python爬取豆瓣电影第一页数据and使用with open() as读写文件
# _*_ coding : utf-8 _*_
# @Time : 2021/11/2 9:58
# @Author : 秋泊酱
# @File : 获取豆瓣电影第一页
# @Project : 爬虫案例 # get请求
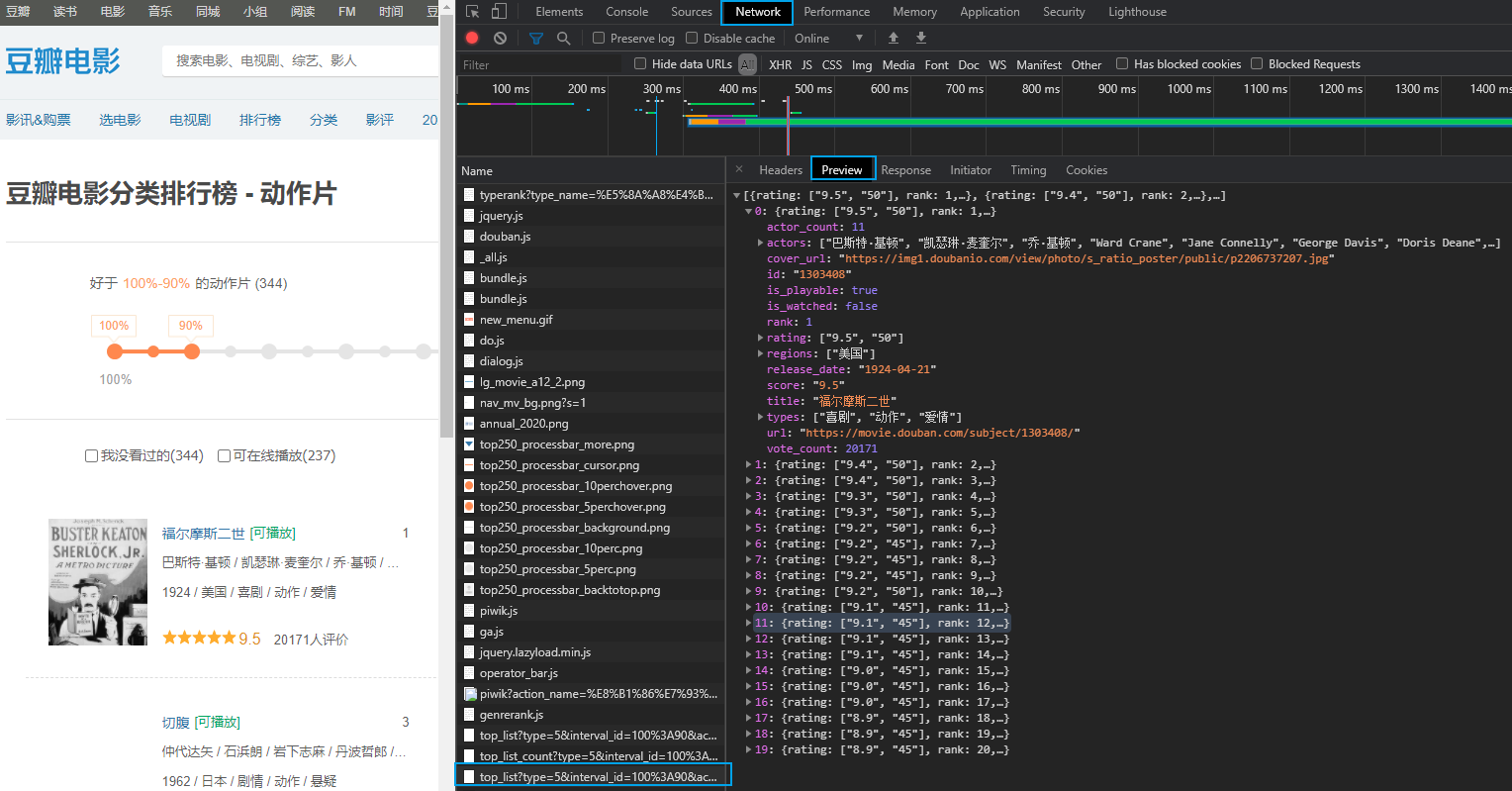
# 获取豆瓣电影的第一页的数据,并且保存到本地 import urllib.request
# 请求路径
url = 'https://movie.douban.com/j/chart/top_list?type=5&interval_id=100%3A90&action=&start=0&limit=20' # 请求头
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.89 Safari/537.36'
} # (1) 请求对象的定制
request = urllib.request.Request(url=url,headers=headers) # (2)获取响应的数据
response = urllib.request.urlopen(request)
content = response.read().decode('utf-8') # (3) 数据下载到本地
# open方法默认情况下使用的是gbk的编码 如果我们要想保存汉字 那么需要在open方法中指定编码格式为utf-8
# encoding = 'utf-8'
# fp = open('douban.json','w',encoding='utf-8')
# fp.write(content) with open('douban1.json','w',encoding='utf-8') as fp:
fp.write(content)
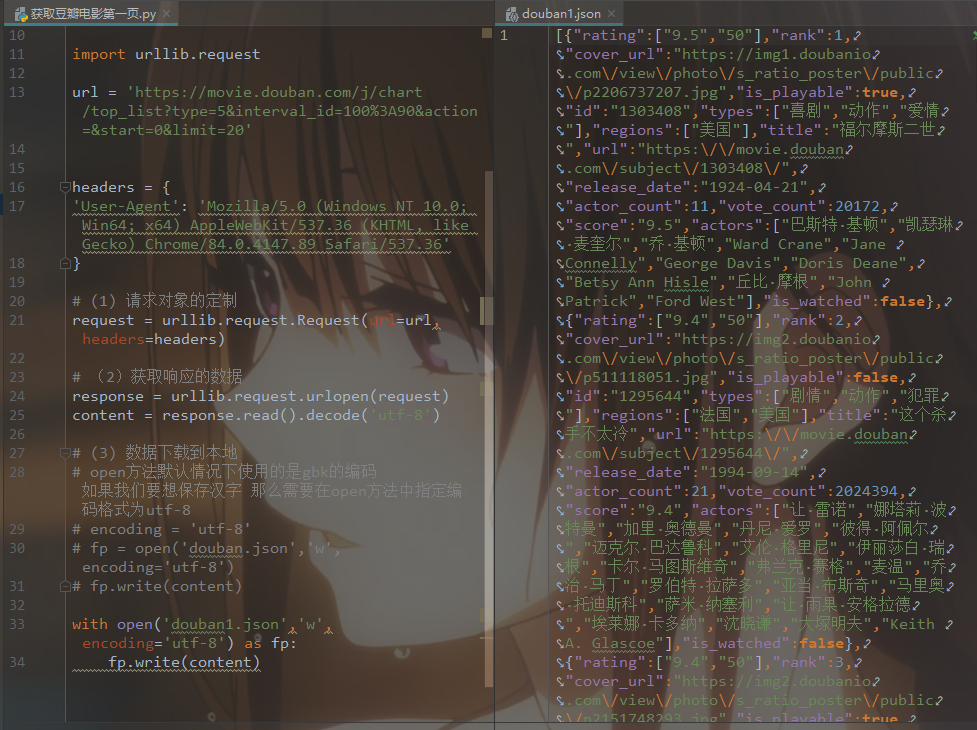
文件对象.readline() 方法用于从文件读取整行,包括 "\n" 字符。如果指定了一个非负数的参数,则返回指定大小的字节数,包括 "\n" 字符
文件读写时有可能产生IOError,一旦出错,后面的file.close()就不会调用。
file = open("test.txt", "r", encoding='UTF-8')
for line in file.readlines():
print (line)
file.close()
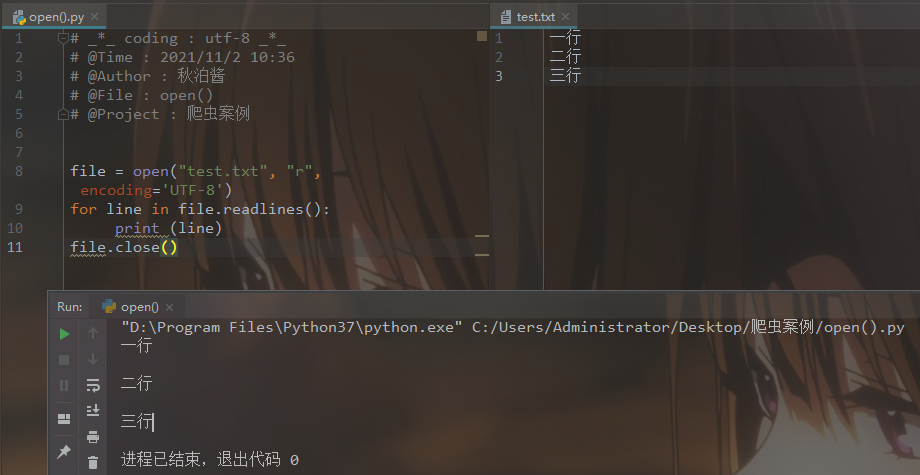
所以,为了保证无论是否出错都能正确地关闭文件,我们可以使用try: ...except: ... finally: ... 捕捉异常、处理异常来实现。
# _*_ coding : utf-8 _*_
# @Time : 2021/11/2 10:58
# @Author : 秋泊酱
# @File : 无法关闭
# @Project : 爬虫案例 file= open("../test.txt","r")
try:
for line in file.readlines():
print(line)
except:
print("error") # finally 语句无论是否发生异常都将执行最后的代码
finally:
file.close()
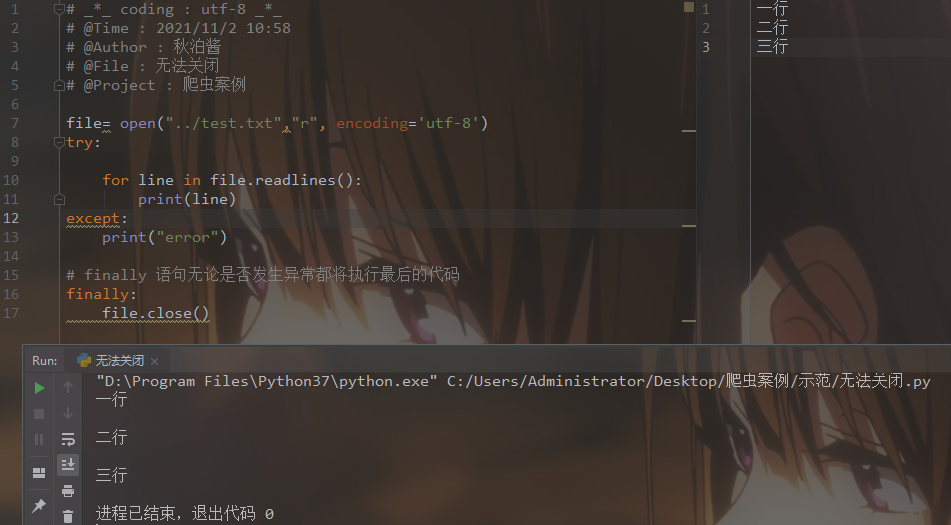
每次都这么写,太繁琐。
with open()as 会在语句结束自动关闭文件,即便出现异常
语法:
with open(文件名, 模式) as 文件对象:
文件对象.方法()
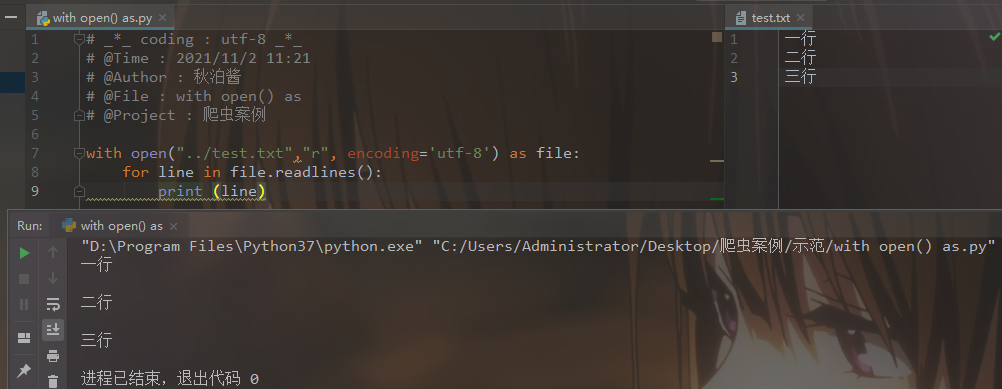
# _*_ coding : utf-8 _*_
# @Time : 2021/11/2 11:21
# @Author : 秋泊酱
# @File : with open() as
# @Project : 爬虫案例 with open("../test.txt","r", encoding='utf-8') as file:
for line in file.readlines():
print (line)
python爬取豆瓣电影第一页数据and使用with open() as读写文件的更多相关文章
- Python爬取豆瓣电影top
Python爬取豆瓣电影top250 下面以四种方法去解析数据,前面三种以插件库来解析,第四种以正则表达式去解析. xpath pyquery beaufifulsoup re 爬取信息:名称 评分 ...
- 利用Python爬取豆瓣电影
目标:使用Python爬取豆瓣电影并保存MongoDB数据库中 我们先来看一下通过浏览器的方式来筛选某些特定的电影: 我们把URL来复制出来分析分析: https://movie.douban.com ...
- python爬取豆瓣电影信息数据
题外话+ 大家好啊,最近自己在做一个属于自己的博客网站(准备辞职回家养老了,明年再战)在家里 琐事也很多, 加上自己 一回到家就懒了(主要是家里冷啊! 广东十几度,老家几度,躲在被窝瑟瑟发抖,) 由于 ...
- python 爬取豆瓣电影短评并wordcloud生成词云图
最近学到数据可视化到了词云图,正好学到爬虫,各种爬网站 [实验名称] 爬取豆瓣电影<千与千寻>的评论并生成词云 1. 利用爬虫获得电影评论的文本数据 2. 处理文本数据生成词云图 第一步, ...
- python 爬取豆瓣电影评论,并进行词云展示及出现的问题解决办法
本文旨在提供爬取豆瓣电影<我不是药神>评论和词云展示的代码样例 1.分析URL 2.爬取前10页评论 3.进行词云展示 1.分析URL 我不是药神 短评 第一页url https://mo ...
- 零基础爬虫----python爬取豆瓣电影top250的信息(转)
今天利用xpath写了一个小爬虫,比较适合一些爬虫新手来学习.话不多说,开始今天的正题,我会利用一个案例来介绍下xpath如何对网页进行解析的,以及如何对信息进行提取的. python环境:pytho ...
- python爬取豆瓣电影Top250(附完整源代码)
初学爬虫,学习一下三方库的使用以及简单静态网页的分析.就跟着视频写了一个爬取豆瓣Top250排行榜的爬虫. 网页分析 我个人感觉写爬虫最重要的就是分析网页,找到网页的规律,找到自己需要内容所在的地方, ...
- Python 爬取大众点评 50 页数据,最好吃的成都火锅竟是它!
前言 文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 作者: 胡萝卜酱 PS:如有需要Python学习资料的小伙伴可以加点击下方链 ...
- Python 爬取豆瓣电影Top250排行榜,爬虫初试
from bs4 import BeautifulSoup import openpyxl import re import urllib.request import urllib.error # ...
随机推荐
- Redis分布式方案:集群
Redis集群通过分片(sharding)进行数据共享,并提供复制和故障转移功能. 节点 一个Redis集群由多个node组成,连接各节点的命令格式如下: CLUSTER MEET 127.0.0.1 ...
- oeasy教您玩转vim - 53 - # 批量替换
查找细节 回忆上节课内容 我们温习了关于搜索的相关内容 /正向,?反向 n保持方向,N改变方向 可以设置 是否忽略大写小写 是否从头开始查找 是否高亮显示 还有一些正则表达式的使用方法 行头行尾 ^$ ...
- 最详细STL(一)vector
vector的本质还是数组,但是可以动态的增加和减少数组的容量(当数组空间内存不足时,都会执行: 分配新空间-复制元素-释放原空间),首先先讲讲vector和数组的具体区别 一.vector和数组的区 ...
- JDK源码阅读(3):AbstractStringBuilder、StringBuffer、StringBuilder类阅读笔记
AbstractStringBuilder abstract class AbstractStringBuilder implements Appendable, CharSequence{ ... ...
- 极简SpringBoot指南-Chapter01-如何用Spring框架声明Bean
仓库地址 w4ngzhen/springboot-simple-guide: This is a project that guides SpringBoot users to get started ...
- UOJ 2021 NOI Day2 部分题解
获奖名单 题目传送门 Solution 不难看出,若我们单个 \(x\) 连 \((0,x),(x,0)\),两个连 \((x,y),(y,x)\) ,除去中间过对称轴的一个两个组,就是找很多个欧拉回 ...
- hdu3507 斜率优化学习笔记(斜率优化+dp)
QWQ菜的真实. 首先来看这个题. 很显然能得到一个朴素的\(dp\)柿子 \[dp[i]=max(dp[i],dp[j]+(sum[i]-sum[j])^2) \] 但是因为\(n\le 50000 ...
- 论文解读(MPNN)Neural Message Passing for Quantum Chemistry
论文标题:DEEP GRAPH INFOMAX 论文方向: 论文来源:ICML 2017 论文链接:https://arxiv.org/abs/1704.01212 论文代码: 1 介绍 本文的目标 ...
- Java多线程编程实战指南 核心篇 读书笔记
锁 volatile CAS final static 原子性保障 具备 具备 具备 不涉及 不涉及 可见性保障 具备 具备 不具备 不具备 具备① 有序性保证 具备 具备 不涉及 具备 具备② 上下 ...
- 利用python爬取全国水雨情信息
分析 我们没有找到接口,所以打算利用selenium来爬取. 代码 import datetime import pandas as pd from bs4 import BeautifulSoup ...