爬虫——正则表达式爬取豆瓣电影TOP前250的中英文名
正则表达式爬取豆瓣电影TOP前250的中英文名
1、首先要实现网页的数据的爬取。新建test.py文件
test.py
1 import requests
2
3 def get_Html_text(url,p):
4 try:
5 h= {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36 Edg}#User-Agent随便进入一个网页F12->Network->选择xxx?xxx,找到自己的User-Agent复制粘贴就好了
6
7 r = requests.get(url,params=p,headers=h)
8 r.raise_for_status()
9 r.encoding=r.apparent_encoding
10 return r.text
11 except:
12 return 'error'
13
14
15
16 if __name__=='__main__':
17 url = 'https://movie.douban.com/top250'
18 for i in range(0,226,25):#实现循环爬取
19 p={'start':str(i),'filter':''}
20 html_text=get_Html_text(url,p)
21 if html_text!='error':
22 with open('c.txt','at',encoding='utf-8') as f:#将文件爬取到的文件写入c.txt中
23 f.write(html_text)
24
2、利用正则表达式规则对爬取到的数据进行筛选,当前我们仅需要中文电影名与英文电影名。
test2.py
1 import re#这里我们需要导入re
2 with open ('c.txt','rt',encoding='utf-8')as f:
3 html_text=f.read()
4 pat=re.compile(r'<span class="title">(.*?)</span>.*?<span class="title"> / (.*?)</span>',re.S)
5 mats=pat.finditer(html_text)
6 for i in mats:
7 print(i.group(1),i.group(2))
3、运行结果
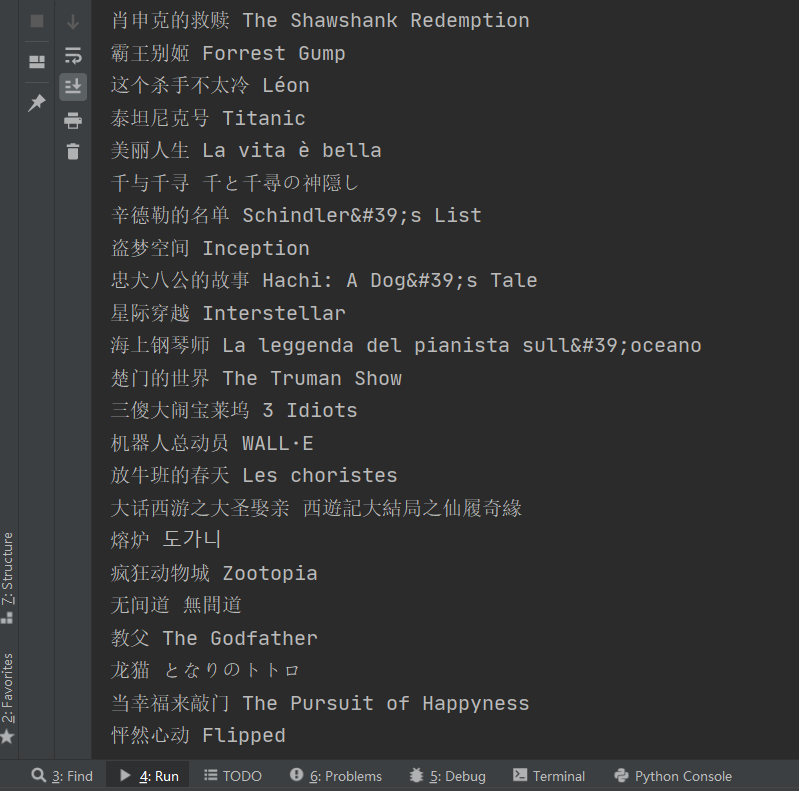
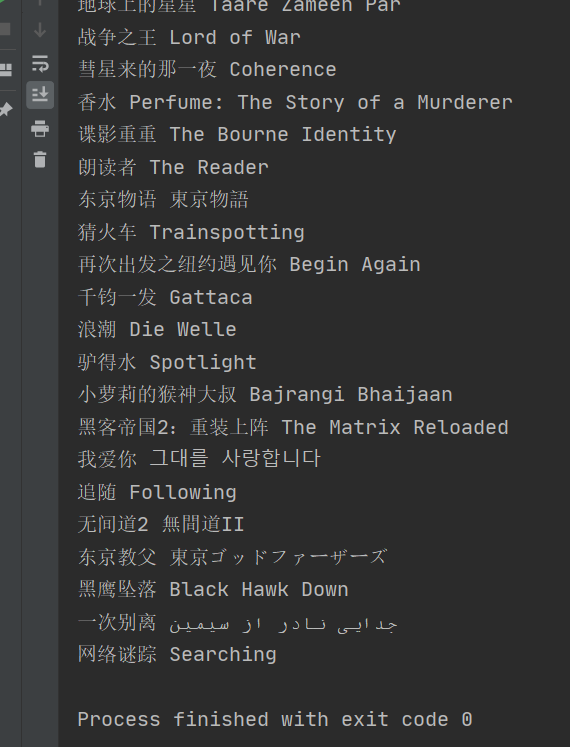
爬虫——正则表达式爬取豆瓣电影TOP前250的中英文名的更多相关文章
- 爬虫系列1:Requests+Xpath 爬取豆瓣电影TOP
爬虫1:Requests+Xpath 爬取豆瓣电影TOP [抓取]:参考前文 爬虫系列1:https://www.cnblogs.com/yizhiamumu/p/9451093.html [分页]: ...
- 爬取豆瓣电影TOP 250的电影存储到mongodb中
爬取豆瓣电影TOP 250的电影存储到mongodb中 1.创建项目sp1 PS D:\scrapy> scrapy.exe startproject douban 2.创建一个爬虫 PS D: ...
- 第一个nodejs爬虫:爬取豆瓣电影图片
第一个nodejs爬虫:爬取豆瓣电影图片存入本地: 首先在命令行下 npm install request cheerio express -save; 代码: var http = require( ...
- Python开发爬虫之静态网页抓取篇:爬取“豆瓣电影 Top 250”电影数据
所谓静态页面是指纯粹的HTML格式的页面,这样的页面在浏览器中展示的内容都在HTML源码中. 目标:爬取豆瓣电影TOP250的所有电影名称,网址为:https://movie.douban.com/t ...
- 一起学爬虫——通过爬取豆瓣电影top250学习requests库的使用
学习一门技术最快的方式是做项目,在做项目的过程中对相关的技术查漏补缺. 本文通过爬取豆瓣top250电影学习python requests的使用. 1.准备工作 在pycharm中安装request库 ...
- Python爬取豆瓣电影top
Python爬取豆瓣电影top250 下面以四种方法去解析数据,前面三种以插件库来解析,第四种以正则表达式去解析. xpath pyquery beaufifulsoup re 爬取信息:名称 评分 ...
- go爬虫之爬取豆瓣电影
go爬取豆瓣电影 好久没使用go语言做个项目了,上午闲来无事花了点时间使用golang来爬取豆瓣top电影,这里我没有用colly框架而是自己设计简单流程.mark一下 思路 定义两个channel, ...
- 零基础爬虫----python爬取豆瓣电影top250的信息(转)
今天利用xpath写了一个小爬虫,比较适合一些爬虫新手来学习.话不多说,开始今天的正题,我会利用一个案例来介绍下xpath如何对网页进行解析的,以及如何对信息进行提取的. python环境:pytho ...
- 用python爬取豆瓣电影Top 250
首先,打开豆瓣电影Top 250,然后进行网页分析.找到它的Host和User-agent,并保存下来. 然后,我们通过翻页,查看各页面的url,发现规律: 第一页:https://movie.dou ...
随机推荐
- Java(8)详解Random使用
作者:季沐测试笔记 原文地址:https://www.cnblogs.com/testero/p/15201556.html 博客主页:https://www.cnblogs.com/testero ...
- Coursera Deep Learning笔记 改善深层神经网络:优化算法
笔记:Andrew Ng's Deeping Learning视频 摘抄:https://xienaoban.github.io/posts/58457.html 本章介绍了优化算法,让神经网络运行的 ...
- mysql all_ip_test局域网IP测试工具,有需要的改一改.
1 import threading 2 import subprocess 3 import pymysql 4 # threading.Lock() 5 6 7 class Link(object ...
- 如何配置log4Net
之前曾经用过几次,但是每次都是用完就忘了,下次再用的时候要baidu半天,这次弄通之后直接记下来. 步骤如下. 1. 安装log4Net,直接用NuGet, Install-Package log4N ...
- 第三次Alpha Scrum Meeting
本次会议为Alpha阶段第三次Scrum Meeting会议 会议概要 会议时间:2021年4月26日 会议地点:线上会议 会议时长:20min 会议内容简介:本次会议主要由每个人展示自己目前完成的工 ...
- mysql分表之后怎么平滑上线?
分表的目的 项目开发中,我们的数据库数据越来越大,随之而来的是单个表中数据太多.以至于查询数据变慢,而且由于表的锁机制导致应用操作也受到严重影响,出现了数据库性能瓶颈. 当出现这种情况时,我们可以考虑 ...
- 通过Envoy实现.NET架构的网关
什么是Gateway 在微服务体系结构中,如果每个微服务通常都会公开一组精细终结点,这种情况可能会有以下问题 如果没有 API 网关模式,客户端应用将与内部微服务相耦合. 在客户端应用中,单个页面/屏 ...
- 按照工业标准1英寸=25.4mm,而在电子元件成像领域Sensor尺寸1英寸=16mm。
按照工业标准1英寸=25.4mm,而在电子元件成像领域Sensor尺寸1英寸=16mm. 我们平常所说的CCD/CMOS的尺寸,实际上是指Sensor对角线的长度,这一点跟我们平常所说的屏幕尺寸是一样 ...
- C语言基础资料,可以看看哦
C语言程序的结构认识 用一个简单的c程序例子,介绍c语言的基本构成.格式.以及良好的书写风格,使小伙伴对c语言有个初步认识. 例1:计算两个整数之和的c程序: #include main() { in ...
- hdu 3032 Nim or not Nim? (SG,然后找规律)
题意: n堆石头,每堆石头个数:s[1]...s[n]. 每人每次可以选择在一堆中取若干个(不能不取),或者把一堆石头分成两堆(两堆要都有石头). 无法操作者负. 数据范围: (1 ≤ N ≤ 10^ ...