论文笔记:(2019)LDGCNN : Linked Dynamic Graph CNN-Learning on PointCloud via Linking Hierarchical Features
LDGCNN : Linked Dynamic Graph CNN-Learning on PointCloud via Linking Hierarchical Features
论文地址:https://arxiv.org/abs/1904.10014
代码:https://github.com/KuangenZhang/ldgcnn
摘要
由于点云是一种常见的几何数据类型,可以帮助机器人牢固地理解环境,因此迫切需要在点云上学习。但是,点云是稀疏的,非结构化的和无序的,传统的卷积神经网络(CNN)或递归神经网络(RNN)无法准确识别。幸运的是,图卷积神经网络(图CNN)可以处理稀疏和无序数据。因此,我们提出一种链接动态图CNN(LDGCNN),以直接对点云进行分类和分割。我们删除了转换网络,从动态图链接了层次特征,冻结了特征提取器,并重新训练了分类器,以提高LDGCNN的性能。我们使用理论分析和可视化来解释我们的网络。通过实验,我们证明了所提出的LDGCNN在两个标准数据集:ModelNet40和ShapeNet上达到了最先进的性能。
索引词——深度学习,图卷积神经网络,点云,分类,分割
一、引言
三维(3D)感知可帮助机器人感知和理解环境,从而提高机器人的智能。深度相机、LiDAR扫描仪和雷达可以提供3D几何数据。这些传感器通常通过将脉冲信号(例如激光和红外光)投射到目标,并测量反射的脉冲或作用时间来测量目标与传感器之间的距离。因此,3D几何数据可以提供3D空间信息,并且受照明强度的影响较小,照明强度比RGB(红色,绿色和蓝色)图像更强健。例如,3D传感器可以在夜间感知环境。此外,可以融合来自不同视角的3D几何数据以提供完整的环境信息。因此,3D几何数据对于机器人在实际环境中执行任务至关重要。此外,在实际应用中急切需要3D理解,包括自动驾驶[1],自动室内导航[2]和机器人技术[3,4]。
点云通常表示3D空间(R3)中的一组3D点。点云中的每个点都有三个坐标:x,y和z。点云是3D几何数据的最常见表示形式。例如,深度相机、LiDAR扫描仪和雷达的原始数据通常是点云。此外,几何数据的其他3D表示形式,例如网格,体素和深度图像可以容易地转换为点云。 因此,认识点云很重要。
因此,我们考虑在本文中设计识别点云的方法。具体来说,我们专注于两个任务:点云分类和分割。如图1所示,点云分类将整个点云作为输入,并输出输入点云的类别。分割是将每个点分类为点云的特定部分。对于这两个任务,有两个经典的公共数据集:ModelNet40 [5]和ShapeNet [6]。第二节简要介绍了这两个数据集。
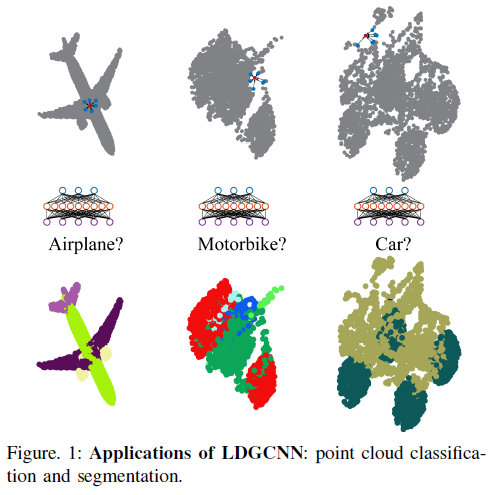
图1:LDGCNN的应用:点云分类和分割
传统上,研究人员倾向于设计手工制作的特征,例如形状上下文[7],点特征直方图[8],局部表面特征描述[9]和面片上下文[10]以识别点云。但是,这些手工制作的功能通常旨在解决特定问题,并且难以推广到新任务。近年来,深度学习方法在对象的分类和分割上取得了成功[11,12]。研究人员倾向于设计数据驱动的方法来学习特征并自动识别点云。
深度学习方法已经在处理2D图像方面取得了显着进展[13],但是准确地对点云进行分类和分割仍然是挑战。由于点云稀疏,无结构化,无序,典型的卷积神经网络(CNN)和递归神经网络(RNN)需要规则的图像格式或有序序列,因此不适合直接识别点云。为了识别点云,先前的研究人员提出了三种深度学习方法:基于视图的方法,体素方法和几何方法。我们将在下面详细讨论这些方法。
A.基于视图的方法
以前的研究人员试图将点云沿不同方向投影到2D图像,然后应用标准2D CNN提取特征。从不同图像中学习到的特征通过视图池化层聚合为全局特征,然后可以利用该全局特征对对象进行分类[5、14、15]。尽管基于视图的方法可以在分类任务中实现较高的准确性,但是将这种方法应用于分割点云即将每个点分类为特定类别并非易事。
B.基于体素的方法
识别点云的另一种方法是应用体素化将非结构化点云转换为结构化3D网格。 然后,可以利用3D CNN和体积CNN来对3D网格进行分类和分割[16,17]。但是,点云是稀疏,使用3D网格表示点云是浪费的。另外,考虑到体积数据的高存储和计算成本,3D网格的分辨率通常较低,这可能导致量化伪像。因此,利用体积方法来处理大规模点云是有问题的。
C.基于几何的方法
近年来,Qi等人引入了PointNet来直接对点云进行分类和分割[18],这开创了用于处理非结构化数据的几何方法[19]。点云具有几个特征:稀疏性,排列不变性和变换不变性。考虑到点云的稀疏性,PointNet的研究人员直接处理点,而不是将点云投影到图像或体积网格上。为了解决置换不变性问题,他们设计了一个多层感知器(MLP)来从每个点独立提取特征。由于用于不同点的MLP共享参数,因此可以从不同点提取相同类型的特征。此外,他们使用最大池化层提取全局特征以汇总来自所有点的信息。共享的MLP和最大池化层都是对称的,从而解决了置换不变性问题。此外,他们设计了一个转换网络来估计点云的仿射转换矩阵。然后他们使用估计的仿射转换矩阵来弥补点云,以解决变换不变性问题。
PointNet独具匠心,可以直接对点云进行分类和分割,但是它可以单独处理每个点,而无需提取点与其邻居之间的局部信息。相邻点之间的局部特征可能比每个点的坐标更健壮,因为点云可以旋转和移动。结果,PointNet的研究人员将他们的网络改进到PointNet ++ [20]。他们将PointNet递归地应用于嵌套分区,以提取局部特征并组合多尺度的学习特征。提取局部特征后,PointNet ++在几个常见的3D数据集上实现了点云分类和分割任务的最新结果。但是,PointNet ++仍然会单独处理局部点中的每个点,并且不会提取该点及其邻居之间的关系,例如距离和边缘向量。
最近,研究人员开始设计PointNet的变体,以从点对之间的关系中学习局部特征。k维树(KD-tree)用于将点云划分为细分。研究人员逐步在这些细分上执行乘法变换,并对点云进行分类。但是,如果点云的规模发生变化,则基于KDtree的这些分区可能会有所不同。 Wang等人设计了一个边缘卷积算子,从中心点(pc)提取特征,并从其邻域自身(pn - pc)提取边缘向量。此外,他们在每个边缘卷积层之前应用k最近邻(KNN)算法。因此,它们不仅在输入的欧几里得空间R3中搜索邻居,而且还在特征空间中聚集相似的特征。受益于提取动态特征,它们的动态图CNN(DGCNN)在点云识别任务上获得了最先进的结果[21]。最近,徐等人指出MLP在点云上不能很好地工作,他们基于泰勒多项式设计了一个新的卷积层SpiderCNN,以提取局部测地信息[22]。但是,对于与DGCNN相同的输入(1024点),SpiderCNN的分类精度略低于DGCNN的分类精度。因此,这种复杂的卷积内核似乎并不胜过简单而有效的MLP。李等人为了从点云中提取层次特征,随机对点云进行下采样,并将PointCNN应用于稀疏点云中新邻居之间的关系[23]。此外,他们从局部点集学习变换矩阵,以将点排列为潜在的规范顺序。它们由于下采样而减少了网络的前向时间,并达到了与DGCNN相似的精度。但是,下采样可能会影响配点云的精度,因为每个点都应归为一类。
到目前为止,当输入点云中只有1024个点时,DGCNN在modelNet40数据集上实现了最高的分类精度。尽管其他一些方法(例如自组织网络[24]和GeometricCNN(Geo-CNN)[25])可以进一步提高分类精度,但它们需要更密集的点云,该点云由10,000或5,000个点和法向矢量组成。由于ModelNet40和ShapeNet的数据集是从计算机辅助设计(CAD)模型生成的,因此很容易使用法向矢量获取更密集的点云。然而,在实际应用中情况却不同。 3D传感器(如LiDAR扫描仪)只能捕获稀疏点云。此外,在3D传感器的原始数据中没有法线向量。因此,DGCNN似乎更实用,但也存在一些问题。首先,DGCNN依赖于转换网络来抵消点云,但是此转换网络使网络的大小增加了一倍。此外,深度特征及其邻居可能太相似而无法提供有价值的边缘向量。此外,DGCNN中有许多可训练的参数,并且在训练整个网络时很难找到最佳参数。
在本文中,我们优化了DGCNN的网络架构,以提高性能并减少网络的模型大小。由于我们的网络链接了来自不同动态图的分层功能,因此我们将其称为链接动态图CNN(LDGCNN)。 我们应用K-NN和共享参数的MLP提取中心点及其邻居中的局部特征。然后,我们在不同层之间添加shortcuts,以链接层次特征以计算有用的边缘矢量。此外,LDGCNN中包含两部分:卷积层(特征提取器)和完全连接层(分类器)。训练完LDGCNN后,我们冻结特征提取器并重新训练分类器以提高网络性能。在实验中,我们在两个公共数据集上对LDGCNN进行评估:Model-Net40和ShapeNet用于分类和分割。实验结果表明,我们的LDGCNN在这两个数据集上均达到了最先进的性能。
这篇文章的 关键贡献 包括:
- 我们将来自不同动态图的层次特征链接起来,以计算出有用的边缘矢量,并避免梯度问题的消失。
- 我们从DGCNN中移除了变换网络,并证明了我们可以使用MLP来提取变换不变特征。
- 我们通过冻结特征提取器并重新训练分类器来提高LDGCNN的性能( 避免在大量参数下产生局部最优解 )。
- 我们评估了LDGCNN,并显示它在两个经典3D数据集上均达到了最新的性能。
在本文的以下部分中,我们将在第二部分介绍ModelNet40和ShapeNet的数据集。然后在第三节中描述研究问题,我们的理论方法和网络体系结构。实验结果和相应的讨论见第四节。最后,我们在第五节结束本文。
二、材料
分类的数据集为ModelNet40 [5],其中包括属于40个类别的12,311个CAD模式。 该数据集分为训练集(9843个模型)和验证集(2468个模型)[18]。 但是,没有对ModelNet40进行测试。 我们将在IV-B小节中讨论这个问题。 此外,每个CAD模型都通过1024个点进行采样,这些点被标准化为一个单位球体。
分割任务基于ShapeNet零件数据集[6],该数据集由16个类别的16,881个CAD模型组成。以前的研究人员将每个CAD模型采样到2048个点,每个点用50个零件中的一个进行注释。 本文中的训练,验证和测试数据集与[21]中的相同。
三、方法
我们的LDGCNN受PointNet [18]和DGCNN [21]的启发。我们为点云构造一个有向图。然后我们从构造的图形中提取特征,并利用特征对点云进行分类和分割。下面,我们讨论研究问题和相应的解决方案。
A.问题陈述
我们方法的输入是点云,它是一组3D点:
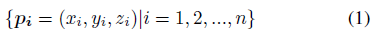
其中pi是点云的一个点,由三个坐标(xi; yi; zi)组成。 该点的索引和点云中的点数分别为i和n。
我们在本文中专注于两个任务:点云分类和分割。对于点云分类,我们需要对整个点云的类别进行分类。因此,我们应该找到一个分类函数fc,将输入点云转换为每个类Pr上的概率分布:
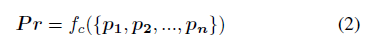
至于点云分割,可以将每个点pi分类为特定类别。因此,我们需要找到一个分割函数fs来计算每个点pi在每个类别Pri上的概率分布:
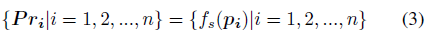
分类函数fc和分割函数fs有几个设计约束:
(1)置换不变性:
点云是一个点集,而不是序列信号。因此,点的顺序可以变化,但不影响点云的类别。分类函数不应受输入点的顺序影响:
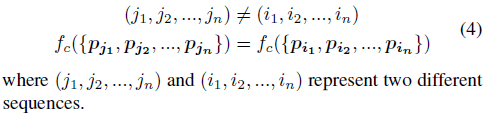
(2)变换不变性:
在实际应用中,传感器和物体之间的相对位置和方向可能会发生变化,从而导致生成的点云平移和旋转。但是,上述仿射变换不应更改分类和分割的结果:
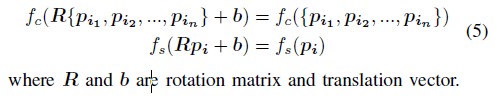
(3)提取局部特征:
局部特征是点与它的邻居之间的关系,这对于点云识别的成功至关重要。 因此,我们需要学习局部特征,而不是分别处理每个点:
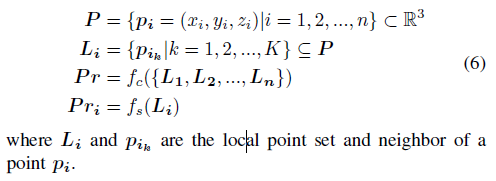
B.图生成
图神经网络是一种适用于处理点云的方法,因为它在每个节点上传播而忽略了节点的输入顺序,并学习两个节点之间的依存关系信息[26]将其作为边。要在点云上应用图神经网络,我们需要先将其转换为有向图。图G由顶点V和边E组成:
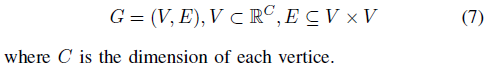
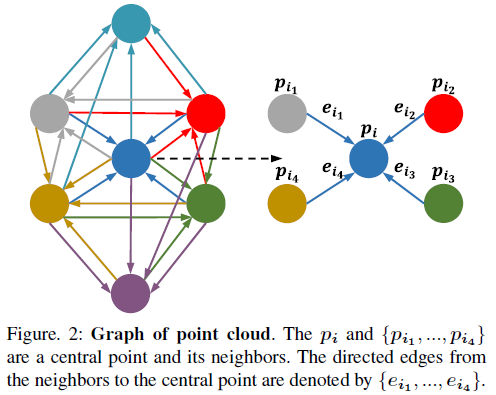
我们不为点云构造完全连接的边缘,因为它消耗大量内存。一种简单的方法是利用K-NN构造局部有向图,如图2所示。在该局部有向图中,每个点pi是一个中心节点,并计算出中心节点与其k个近邻之间的边ei:
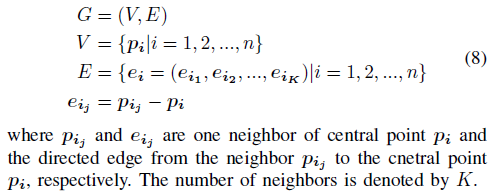
像DGCNN [21]一样,我们在每个卷积层之前应用K-NN,然后我们可以在欧氏空间和特征空间中构造局部图。因此,点pi也代表特征空间中的中心点,而pij是特征空间中中心点pi的邻居。
C.图特征提取
构造局部图后,我们基于边缘卷积层提取局部图特征[21]。特征提取函数fe对于所有点都是相同的,因此我们以一个中心点pi及其K个邻居为例进行说明。 输入是中心点pi的局部图,输出是局部特征li:
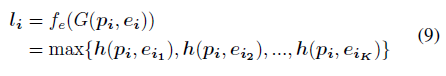
其中h(pi; eij)是关于中心点pi和一个边缘向量eij的隐藏层向量。
在(9)中,我们使用最大池化操作,因为它不受邻居顺序的影响,并且可以提取所有边缘中最主要的特征。 此外,我们利用一个MLP提取隐藏特征向量h(pi; eij):
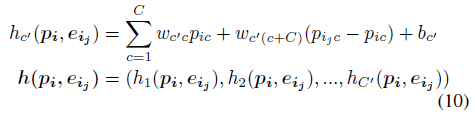
其中pic和pijc是通道c中中心点pi及其相邻pij的值。 输入点pi和输出隐藏特征向量h(pi; eij)的通道数分别为C和C’,隐藏层特征向量在通道c’中的值由hc’(pi; eij)表示。MLP的可训练参数为wc’c,wc’(c + C)和bc’。
D.变换不变函数
PointNet [18]和DGCNN [21]都依赖于转换网络来估计点云的旋转矩阵并补偿点云。但是,转换网络使网络的大小增加了一倍。此外,通过实验,我们发现该网络在去除转换网络后仍然具有令人满意的性能。因此,我们在这里讨论相应的原因。
转换网络的输出是一个3 x 3的矩阵R,它可以补偿点云P:
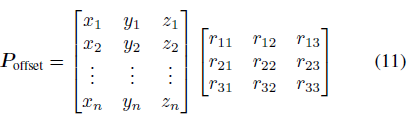
其中rij是第i行第j列上旋转矩阵R的值。另外,xi,yi和zi是点云P中单点pi的坐标。
如果将MLP转换为矩阵形式,我们可以找到隐藏层的特征向量是:
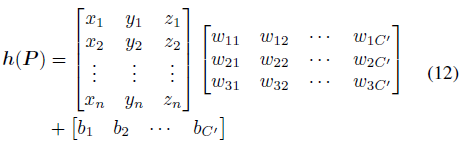
其中wic’和bc’是通道c’中MLP的可训练参数。输出通道数为C’。
将(12)与(11)进行比较,我们可以发现它们是相似的。不同之处在于,转换网络可以为每个点云估计一个特定的矩阵,而MLP对于所有点云都是静态的。MLP在不同通道中的参数可以使点云旋转不同的角度,并可以使点云移动不同的平移。考虑到我们至少有64个输出通道,MLP可以沿至少64个方向观察点云,这可以使网络大致旋转不变。
此外,我们增加了训练数据以提高网络的泛化能力。像PointNet ++ [20]一样,我们也随机旋转,移动和缩放输入点云,并在每个点上添加随机噪声。扩充训练数据后,网络可以学习旋转和平移不变特征。
E.LDGCNN架构
LDGCNN的体系结构如图3所示,详细说明在图3的标题中进行了说明。我们的网络类似于DGCNN [21],并且LDGCNN和DGCNN之间存在一些差异:
- 我们链接来自不同层的分层特征。
- 我们删除了转换网络。
删除转换网络的原因在第III-D小节中讨论。在这里,我们解释了为什么我们要链接来自不同层的层次结构特征。第一个原因是,链接层次结构特征可以避免深度神经网络的梯度消失问题,这在[27]中得到了证明。此外基于当前特征的邻域索引不同于基于先前特征的邻域索引。因此,我们可以通过,使用当前索引从先前特征中提取边缘来学习新特征。此外,当前特征的邻居彼此相似,这可能导致边缘向量接近零。如果我们使用当前的邻域索引从以前的特征计算边缘,则可能会得到有用的边缘向量。

F.冻结特征提取器和再训练分类器
通过冻结特征提取器(在全局特征之前的网络)并重新训练分类器(在全局特征之后的MLP),我们进一步提高了网络的性能。从理论上讲,训练整个网络可以找到全局最小值。但是,网络中的参数太多,几乎不可能通过训练找到全局最小值。相反,由于参数大,网络可能会降到较低的局部最小值。冻结特征提取器后,反向传播仅影响分类器的参数,该分类器由三个完全连接的层组成。因此,在训练了整个网络之后,我保存了全局特征,然后利用这些全局特征分别训练了分类器,这有助于我的网络获得更好的性能。
四、结果
A.应用细节
我们的训练策略与[21]相同。学习率为0.001的Adam optimizer用于优化整个网络。输入点数,批次大小和动量分别为1024、32和0.9。我们将邻居数K设置为20。此外,所有丢失层dropout的丢失率都设置为0.5。训练完整个网络后,我冻结特征提取器并重新训练分类器。在重训练过程中,我仅将优化器更改为Momentum。对于分割网络,由于输入点数更改为2048,因此将邻居数K更改为30。其他设置与分类的设置相同。此外,我们用一个NVIDIA TITAN V GPU训练分类网络。 然后,我们使用两个NVIDIA TITANV GPU来训练我们的分割网络。
B.点云分类
我们在第二部分介绍的ModelNet40数据集[5]上评估分类网络的性能。如表1所示,我们的LDGCNN在此数据集上实现了最高的准确性。对于相同的输入(1024点),我们的网络的整体分类准确度(92.9%)比DGCNN和PointCNN高0.7%。
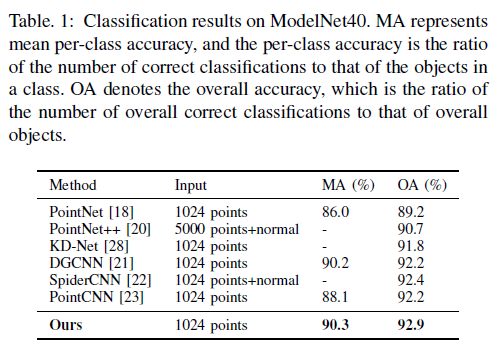
先前的研究人员提出,他们将ModelNet40分为训练集和测试集[18,21]。 但是,他们在论文中写下了最佳的测试精度。他们训练的最后一个时期的测试准确性可能比其最佳测试准确性低约1%-1.5%。因此,他们将测试集视为验证集,并使用验证集优化其超参数并确定停止训练的时间。因为我们需要将我们的网络与以前的网络进行比较,所以我们还使用ModelNet40的验证集来确定停止训练的时间。 由于我们使用与以前的研究人员相同的分裂数据集和训练策略,因此,我们网络的更高分类精度仍然可以证明我们的网络达到了最先进的性能。
C.点云分割
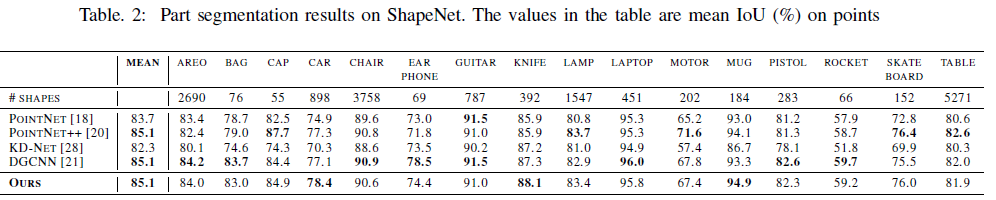
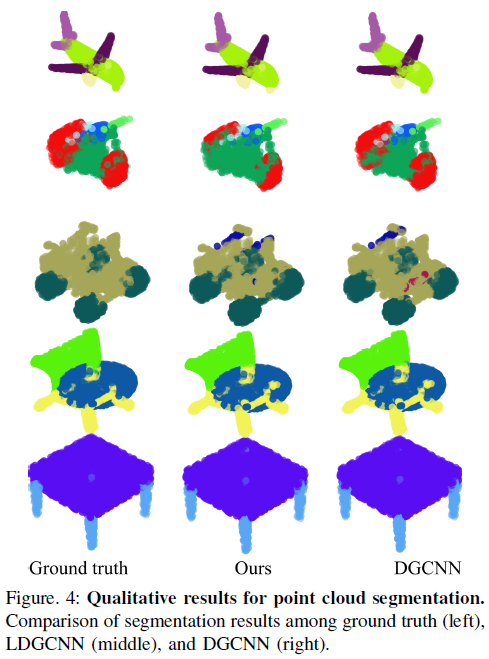
交并比(IoU)用于评估我们的网络在ShapeNet [6]上进行点云分割的性能,这在第二节中进行了描述。分割网络预测每个点的标签,并将预测结果与真实标签进行比较。然后计算出预测点与真实点的交集和并集。IoU是交集与并集中的点数之比。如表2所示,我们的分割网络也达到了最先进的性能。此外,在图4中,我们将分割的点云与真实点云和DGCNN分割的点云进行了比较。
D.时间和空间复杂度分析
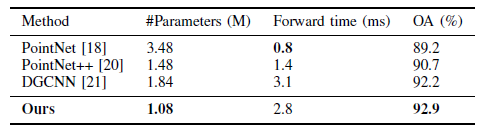
我们通过与其他分类网络比较我们的分类网络的参数数量和前向时间来评估模型的复杂性。根据一个NVIDIA TITAN V GPU的计算能力来估算前向时间。如表3所示,我们网络的模型规模小于PointNet,PointNet ++和DGCNN。我们的网络的前向时间比DGCNN的要短,但比PointNet ++和PointNet的要长,这是因为我们将K-NN用于在每个边缘卷积层中搜索邻居。与DGCNN相比,我们的网络更加简洁,并且实现了更高的分类精度。
E.可视化和消融实验
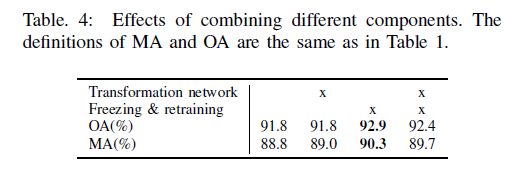
T分布随机邻居嵌入(T-SNE)被用来展示我们的特征提取器的性能[29]。T-SNE减少了高维特征的维数以可视化特征的可分离性。如图5所示,提取的特征比原始点云具有更大的判别力。此外,我们分析了这两个组成部分的作用:删除变换网络和冻结特征提取器并重新训练分类器。如表4所示,通过冻结特征提取器和重新训练分类器,我们将整体分类精度从91.8%提高到92.9%。此外,转换网络无法提高网络的性能。这一结果证实了我们的假设,即MLP可以代替变换网络逼近旋转不变性,这是在III-D小节中提出的。

)
五、总结
在本文中,我们提出了一种LDGCNN直接对点云进行分类和分割。 与DGCNN相比,我们通过删除转换网络来减小网络的模型大小,并通过链接来自不同动态图的层次结构特征来优化网络体系结构。在训练了整个网络之后,我们冻结了特征提取器并重新训练了分类器,这使ModelNet40上的分类准确性从91.8%提高到92.9%。我们的网络在两个标准数据集上实现了最先进的性能:ModelNet40和ShapeNet。此外,我们提供了对网络的理论分析以及可视化的分类和分割结果。将来,我们将在更多语义分割数据集上评估LDGCNN并将其应用于实时环境理解应用程序。
论文笔记:(2019)LDGCNN : Linked Dynamic Graph CNN-Learning on PointCloud via Linking Hierarchical Features的更多相关文章
- 【论文阅读】DGCNN:Dynamic Graph CNN for Learning on Point Clouds
毕设进了图网络的坑,感觉有点难,一点点慢慢学吧,本文方法是<Rethinking Table Recognition using Graph Neural Networks>中关系建模环节 ...
- 论文笔记:(TOG2019)DGCNN : Dynamic Graph CNN for Learning on Point Clouds
目录 摘要 一.引言 二.相关工作 三.我们的方法 3.1 边缘卷积Edge Convolution 3.2动态图更新 3.3 性质 3.4 与现有方法比较 四.评估 4.1 分类 4.2 模型复杂度 ...
- 论文阅读 Dynamic Graph Representation Learning Via Self-Attention Networks
4 Dynamic Graph Representation Learning Via Self-Attention Networks link:https://arxiv.org/abs/1812. ...
- 论文阅读 dyngraph2vec: Capturing Network Dynamics using Dynamic Graph Representation Learning
6 dyngraph2vec: Capturing Network Dynamics using Dynamic Graph Representation Learning207 link:https ...
- 论文解读(GMI)《Graph Representation Learning via Graphical Mutual Information Maximization》2
Paper Information 论文作者:Zhen Peng.Wenbing Huang.Minnan Luo.Q. Zheng.Yu Rong.Tingyang Xu.Junzhou Huang ...
- 论文解读(GMI)《Graph Representation Learning via Graphical Mutual Information Maximization》
Paper Information 论文作者:Zhen Peng.Wenbing Huang.Minnan Luo.Q. Zheng.Yu Rong.Tingyang Xu.Junzhou Huang ...
- 论文解读(GRCCA)《 Graph Representation Learning via Contrasting Cluster Assignments》
论文信息 论文标题:Graph Representation Learning via Contrasting Cluster Assignments论文作者:Chun-Yang Zhang, Hon ...
- 论文解读(GCA)《Graph Contrastive Learning with Adaptive Augmentation》
论文信息 论文标题:Graph Contrastive Learning with Adaptive Augmentation论文作者:Yanqiao Zhu.Yichen Xu3.Feng Yu4. ...
- 论文笔记《Tracking Using Dynamic Programming for Appearance-Based Sign Language Recognition》
一.概述 这是我在做手势识别的时候,在解决手势画面提取的时候看的一篇paper,这里关键是使用了动态规划来作为跟踪算法,效果是可以比拟cameshift和kf的,但在occlusion,gaps或者离 ...
随机推荐
- ORA-01157:cannot identify/lock data file 6 - see DBWR trace file ORA-01110:data file 6:'/u01/app/oracle/oradata/PRDO2/sysaux02.dbf'
- 『无为则无心』Python基础 — 5、Python开发工具的安装与使用
目录 1.Pycharm下载 2.Pycharm安装 3.PyCharm界面介绍 4.基本使用 (1)新建Python项目 (2)编写Python代码 (3)执行代码查看结果 (4)设置PyCharm ...
- redis字典快速映射+hash釜底抽薪+渐进式rehash | redis为什么那么快
前言 相信你一定使用过新华字典吧!小时候不会读的字都是通过字典去查找的.在Redis中也存在相同功能叫做字典又称为符号表!是一种保存键值对的抽象数据结构 本篇仍然定位在[redis前传]系列中,因为本 ...
- css 设置小知识点记录
1.消除控件与控件之间的边界 /* 公共样式 用于消除控件与控件之间的边界 */ *{ margin:0; padding:0} 2.设置背景图片大小与控件大小一致 #frame_top{ min-h ...
- oracle 日常运维
1.查询表或存储过程.函数异常 select * from user_errors where name ='TEST_TABLE' 2.查询表是否存在 select * from user_tabl ...
- Centos中安装Node.Js
NodeJs安装有好几种方式: 第一种: 最简单的是用yum命令,可惜我现在用的时候 发现 镜像中没有nodejs:所以这种方式放弃: 第二种:去官网下载源码,然后自己编译:编译过程中可能会出现问题, ...
- B 站崩了,总结下「高可用」和「异地多活」
你好,我是悟空. 一.背景 不用想象一种异常场景了,这就真实发生了:B 站晚上 11 点突然挂了,网站主页直接报 404. 手机 APP 端数据加载不出来. 23:30 分,B 站做了降级页面,将 4 ...
- Spring Boot中的那些生命周期和其中的可扩展点(转)
前言可扩展点的种类Spring Boot启动过程 1.SpringApplication的启动过程 2.ApplicationContext的启动过程 3.一般的非懒加载单例Bean在Spring B ...
- MYSQL_Join注入技巧
Join注入技巧 join无名列报错注入 约束条件 在知到表名的前提下才能操作 注入语句 and extractvalue(1,concat(0x7e,(select * from (select * ...
- Python - 基本数据类型_Number 数字、bool 布尔、complex 复数
Number 数字,是一个大的分类,细分四小类 整数:int 浮点数:float 布尔:bool 复数:complex int 的栗子 print(type(-1)) print(type(1)) p ...