Coursera Deep Learning笔记 序列模型(三)Sequence models & Attention mechanism(序列模型和注意力机制)
1. 基础模型(Basic Model)
Sequence to sequence模型(Seq2Seq)
从机器翻译到语音识别方面都有着广泛的应用。
举例:

该机器翻译问题,可以使用“编码网络(encoder network)”+“解码网络(decoder network)”两个RNN模型组合的形式来解决。
encoder network将输入语句编码为一个特征向量,传递给decoder network,完成翻译。具体模型结构如下图所示:
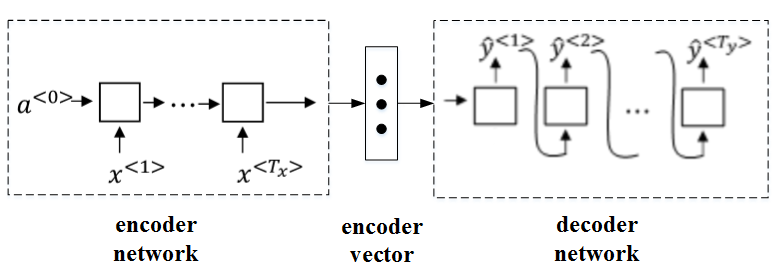
其中,encoder vector代表了输入语句的编码特征。encoder network和decoder network都是RNN模型,可使用GRU或LSTM单元。
这种“编码网络(encoder network)”+“解码网络(decoder network)”的模型,在实际的机器翻译应用中有着不错的效果。
这种模型也可以应用到图像捕捉领域。图像捕捉,即捕捉图像中主体动作和行为,描述图像内容。
- 例如下面这个例子,根据图像,捕捉图像内容。
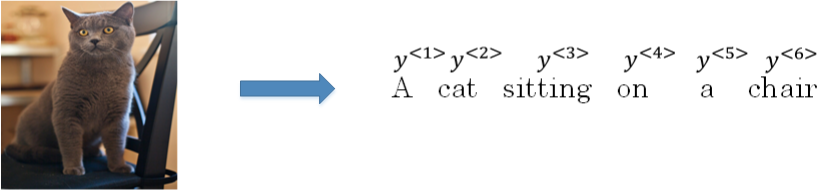
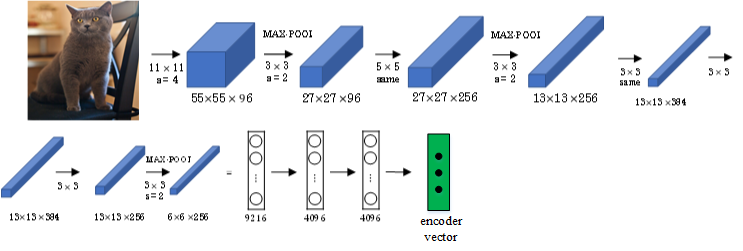
首先,可以将图片输入到CNN,例如使用预训练好的AlexNet,删去最后的softmax层,保留至最后的全连接层。
则该全连接层就构成了一个图片的特征向量(编码向量),表征了图片特征信息。
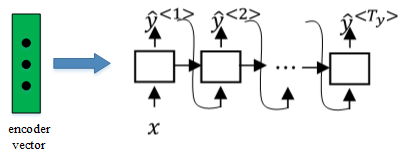
- 然后,将encoder vector输入至RNN,即decoder network中,进行解码翻译。
2. 选择最可能的句子(Picking the most likely sentence)
Sequence to sequence machine translation模型与language模型的区别。二者模型结构如下所示:
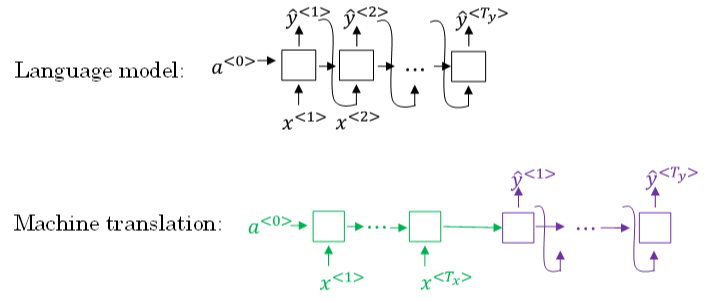
Language model是自动生成一条完整语句,语句是随机的。
machine translation model是根据输入语句,进行翻译,生成另外一条完整语句。
上图中,绿色部分表示encoder network,紫色部分表示decoder network。
decoder network 与 language model是相似的
encoder network可以看成是language model的 \(a^{<0>}\),是模型的一个条件
在输入语句的条件下,生成正确的翻译语句。
因此,machine translation可以看成是有条件的语言模型(conditional language model)
machine translation的目标是 根据输入语句,作为条件,找到最佳翻译语句,使其概率最大:
\]
- 列举几个模型可能得到的翻译:

显然,第一条翻译“Jane is visiting Africa in September.”最为准确。
- 即我们的优化目标:要让这条翻译对应的 \(P(y^{<1>},\cdots,y^{<T_y>}|x)\) 最大化.
实现优化目标的方法之一:使用贪婪搜索(greedy search)(不是最优)
Greedy search根据条件,每次只寻找一个最佳单词作为翻译输出,力求把每个单词都翻译准确。
- 例如,首先根据输入语句,找到第一个翻译的单词“Jane”,然后再找第二个单词“is”,再继续找第三个单词“visiting”,以此类推。
Greedy search缺点:
首先,因为greedy search每次只搜索一个单词,没有考虑该单词前后关系,概率选择上有可能会出错。
例如,上面翻译语句中,第三个单词“going”比“visiting”更常见,模型很可能会错误地选择了“going”,而错失最佳翻译语句。
greedy search运算成本巨大,降低运算速度。
3. 定向搜索(Beam Search)
Greedy search每次是找出预测概率最大的单词
beam search:每次找出预测概率最大的B个单词
- 其中,参数B:表示取概率最大的单词个数,可调。本例中,令B=3
beam search的搜索原理:
首先,先从词汇表中找出翻译的第一个单词概率最大的B个预测单词
根据上例,预测得到的第一个单词为:in,jane,september。

概率表示:\(P(\hat y^{<1>} | x)\)
然后,再分别以in,jane,september为条件,计算每个词汇表单词作为预测第二个单词的概率,从中选择概率最大的3个作为第二个单词的预测值
预测得到的第二个单词:in september,jane is,jane visits。(注意这里, in的第二个是september,则去掉了September作为英语翻译结果的第一个单词的选择)
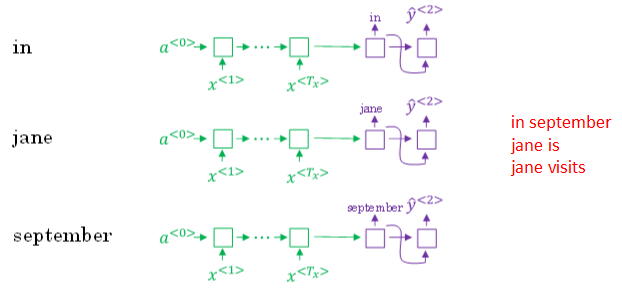
概率表示为:\(P(\hat y^{<2>}|x,\hat y^{<1>})\)
此时,得到的前两个单词的3种情况的概率:\(P(\hat y^{<1>},\hat y^{<2>}|x)=P(\hat y^{<1>} | x)\cdot P(\hat y^{<2>}|x,\hat y^{<1>})\)
接着,分别以in september,jane is,jane visits为条件,计算每个词汇表单词作为预测第三个单词的概率。从中选择概率最大的3个作为第三个单词的预测值
预测得到:in september jane,jane is visiting,jane visits africa。

概率表示:\(P(\hat y^{<3>}|x,\hat y^{<1>},\hat y^{<2>})\)
此时,得到的前三个单词的3种情况的概率:\(P(\hat y^{<1>},\hat y^{<2>},\hat y^{<3>}|x)=P(\hat y^{<1>} | x)\cdot P(\hat y^{<2>}|x,\hat y^{<1>})\cdot P(\hat y^{<3>}|x,\hat y^{<1>},\hat y^{<2>})\)
以此类推,每次都取概率最大的三种预测。最后,选择概率最大的那一组作为最终的翻译语句
Jane is visiting Africa in September.
注意,如果参数(Beam width)B=1,则就等同于greedy search。实际应用中,可以根据不同的需要设置B为不同的值。
一般B越大,机器翻译越准确,但同时也会增加计算复杂度。
1->10->100->1000->3000....
4. 改进定向搜索(Refinements to Beam Search)
Beam search中,最终机器翻译的概率是乘积的形式:
\]
问题1:多个概率相乘可能会使乘积结果很小,造成数值下溢
- 对上述乘积形式取对数log运算:
\]
- 因为取对数运算,将乘积转化为求和形式,避免了数值下溢,使得数据更加稳定有效。
问题2:机器翻译的单词越多,乘积形式或求和形式得到的概率就越小,这样会造成模型倾向于选择单词数更少的翻译语句,使机器翻译受单词数目的影响
- Length normalization(长度归一化),消除语句长度影响:
\]
实际应用中,通常会引入归一化因子 \(\alpha\):
若\(\alpha=1\),则完全进行长度归一化;
若\(\alpha=0\),则不进行长度归一化;
一般令\(\alpha=0.7\),效果不错。
\]
总结:如何运行beam search
当你运行beam search时,会看到很多长度 \(T_y=1, 2, 3, ...,30\),因为B=3,所有这些可能的句子长度(1,2,3,...,30)
然后,针对这些所有可能的输出句子,用 公式(3) 给它们打分,取概率最大的几个句子,然后对这些beam search得到的句子,计算这个目标函数
最后从经过评估的这些句子中,挑选出在归一化的log概率目标函数上得分最高的一个。
上述也叫,归一化的对数似然目标函数
与BFS (Breadth First Search) 、DFS (Depth First Search)算法不同,beam search运算速度更快,但并不保证一定能找到正确的翻译语句。
5. 定向搜索的误差分析(Error analysis in beam search)
Beam search是一种近似搜索算法。实际应用中,如果机器翻译效果不好,需要通过错误分析,判断是RNN模型问题还是beam search算法问题。
首先,为待翻译语句建立人工翻译,记为 \(y^{*}\)
在RNN模型上使用beam search算法,得到机器翻译,记为 \(\hat y\)
显然,人工翻译 \(y^{*}\) 更准确
Input: Jane visite l’Afrique en septembre.
Human: Jane visits Africa in September. \(y^{*}\)
Algorithm: Jane visited Africa last September. \(\hat y\)
整个模型包含两部分:RNN 和 beam search算法。
将输入语句输入到RNN模型中,分别计算输出是 \(y^{*}\) 的概率 \(P(y^*|x)\) 和 \(\hat y\) 的概率 \(P(\hat y|x)\)
接下来比较 \(P(y^*|x)\) 和 \(P(\hat y|x)\) 的大小
\(P(y^*|x)\) > \(P(\hat y|x)\):Beam search有误
\(P(y^*|x)\) < \(P(\hat y|x)\):RNN模型有误
如果beam search算法表现不佳,可以调试参数B;
若RNN模型不好,则可以增加网络层数,使用正则化,增加训练样本数目等方法来优化。


6. Bleu Score
Bilingual evaluation understudy 双语评价替补;Bleu Score:单一实数评估指标
使用Bleu score,对机器翻译进行打分。
首先,对原语句 建立人工翻译参考,一般有多个人工翻译(利用验证集和测试集)。例:
Bleu Score:机器翻译越接近参考的人工翻译,其得分越高。
- 原理:看 机器翻译的各个单词 是否 出现在参考翻译中。
French: Le chat est sur le tapis.
Reference 1: The cat is on the mat.
Reference 2: There is a cat on the mat.
上述两个人工翻译都是正确的,作为参考。
- 相应的机器翻译如下所示:
French: Le chat est sur le tapis.
Reference 1: The cat is on the mat.
Reference 2: There is a cat on the mat.
MT output: the the the the the the the.
- 如上所示,机器翻译为 “the the the the the the the.”,效果很差。
Modified precision:看机器翻译单词 出现在 参考翻译单个语句 中的次数,取最大次数。上述例子对应的准确率为 \(\frac{2}{7}\)
分母:机器翻译单词数目
分子:相应单词 出现在 参考翻译中的次数(分子为2是因为“the”在参考1中出现了两次)。该评价方法较为准确。
Bleu score on bigrams
- 同时对两个连续单词进行打分。例:
French: Le chat est sur le tapis.
Reference 1: The cat is on the mat.
Reference 2: There is a cat on the mat.
MT output: The cat the cat on the mat.
- 可能有的bigrams(二元组) 及 其出现在 MIT output 中的次数count为:
the cat: 2
cat the: 1
cat on: 1
on the: 1
the mat: 1
- 统计上述bigrams出现在 参考翻译单个语句 中的次数(取最大次数)\(count_{clip}\)为:
the cat: 1
cat the: 0
cat on: 1
on the: 1
the mat: 1
- 相应的bigrams precision为:
\]
- 如果只看单个单词,相应的(一元组)unigrams precision为:
\]
- 如果是n个连续单词,相应的(n元组)n-grams precision为:
\]
- 总结,可以同时计算 \(p_1,\cdots,p_n\),再对其求平均:
\]
通常,对上式进行指数处理,并引入 参数因子Brevity Penalty,记为BP。
- BP是为了“惩罚”机器翻译语句过短,而造成的得分“虚高”的情况。
\]
- BP值:由 机器翻译长度 和 参考翻译长度 共同决定。
\]
7. Attention Model Intuition

如果原语句很长,要对整个语句 输入RNN的 编码网络和解码网络进行翻译,则效果不佳。相应的bleu score会 随着单词数目增加 而 逐渐降低。
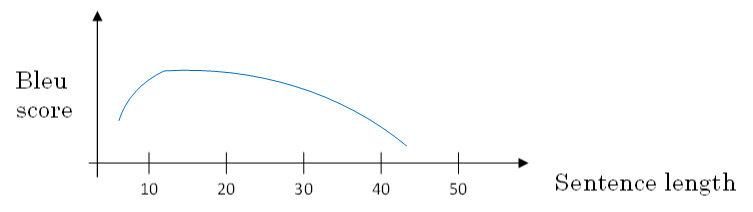
对待长语句,正确的翻译方法是将长语句分段,每次只对长语句的一部分进行翻译。
也就是说,每次翻译只注重一部分区域,这种方法使得bleu score不太受语句长度的影响。

根据这种“局部聚焦”的思想,建立相应的注意力模型(attention model)
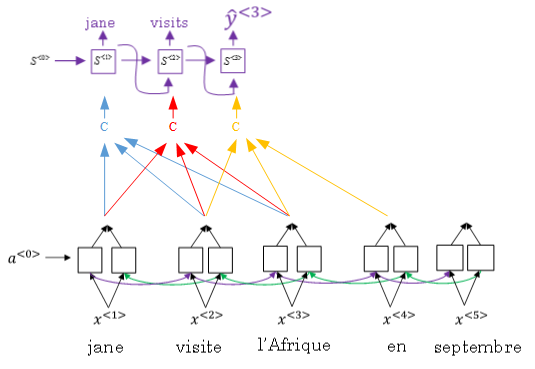
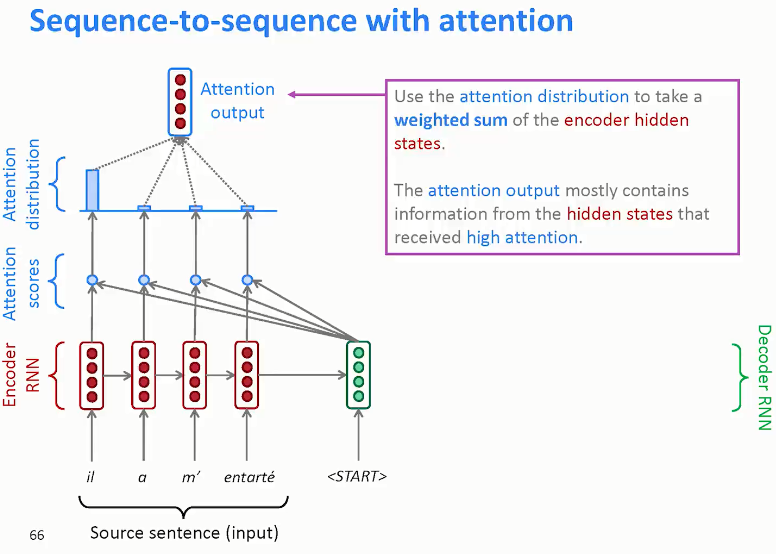
如上图所示,attention model仍由类似的编码网络(下)和解码网络(上)构成。
其中,\(S^{<t>}\)由原语句附近单元共同决定,原则上说,离得越近,注意力权重(attention weights)越大,相当于 在你当前的注意力区域有个滑动窗。
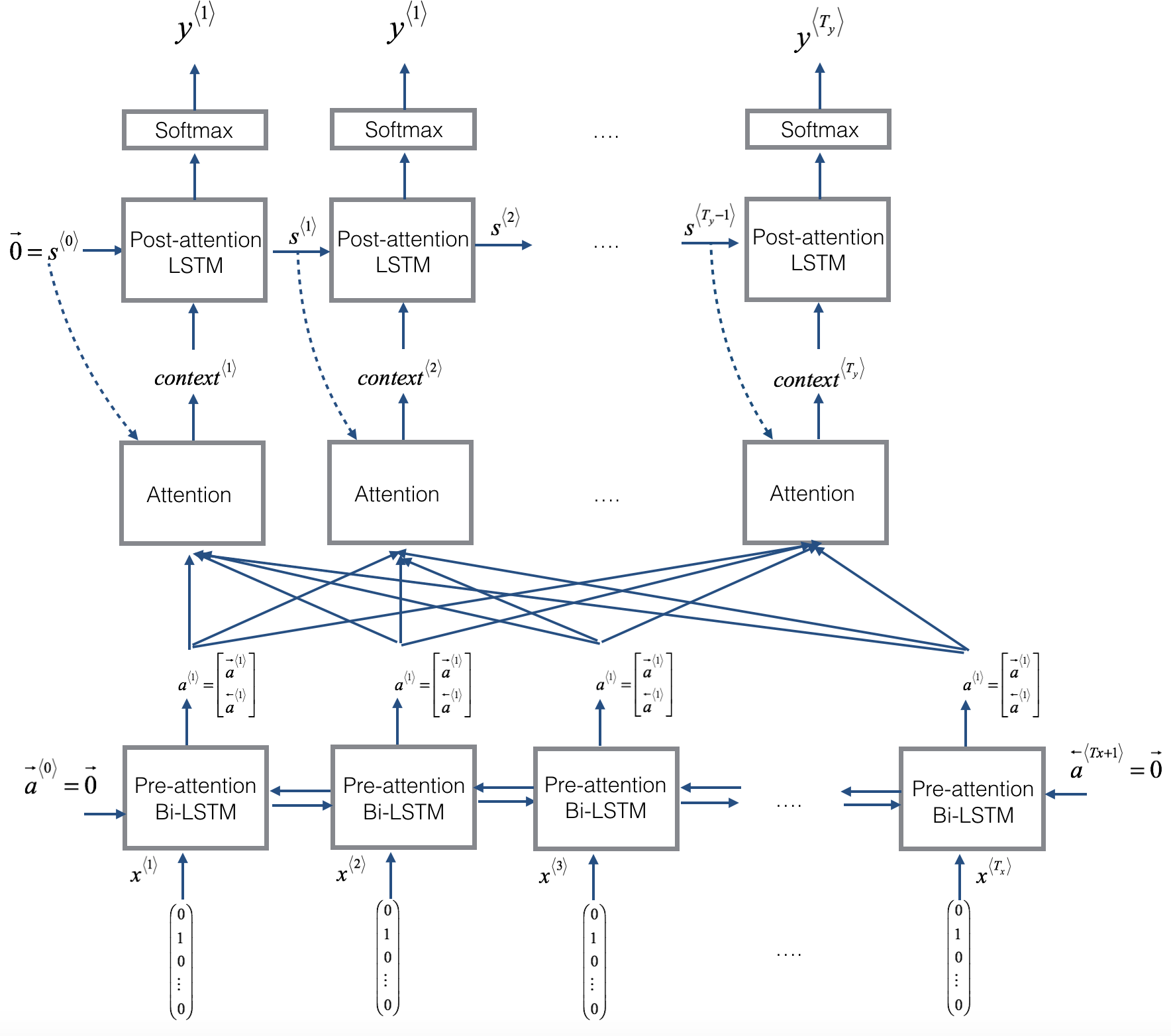
8. Attention Models



 |
 |
**Figure 1**: Neural machine translation with attention
Attention model中选择 双向RNN,可以使用GRU单元 或者 LSTM(更常用)。
由于是双向RNN,每个\(a^{<t^{\prime}>}\)表示:
\]
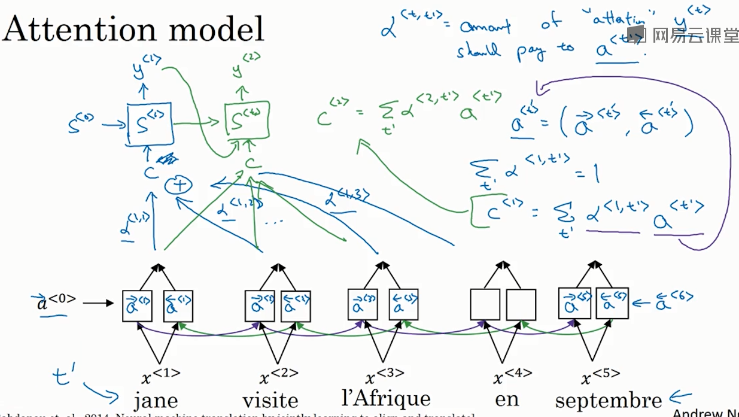
RNN编码生成特征,注意力权重 用 \(\alpha^{<t, t^{\prime}>}\) 表示,\(C^{<t>}\) 是各个RNN神经元经过 注意力权重 得到的参数值。
例如, \(\alpha^{<1, t^{\prime}>}\) 表示机器翻译的 第一个单词 “jane" 对应的 第 t' 个RNN神经元
\(C^{<1>}\) 表示机器翻译 第一个单词 "jane" 对应的 解码网络输入参数。满足:
\ \\
C^{<1>}=\sum_{t'}\alpha^{<1,t'>}\cdot a^{<t'>}
\]
\(\alpha^{<t, t^{\prime}>}\):表示输出 \(\hat{y}^{<t>}\) 对 RNN单元 \(a^{<t'>}\) 的 注意力权重因子
为了让 \(\alpha^{<t, t^{\prime}>}\) 之和为1,利用softamx里想,引入参数 \(e^{\left\langle t, t^{\prime}\right\rangle},\) 使得:
\]
这样,只要求出 \(e^{\left\langle t, t^{\prime}\right\rangle},\) 就能得到 \(\alpha^{\left\langle t, t^{\prime}\right\rangle}\)
如何求出 \(e^{<t, t^{\prime}>}\):
- 建立一个简单的神经网络,如下图所示。输入是 \(S^{<t-1>}\) 和 \(a^{<t^{\prime}>}\),输出是 \(e^{<t, t^{\prime}>}\)

- 然后,利用梯度下降算法迭代优化,计算得到 \(e^{\left\langle t, t^{\prime}\right\rangle}\) 和 \(\alpha^{<t, t^{\prime}>}\)
Attention model缺点:
其计算量较大。\(O(n^3)\)
若输入句子长度为 \(T_{x},\) 输出句子长度为 \(T_{y}\), 则计算时间约为 \(T_{x} * T_{y}\) 是,其性能提升很多,计算量大一些也是可以接受的。
Attention model在图像捕捉方面也有应用。
Attention model能有效处理很多机器翻译问题,例如下面的时间格式归一化:

下图将注意力权重 \(\alpha^{<t, t^{\prime}>}\) 可视化:
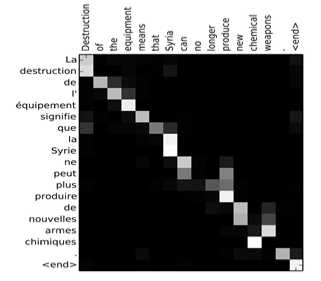
上图中,颜色越白表示注意力权重越大,颜色越深表示权重越小。
可见,输出语句单词 与 其输入语句单词 对应位置的注意力权重较大,即对角线附近。
9. Speech recognition
深度学习中,语音识别的输入是声音,量化成时间序列。可以把信号转化为频域信号,即声谱图(spectrogram),再进入RNN模型进行语音识别。

在end-to-end深度神经网络模型中,可以得到很好的识别效果。通常训练样本很大,需要上千上万个小时的语音素材。
语音识别的注意力模型(attention model)如下图所示:
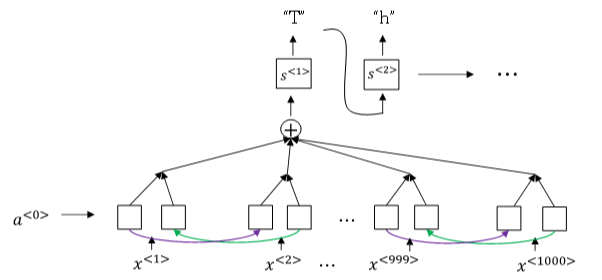
一般来说,语音识别的输入时间序列都比较长,例如是10s语音信号,采样率为100HZ,则语音长度为1000。
而翻译的语句通常很短,例如 "the quick brown fox" ,包含19个字符。这时候,\(T_{x}\) 与 \(T_{y}\) 差别很大。为了让 \(T_{x}=T_{y}\), 可以把输出相应字符重复并加入空白 ( blank ),形如:
\]
其中,下划线 "_" 表示空白, "\(\sqcup\)“ 表示两个单词之间的空字符。
该写法的一个基本准则:是没有被空白符 "_“ 分割 的 重复字符将被折叠到一起,即表示一个字符。
这样,加入了重复字符和空白符、空字符,可以让输出长度也达到1000,即 \(T_{x}=T_{y}\) 。这种模型被称为 CTC ( Connectionist temporal classification )

10. Trigger Word Detection
触发字检测(Trigger Word Detection)在很多产品中都有应用,操作方法就是说出触发字通过语音来启动相应的设备。
- 例如,百度DuerOS的触发字是”小度你好“,Apple Siri的触发字是”Hey Siri“
触发字检测系统可以使用RNN模型来建立。
如下图所示,输入语音中包含一些触发字,其余都是非触发字。
RNN检测到触发字后输出1,非触发字输出0。这样训练的RNN模型就能实现触发字检测。
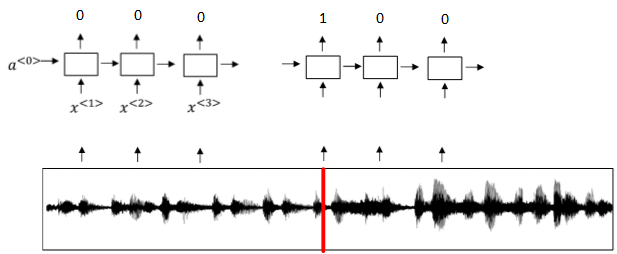
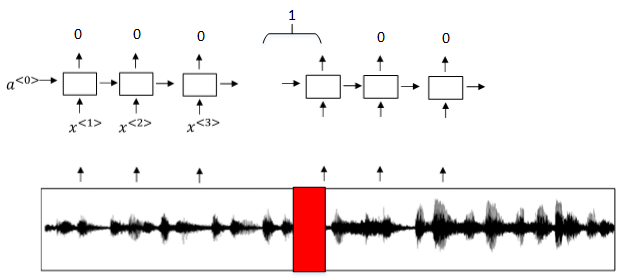
模型缺点:
- 通常训练样本语音中的触发字较非触发字数目少得多,即正负样本分布不均。
解决办法:
- 在出现一个触发字时,将其附近的RNN都输出1。这样就简单粗暴地增加了正样本。
Coursera Deep Learning笔记 序列模型(三)Sequence models & Attention mechanism(序列模型和注意力机制)的更多相关文章
- 吴恩达《深度学习》-第五门课 序列模型(Sequence Models)-第三周 序列模型和注意力机制(Sequence models & Attention mechanism)-课程笔记
第三周 序列模型和注意力机制(Sequence models & Attention mechanism) 3.1 序列结构的各种序列(Various sequence to sequence ...
- [C5W3] Sequence Models - Sequence models & Attention mechanism
第三周 序列模型和注意力机制(Sequence models & Attention mechanism) 基础模型(Basic Models) 在这一周,你将会学习 seq2seq(sequ ...
- Coursera Deep Learning笔记 序列模型(一)循环序列模型[RNN GRU LSTM]
参考1 参考2 参考3 1. 为什么选择序列模型 序列模型能够应用在许多领域,例如: 语音识别 音乐发生器 情感分类 DNA序列分析 机器翻译 视频动作识别 命名实体识别 这些序列模型都可以称作使用标 ...
- Coursera Deep Learning笔记 逻辑回归典型的训练过程
Deep Learning 用逻辑回归训练图片的典型步骤. 笔记摘自:https://xienaoban.github.io/posts/59595.html 1. 处理数据 1.1 向量化(Vect ...
- Coursera Deep Learning笔记 结构化机器学习项目 (下)
参考:https://blog.csdn.net/red_stone1/article/details/78600255https://blog.csdn.net/red_stone1/article ...
- Coursera, Deep Learning 5, Sequence Models, week3, Sequence models & Attention mechanism
Sequence to Sequence models basic sequence-to-sequence model: basic image-to-sequence or called imag ...
- deeplearning.ai 序列模型 Week 3 Sequence models & Attention mechanism
1. 基础模型 A. Sequence to sequence model:机器翻译.语音识别.(1. Sutskever et. al., 2014. Sequence to sequence le ...
- 课程五(Sequence Models),第三周(Sequence models & Attention mechanism) —— 2.Programming assignments:Trigger word detection
Expected OutputTrigger Word Detection Welcome to the final programming assignment of this specializa ...
- 课程五(Sequence Models),第三周(Sequence models & Attention mechanism) —— 1.Programming assignments:Neural Machine Translation with Attention
Neural Machine Translation Welcome to your first programming assignment for this week! You will buil ...
随机推荐
- Python网络爬虫——京东商城商品列表
Python_网络爬虫--京东商城商品列表 最近在拓展自己知识面,想学习一下其他的编程语言,处于多方的考虑最终选择了Python,Python从发布之初就以庞大的用户集群占据了编程的一席之地,pyth ...
- Python - 执行cmd命令
python操作cmd 我们通常可以使用os模块的命令进行执行cmd 方法一:os.system os.system(执行的命令) # 源码 def system(*args, **kwargs): ...
- IKE~多预共享密钥问题~解决方案
原文链接:Configuring more than one Main-Mode Pre-Shared Key (PSK) *dialup* IPSec phase1 可能需要梯子来翻过高墙.文章内容 ...
- tornado2.2安装教程
最近要用到vxworks 系统,所以避免不了要安装tornado 软件,进行相关的开发. 自己在安装过程中遇到了点点问题,这里记录下来,免得以后再次安装时遇到同样的问题. 1. 首先提供一个tor ...
- WEB漏洞——PHP反序列化
序列化 首先说说什么是序列化 序列化给我们传递对象提供了一种简单的方法.serialize()将一个对象转换成一个字符串,并且在转换的过程中可以保存当前变量的值 而反序列化unserialize()将 ...
- 【第十篇】- Git 远程仓库(Github)之Spring Cloud直播商城 b2b2c电子商务技术总结
Git 远程仓库(Github) Git 并不像 SVN 那样有个中心服务器. 目前我们使用到的 Git 命令都是在本地执行,如果你想通过 Git 分享你的代码或者与其他开发人员合作. 你就需要将数据 ...
- 【第十四篇】- Maven 自动化构建之Spring Cloud直播商城 b2b2c电子商务技术总结
Maven 自动化构建 自动化构建定义了这样一种场景: 在一个项目成功构建完成后,其相关的依赖工程即开始构建,这样可以保证其依赖项目的稳定. 比如一个团队正在开发一个项目 bus-core-api, ...
- 苹果ASA广告投放归因的接入
前段时间,苹果终于在大陆区开放了应用商店的竞价广告.毫无疑问又开启了苹果应用导量的新玩法,各大厂商都紧跟脚步吃螃蟹.本篇讲解苹果广告中的归因部分. 苹果广告其实在海外已运行多年,而因为IDFA的政策变 ...
- C++课后习题
一.设计一个类people,有保护数据成员:age(年龄,整型),name(姓名,string),行为成员:两个构造函数(一个默认,另一个带参数):析构函数:void setValue(int m, ...
- python 小鸡飞行小游戏
python 小鸡飞行小游戏 用空格键控制小鸡飞行 代码 import pygame.freetype import sys import random pygame.init() screen = ...