爬虫:获取动态加载数据(selenium)(某站)
如果网站数据是动态加载,需要不停往下拉进度条才能显示数据,用selenium模拟浏览器下拉进度条可以实现动态数据的抓取。
本文希望找到某乎某话题下讨论较多的问题,以此再寻找每一问题涉及的话题关键词(侵删)。
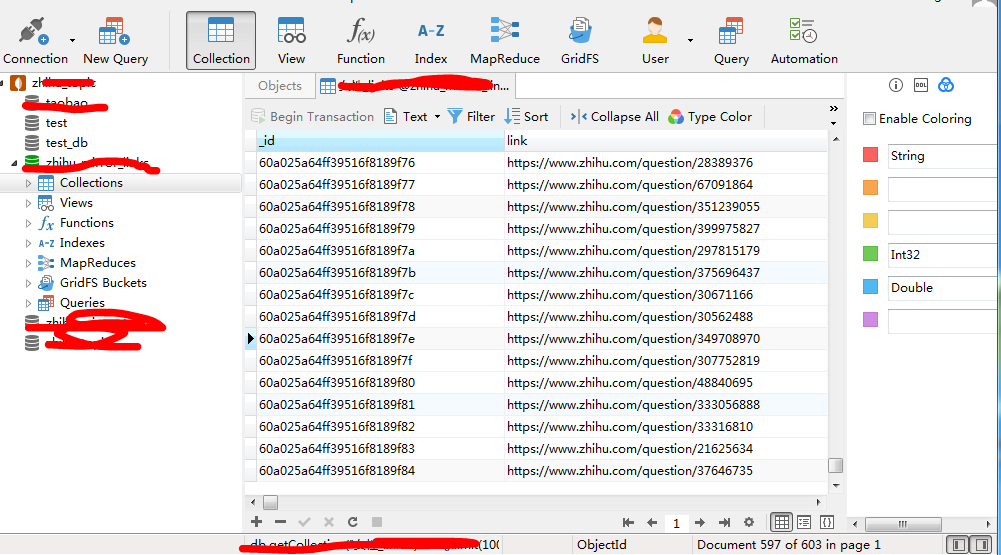
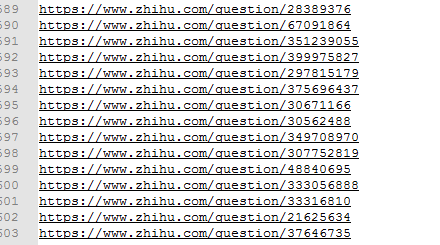
下面代码采用driver.execute_script("window.scrollTo(0, document.body.scrollHeight)")模拟浏览器下拉进度条200次,获取了女性话题下近900多条回答,去重(同一话题下有重复问题)后得到600多个问题
from selenium.webdriver import Chrome
from selenium.webdriver import ChromeOptions
import time
import random
import re
from pymongo import MongoClient client = MongoClient('localhost')
db = client['test_db'] def get_links(url, word):
option = ChromeOptions()
option.add_experimental_option('excludeSwitches', ['enable-automation'])
option.add_argument('user-agent="Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.130 Safari/537.36"')
driver = Chrome(options=option)
time.sleep(10)
driver.get('https://www.zhihu.com')
time.sleep(10)
driver.delete_all_cookies() # 清除刚才的cookie
time.sleep(2)
cookie = {} # 替换为自己的cookie
driver.add_cookie(cookie)
driver.get(url)
time.sleep(random.uniform(10, 11)) for i in range(0, 200):
driver.execute_script("window.scrollTo(0, document.body.scrollHeight)")
time.sleep(random.uniform(3, 4)) links = driver.find_elements_by_css_selector('h2.ContentItem-title > div > a')
print(len(links))
# 去重
regex = re.compile(r'https://www.zhihu.com/question/\d+') # 匹配问题而不是答案链接
links_set = set()
for link in links:
try:
links_set.add(regex.search(link.get_attribute("href")).group())
except AttributeError:
pass
print(len(links_set)) with open(r'知乎镜像链接' + '/' + word + '-'.join(str(i) for i in list(time.localtime())[:5]) + '.txt', 'a') as f:
for item in links_set:
f.write(item + '\n')
db[word + '_' + 'links'].insert_one({"link": item}) if __name__ == '__main__':
input_word = input('输入话题:')
input_link = input('输入话题对应链接url:')
get_links(input_link, input_word)
截图如下:

爬虫:获取动态加载数据(selenium)(某站)的更多相关文章
- 爬虫--selenuim和phantonJs处理网页动态加载数据的爬取
1.谷歌浏览器的使用 下载谷歌浏览器 安装谷歌访问助手 终于用上谷歌浏览器了.....激动 问题:处理页面动态加载数据的爬取 -1.selenium -2.phantomJs 1.selenium 二 ...
- 爬虫开发6.selenuim和phantonJs处理网页动态加载数据的爬取
selenuim和phantonJs处理网页动态加载数据的爬取阅读量: 1203 动态数据加载处理 一.图片懒加载 什么是图片懒加载? 案例分析:抓取站长素材http://sc.chinaz.com/ ...
- (五)selenuim和phantonJs处理网页动态加载数据的爬取
selenuim和phantonJs处理网页动态加载数据的爬取 一 图片懒加载 自己理解------就是在打开一个页面的时候,图片数量特别多,图片加载会增加服务器的压力,所以我们在这个时候,就会用到- ...
- AppCan学习笔记----关闭页面listview动态加载数据
AppCan页面关闭 AppCan 的页面是由两个HTML组成,如果要完全关闭的话需要在主HTML eg.index.html中关闭,关闭方法:appcan.window.close(-1); 管道 ...
- mui 动态加载数据出现的问题处理 (silder轮播组件 indexedList索引列表 下拉刷新不能继续加载数据)
mui-slider 问题:动态给mui的图片轮播添加图片,轮播不滚动. 解决:最后把滚动轮播图片的mui(".mui-slider").slider({interval: 300 ...
- asp.net c# select 动态加载数据
1.说明通过 asp.net,利用jQuery ,c#语言给 select控件动态加载数据.前端页面使用的是.aspx类型的HTML页面,后台使用MVC上的controller控制器 2.webcon ...
- [JS前端开发] js/jquery控制页面动态加载数据 滑动滚动条自动加载事件
页面滚动动态加载数据,页面下拉自动加载内容 相信很多人都见过瀑布流图片布局,那些图片是动态加载出来的,效果很好,对服务器的压力相对来说也小了很多 有手机的相信都见过这样的效果:进入qq空间,向下拉动空 ...
- 微信小程序(五) 利用模板动态加载数据
利用模板动态加载数据,其实是对上一节静态数据替换成动态数据:
- ASP.NET MVC动态加载数据
ASP.NET MVC动态加载数据,一般的做法是使用$.each方法来循环产生tabel: 你可以在html时先写下非动态的部分: Source Code 上图中,有一行代码: <tbody ...
随机推荐
- 从零学脚手架(八)---webpack-dev-server源码分析
上一篇中介绍了webpack-dev-server属性配置 这一篇就简单的梳理下webpack-dev-server内部实现. 由于涉及到源码解析,所以会涉及到一些比较难啃的知识,我会尽量进行简单化描 ...
- [源码解析] 并行分布式框架 Celery 之 worker 启动 (2)
[源码解析] 并行分布式框架 Celery 之 worker 启动 (2) 目录 [源码解析] 并行分布式框架 Celery 之 worker 启动 (2) 0x00 摘要 0x01 前文回顾 0x2 ...
- ECharts地理坐标系属性介绍
在 ECharts 地理坐标系的属性设置中,如果您要将地理坐标系组件显示出来,那么,请使用 geo 组件的 show 属性.在 geo 组件中提供了两种类型的地图数据:javascript 文件与 J ...
- java面试-生产环境出现CPU占用过高,谈谈你的分析思路和定位
思路:结合Linux和JDK命令一起分析 1.用top命令找出CPU占比最高的进程 2.ps -ef|grep java|grep -v grep 或者jps -l进一步定位,得知是怎样一个后台程序惹 ...
- 【Git基本命令】
[基本指令] git init :使目标文件夹变成一个仓库 git add <文件名,含后缀> : 告诉git我要添加文件了 git commit -m "<提交说明> ...
- 100天搞定机器学习:PyYAML基础教程
编程中免不了要写配置文件,今天我们继续Python网络编程,学习一个比 JSON 更简洁和强大的语言----YAML .本文老胡简单介绍 YAML 的语法和用法,以及 YAML 在机器学习项目中的应用 ...
- 使用gradle插件发布项目到nexus中央仓库
目录 简介 Gradle Nexus Publish Plugin历史 插件的使用 Groovy DSL Kotlin DSL 插件背后的故事 总结 简介 Sonatype 提供了一个叫做开源软件资源 ...
- 解决WebStorm无法正确识别Vue3组合式API的问题
1 问题描述 Vue3的组合式API无法在WebStorm中正确识别,表现为defineComponent等无法被识别: 2 尝试方案 猜想这种问题的原因是无法正确识别对应的Vue3库,笔者相信Web ...
- K8s - 解决主机重启后kubelet无法自动启动问题 错误:The connection to the server 192.168.60.128:6443 was refused - did you specify the right host or port?
1,问题描述 (1)在安装配置好 Kubernetes 后,正常情况下服务器关机重启,kubelet 也会自动启动的.但最近配置的一台服务器重启后,输入命令 kubectl get nodes 查看节 ...
- 5. Mybatis UPDATE更新,DELETE删除
案例: 1. update <?xml version="1.0" encoding="UTF-8" ?> <!DOCTYPE mapper ...