的子串只算一次。
这是什么板子题?
对 \(s\) 建出 SAM 可以自动去重,考虑每个状态 \(p\),它所表示的字串个数为 \(len(p)-len(link(p))\),出现次数为 \(p\) 在 \(link\) 树上的子树所包含的终止节点个数(终止节点是 \(s\) 所有前缀在 SAM 上表示的状态),记为 \(ed_p\)。那么答案为 \(\sum_{i=1}^{cnt} ed^2_p\times (len(p)-len(link(p)))\)。
时间复杂度线性。
CF802I 代码
/*
Powered by C++11.
Author : Alex_Wei.
*/
#include <bits/stdc++.h>
using namespace std;
#define ll long long
#define mem(x,v) memset(x,v,sizeof(x))
const int N=2e5+5;
const int S=26;
int cnt,las,son[N][S],ed[N],fa[N],len[N],buc[N],id[N];
void clear(){
mem(son,0),mem(ed,0),mem(fa,0),mem(len,0),mem(buc,0);
cnt=las=1;
} void ins(char s){
int p=las,cur=++cnt,it=s-'a';
len[cur]=len[p]+1,las=cur,ed[cur]=1;
while(!son[p][it])son[p][it]=cur,p=fa[p];
if(!p)return fa[cur]=1,void();
int q=son[p][it];
if(len[p]+1==len[q])return fa[cur]=q,void();
int cl=++cnt;
fa[cl]=fa[q],fa[q]=fa[cur]=cl,len[cl]=len[p]+1;
memcpy(son[cl],son[q],sizeof(son[q]));
while(son[p][it]==q)son[p][it]=cl,p=fa[p];
} ll build(char *s){
int n=strlen(s+1); clear();
for(int i=1;i<=n;i++)ins(s[i]);
for(int i=1;i<=cnt;i++)buc[len[i]]++;
for(int i=1;i<=n;i++)buc[i]+=buc[i-1];
for(int i=cnt;i;i--)id[buc[len[i]]--]=i;
for(int i=cnt;i;i--)ed[fa[id[i]]]+=ed[id[i]];
ll ans=0;
for(int i=1;i<=cnt;i++)ans+=1ll*ed[i]*ed[i]*(len[i]-len[fa[i]]);
return ans;
}
int n;
char s[N];
int main(){
cin>>n;
for(int i=1;i<=n;i++)scanf("%s",s+1),cout<<build(s)<<endl;
return 0;
}
XV. CF123D String
题意简述:给出 \(s\),求所有 \(s\) 的子串 \(p\) 在 \(s\) 中的出现位置的所有子串个数,字符串的重复子串只算一次。
这是什么板子题?
对 \(s\) 建出 SAM 可以自动去重,考虑每个状态 \(p\),它所表示的字串个数为 \(len(p)-len(link(p))\),出现次数为 \(p\) 在 \(link\) 树上的子树所包含的终止节点个数(终止节点是 \(s\) 所有前缀在 SAM 上表示的状态),记为 \(ed_p\)。那么答案为 \(\sum_{i=1}^{cnt} \frac{ed_p(ed_p+1)}{2}\times (len(p)-len(link(p)))\)。
时间复杂度线性。
CF123D 代码
/*
Powered by C++11.
Author : Alex_Wei.
*/
#include <bits/stdc++.h>
using namespace std;
#define ll long long
#define mem(x,v) memset(x,v,sizeof(x))
const int N=2e5+5;
const int S=26;
int cnt,las,son[N][S],ed[N],fa[N],len[N],buc[N],id[N];
void clear(){
mem(son,0),mem(ed,0),mem(fa,0),mem(len,0),mem(buc,0);
cnt=las=1;
} void ins(char s){
int p=las,cur=++cnt,it=s-'a';
len[cur]=len[p]+1,las=cur,ed[cur]=1;
while(!son[p][it])son[p][it]=cur,p=fa[p];
if(!p)return fa[cur]=1,void();
int q=son[p][it];
if(len[p]+1==len[q])return fa[cur]=q,void();
int cl=++cnt;
fa[cl]=fa[q],fa[q]=fa[cur]=cl,len[cl]=len[p]+1;
memcpy(son[cl],son[q],sizeof(son[q]));
while(son[p][it]==q)son[p][it]=cl,p=fa[p];
} ll build(char *s){
int n=strlen(s+1); clear();
for(int i=1;i<=n;i++)ins(s[i]);
for(int i=1;i<=cnt;i++)buc[len[i]]++;
for(int i=1;i<=n;i++)buc[i]+=buc[i-1];
for(int i=cnt;i;i--)id[buc[len[i]]--]=i;
for(int i=cnt;i;i--)ed[fa[id[i]]]+=ed[id[i]];
ll ans=0;
for(int i=1;i<=cnt;i++)ans+=1ll*ed[i]*(ed[i]+1)/2*(len[i]-len[fa[i]]);
return ans;
}
int n;
char s[N];
int main(){
scanf("%s",s+1),cout<<build(s)<<endl;
return 0;
}
*XVI. P4384 [八省联考2018]制胡窜
题意简述:给出字符串 \(s\),多次询问给出 \(l,r\),求有多少对 \((i,j)\ (1\leq i<j\leq n,i+1<j)\) 使得 \(s_{1,i},s_{i+1,j-1},s_{j,n}\) 中至少出现一次 \(s_{l,r}\)。
套路题大赏 & 阿巴细节题(五一劳动节当然要写码农题)。
约定:记 \(len=r-l+1\),\(t=s_{l,r}\),\(l_{1,2,\cdots,c},r_{1,2,\cdots,c}\) 为 \(t\) 在 \(s\) 中所有出现位置(\(l\) 开头,\(r\) 结尾,有 \(l_i+len-1=r_i\))。
转化题目所求数对 \((i,j)\):不难看出其等价于在 \(i,j-1\) 处切两刀所得到的三个字符串中至少出现一次 \(t\)。正难则反,将答案写成 \(\binom{n-1}{2}-ans\),其中 \(ans\) 表示切两刀切不出 \(t\) 的方案数。
当有三个及三个以上互不相交的 \(t\) 时:显然 \(ans=0\)。
当最左边的 \(t\) 与最右边的 \(t\) 相交(\(r_1+len>r_c\))时:
- 若第一刀切在 \(l_1\) 左边,那么第二刀必须切在相交部分(\([l_c,r_1]\))中间,方案数为 \((l_1-1)(r_1-p_c)\)。
- 若第一刀切在 \(l_i\) 与 \(l_{i+1}\ (i<c)\) 间,那么第二刀必须切在 \(l_c\) 与 \(r_{i+1}\) 间,方案数为 \((l_{i+1}-l_i)(r_{i+1}-l_c)\)。
- 若第一刀切在相交部分中间,第二刀可以切在其右边的任意一个位置,方案数为 \((n-r_1)+(n-r_1+1)+\cdots+(n-l_c-1)=\frac{(2n-r_1-l_c-1)(r_1-l_c)}{2}\)。
- 若第一刀切在相交部分右边,则 \(s_{1,i}\) 必然包含 \(t\),舍去。
比较麻烦的是 part 2,因为枚举每一个位置时间复杂度必然会爆炸。根据两个字符串出现的开头结尾的相对位置不变进行变形:
\[\begin{aligned}&\sum_{1\leq i<c}(l_{i+1}-l_i)(r_{i+1}-l_c)\\=&\sum_{1\leq i<c}(r_{i+1}-r_i)(r_{i+1}-l_c)\\=&\sum_{1\leq i<c}r^2_{i+1}-r_ir_{i+1}-(r_{i+1}-r_i)l_c\\=&-(r_c-r_1)l_c+\sum_{1\leq i<c}r^2_{i+1}-r_ir_{i+1}\end{aligned}
\]因此我们只需在线段树上维护 \(\sum r^2_i\) 和 \(\sum r_ir_{i+1}\) 即可。
当左边的 \(t\) 与最右边的 \(t\) 不相交时:设 \(m\) 为使 \(r_i+len\leq r_c\) 的最大的 \(i\)。
- 若第一刀切在 \(l_m\) 左边,那么其右边有两个不相交的 \(t\),但只能切割其中一个,舍去。
- 若第一刀切在 \(l_m\) 与 \(r_1\) 间,发现不方便统计,继续分类:设 \(lim\) 为使 \(l_i\leq r_1\) 的最大的 \(i\)。
- 若第一刀切在 \(l_i\) 与 \(l_{i+1}\ (m\leq i<lim)\) 间:类似上文推一推即可,方案数为 \(-(r_{lim}-r_m)l_c+\sum_{m\leq i<lim}r^2_{i+1}-r_ir_{i+1}\)。
- 若第一刀切在 \(l_{lim}\) 与 \(r_1\) 间,第二刀必须切在 \(l_c\) 与 \(r_{lim+1}\) 间(因为必须切掉第 \(lim+1\) 个 \(t\)),方案数为 \((r_1-l_{lim})(r_{lim+1}-l_2)\)。
- 若第一刀切在 \(r_1\) 右边,不符合题意,舍去。
理论分析完毕,接下来是实现:首先对 \(s\) 建出 SAM;根据 trick 4 用线段树合并维护 endpos 集合,以及区间 \(\min,\max,r^2_i,r_ir_{i+1}\);同时根据 trick 3 可以倍增跳到 \(t\) 所表示的区间。总时间复杂度 \(\mathcal{O}((n+q)\log n)\)。
码完一遍过,可喜可贺。
P4384 代码
/*
Author : Alex_Wei
Problem : P4384 [八省联考2018]制胡窜
Powered by C++11
2021.4.26 20:22
*/
#include <bits/stdc++.h>
using namespace std;
using ll = long long;
const int N=2e5+5;
const int inf=1e9+7;
const int K=17;
const int S=10;
ll n,node;
char s[N];
int rt[N],ls[N<<6],rs[N<<6];
ll mi[N<<6],mx[N<<6],val[N<<6],sq[N<<6];
void push(int x){
mi[x]=min(mi[ls[x]],mi[rs[x]]);
mx[x]=max(mx[ls[x]],mx[rs[x]]);
val[x]=val[ls[x]]+val[rs[x]]+mx[ls[x]]*(mi[rs[x]]<inf?mi[rs[x]]:0);
sq[x]=sq[ls[x]]+sq[rs[x]];
} void modify(int l,int r,int p,int &x){
x=++node;
if(l==r)return mi[x]=mx[x]=l,sq[x]=1ll*l*l,void();
int m=l+r>>1;
if(p<=m)modify(l,m,p,ls[x]);
else modify(m+1,r,p,rs[x]);
push(x);
} int merge(int l,int r,int x,int y){
if(!x||!y)return x|y;
int z=++node,m=l+r>>1;
if(l==r)return mi[z]=mx[z]=l,sq[x]=1ll*l*l,z;
ls[z]=merge(l,m,ls[x],ls[y]),rs[z]=merge(m+1,r,rs[x],rs[y]);
return push(z),z;
}
struct data{
ll mi,mx,val,sq;
data operator + (data x){
return {min(mi,x.mi),max(mx,x.mx),val+x.val+mx*(x.mi<inf?x.mi:0),sq+x.sq};
}
};
data query(int l,int r,int ql,int qr,int x){
if(ql<=l&&r<=qr)return {mi[x],mx[x],val[x],sq[x]};
int m=l+r>>1;
if(ql<=m&&m<qr)return query(l,m,ql,qr,ls[x])+query(m+1,r,ql,qr,rs[x]);
if(ql<=m)return query(l,m,ql,qr,ls[x]);
return query(m+1,r,ql,qr,rs[x]);
}
int cnt,las;
int son[N][S],fa[N],len[N],ed[N];
int id[N],buc[N],anc[N][K];
void ins(char s){
int it=s-'0',cur=++cnt,p=las;
len[las=cur]=len[p]+1,ed[len[cur]]=cur;
modify(1,n,len[cur],rt[cur]);
while(!son[p][it])son[p][it]=cur,p=fa[p];
if(!p)return fa[cur]=1,void();
int q=son[p][it];
if(len[p]+1==len[q])return fa[cur]=q,void();
int cl=++cnt;
fa[cl]=fa[q],fa[q]=fa[cur]=cl,len[cl]=len[p]+1;
memcpy(son[cl],son[q],sizeof(son[q]));
while(p&&son[p][it]==q)son[p][it]=cl,p=fa[p];
} void build(char *s){
las=cnt=1;
for(int i=0;i<n;i++)ins(s[i]);
for(int i=0;i<K;i++)
for(int j=1;j<=cnt;j++)
if(i)anc[j][i]=anc[anc[j][i-1]][i-1];
else anc[j][i]=fa[j];
for(int i=1;i<=cnt;i++)buc[len[i]]++;
for(int i=1;i<=n;i++)buc[i]+=buc[i-1];
for(int i=cnt;i;i--)id[buc[len[i]]--]=i;
for(int i=cnt;i;i--)rt[fa[id[i]]]=merge(1,n,rt[fa[id[i]]],rt[id[i]]);
}
ll sum(ll a,ll b){return (a+b)*(b-a+1)/2;}
int q,l,r;
int main(){
memset(mi,0x3f,sizeof(mi));
scanf("%d%d%s",&n,&q,s),build(s);
while(q--){
scanf("%d%d",&l,&r);
int p=ed[r],ln=r-l+1;
for(int i=K-1;~i;i--)if(len[anc[p][i]]>=ln)p=anc[p][i];
data dt=query(1,n,1,n,rt[p]);
ll lp=dt.mi,l1=lp-ln+1,rp=dt.mx,l2=rp-ln+1;
ll ans=1ll*(n-1)*(n-2)/2;
if(lp>=l2){
ll cover=lp-l2+1;
ans-=(l1-1)*(cover-1);
ans-=(dt.sq-lp*lp)-dt.val-(rp-lp)*l2;
ans-=sum(n-lp,n-l2-1);
printf("%lld\n",ans);
continue;
}
data dm=query(1,n,1,rp-ln,rt[p]);
ll mp=dm.mx,lm=mp-ln+1;
if(lp+ln<=mp){
printf("%lld\n",ans);
continue;
}
data dr=query(1,n,mp,lp+ln-1,rt[p]);
ans-=(dr.sq-mp*mp)-dr.val-(dr.mx-mp)*l2;
ans-=(lp-(dr.mx-ln+1))*(query(1,n,dr.mx+1,n,rt[p]).mi-l2);
printf("%lld\n",ans);
}
return 0;
}
*XVII. (SA)P6095 [JSOI2015]串分割
显然的贪心是让最大位数最小,即 \(len=\lceil\frac{n}{k}\rceil\)。
同时答案满足可二分性,那么我们破环成链,枚举 \(len\) 个断点并判断是否可行。具体来说,假设当前匹配到 \(i\),若 \(s_{i,i+len-1}\) 不大于二分的答案,那么就匹配 \(len\) 位,否则匹配 \(len-1\) 位。若总匹配位数不小于 \(n\) 则可行。
正确性证明:若可匹配 \(len\) 位时匹配 \(len-1\) 位,则下一次最多匹配 \(len\) 位,这与首先匹配 \(len\) 位的下一次匹配的最坏情况(即匹配 \(len-1\) 为)相同(\((len-1)+len=len+(len-1)\))。得证。
P6095
#include <bits/stdc++.h>
using namespace std;
const int N=4e5+5;
char s[N];
int n,k,len;
int sa[N],rk[N<<1],ork[N<<1];
int buc[N],id[N],px[N];
bool cmp(int a,int b,int w){
return ork[a]==ork[b]&&ork[a+w]==ork[b+w];
}
void build(int n){
int m=128;
for(int i=1;i<=n;i++)buc[rk[i]=s[i]]++;
for(int i=1;i<=m;i++)buc[i]+=buc[i-1];
for(int i=n;i;i--)sa[buc[rk[i]]--]=i;
for(int w=1,p=0;w<=n;w<<=1,m=p,p=0){
for(int i=n;i>n-w;i--)id[++p]=i;
for(int i=1;i<=n;i++)if(sa[i]>w)id[++p]=sa[i]-w;
for(int i=0;i<=m;i++)buc[i]=0;
for(int i=1;i<=n;i++)buc[px[i]=rk[id[i]]]++;
for(int i=1;i<=m;i++)buc[i]+=buc[i-1];
for(int i=n;i;i--)sa[buc[px[i]]--]=id[i];
for(int i=1;i<=n;i++)ork[i]=rk[i]; p=0;
for(int i=1;i<=n;i++)rk[sa[i]]=cmp(sa[i],sa[i-1],w)?p:++p;
if(p==n)break;
}
}
bool check(int d){
for(int i=1;i<=len;i++){
int pos=i;
for(int j=1;j<=k;j++){
pos+=len-(rk[pos]>d);
if(pos>=i+n)return 1;
}
} return 0;
}
int main(){
scanf("%d%d%s",&n,&k,s+1);
for(int i=1;i<=n;i++)s[i+n]=s[i];
len=(n-1)/k+1,build(n<<1);
int l=1,r=n*2;
while(l<r){
int m=l+r>>1;
if(check(m))r=m;
else l=m+1;
} for(int i=sa[l];i<sa[l]+len;i++)cout<<s[i];
return 0;
}
SAM 做题笔记(各种技巧,持续更新,SA)的更多相关文章
- markdown常用语法使用笔记+使用技巧(持续更新......)
参考引用内容: 简书教程 一 基本语法 1. 标题 语法: 在想要设置为标题的文字前面加#来表示,一个#是一级标题,二个#是二级标题,以此类推.支持六级标题. 注:标准语法一般在#后跟个空格再写文字 ...
- SDOI2016 R1做题笔记
SDOI2016 R1做题笔记 经过很久很久的时间,shzr终于做完了SDOI2016一轮的题目. 其实没想到竟然是2016年的题目先做完,因为14年的六个题很早就做了四个了,但是后两个有点开不动.. ...
- fastadmin 后台管理框架使用技巧(持续更新中)
fastadmin 后台管理框架使用技巧(持续更新中) FastAdmin是一款基于ThinkPHP5+Bootstrap的极速后台开发框架,具体介绍,请查看文档,文档地址为:https://doc. ...
- Sam做题记录
Sam做题记录 Hihocoder 后缀自动机二·重复旋律5 求一个串中本质不同的子串数 显然,答案是 \(\sum len[i]-len[fa[i]]\) Hihocoder 后缀自动机三·重复旋律 ...
- LCT做题笔记
最近几天打算认真复习LCT,毕竟以前只会板子.正好也可以学点新的用法,这里就用来写做题笔记吧.这个分类比较混乱,主要看感觉,不一定对: 维护森林的LCT 就是最普通,最一般那种的LCT啦.这类题目往往 ...
- C语言程序设计做题笔记之C语言基础知识(下)
C 语言是一种功能强大.简洁的计算机语言,通过它可以编写程序,指挥计算机完成指定的任务.我们可以利用C语言创建程序(即一组指令),并让计算机依指令行 事.并且C是相当灵活的,用于执行计算机程序能完成的 ...
- C语言程序设计做题笔记之C语言基础知识(上)
C语言是一种功能强大.简洁的计算机语言,通过它可以编写程序,指挥计算机完成指定的任务.我们可以利用C语言创建程序(即一组指令),并让计算机依指令行事.并且C是相当灵活的,用于执行计算机程序能完成的几乎 ...
- SDOI2017 R1做题笔记
SDOI2017 R1做题笔记 梦想还是要有的,万一哪天就做完了呢? 也就是说现在还没做完. 哈哈哈我竟然做完了-2019.3.29 20:30
- SDOI2014 R1做题笔记
SDOI2014 R1做题笔记 经过很久很久的时间,shzr又做完了SDOI2014一轮的题目. 但是我不想写做题笔记(
随机推荐
- javascript-jquery对象的事件处理
一.页面加载 1.页面加载顺序:先加载<head></head>之间的内容,然后加载<body></body>之间的内容 直接在head之间书写jque ...
- [敏捷软工团队博客]Beta阶段发布声明
项目 内容 2020春季计算机学院软件工程(罗杰 任健) 博客园班级博客 作业要求 Beta阶段发布声明 我们在这个课程的目标是 在团队合作中锻炼自己 这个作业在哪个具体方面帮助我们实现目标 对Bet ...
- 2020BUAA软工热身作业
2020BUAA软工热身作业 17373010 杜博玮 项目 内容 这个作业属于哪个课程 2020春季计算机学院软件工程(罗杰 任健) 这个作业的要求在哪里 热身作业 我在这个课程的目标是 学习软件工 ...
- Noip模拟77 2021.10.15
T1 最大或 $T1$因为没有开$1ll$右移给炸掉了,调了一年不知道为啥,最后实在不懂了 换成$pow$就过掉了,但是考场上这题耽误了太多时间,后面的题也就没办法好好打了.... 以后一定要注意右移 ...
- Noip模拟35 2021.8.10
考试题目变成四道了,貌似确实根本改不完... 不过给了两个小时颓废时间确实很爽(芜湖--) 但是前几天三道题改着不是很费劲的时候为什么不给放松时间, 非要在改不完题的时候颓?? 算了算了不碎碎念了.. ...
- Linux零基础之shell基础编程入门
从程序员的角度来看, Shell本身是一种用C语言编写的程序,从用户的角度来看,Shell是用户与Linux操作系统沟通的桥梁.用户既可以输入命令执行,又可以利用 Shell脚本编程,完成更加复杂的操 ...
- IE浏览器——网络集合代理无法启动
用管理员身份运行cmd然后输入 sc config diagnosticshub.standardcollector.service start=demand
- Spring Security:Servlet 过滤器(三)
3)Servlet 过滤器 Spring Security 过滤器链是一个非常复杂且灵活的引擎.Spring Security 的 Servlet 支持基于 Servlet 过滤器,因此通常首先了解过 ...
- Oracle 相关命令
http://www.mamicode.com/info-detail-2481866.html sql语句 system用户登陆 查看表空间和存放位置 select t1.name,t2.name ...
- PHP查看内存占用
function test(){ echo memory_get_usage(), '<br>'; $start = memory_get_usage(); $a = []; for ($ ...