大数据学习(17)—— HBase表设计
为啥要把表设计拿出来独立成章?因为我觉得像我这样搞了很多年Java后端开发的技术人员,在学习HBase的时候,会受到关系型数据库3NF、BCNF的影响。事实上,数据库范式在HBase里完全没用,必须转变思想。因此把这一点单独写出来,供类似情况的技术人员参考。
HBase逻辑视图
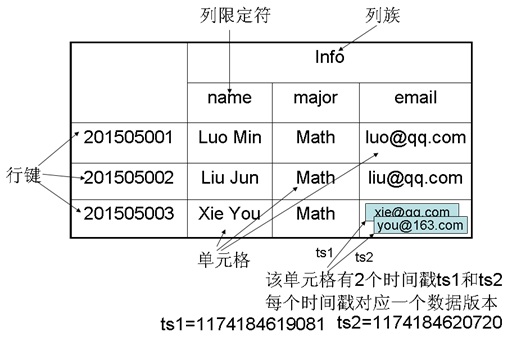
这个图看起来像是Excel表格,不同的是,它的一个单元格可以有多个版本的数据,这是HBase的多版本特性,默认版本数是1。实际存储格式是每个单元格一行记录,如下图。
hbase(main):003:0> scan 'test'
ROW COLUMN+CELL
rowkey1 column=cf:level, timestamp=1608108298860, value=P9
rowkey1 column=cf:name, timestamp=1607677762394, value=guanyu
rowkey2 column=cf:salary, timestamp=1607328820620, value=200w
rowkey3 column=cf:corp, timestamp=1607330730061, value=Alibaba
rowkey4 column=cf:name, timestamp=1607331563986, value=XiaoYaoZi
4 row(s)
Took 1.7952 seconds
我们再来看看存放在HDFS里的hfile文件内容。
[hadoop@server01 hadoop]$ hbase hfile -p -f /hbase/data/default/test/bc89689612a0269a2216349bd23133ec/cf/c66c7553a5d6488a9e1e57ca2b0a5577
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/usr/hadoop-3.3.0/share/hadoop/common/lib/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/usr/hbase-2.2.6/lib/client-facing-thirdparty/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
2020-12-16 18:30:46,116 INFO [main] metrics.MetricRegistries: Loaded MetricRegistries class org.apache.hadoop.hbase.metrics.impl.MetricRegistriesImpl
K: rowkey1/cf:level/1608108298860/Put/vlen=2/seqid=27 V: P9
K: rowkey1/cf:name/1607677762394/Put/vlen=6/seqid=14 V: guanyu
K: rowkey2/cf:salary/1607328820620/Put/vlen=4/seqid=0 V: 200w
K: rowkey3/cf:corp/1607330730061/Put/vlen=7/seqid=0 V: Alibaba
K: rowkey4/cf:name/1607331563986/Put/vlen=9/seqid=0 V: XiaoYaoZi
Scanned kv count -> 5
这个文件可以很明显地看出,它是一个键值存储系统,键包含rowkey、列族、列名(列标识符)、时间戳、数据类型(Put、Delete)、字符数组长度、seqid。值就是单元格存储的值。
这个键占用了大量的空间,而且不同数据它们的列族列名完全是一样的,太浪费空间了,这就需要用到HBase的压缩,压缩方式请自行查看官网。
seqid是个什么东西?百度了一下,可能是一个时间序列的标识,提示老的HLog是否可以删除。
HBase表设计原则
- 行键根据需求来设计,尽量短,尽量只调用一次API就可以完成需求。
- HBase原生语法不支持表join操作,适当使用冗余来简化查询操作。
- 列名(列标识符)可以存储数据,每一条记录的列名可以完全不同,但是尽量短。
表设计实战
以微博关注为例来做一个小小的表设计,可能与微博实际不符,仅用于说明设计方法。
关注关系如下:
景天关注重楼、龙葵、雪见
飞蓬关注景天、重楼
重楼关注飞蓬、紫萱
龙葵关注景天
雪见关注景天
紫萱关注雪见
这是一个多对多的关系,如果是关系型数据库,至少要两张表来存放。一张表存放人物信息,一张表存放人物关注关系。
时刻要想到,HBase没有join操作,只能用一张表来存放关注和被关注的信息,这肯定会存在数据冗余。不要怕,HBase可以支持十亿级别的列和百万级别的行,冗余不是问题。
我们可以这么设计
| 行键 | 列族cf1(关注谁) | 列族cf2(被谁关注) |
| 001_景天 | cf1:003=重楼,cf1:004=龙葵,cf1:005=雪见 | cf2:002=飞蓬,cf2:004=龙葵,cf2:005=雪见 |
| 002_飞蓬 | cf1:001=景天,cf1:003=重楼 | cf2:003=重楼 |
| 003_重楼 | cf1:002=飞蓬,cf1:006=紫萱 | cf2:001=景天,cf2:002=飞蓬 |
| 004_龙葵 | cf1:001=景天 | cf2:001=景天 |
| 005_雪见 | cf1:001=景天 | cf2:001=景天,cf2:006=紫萱 |
| 006_紫萱 | cf1:005=雪见 | cf2:003=重楼 |
是不是惊呆了,这都什么玩意。这种设计可以只用一次API调用就查出每个人关注了谁,每个人被谁关注了,按照需求来合理设计。
大数据学习(17)—— HBase表设计的更多相关文章
- HBase学习——3.HBase表设计
1.建表高级属性 建表过程中常用的shell命令 1.1 BLOOMFILTER 默认是 NONE 是否使用布隆过虑及使用何种方式,布隆过滤可以每列族单独启用 使用HColumnDescriptor. ...
- 大数据学习笔记——HBase使用bulkload导入数据
HBase使用bulkload批量导入数据 HBase可使用put命令向一张已经建好了的表中插入数据,然而,当遇到数据量非常大的情况,一条一条的进行插入效率将会大大降低,因此本篇博客将会整理提高批量导 ...
- 大数据学习笔记——Hbase高可用+完全分布式完整部署教程
Hbase高可用+完全分布式完整部署教程 本篇博客承接上一篇sqoop的部署教程,将会详细介绍完全分布式并且是高可用模式下的Hbase的部署流程,废话不多说,我们直接开始! 1. 安装准备 部署Hba ...
- 大数据学习(16)—— HBase环境搭建和基本操作
部署规划 HBase全称叫Hadoop Database,它的数据存储在HDFS上.我们的实验环境依然基于上个主题Hive的配置,参考大数据学习(11)-- Hive元数据服务模式搭建. 在此基础上, ...
- 大数据学习(13)—— HBase入门
从这一篇起,开始介绍HBase相关知识.还是一样,大数据的学习,获取官网知识很重要.官网看这里Apache HBase HBase简介 Apache HBase is the Hadoop datab ...
- 大数据学习系列之五 ----- Hive整合HBase图文详解
引言 在上一篇 大数据学习系列之四 ----- Hadoop+Hive环境搭建图文详解(单机) 和之前的大数据学习系列之二 ----- HBase环境搭建(单机) 中成功搭建了Hive和HBase的环 ...
- 大数据学习系列之九---- Hive整合Spark和HBase以及相关测试
前言 在之前的大数据学习系列之七 ----- Hadoop+Spark+Zookeeper+HBase+Hive集群搭建 中介绍了集群的环境搭建,但是在使用hive进行数据查询的时候会非常的慢,因为h ...
- 大数据学习系列之—HBASE
hadoop生态系统 zookeeper负责协调 hbase必须依赖zookeeper flume 日志工具 sqoop 负责 hdfs dbms 数据转换 数据到关系型数据库转换 大数据学习群119 ...
- 大数据学习day26----hive01----1hive的简介 2 hive的安装(hive的两种连接方式,后台启动,标准输出,错误输出)3. 数据库的基本操作 4. 建表(内部表和外部表的创建以及应用场景,数据导入,学生、分数sql练习)5.分区表 6加载数据的方式
1. hive的简介(具体见文档) Hive是分析处理结构化数据的工具 本质:将hive sql转化成MapReduce程序或者spark程序 Hive处理的数据一般存储在HDFS上,其分析数据底 ...
随机推荐
- moment常用方法
1.subtract方法,时间加减处理 console.log(moment().format("YYYY-MM-DD HH:mm:ss")); //当前时间 console.lo ...
- 20201123 实验二《Python程序设计》实验报告
20201123 2020-2021-2 <Python程序设计>实验报告课程:<Python程序设计>班级:2011姓名:晏鹏捷学号:20201123实验教师:王志强实验日期 ...
- 远程代码执行MS08-067漏洞复现失败过程
远程代码执行MS08-067漏洞复现失败过程 漏洞描述: 如果用户在受影响的系统上收到特制的 RPC 请求,则该漏洞可能允许远程执行代码. 在微软服务器系统上,攻击者可能未经身份验证即可利用此漏洞运行 ...
- SonarQube遇到的启动问题及解决方案
操作系统:centos 7 (x86)一.问题描述:使用root启动时,一直反馈 SonarQube is not running问题原因:不能够使用root用户进行启动解决方案:①创建一个其他用户( ...
- nginx日志分析及其统计PV、UV、IP
一.nginx日志结构 nginx中access.log 的日志结构: $remote_addr 客户端地址 211.28.65.253 $remote_user 客户端用户名称 -- $time_l ...
- Collections中的实用方法
总结一下java.util.Collections类内部的静态方法. checkedCollection(Collection<T> , Class<T> type) chec ...
- Spirng boot maven多模块
https://blog.csdn.net/Ser_Bad/article/details/78433340
- Formily教程 | formily是中后台复杂场景的表单解决方案
前言 formily 不是一个简单的前端轮子.Formily 是一个由阿里巴巴集团多 BU 共建的面向中后台复杂场景的表单解决方案,它也是一个表单框架.它的前身是供应链平台在 2019 年初对外开源的 ...
- 探索互斥锁 Mutex 实现原理
Mutex 互斥锁 概要描述 mutex 是 go 提供的同步原语.用于多个协程之间的同步协作.在大多数底层框架代码中都会用到这个锁. mutex 总过有三个状态 mutexLocked: 表示占有锁 ...
- npm run start失败&Node.js 查询指定端口运行情况及终止占用端口办法
缘由: node.js项目中运行npm run start命令脚本报错,No such file or directory 最开始以为是命令脚本找不到所谓的执行路径,但后面发现不是,是package. ...